 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning to Amend Facial Expression Representation via De-albino and Affinity
Mar 18, 2021


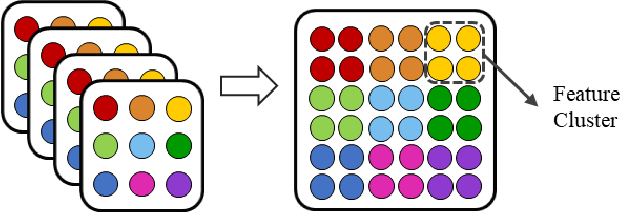

Facial Expression Recognition (FER) is a classification task that points to face variants. Hence, there are certain intimate relationships between facial expressions. We call them affinity features, which are barely taken into account by current FER algorithms. Besides, to capture the edge information of the image, Convolutional Neural Networks (CNNs) generally utilize a host of edge paddings. Although they are desirable, the feature map is deeply eroded after multi-layer convolution. We name what has formed in this process the albino features, which definitely weaken the representation of the expression. To tackle these challenges, we propose a novel architecture named Amend Representation Module (ARM). ARM is a substitute for the pooling layer. Theoretically, it could be embedded in any CNN with a pooling layer. ARM efficiently enhances facial expression representation from two different directions: 1) reducing the weight of eroded features to offset the side effect of padding, and 2) sharing affinity features over mini-batch to strengthen the representation learning. In terms of data imbalance, we designed a minimal random resampling (MRR) scheme to suppress network overfitting. Experiments on public benchmarks prove that our ARM boosts the performance of FER remarkably. The validation accuracies are respectively 90.55% on RAF-DB, 64.49% on Affect-Net, and 71.38% on FER2013, exceeding current state-of-the-art methods.
Fine-grained Visual Textual Alignment for Cross-Modal Retrieval using Transformer Encoders
Aug 12, 2020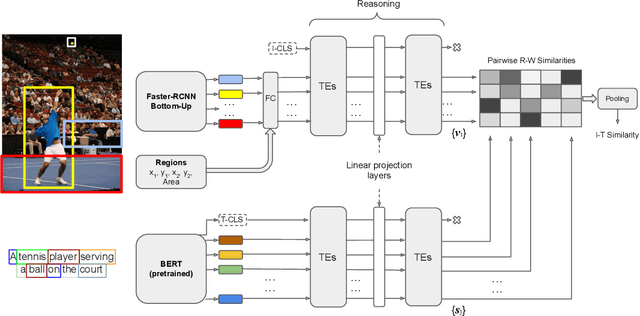
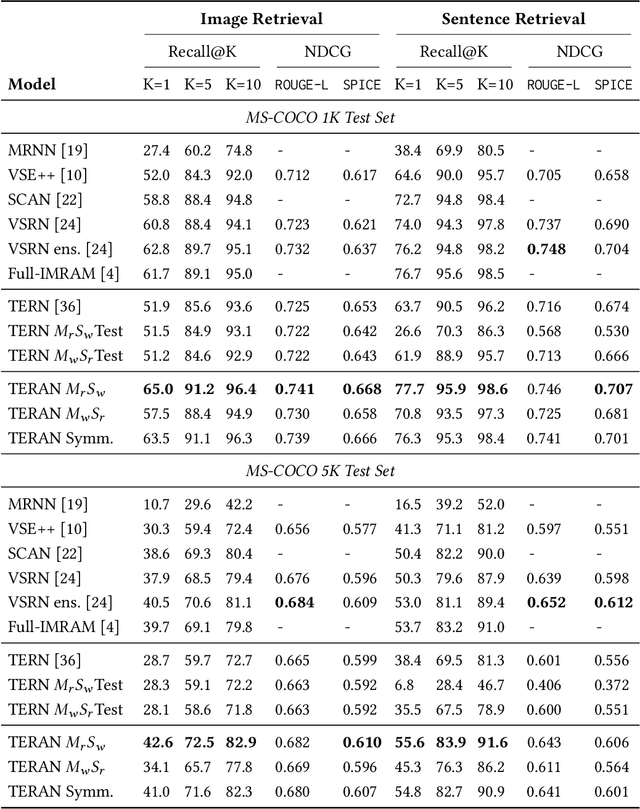
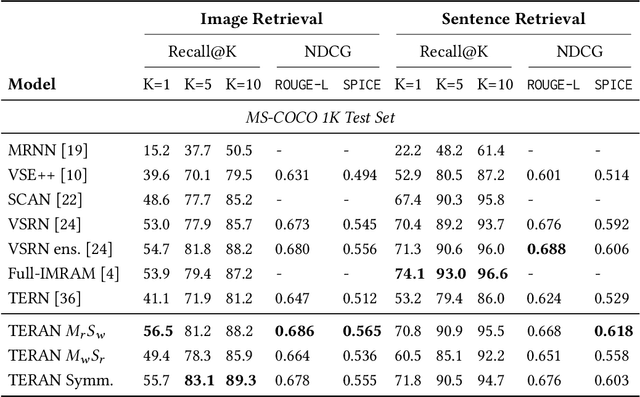

Despite the evolution of deep-learning-based visual-textual processing systems, precise multi-modal matching remains a challenging task. In this work, we tackle the problem of accurate cross-media retrieval through image-sentence matching based on word-region alignments using supervision only at the global image-sentence level. In particular, we present an approach called Transformer Encoder Reasoning and Alignment Network (TERAN). TERAN enforces a fine-grained match between the underlying components of images and sentences, i.e., image regions and words, respectively, in order to preserve the informative richness of both modalities. The proposed approach obtains state-of-the-art results on the image retrieval task on both MS-COCO and Flickr30k. Moreover, on MS-COCO, it defeats current approaches also on the sentence retrieval task. Given our long-term interest in scalable cross-modal information retrieval, TERAN is designed to keep the visual and textual data pipelines well separated. In fact, cross-attention links invalidate any chance to separately extract visual and textual features needed for the online search and the offline indexing steps in large-scale retrieval systems. In this respect, TERAN merges the information from the two domains only during the final alignment phase, immediately before the loss computation. We argue that the fine-grained alignments produced by TERAN pave the way towards the research for effective and efficient methods for large-scale cross-modal information retrieval. We compare the effectiveness of our approach against the best eight methods in this research area. On the MS-COCO 1K test set, we obtain an improvement of 3.5% and 1.2% respectively on the image and the sentence retrieval tasks on the Recall@1 metric. The code used for the experiments is publicly available on GitHub at https://github.com/mesnico/TERAN.
Real-time Localized Photorealistic Video Style Transfer
Oct 20, 2020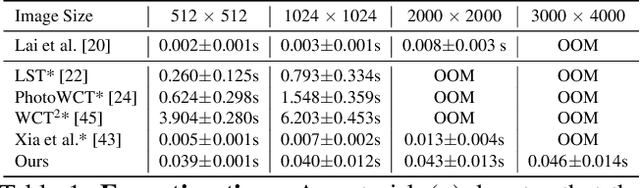
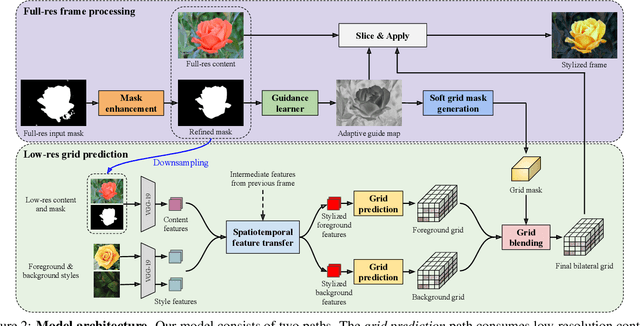
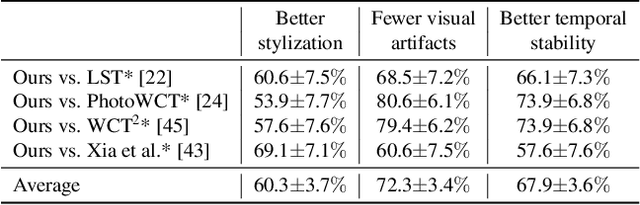

We present a novel algorithm for transferring artistic styles of semantically meaningful local regions of an image onto local regions of a target video while preserving its photorealism. Local regions may be selected either fully automatically from an image, through using video segmentation algorithms, or from casual user guidance such as scribbles. Our method, based on a deep neural network architecture inspired by recent work in photorealistic style transfer, is real-time and works on arbitrary inputs without runtime optimization once trained on a diverse dataset of artistic styles. By augmenting our video dataset with noisy semantic labels and jointly optimizing over style, content, mask, and temporal losses, our method can cope with a variety of imperfections in the input and produce temporally coherent videos without visual artifacts. We demonstrate our method on a variety of style images and target videos, including the ability to transfer different styles onto multiple objects simultaneously, and smoothly transition between styles in time.
On evaluating CNN representations for low resource medical image classification
Mar 26, 2019

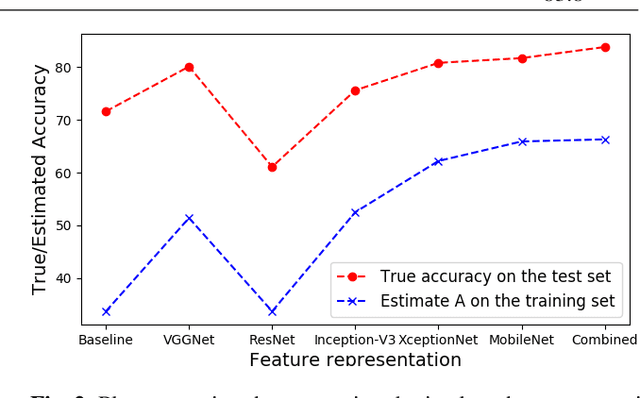
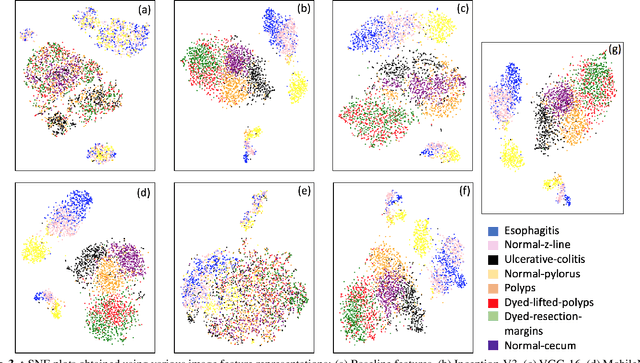
Convolutional Neural Networks (CNNs) have revolutionized performances in several machine learning tasks such as image classification, object tracking, and keyword spotting. However, given that they contain a large number of parameters, their direct applicability into low resource tasks is not straightforward. In this work, we experiment with an application of CNN models to gastrointestinal landmark classification with only a few thousands of training samples through transfer learning. As in a standard transfer learning approach, we train CNNs on a large external corpus, followed by representation extraction for the medical images. Finally, a classifier is trained on these CNN representations. However, given that several variants of CNNs exist, the choice of CNN is not obvious. To address this, we develop a novel metric that can be used to predict test performances, given CNN representations on the training set. Not only we demonstrate the superiority of the CNN based transfer learning approach against an assembly of knowledge driven features, but the proposed metric also carries an 87% correlation with the test set performances as obtained using various CNN representations.
Interactive Learning for Semantic Segmentation in Earth Observation
Sep 23, 2020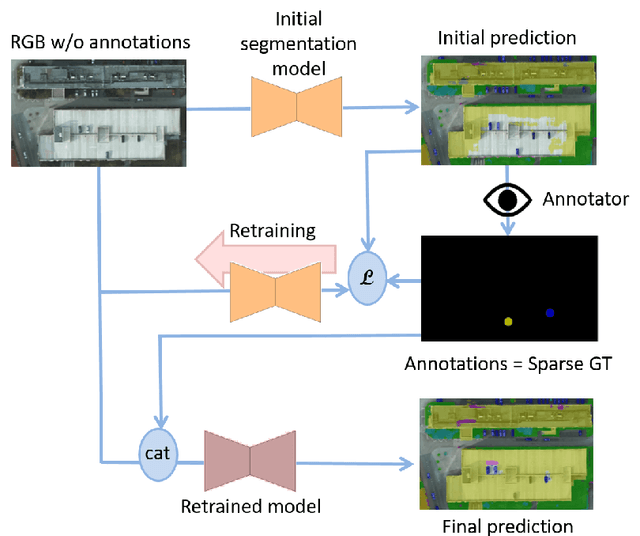


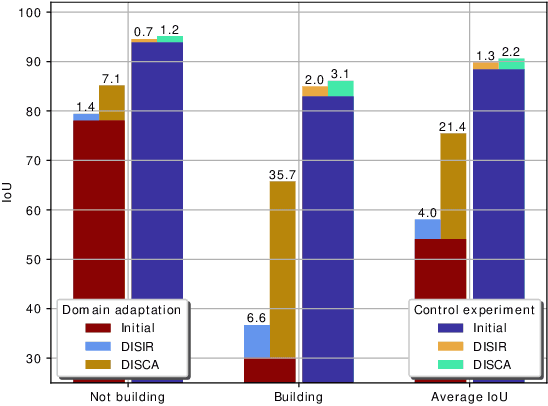
Dense pixel-wise classification maps output by deep neural networks are of extreme importance for scene understanding. However, these maps are often partially inaccurate due to a variety of possible factors. Therefore, we propose to interactively refine them within a framework named DISCA (Deep Image Segmentation with Continual Adaptation). It consists of continually adapting a neural network to a target image using an interactive learning process with sparse user annotations as ground-truth. We show through experiments on three datasets using synthesized annotations the benefits of the approach, reaching an IoU improvement up to 4.7% for ten sampled clicks. Finally, we exhibit that our approach can be particularly rewarding when it is faced to additional issues such as domain adaptation.
Interpreting Super-Resolution Networks with Local Attribution Maps
Nov 22, 2020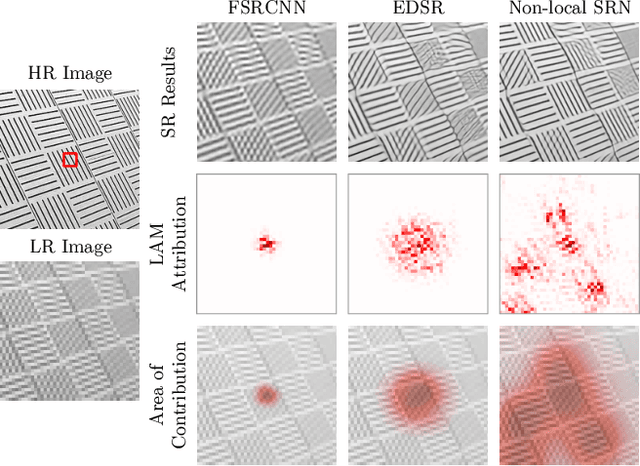
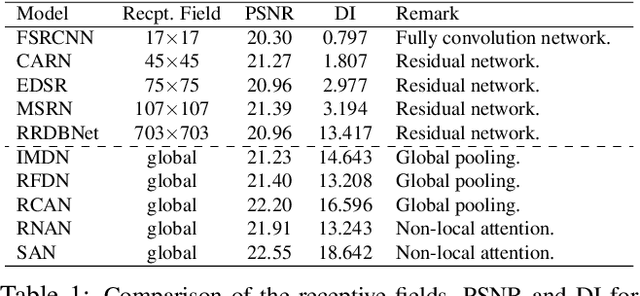
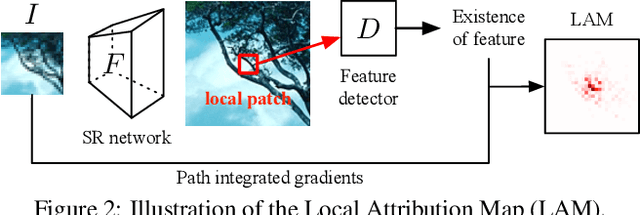
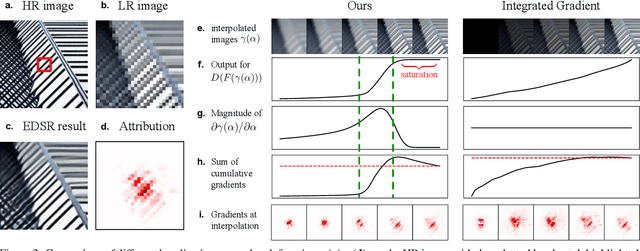
Image super-resolution (SR) techniques have been developing rapidly, benefiting from the invention of deep networks and its successive breakthroughs. However, it is acknowledged that deep learning and deep neural networks are difficult to interpret. SR networks inherit this mysterious nature and little works make attempt to understand them. In this paper, we perform attribution analysis of SR networks, which aims at finding the input pixels that strongly influence the SR results. We propose a novel attribution approach called local attribution map (LAM), which inherits the integral gradient method yet with two unique features. One is to use the blurred image as the baseline input, and the other is to adopt the progressive blurring function as the path function. Based on LAM, we show that: (1) SR networks with a wider range of involved input pixels could achieve better performance. (2) Attention networks and non-local networks extract features from a wider range of input pixels. (3) Comparing with the range that actually contributes, the receptive field is large enough for most deep networks. (4) For SR networks, textures with regular stripes or grids are more likely to be noticed, while complex semantics are difficult to utilize. Our work opens new directions for designing SR networks and interpreting low-level vision deep models.
Skeleton Key: Image Captioning by Skeleton-Attribute Decomposition
Apr 23, 2017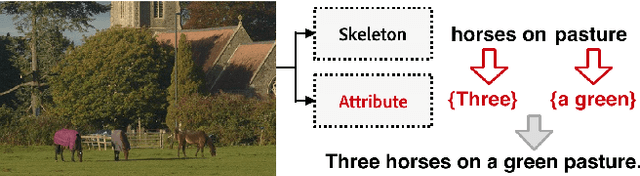

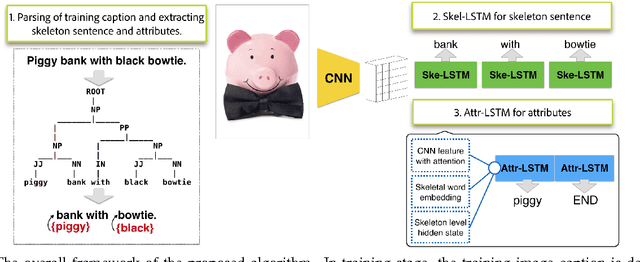
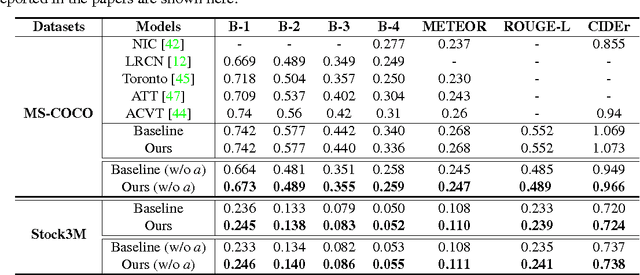
Recently, there has been a lot of interest in automatically generating descriptions for an image. Most existing language-model based approaches for this task learn to generate an image description word by word in its original word order. However, for humans, it is more natural to locate the objects and their relationships first, and then elaborate on each object, describing notable attributes. We present a coarse-to-fine method that decomposes the original image description into a skeleton sentence and its attributes, and generates the skeleton sentence and attribute phrases separately. By this decomposition, our method can generate more accurate and novel descriptions than the previous state-of-the-art. Experimental results on the MS-COCO and a larger scale Stock3M datasets show that our algorithm yields consistent improvements across different evaluation metrics, especially on the SPICE metric, which has much higher correlation with human ratings than the conventional metrics. Furthermore, our algorithm can generate descriptions with varied length, benefiting from the separate control of the skeleton and attributes. This enables image description generation that better accommodates user preferences.
Pixel-wise Distance Regression for Glacier Calving Front Detection and Segmentation
Mar 09, 2021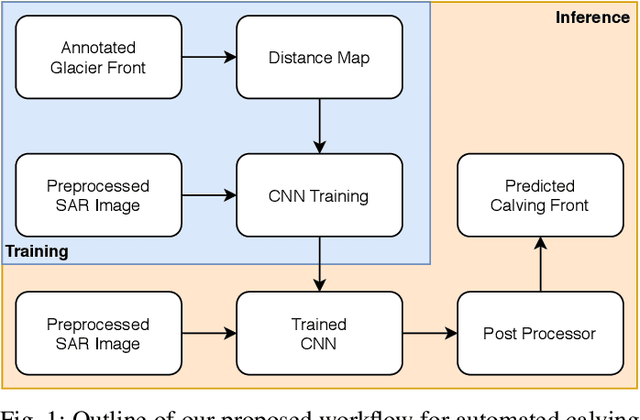


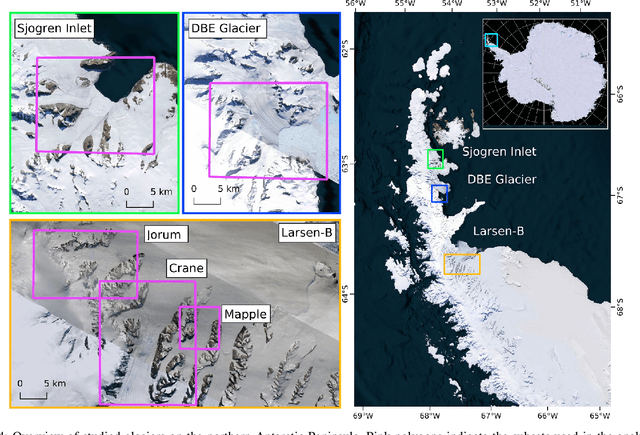
Glacier calving front position (CFP) is an important glaciological variable. Traditionally, delineating the CFPs has been carried out manually, which was subjective, tedious and expensive. Automating this process is crucial for continuously monitoring the evolution and status of glaciers. Recently, deep learning approaches have been investigated for this application. However, the current methods get challenged by a severe class-imbalance problem. In this work, we propose to mitigate the class-imbalance between the calving front class and the non-calving front class by reformulating the segmentation problem into a pixel-wise regression task. A Convolutional Neural Network gets optimized to predict the distance values to the glacier front for each pixel in the image. The resulting distance map localizes the CFP and is further post-processed to extract the calving front line. We propose three post-processing methods, one method based on statistical thresholding, a second method based on conditional random fields (CRF), and finally the use of a second U-Net. The experimental results confirm that our approach significantly outperforms the state-of-the-art methods and produces accurate delineation. The Second U-Net obtains the best performance results, resulting in an average improvement of about 21% dice coefficient enhancement.
MDNet: A Semantically and Visually Interpretable Medical Image Diagnosis Network
Jul 08, 2017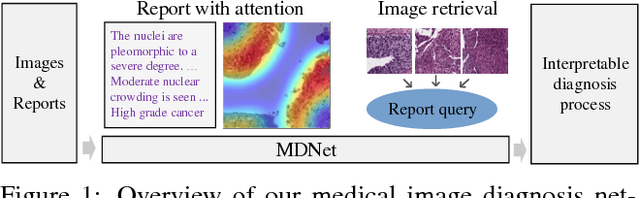
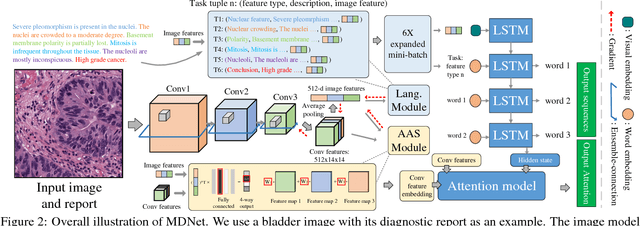
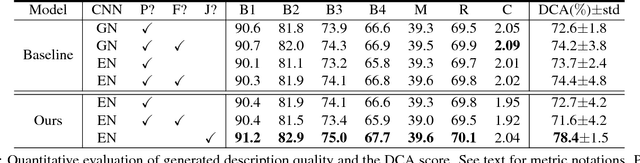
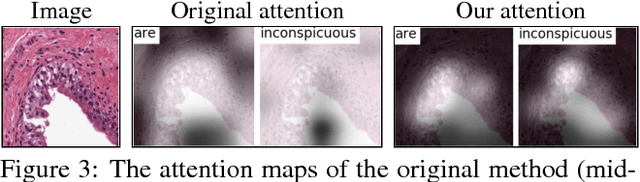
The inability to interpret the model prediction in semantically and visually meaningful ways is a well-known shortcoming of most existing computer-aided diagnosis methods. In this paper, we propose MDNet to establish a direct multimodal mapping between medical images and diagnostic reports that can read images, generate diagnostic reports, retrieve images by symptom descriptions, and visualize attention, to provide justifications of the network diagnosis process. MDNet includes an image model and a language model. The image model is proposed to enhance multi-scale feature ensembles and utilization efficiency. The language model, integrated with our improved attention mechanism, aims to read and explore discriminative image feature descriptions from reports to learn a direct mapping from sentence words to image pixels. The overall network is trained end-to-end by using our developed optimization strategy. Based on a pathology bladder cancer images and its diagnostic reports (BCIDR) dataset, we conduct sufficient experiments to demonstrate that MDNet outperforms comparative baselines. The proposed image model obtains state-of-the-art performance on two CIFAR datasets as well.
SimTriplet: Simple Triplet Representation Learning with a Single GPU
Mar 09, 2021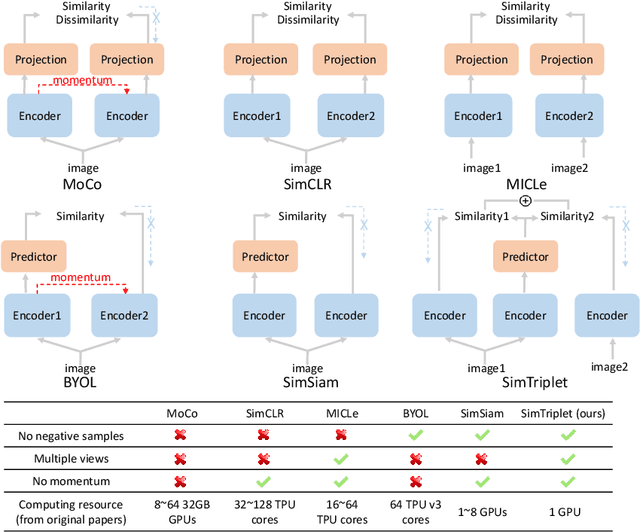
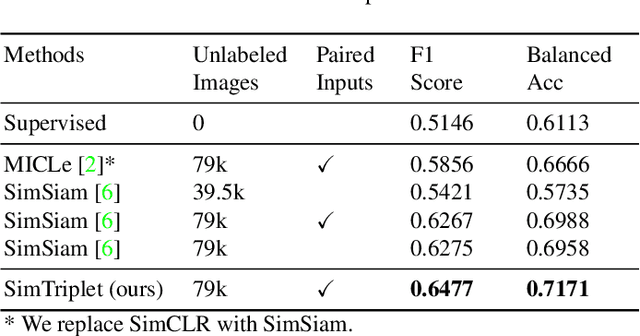
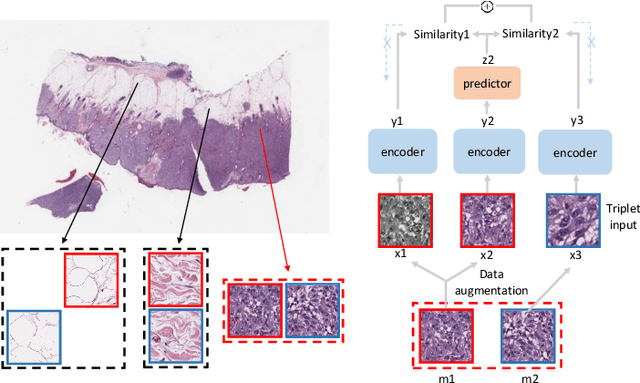
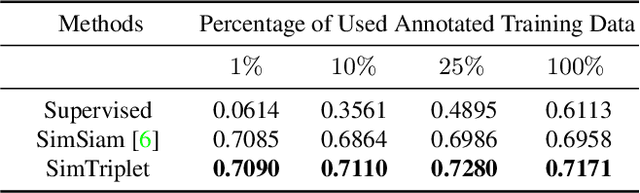
Contrastive learning is a key technique of modern self-supervised learning. The broader accessibility of earlier approaches is hindered by the need of heavy computational resources (e.g., at least 8 GPUs or 32 TPU cores), which accommodate for large-scale negative samples or momentum. The more recent SimSiam approach addresses such key limitations via stop-gradient without momentum encoders. In medical image analysis, multiple instances can be achieved from the same patient or tissue. Inspired by these advances, we propose a simple triplet representation learning (SimTriplet) approach on pathological images. The contribution of the paper is three-fold: (1) The proposed SimTriplet method takes advantage of the multi-view nature of medical images beyond self-augmentation; (2) The method maximizes both intra-sample and inter-sample similarities via triplets from positive pairs, without using negative samples; and (3) The recent mix precision training is employed to advance the training by only using a single GPU with 16GB memory. By learning from 79,000 unlabeled pathological patch images, SimTriplet achieved 10.58% better performance compared with supervised learning. It also achieved 2.13% better performance compared with SimSiam. Our proposed SimTriplet can achieve decent performance using only 1% labeled data. The code and data are available at https://github.com/hrlblab/SimTriple.