 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Cluster-Based Partitioning of Convolutional Neural Networks, A Solution for Computational Energy and Complexity Reduction
Jun 29, 2020
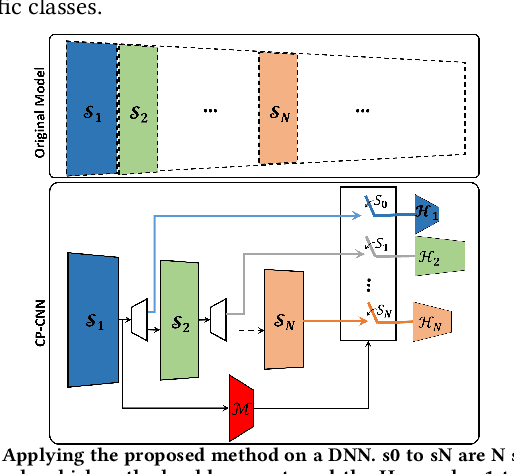
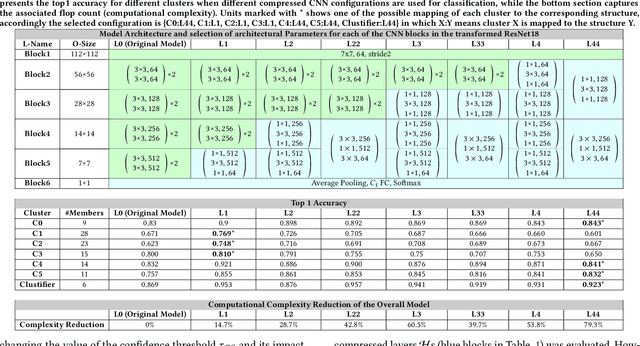
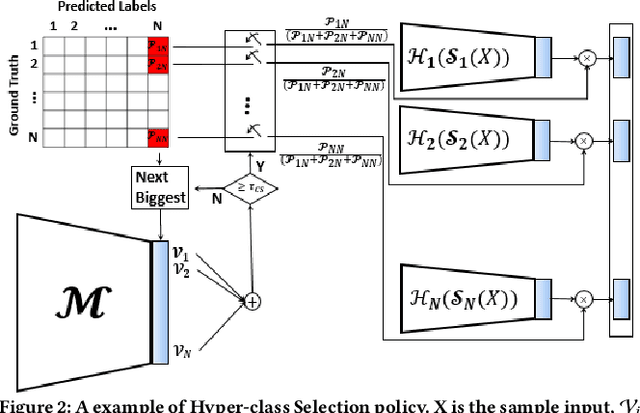
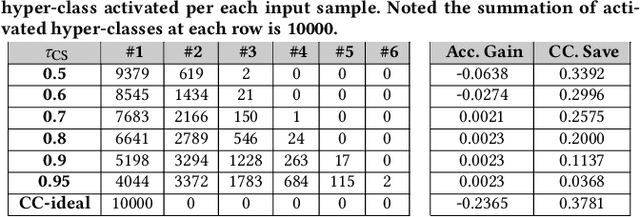
In this paper, we propose a novel solution to reduce the computational complexity of convolutional neural network models used for many class image classification. Our proposed model breaks the classification task into three stages: 1) general feature extraction, 2) Mid-level clustering, and 3) hyper-class classification. Steps 1 and 2 could be repeated to build larger hierarchical models. We illustrate that our proposed classifier can reach the level of accuracy reported by the best in class classification models with far less computational complexity (Flop Count) by only activating parts of the model that are needed for the image classification.
A Resilient Image Matching Method with an Affine Invariant Feature Detector and Descriptor
Dec 29, 2017
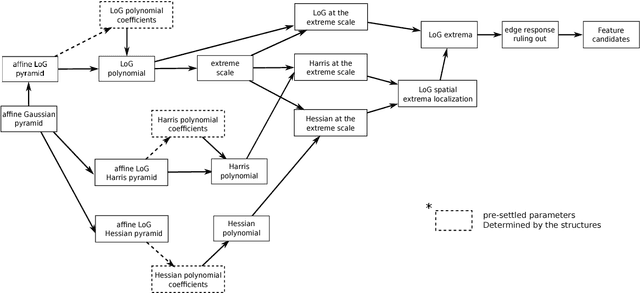
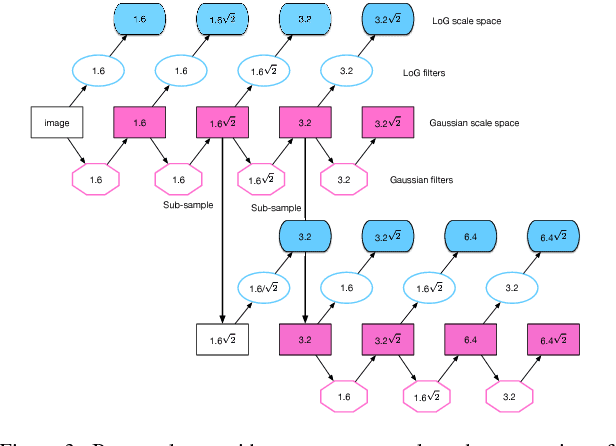
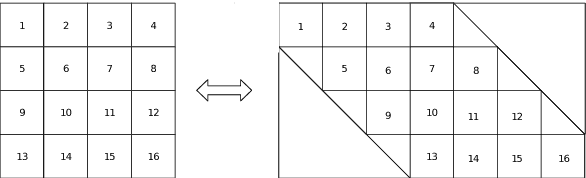
Image feature matching is to seek, localize and identify the similarities across the images. The matched local features between different images can indicate the similarities of their content. Resilience of image feature matching to large view point changes is challenging for a lot of applications such as 3D object reconstruction, object recognition and navigation, etc, which need accurate and robust feature matching from quite different view points. In this paper we propose a novel image feature matching algorithm, integrating our previous proposed Affine Invariant Feature Detector (AIFD) and new proposed Affine Invariant Feature Descriptor (AIFDd). Both stages of this new proposed algorithm can provide sufficient resilience to view point changes. With systematic experiments, we can prove that the proposed method of feature detector and descriptor outperforms other state-of-the-art feature matching algorithms especially on view points robustness. It also performs well under other conditions such as the change of illumination, rotation and compression, etc.
BoxNet: Deep Learning Based Biomedical Image Segmentation Using Boxes Only Annotation
Jun 02, 2018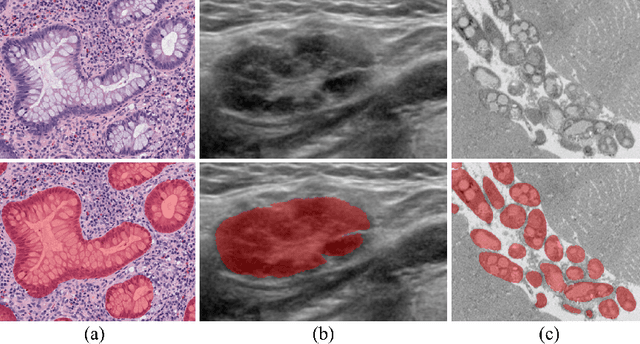
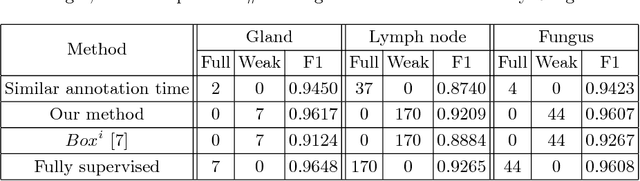


In recent years, deep learning (DL) methods have become powerful tools for biomedical image segmentation. However, high annotation efforts and costs are commonly needed to acquire sufficient biomedical training data for DL models. To alleviate the burden of manual annotation, in this paper, we propose a new weakly supervised DL approach for biomedical image segmentation using boxes only annotation. First, we develop a method to combine graph search (GS) and DL to generate fine object masks from box annotation, in which DL uses box annotation to compute a rough segmentation for GS and then GS is applied to locate the optimal object boundaries. During the mask generation process, we carefully utilize information from box annotation to filter out potential errors, and then use the generated masks to train an accurate DL segmentation network. Extensive experiments on gland segmentation in histology images, lymph node segmentation in ultrasound images, and fungus segmentation in electron microscopy images show that our approach attains superior performance over the best known state-of-the-art weakly supervised DL method and is able to achieve (1) nearly the same accuracy compared to fully supervised DL methods with far less annotation effort, (2) significantly better results with similar annotation time, and (3) robust performance in various applications.
Separation and Concentration in Deep Networks
Dec 18, 2020

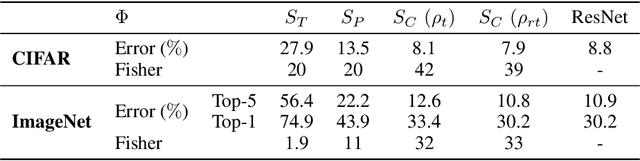

Numerical experiments demonstrate that deep neural network classifiers progressively separate class distributions around their mean, achieving linear separability on the training set, and increasing the Fisher discriminant ratio. We explain this mechanism with two types of operators. We prove that a rectifier without biases applied to sign-invariant tight frames can separate class means and increase Fisher ratios. On the opposite, a soft-thresholding on tight frames can reduce within-class variabilities while preserving class means. Variance reduction bounds are proved for Gaussian mixture models. For image classification, we show that separation of class means can be achieved with rectified wavelet tight frames that are not learned. It defines a scattering transform. Learning $1 \times 1$ convolutional tight frames along scattering channels and applying a soft-thresholding reduces within-class variabilities. The resulting scattering network reaches the classification accuracy of ResNet-18 on CIFAR-10 and ImageNet, with fewer layers and no learned biases.
SRPGAN: Perceptual Generative Adversarial Network for Single Image Super Resolution
Dec 20, 2017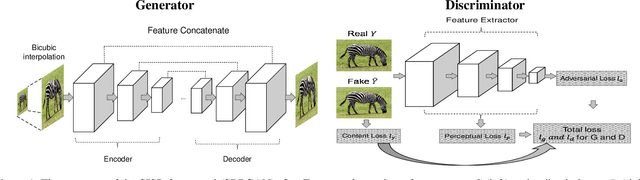
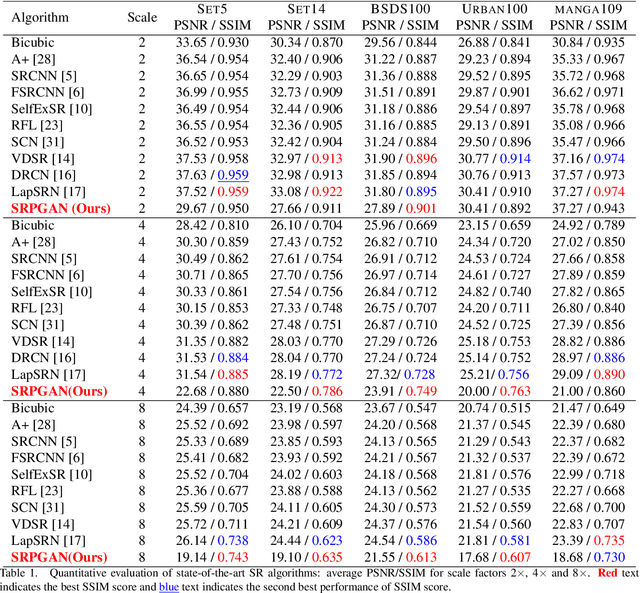

Single image super resolution (SISR) is to reconstruct a high resolution image from a single low resolution image. The SISR task has been a very attractive research topic over the last two decades. In recent years, convolutional neural network (CNN) based models have achieved great performance on SISR task. Despite the breakthroughs achieved by using CNN models, there are still some problems remaining unsolved, such as how to recover high frequency details of high resolution images. Previous CNN based models always use a pixel wise loss, such as l2 loss. Although the high resolution images constructed by these models have high peak signal-to-noise ratio (PSNR), they often tend to be blurry and lack high-frequency details, especially at a large scaling factor. In this paper, we build a super resolution perceptual generative adversarial network (SRPGAN) framework for SISR tasks. In the framework, we propose a robust perceptual loss based on the discriminator of the built SRPGAN model. We use the Charbonnier loss function to build the content loss and combine it with the proposed perceptual loss and the adversarial loss. Compared with other state-of-the-art methods, our method has demonstrated great ability to construct images with sharp edges and rich details. We also evaluate our method on different benchmarks and compare it with previous CNN based methods. The results show that our method can achieve much higher structural similarity index (SSIM) scores on most of the benchmarks than the previous state-of-art methods.
Classification of COVID-19 via Homology of CT-SCAN
Feb 21, 2021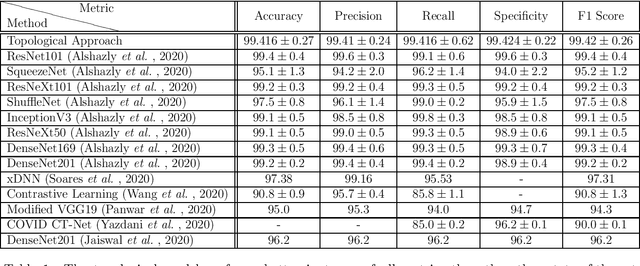
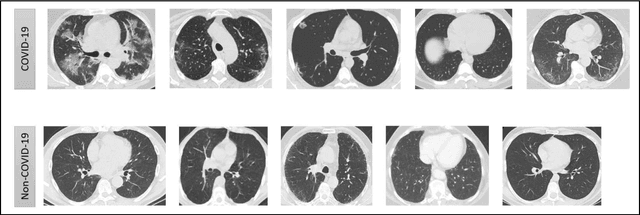
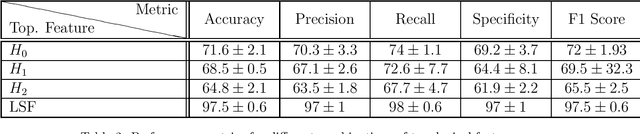
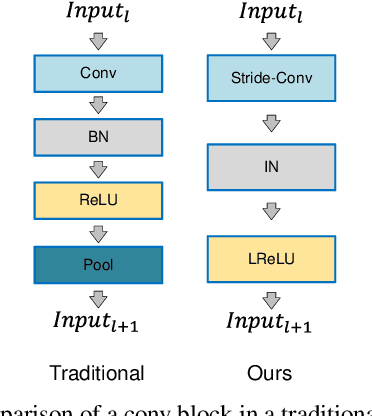
In this worldwide spread of SARS-CoV-2 (COVID-19) infection, it is of utmost importance to detect the disease at an early stage especially in the hot spots of this epidemic. There are more than 110 Million infected cases on the globe, sofar. Due to its promptness and effective results computed tomography (CT)-scan image is preferred to the reverse-transcription polymerase chain reaction (RT-PCR). Early detection and isolation of the patient is the only possible way of controlling the spread of the disease. Automated analysis of CT-Scans can provide enormous support in this process. In this article, We propose a novel approach to detect SARS-CoV-2 using CT-scan images. Our method is based on a very intuitive and natural idea of analyzing shapes, an attempt to mimic a professional medic. We mainly trace SARS-CoV-2 features by quantifying their topological properties. We primarily use a tool called persistent homology, from Topological Data Analysis (TDA), to compute these topological properties. We train and test our model on the "SARS-CoV-2 CT-scan dataset" \citep{soares2020sars}, an open-source dataset, containing 2,481 CT-scans of normal and COVID-19 patients. Our model yielded an overall benchmark F1 score of $99.42\% $, accuracy $99.416\%$, precision $99.41\%$, and recall $99.42\%$. The TDA techniques have great potential that can be utilized for efficient and prompt detection of COVID-19. The immense potential of TDA may be exploited in clinics for rapid and safe detection of COVID-19 globally, in particular in the low and middle-income countries where RT-PCR labs and/or kits are in a serious crisis.
Towards Robust Data Hiding Against (JPEG) Compression: A Pseudo-Differentiable Deep Learning Approach
Dec 30, 2020
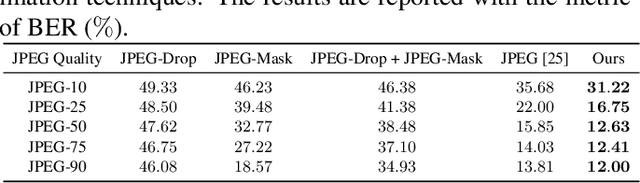
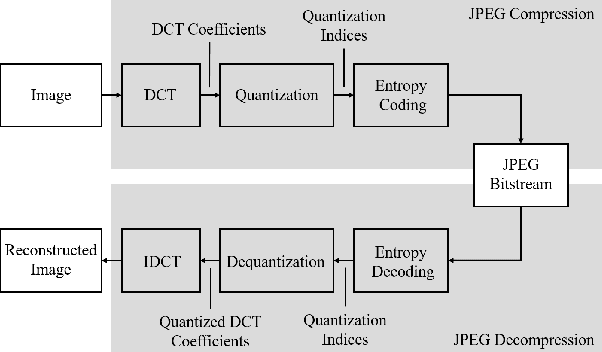

Data hiding is one widely used approach for protecting authentication and ownership. Most multimedia content like images and videos are transmitted or saved in the compressed form. This kind of lossy compression, such as JPEG, can destroy the hidden data, which raises the need of robust data hiding. It is still an open challenge to achieve the goal of data hiding that can be against these compressions. Recently, deep learning has shown large success in data hiding, while non-differentiability of JPEG makes it challenging to train a deep pipeline for improving robustness against lossy compression. The existing SOTA approaches replace the non-differentiable parts with differentiable modules that perform similar operations. Multiple limitations exist: (a) large engineering effort; (b) requiring a white-box knowledge of compression attacks; (c) only works for simple compression like JPEG. In this work, we propose a simple yet effective approach to address all the above limitations at once. Beyond JPEG, our approach has been shown to improve robustness against various image and video lossy compression algorithms.
On the Influence of Ageing on Face Morph Attacks: Vulnerability and Detection
Jul 06, 2020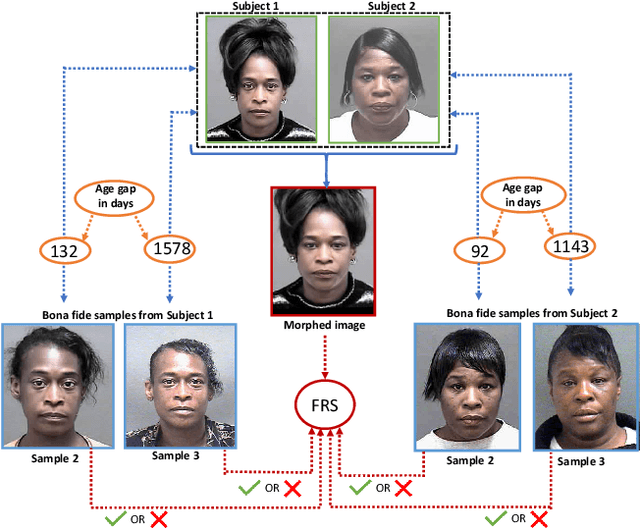
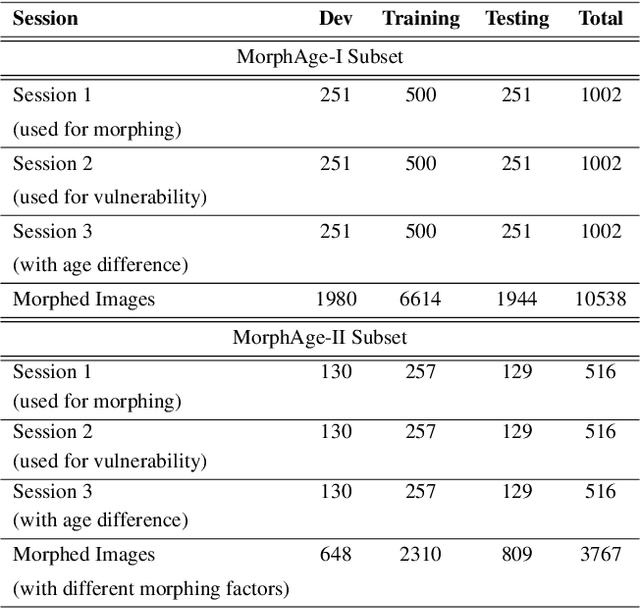
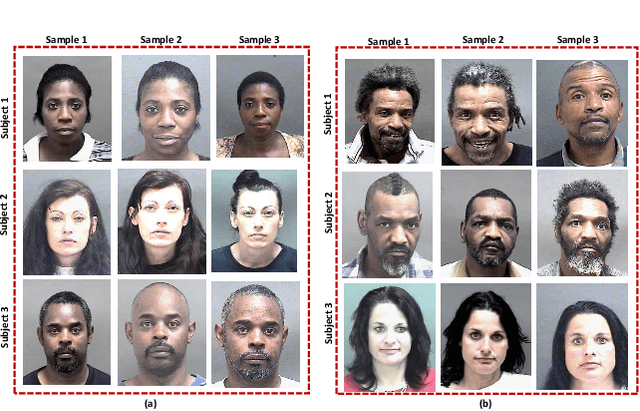
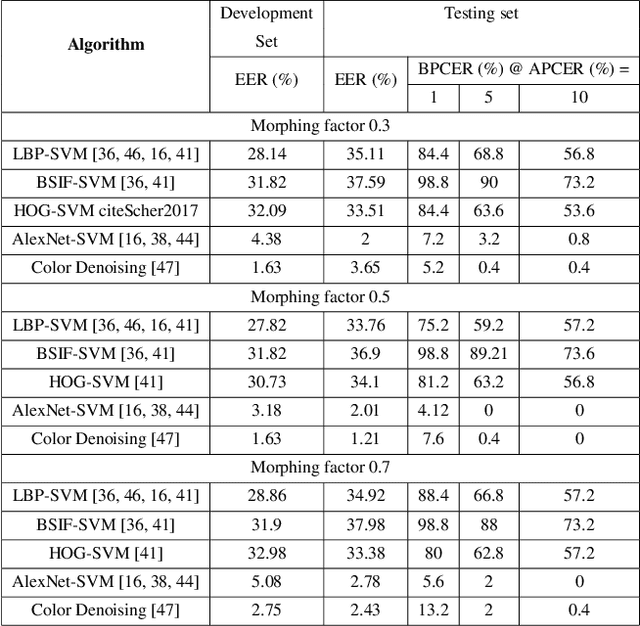
Face morphing attacks have raised critical concerns as they demonstrate a new vulnerability of Face Recognition Systems (FRS), which are widely deployed in border control applications. The face morphing process uses the images from multiple data subjects and performs an image blending operation to generate a morphed image of high quality. The generated morphed image exhibits similar visual characteristics corresponding to the biometric characteristics of the data subjects that contributed to the composite image and thus making it difficult for both humans and FRS, to detect such attacks. In this paper, we report a systematic investigation on the vulnerability of the Commercial-Off-The-Shelf (COTS) FRS when morphed images under the influence of ageing are presented. To this extent, we have introduced a new morphed face dataset with ageing derived from the publicly available MORPH II face dataset, which we refer to as MorphAge dataset. The dataset has two bins based on age intervals, the first bin - MorphAge-I dataset has 1002 unique data subjects with the age variation of 1 year to 2 years while the MorphAge-II dataset consists of 516 data subjects whose age intervals are from 2 years to 5 years. To effectively evaluate the vulnerability for morphing attacks, we also introduce a new evaluation metric, namely the Fully Mated Morphed Presentation Match Rate (FMMPMR), to quantify the vulnerability effectively in a realistic scenario. Extensive experiments are carried out by using two different COTS FRS (COTS I - Cognitec and COTS II - Neurotechnology) to quantify the vulnerability with ageing. Further, we also evaluate five different Morph Attack Detection (MAD) techniques to benchmark their detection performance with ageing.
High-Resolution Daytime Translation Without Domain Labels
Mar 23, 2020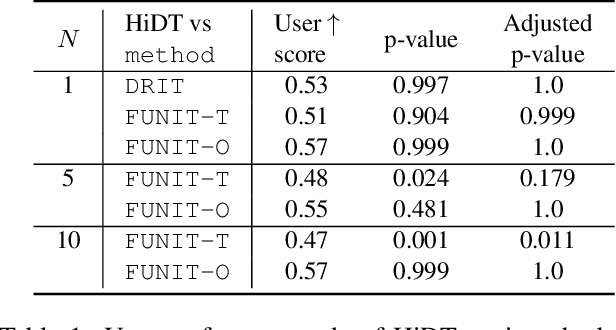
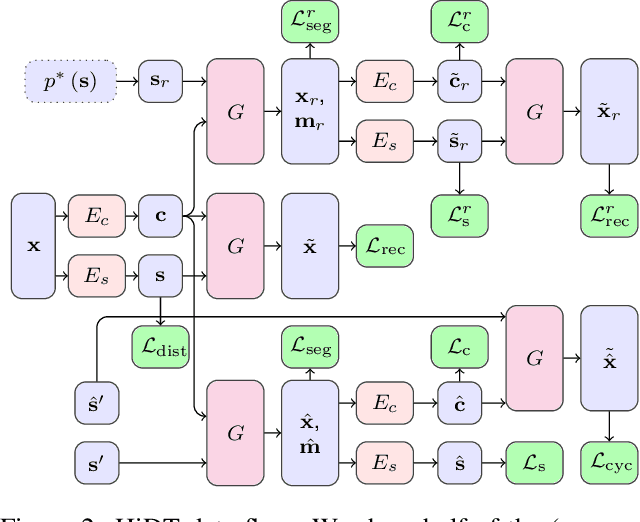
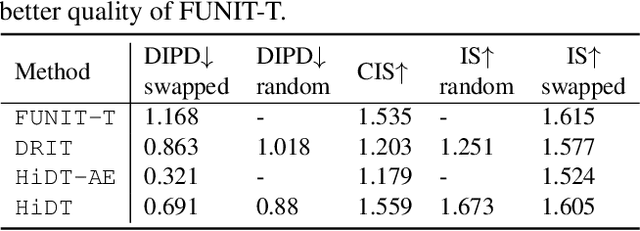
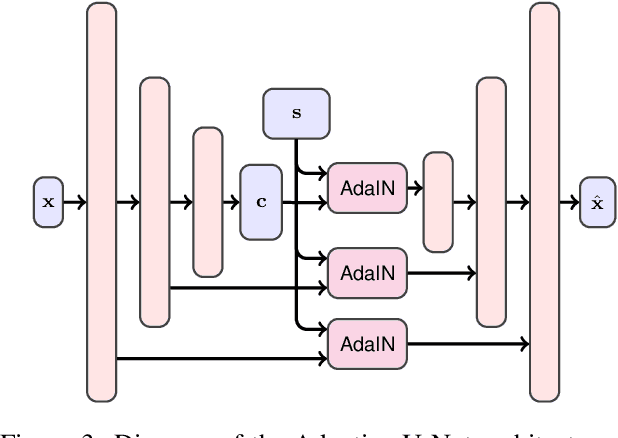
Modeling daytime changes in high resolution photographs, e.g., re-rendering the same scene under different illuminations typical for day, night, or dawn, is a challenging image manipulation task. We present the high-resolution daytime translation (HiDT) model for this task. HiDT combines a generative image-to-image model and a new upsampling scheme that allows to apply image translation at high resolution. The model demonstrates competitive results in terms of both commonly used GAN metrics and human evaluation. Importantly, this good performance comes as a result of training on a dataset of still landscape images with no daytime labels available. Our results are available at https://saic-mdal.github.io/HiDT/.
Light Field Reconstruction via Attention-Guided Deep Fusion of Hybrid Lenses
Feb 14, 2021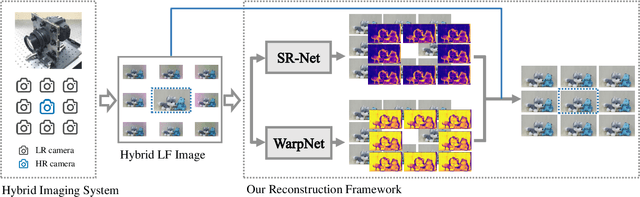
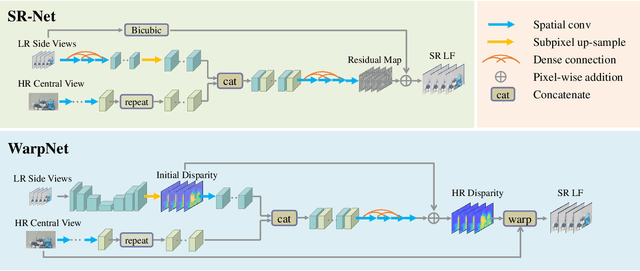
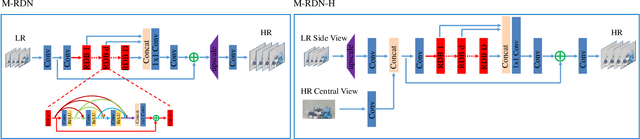

This paper explores the problem of reconstructing high-resolution light field (LF) images from hybrid lenses, including a high-resolution camera surrounded by multiple low-resolution cameras. The performance of existing methods is still limited, as they produce either blurry results on plain textured areas or distortions around depth discontinuous boundaries. To tackle this challenge, we propose a novel end-to-end learning-based approach, which can comprehensively utilize the specific characteristics of the input from two complementary and parallel perspectives. Specifically, one module regresses a spatially consistent intermediate estimation by learning a deep multidimensional and cross-domain feature representation, while the other module warps another intermediate estimation, which maintains the high-frequency textures, by propagating the information of the high-resolution view. We finally leverage the advantages of the two intermediate estimations adaptively via the learned attention maps, leading to the final high-resolution LF image with satisfactory results on both plain textured areas and depth discontinuous boundaries. Besides, to promote the effectiveness of our method trained with simulated hybrid data on real hybrid data captured by a hybrid LF imaging system, we carefully design the network architecture and the training strategy. Extensive experiments on both real and simulated hybrid data demonstrate the significant superiority of our approach over state-of-the-art ones. To the best of our knowledge, this is the first end-to-end deep learning method for LF reconstruction from a real hybrid input. We believe our framework could potentially decrease the cost of high-resolution LF data acquisition and benefit LF data storage and transmission.