 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePyramidalWan: On Making Pretrained Video Model Pyramidal for Efficient Inference
Jan 08, 2026Recently proposed pyramidal models decompose the conventional forward and backward diffusion processes into multiple stages operating at varying resolutions. These models handle inputs with higher noise levels at lower resolutions, while less noisy inputs are processed at higher resolutions. This hierarchical approach significantly reduces the computational cost of inference in multi-step denoising models. However, existing open-source pyramidal video models have been trained from scratch and tend to underperform compared to state-of-the-art systems in terms of visual plausibility. In this work, we present a pipeline that converts a pretrained diffusion model into a pyramidal one through low-cost finetuning, achieving this transformation without degradation in quality of output videos. Furthermore, we investigate and compare various strategies for step distillation within pyramidal models, aiming to further enhance the inference efficiency. Our results are available at https://qualcomm-ai-research.github.io/PyramidalWan.
Neodragon: Mobile Video Generation using Diffusion Transformer
Nov 08, 2025We introduce Neodragon, a text-to-video system capable of generating 2s (49 frames @24 fps) videos at the 640x1024 resolution directly on a Qualcomm Hexagon NPU in a record 6.7s (7 FPS). Differing from existing transformer-based offline text-to-video generation models, Neodragon is the first to have been specifically optimised for mobile hardware to achieve efficient and high-fidelity video synthesis. We achieve this through four key technical contributions: (1) Replacing the original large 4.762B T5xxl Text-Encoder with a much smaller 0.2B DT5 (DistilT5) with minimal quality loss, enabled through a novel Text-Encoder Distillation procedure. (2) Proposing an Asymmetric Decoder Distillation approach allowing us to replace the native codec-latent-VAE decoder with a more efficient one, without disturbing the generative latent-space of the generation pipeline. (3) Pruning of MMDiT blocks within the denoiser backbone based on their relative importance, with recovery of original performance through a two-stage distillation process. (4) Reducing the NFE (Neural Functional Evaluation) requirement of the denoiser by performing step distillation using DMD adapted for pyramidal flow-matching, thereby substantially accelerating video generation. When paired with an optimised SSD1B first-frame image generator and QuickSRNet for 2x super-resolution, our end-to-end Neodragon system becomes a highly parameter (4.945B full model), memory (3.5GB peak RAM usage), and runtime (6.7s E2E latency) efficient mobile-friendly model, while achieving a VBench total score of 81.61. By enabling low-cost, private, and on-device text-to-video synthesis, Neodragon democratizes AI-based video content creation, empowering creators to generate high-quality videos without reliance on cloud services. Code and model will be made publicly available at our website: https://qualcomm-ai-research.github.io/neodragon
MoAlign: Motion-Centric Representation Alignment for Video Diffusion Models
Oct 21, 2025Text-to-video diffusion models have enabled high-quality video synthesis, yet often fail to generate temporally coherent and physically plausible motion. A key reason is the models' insufficient understanding of complex motions that natural videos often entail. Recent works tackle this problem by aligning diffusion model features with those from pretrained video encoders. However, these encoders mix video appearance and dynamics into entangled features, limiting the benefit of such alignment. In this paper, we propose a motion-centric alignment framework that learns a disentangled motion subspace from a pretrained video encoder. This subspace is optimized to predict ground-truth optical flow, ensuring it captures true motion dynamics. We then align the latent features of a text-to-video diffusion model to this new subspace, enabling the generative model to internalize motion knowledge and generate more plausible videos. Our method improves the physical commonsense in a state-of-the-art video diffusion model, while preserving adherence to textual prompts, as evidenced by empirical evaluations on VideoPhy, VideoPhy2, VBench, and VBench-2.0, along with a user study.
Mobile Video Diffusion
Dec 10, 2024



Video diffusion models have achieved impressive realism and controllability but are limited by high computational demands, restricting their use on mobile devices. This paper introduces the first mobile-optimized video diffusion model. Starting from a spatio-temporal UNet from Stable Video Diffusion (SVD), we reduce memory and computational cost by reducing the frame resolution, incorporating multi-scale temporal representations, and introducing two novel pruning schema to reduce the number of channels and temporal blocks. Furthermore, we employ adversarial finetuning to reduce the denoising to a single step. Our model, coined as MobileVD, is 523x more efficient (1817.2 vs. 4.34 TFLOPs) with a slight quality drop (FVD 149 vs. 171), generating latents for a 14x512x256 px clip in 1.7 seconds on a Xiaomi-14 Pro. Our results are available at https://qualcomm-ai-research.github.io/mobile-video-diffusion/
On Sampling Strategies for Spectral Model Sharding
Oct 31, 2024



The problem of heterogeneous clients in federated learning has recently drawn a lot of attention. Spectral model sharding, i.e., partitioning the model parameters into low-rank matrices based on the singular value decomposition, has been one of the proposed solutions for more efficient on-device training in such settings. In this work, we present two sampling strategies for such sharding, obtained as solutions to specific optimization problems. The first produces unbiased estimators of the original weights, while the second aims to minimize the squared approximation error. We discuss how both of these estimators can be incorporated in the federated learning loop and practical considerations that arise during local training. Empirically, we demonstrate that both of these methods can lead to improved performance on various commonly used datasets.
A Mutual Information Perspective on Federated Contrastive Learning
May 03, 2024



We investigate contrastive learning in the federated setting through the lens of SimCLR and multi-view mutual information maximization. In doing so, we uncover a connection between contrastive representation learning and user verification; by adding a user verification loss to each client's local SimCLR loss we recover a lower bound to the global multi-view mutual information. To accommodate for the case of when some labelled data are available at the clients, we extend our SimCLR variant to the federated semi-supervised setting. We see that a supervised SimCLR objective can be obtained with two changes: a) the contrastive loss is computed between datapoints that share the same label and b) we require an additional auxiliary head that predicts the correct labels from either of the two views. Along with the proposed SimCLR extensions, we also study how different sources of non-i.i.d.-ness can impact the performance of federated unsupervised learning through global mutual information maximization; we find that a global objective is beneficial for some sources of non-i.i.d.-ness but can be detrimental for others. We empirically evaluate our proposed extensions in various tasks to validate our claims and furthermore demonstrate that our proposed modifications generalize to other pretraining methods.
Self-improving Multiplane-to-layer Images for Novel View Synthesis
Oct 04, 2022
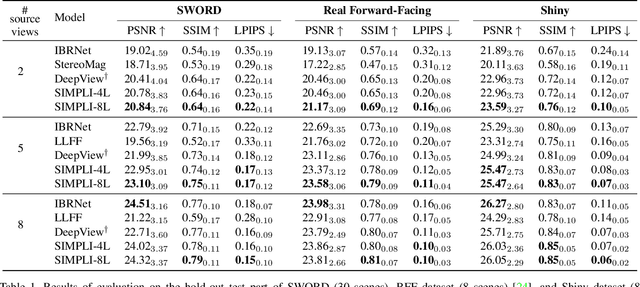
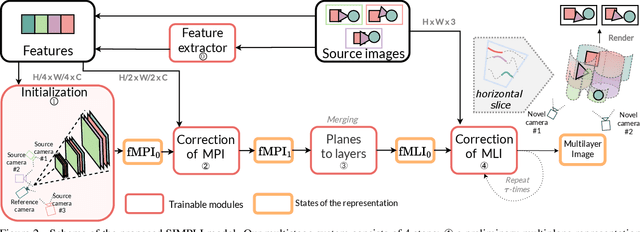
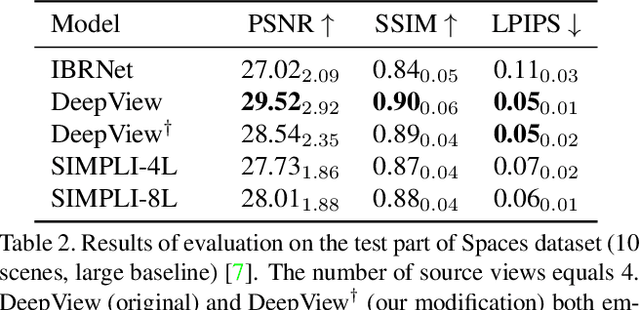
We present a new method for lightweight novel-view synthesis that generalizes to an arbitrary forward-facing scene. Recent approaches are computationally expensive, require per-scene optimization, or produce a memory-expensive representation. We start by representing the scene with a set of fronto-parallel semitransparent planes and afterward convert them to deformable layers in an end-to-end manner. Additionally, we employ a feed-forward refinement procedure that corrects the estimated representation by aggregating information from input views. Our method does not require fine-tuning when a new scene is processed and can handle an arbitrary number of views without restrictions. Experimental results show that our approach surpasses recent models in terms of common metrics and human evaluation, with the noticeable advantage in inference speed and compactness of the inferred layered geometry, see https://samsunglabs.github.io/MLI
Stereo Magnification with Multi-Layer Images
Jan 13, 2022
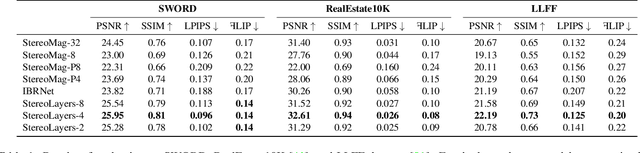

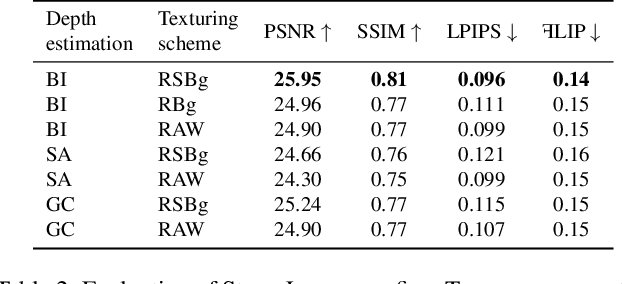
Representing scenes with multiple semi-transparent colored layers has been a popular and successful choice for real-time novel view synthesis. Existing approaches infer colors and transparency values over regularly-spaced layers of planar or spherical shape. In this work, we introduce a new view synthesis approach based on multiple semi-transparent layers with scene-adapted geometry. Our approach infers such representations from stereo pairs in two stages. The first stage infers the geometry of a small number of data-adaptive layers from a given pair of views. The second stage infers the color and the transparency values for these layers producing the final representation for novel view synthesis. Importantly, both stages are connected through a differentiable renderer and are trained in an end-to-end manner. In the experiments, we demonstrate the advantage of the proposed approach over the use of regularly-spaced layers with no adaptation to scene geometry. Despite being orders of magnitude faster during rendering, our approach also outperforms a recently proposed IBRNet system based on implicit geometry representation. See results at https://samsunglabs.github.io/StereoLayers .
Image Generators with Conditionally-Independent Pixel Synthesis
Nov 27, 2020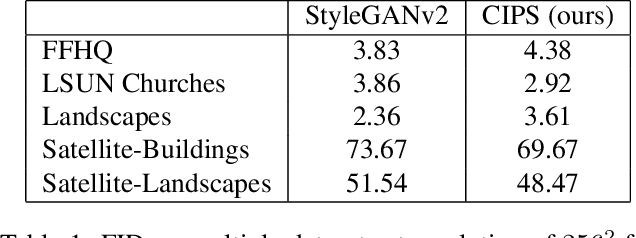
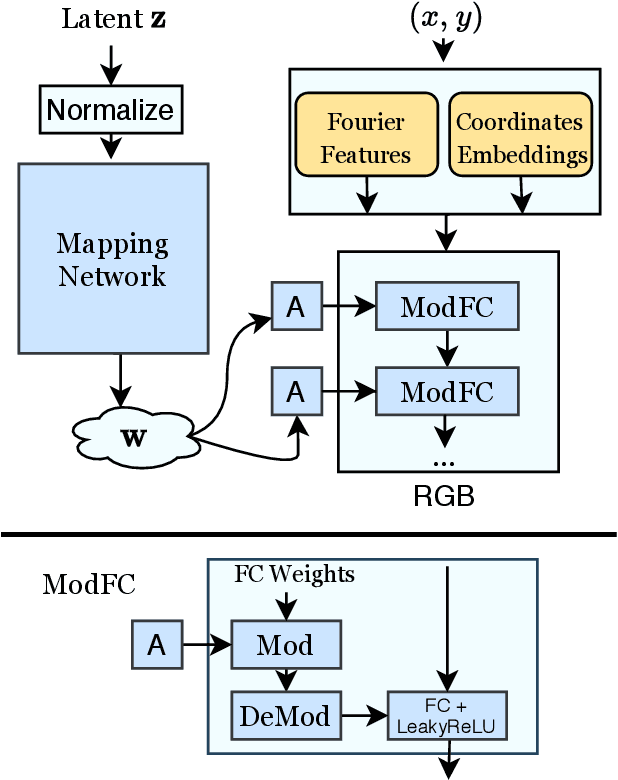
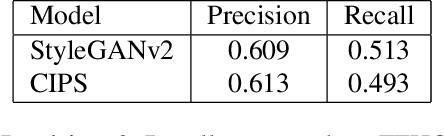
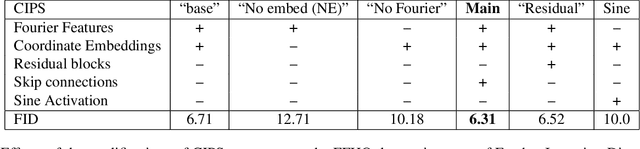
Existing image generator networks rely heavily on spatial convolutions and, optionally, self-attention blocks in order to gradually synthesize images in a coarse-to-fine manner. Here, we present a new architecture for image generators, where the color value at each pixel is computed independently given the value of a random latent vector and the coordinate of that pixel. No spatial convolutions or similar operations that propagate information across pixels are involved during the synthesis. We analyze the modeling capabilities of such generators when trained in an adversarial fashion, and observe the new generators to achieve similar generation quality to state-of-the-art convolutional generators. We also investigate several interesting properties unique to the new architecture.
High-Resolution Daytime Translation Without Domain Labels
Mar 23, 2020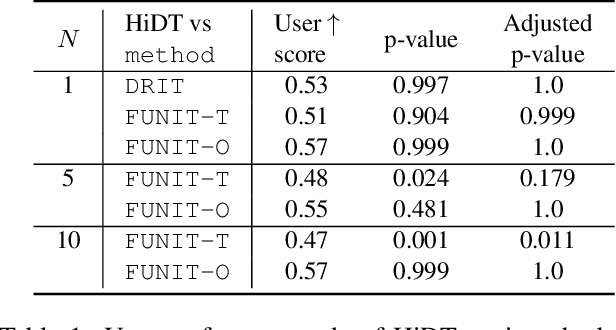
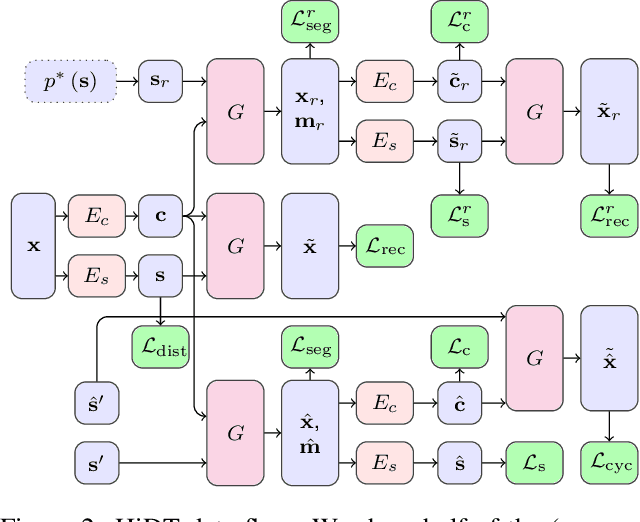
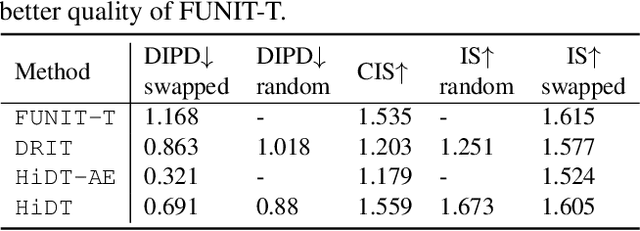
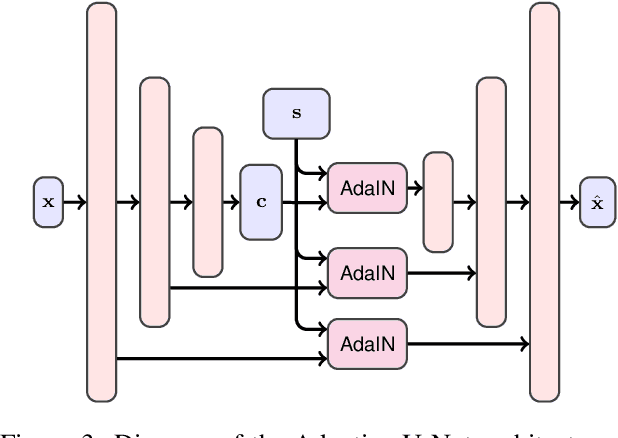
Modeling daytime changes in high resolution photographs, e.g., re-rendering the same scene under different illuminations typical for day, night, or dawn, is a challenging image manipulation task. We present the high-resolution daytime translation (HiDT) model for this task. HiDT combines a generative image-to-image model and a new upsampling scheme that allows to apply image translation at high resolution. The model demonstrates competitive results in terms of both commonly used GAN metrics and human evaluation. Importantly, this good performance comes as a result of training on a dataset of still landscape images with no daytime labels available. Our results are available at https://saic-mdal.github.io/HiDT/.