 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Supervised Learning of Sparsity-Promoting Regularizers for Denoising
Jun 09, 2020

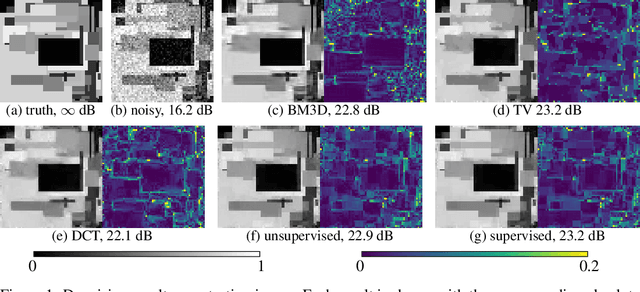
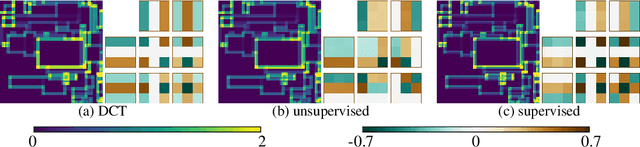
We present a method for supervised learning of sparsity-promoting regularizers for image denoising. Sparsity-promoting regularization is a key ingredient in solving modern image reconstruction problems; however, the operators underlying these regularizers are usually either designed by hand or learned from data in an unsupervised way. The recent success of supervised learning (mainly convolutional neural networks) in solving image reconstruction problems suggests that it could be a fruitful approach to designing regularizers. As a first experiment in this direction, we propose to denoise images using a variational formulation with a parametric, sparsity-promoting regularizer, where the parameters of the regularizer are learned to minimize the mean squared error of reconstructions on a training set of (ground truth image, measurement) pairs. Training involves solving a challenging bilievel optimization problem; we derive an expression for the gradient of the training loss using Karush-Kuhn-Tucker conditions and provide an accompanying gradient descent algorithm to minimize it. Our experiments on a simple synthetic, denoising problem show that the proposed method can learn an operator that outperforms well-known regularizers (total variation, DCT-sparsity, and unsupervised dictionary learning) and collaborative filtering. While the approach we present is specific to denoising, we believe that it can be adapted to the whole class of inverse problems with linear measurement models, giving it applicability to a wide range of image reconstruction problems.
Harnessing Uncertainty in Domain Adaptation for MRI Prostate Lesion Segmentation
Oct 14, 2020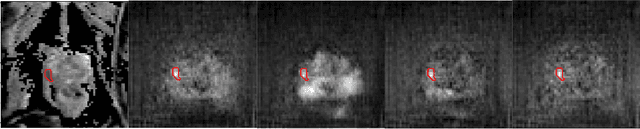
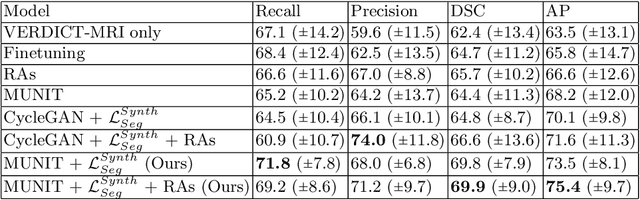
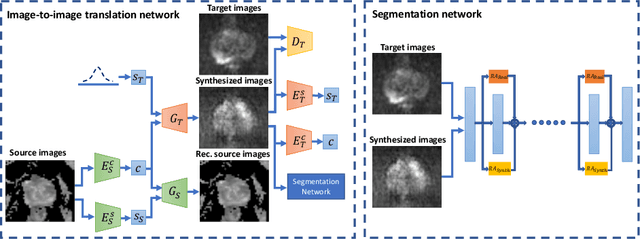
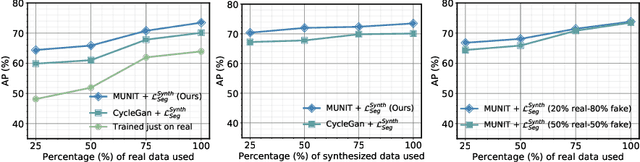
The need for training data can impede the adoption of novel imaging modalities for learning-based medical image analysis. Domain adaptation methods partially mitigate this problem by translating training data from a related source domain to a novel target domain, but typically assume that a one-to-one translation is possible. Our work addresses the challenge of adapting to a more informative target domain where multiple target samples can emerge from a single source sample. In particular we consider translating from mp-MRI to VERDICT, a richer MRI modality involving an optimized acquisition protocol for cancer characterization. We explicitly account for the inherent uncertainty of this mapping and exploit it to generate multiple outputs conditioned on a single input. Our results show that this allows us to extract systematically better image representations for the target domain, when used in tandem with both simple, CycleGAN-based baselines, as well as more powerful approaches that integrate discriminative segmentation losses and/or residual adapters. When compared to its deterministic counterparts, our approach yields substantial improvements across a broad range of dataset sizes, increasingly strong baselines, and evaluation measures.
Voronoi Region-Based Adaptive Unsupervised Color Image Segmentation
Apr 02, 2016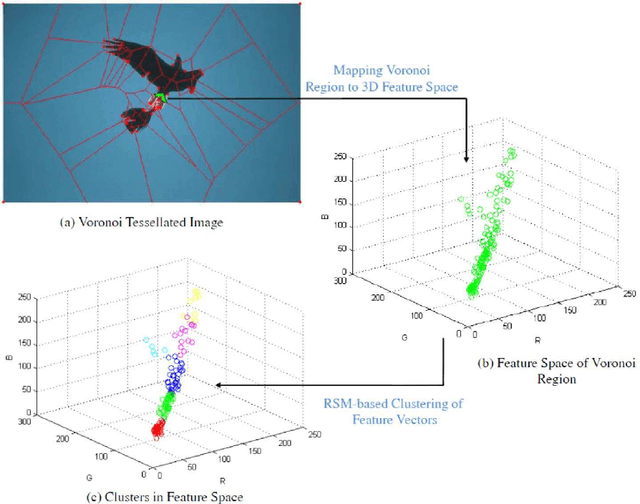
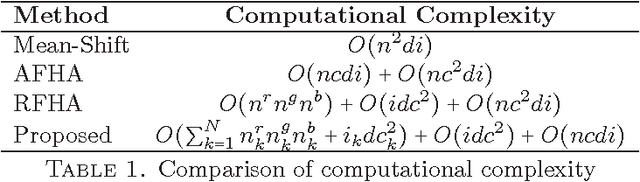
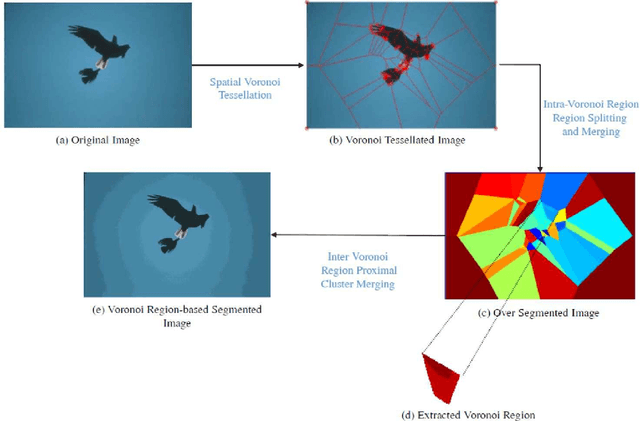
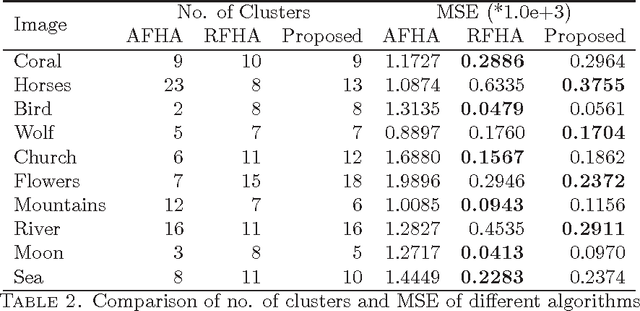
Color image segmentation is a crucial step in many computer vision and pattern recognition applications. This article introduces an adaptive and unsupervised clustering approach based on Voronoi regions, which can be applied to solve the color image segmentation problem. The proposed method performs region splitting and merging within Voronoi regions of the Dirichlet Tessellated image (also called a Voronoi diagram) , which improves the efficiency and the accuracy of the number of clusters and cluster centroids estimation process. Furthermore, the proposed method uses cluster centroid proximity to merge proximal clusters in order to find the final number of clusters and cluster centroids. In contrast to the existing adaptive unsupervised cluster-based image segmentation algorithms, the proposed method uses K-means clustering algorithm in place of the Fuzzy C-means algorithm to find the final segmented image. The proposed method was evaluated on three different unsupervised image segmentation evaluation benchmarks and its results were compared with two other adaptive unsupervised cluster-based image segmentation algorithms. The experimental results reported in this article confirm that the proposed method outperforms the existing algorithms in terms of the quality of image segmentation results. Also, the proposed method results in the lowest average execution time per image compared to the existing methods reported in this article.
Deep Neural Network for Fast and Accurate Single Image Super-Resolution via Channel-Attention-based Fusion of Orientation-aware Features
Dec 09, 2019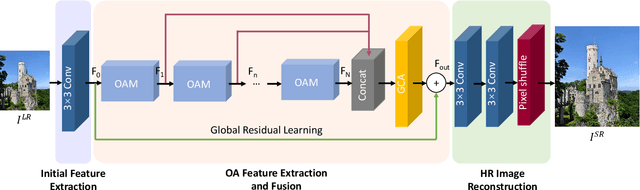


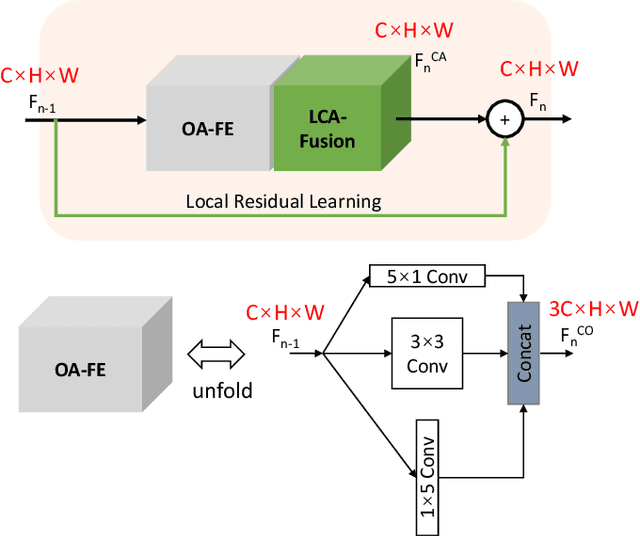
Recently, Convolutional Neural Networks (CNNs) have been successfully adopted to solve the ill-posed single image super-resolution (SISR) problem. A commonly used strategy to boost the performance of CNN-based SISR models is deploying very deep networks, which inevitably incurs many obvious drawbacks (e.g., a large number of network parameters, heavy computational loads, and difficult model training). In this paper, we aim to build more accurate and faster SISR models via developing better-performing feature extraction and fusion techniques. Firstly, we proposed a novel Orientation-Aware feature extraction and fusion Module (OAM), which contains a mixture of 1D and 2D convolutional kernels (i.e., 5 x 1, 1 x 5, and 3 x 3) for extracting orientation-aware features. Secondly, we adopt the channel attention mechanism as an effective technique to adaptively fuse features extracted in different directions and in hierarchically stacked convolutional stages. Based on these two important improvements, we present a compact but powerful CNN-based model for high-quality SISR via Channel Attention-based fusion of Orientation-Aware features (SISR-CA-OA). Extensive experimental results verify the superiority of the proposed SISR-CA-OA model, performing favorably against the state-of-the-art SISR models in terms of both restoration accuracy and computational efficiency. The source codes will be made publicly available.
IntroVAC: Introspective Variational Classifiers for Learning Interpretable Latent Subspaces
Sep 14, 2020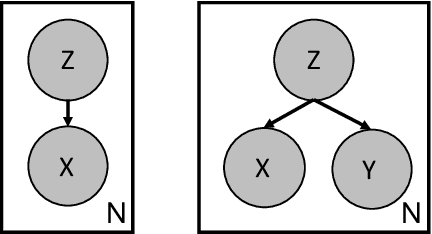

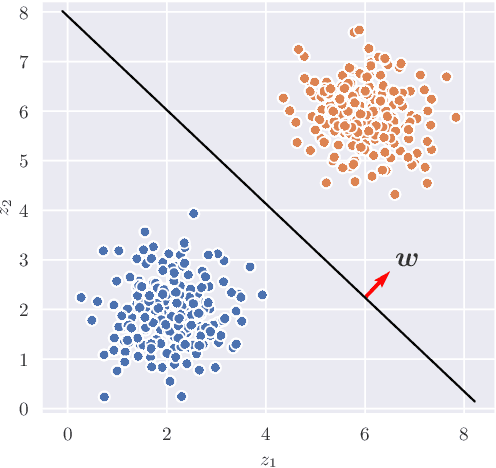

Learning useful representations of complex data has been the subject of extensive research for many years. With the diffusion of Deep Neural Networks, Variational Autoencoders have gained lots of attention since they provide an explicit model of the data distribution based on an encoder/decoder architecture which is able to both generate images and encode them in a low-dimensional subspace. However, the latent space is not easily interpretable and the generation capabilities show some limitations since images typically look blurry and lack details. In this paper, we propose the Introspective Variational Classifier (IntroVAC), a model that learns interpretable latent subspaces by exploiting information from an additional label and provides improved image quality thanks to an adversarial training strategy.We show that IntroVAC is able to learn meaningful directions in the latent space enabling fine-grained manipulation of image attributes. We validate our approach on the CelebA dataset.
Objectron: A Large Scale Dataset of Object-Centric Videos in the Wild with Pose Annotations
Dec 18, 2020

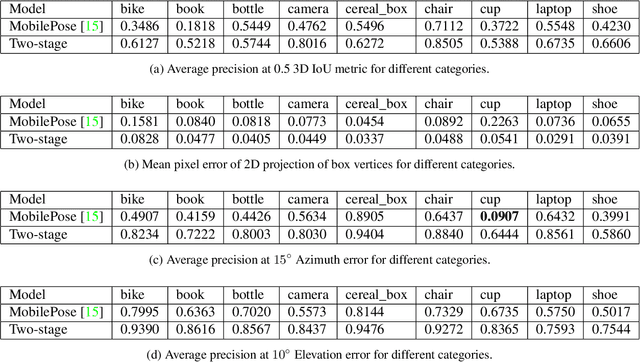
3D object detection has recently become popular due to many applications in robotics, augmented reality, autonomy, and image retrieval. We introduce the Objectron dataset to advance the state of the art in 3D object detection and foster new research and applications, such as 3D object tracking, view synthesis, and improved 3D shape representation. The dataset contains object-centric short videos with pose annotations for nine categories and includes 4 million annotated images in 14,819 annotated videos. We also propose a new evaluation metric, 3D Intersection over Union, for 3D object detection. We demonstrate the usefulness of our dataset in 3D object detection tasks by providing baseline models trained on this dataset. Our dataset and evaluation source code are available online at http://www.objectron.dev
Deep Generative Model-based Quality Control for Cardiac MRI Segmentation
Jun 23, 2020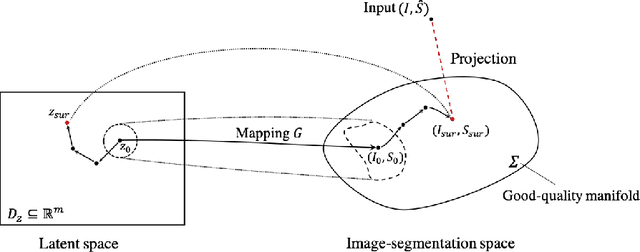
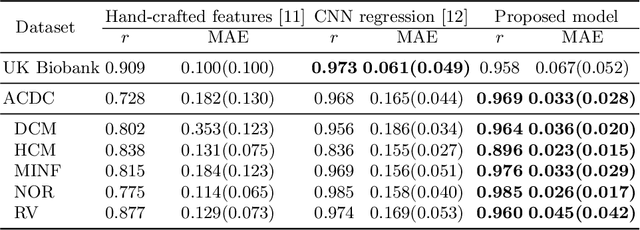
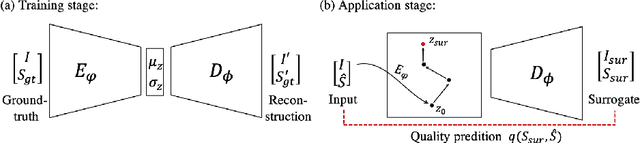
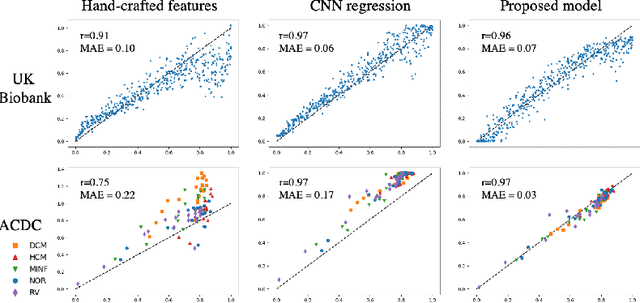
In recent years, convolutional neural networks have demonstrated promising performance in a variety of medical image segmentation tasks. However, when a trained segmentation model is deployed into the real clinical world, the model may not perform optimally. A major challenge is the potential poor-quality segmentations generated due to degraded image quality or domain shift issues. There is a timely need to develop an automated quality control method that can detect poor segmentations and feedback to clinicians. Here we propose a novel deep generative model-based framework for quality control of cardiac MRI segmentation. It first learns a manifold of good-quality image-segmentation pairs using a generative model. The quality of a given test segmentation is then assessed by evaluating the difference from its projection onto the good-quality manifold. In particular, the projection is refined through iterative search in the latent space. The proposed method achieves high prediction accuracy on two publicly available cardiac MRI datasets. Moreover, it shows better generalisation ability than traditional regression-based methods. Our approach provides a real-time and model-agnostic quality control for cardiac MRI segmentation, which has the potential to be integrated into clinical image analysis workflows.
Accelerating Deep Learning Applications in Space
Jul 21, 2020
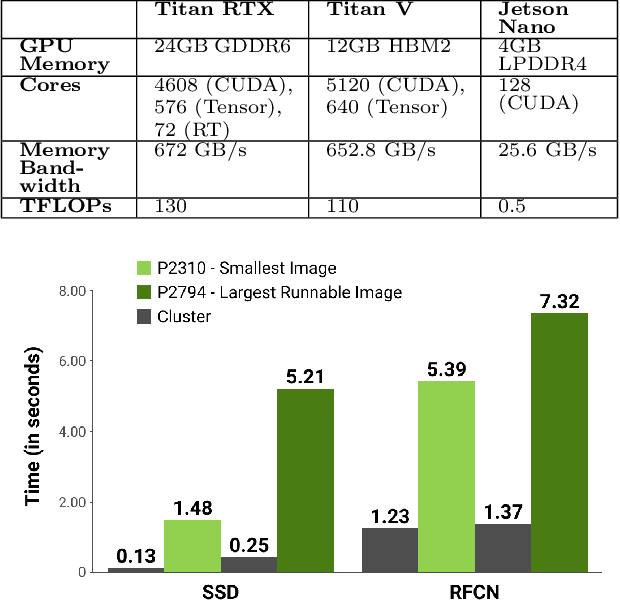

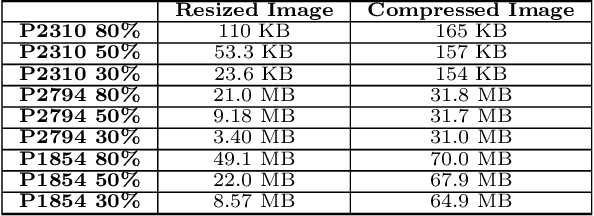
Computing at the edge offers intriguing possibilities for the development of autonomy and artificial intelligence. The advancements in autonomous technologies and the resurgence of computer vision have led to a rise in demand for fast and reliable deep learning applications. In recent years, the industry has introduced devices with impressive processing power to perform various object detection tasks. However, with real-time detection, devices are constrained in memory, computational capacity, and power, which may compromise the overall performance. This could be solved either by optimizing the object detector or modifying the images. In this paper, we investigate the performance of CNN-based object detectors on constrained devices when applying different image compression techniques. We examine the capabilities of a NVIDIA Jetson Nano; a low-power, high-performance computer, with an integrated GPU, small enough to fit on-board a CubeSat. We take a closer look at the Single Shot MultiBox Detector (SSD) and Region-based Fully Convolutional Network (R-FCN) that are pre-trained on DOTA - a Large Scale Dataset for Object Detection in Aerial Images. The performance is measured in terms of inference time, memory consumption, and accuracy. By applying image compression techniques, we are able to optimize performance. The two techniques applied, lossless compression and image scaling, improves speed and memory consumption with no or little change in accuracy. The image scaling technique achieves a 100% runnable dataset and we suggest combining both techniques in order to optimize the speed/memory/accuracy trade-off.
Learning Large Euclidean Margin for Sketch-based Image Retrieval
Dec 11, 2018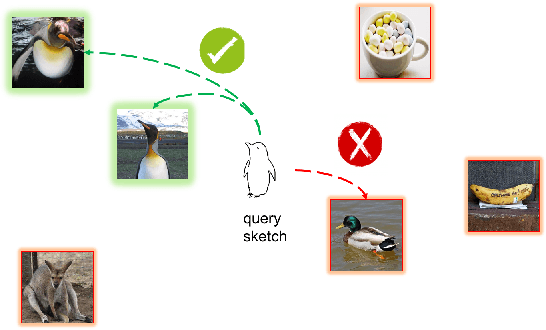
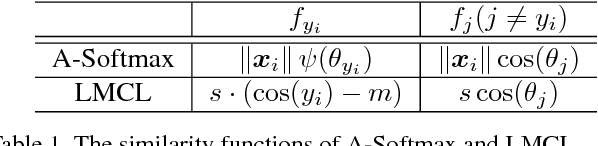
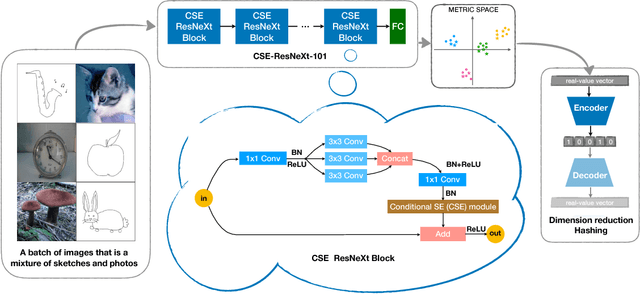
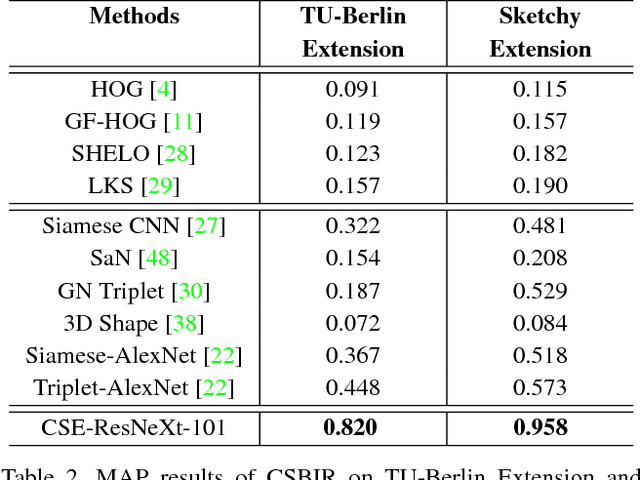
This paper addresses the problem of Sketch-Based Image Retrieval (SBIR), for which bridge the gap between the data representations of sketch images and photo images is considered as the key. Previous works mostly focus on learning a feature space to minimize intra-class distances for both sketches and photos. In contrast, we propose a novel loss function, named Euclidean Margin Softmax (EMS), that not only minimizes intra-class distances but also maximizes inter-class distances simultaneously. It enables us to learn a feature space with high discriminability, leading to highly accurate retrieval. In addition, this loss function is applied to a conditional network architecture, which could incorporate the prior knowledge of whether a sample is a sketch or a photo. We show that the conditional information can be conveniently incorporated to the recently proposed Squeeze and Excitation (SE) module, lead to a conditional SE (CSE) module. Extensive experiments are conducted on two widely used SBIR benchmark datasets. Our approach, although being very simple, achieved new state-of-the-art on both datasets, surpassing existing methods by a large margin.
Detecting the Presence of Vehicles and Equipment in SAR Imagery Using Image Texture Features
Sep 10, 2020


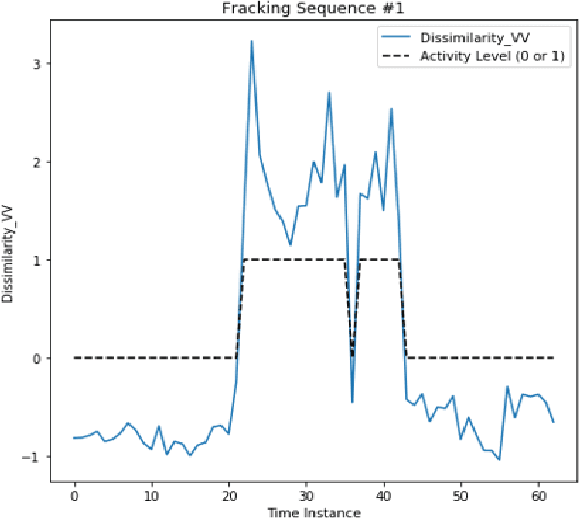
In this work, we present a methodology for monitoring man-made, construction-like activities in low-resolution SAR imagery. Our source of data is the European Space Agency Sentinel-l satellite which provides global coverage at a 12-day revisit rate. Despite limitations in resolution, our methodology enables us to monitor activity levels (i.e. presence of vehicles, equipment) of a pre-defined location by analyzing the texture of detected SAR imagery. Using an exploratory dataset, we trained a support vector machine (SVM), a random binary forest, and a fully-connected neural network for classification. We use Haralick texture features in the VV and VH polarization channels as the input features to our classifiers. Each classifier showed promising results in being able to distinguish between two possible types of construction-site activity levels. This paper documents a case study that is centered around monitoring the construction process for oil and gas fracking wells.
* 6 pages, 6 figures, 2019 IEEE Applied Imagery Pattern Recognition Workshop (AIPR)