 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLight Field Reconstruction via Attention-Guided Deep Fusion of Hybrid Lenses
Paper and Code
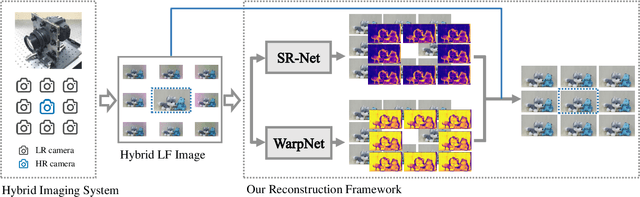
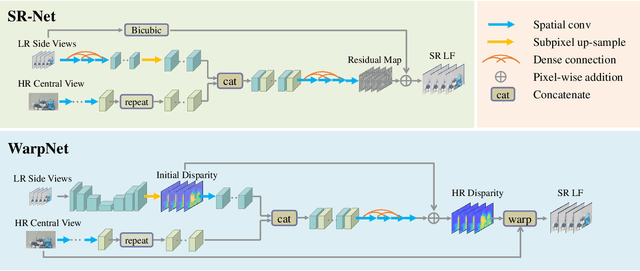
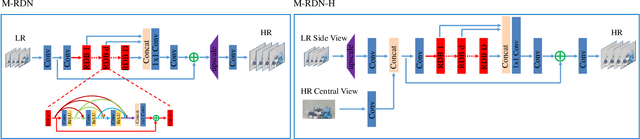

This paper explores the problem of reconstructing high-resolution light field (LF) images from hybrid lenses, including a high-resolution camera surrounded by multiple low-resolution cameras. The performance of existing methods is still limited, as they produce either blurry results on plain textured areas or distortions around depth discontinuous boundaries. To tackle this challenge, we propose a novel end-to-end learning-based approach, which can comprehensively utilize the specific characteristics of the input from two complementary and parallel perspectives. Specifically, one module regresses a spatially consistent intermediate estimation by learning a deep multidimensional and cross-domain feature representation, while the other module warps another intermediate estimation, which maintains the high-frequency textures, by propagating the information of the high-resolution view. We finally leverage the advantages of the two intermediate estimations adaptively via the learned attention maps, leading to the final high-resolution LF image with satisfactory results on both plain textured areas and depth discontinuous boundaries. Besides, to promote the effectiveness of our method trained with simulated hybrid data on real hybrid data captured by a hybrid LF imaging system, we carefully design the network architecture and the training strategy. Extensive experiments on both real and simulated hybrid data demonstrate the significant superiority of our approach over state-of-the-art ones. To the best of our knowledge, this is the first end-to-end deep learning method for LF reconstruction from a real hybrid input. We believe our framework could potentially decrease the cost of high-resolution LF data acquisition and benefit LF data storage and transmission.