 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Data Processing in Space for Object Detection in Satellite Imagery
Jul 08, 2021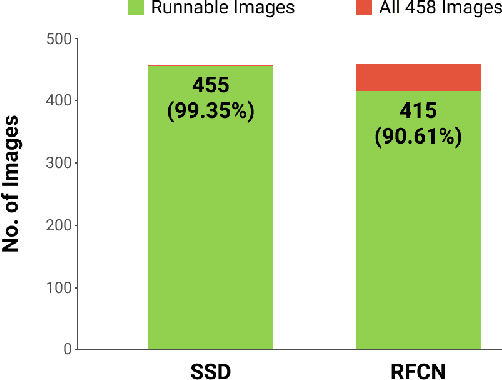

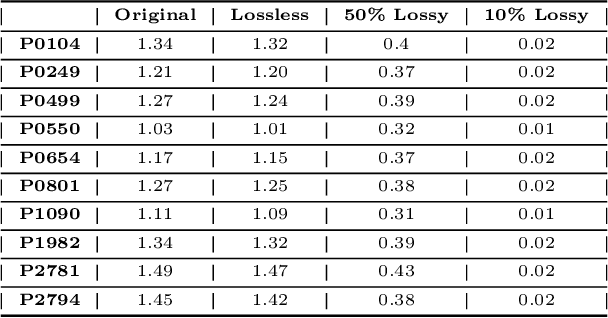

There is a proliferation in the number of satellites launched each year, resulting in downlinking of terabytes of data each day. The data received by ground stations is often unprocessed, making this an expensive process considering the large data sizes and that not all of the data is useful. This, coupled with the increasing demand for real-time data processing, has led to a growing need for on-orbit processing solutions. In this work, we investigate the performance of CNN-based object detectors on constrained devices by applying different image compression techniques to satellite data. We examine the capabilities of the NVIDIA Jetson Nano and NVIDIA Jetson AGX Xavier; low-power, high-performance computers, with integrated GPUs, small enough to fit on-board a nanosatellite. We take a closer look at object detection networks, including the Single Shot MultiBox Detector (SSD) and Region-based Fully Convolutional Network (R-FCN) models that are pre-trained on DOTA - a Large Scale Dataset for Object Detection in Aerial Images. The performance is measured in terms of execution time, memory consumption, and accuracy, and are compared against a baseline containing a server with two powerful GPUs. The results show that by applying image compression techniques, we are able to improve the execution time and memory consumption, achieving a fully runnable dataset. A lossless compression technique achieves roughly a 10% reduction in execution time and about a 3% reduction in memory consumption, with no impact on the accuracy. While a lossy compression technique improves the execution time by up to 144% and the memory consumption is reduced by as much as 97%. However, it has a significant impact on accuracy, varying depending on the compression ratio. Thus the application and ratio of these compression techniques may differ depending on the required level of accuracy for a particular task.
Accelerating Deep Learning Applications in Space
Jul 21, 2020
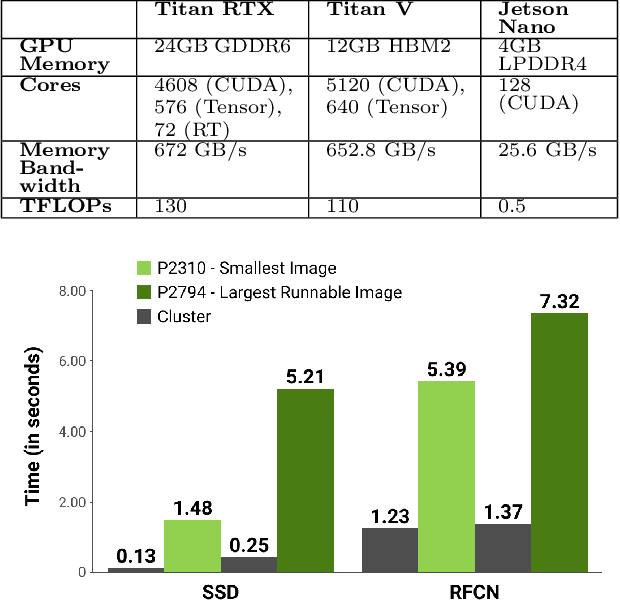

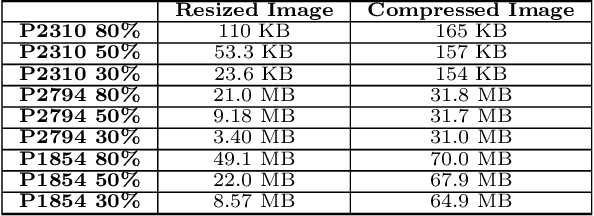
Computing at the edge offers intriguing possibilities for the development of autonomy and artificial intelligence. The advancements in autonomous technologies and the resurgence of computer vision have led to a rise in demand for fast and reliable deep learning applications. In recent years, the industry has introduced devices with impressive processing power to perform various object detection tasks. However, with real-time detection, devices are constrained in memory, computational capacity, and power, which may compromise the overall performance. This could be solved either by optimizing the object detector or modifying the images. In this paper, we investigate the performance of CNN-based object detectors on constrained devices when applying different image compression techniques. We examine the capabilities of a NVIDIA Jetson Nano; a low-power, high-performance computer, with an integrated GPU, small enough to fit on-board a CubeSat. We take a closer look at the Single Shot MultiBox Detector (SSD) and Region-based Fully Convolutional Network (R-FCN) that are pre-trained on DOTA - a Large Scale Dataset for Object Detection in Aerial Images. The performance is measured in terms of inference time, memory consumption, and accuracy. By applying image compression techniques, we are able to optimize performance. The two techniques applied, lossless compression and image scaling, improves speed and memory consumption with no or little change in accuracy. The image scaling technique achieves a 100% runnable dataset and we suggest combining both techniques in order to optimize the speed/memory/accuracy trade-off.