 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Wearable Sensors for Spatio-Temporal Grip Force Profiling
Jan 16, 2021
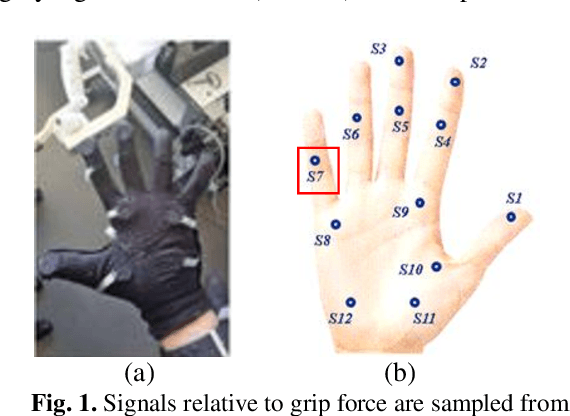
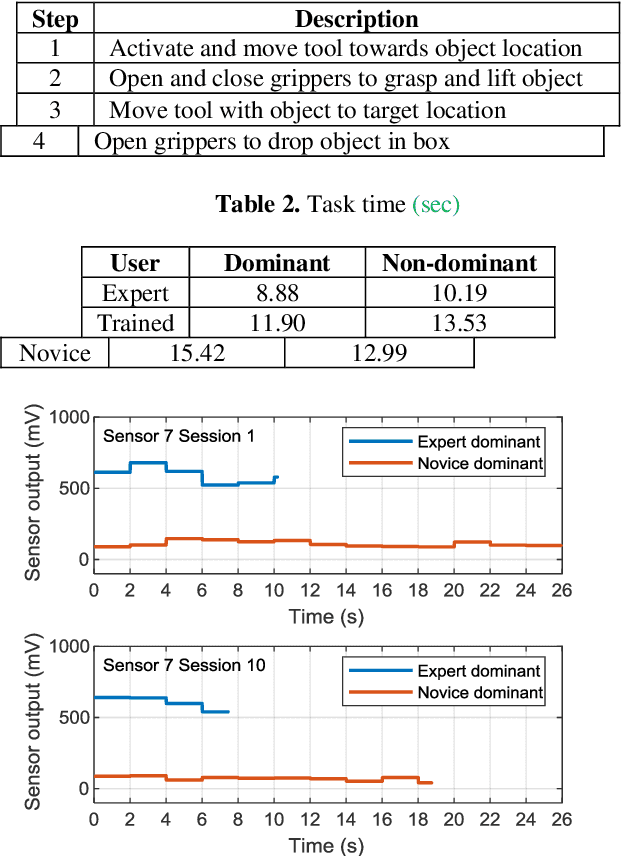
Wearable biosensor technology enables real-time, convenient, and continuous monitoring of users behavioral signals. Such include signals relative to body motion, body temperature, biological or biochemical markers, and individual grip forces, which are studied in this paper. A four step pick and drop image guided and robot assisted precision task has been designed for exploiting a wearable wireless sensor glove system. Individual spatio temporal grip forces are analyzed on the basis of thousands of individual sensor data, collected from different locations on the dominant and non-dominant hands of each of three users in ten successive task sessions. Statistical comparisons reveal specific differences between grip force profiles of the individual users as a function of task skill level (expertise) and time.
Revisiting ResNets: Improved Training and Scaling Strategies
Mar 13, 2021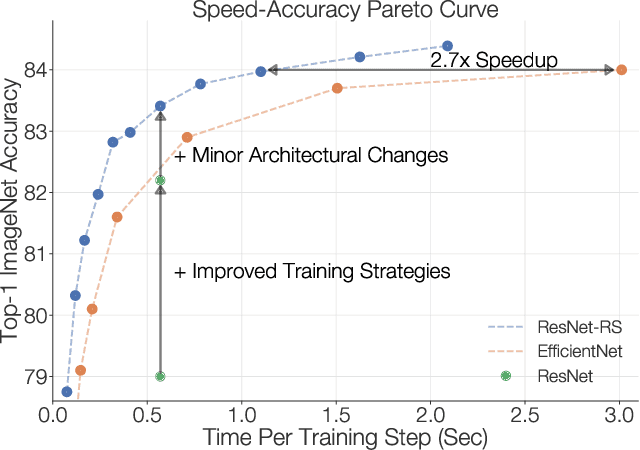
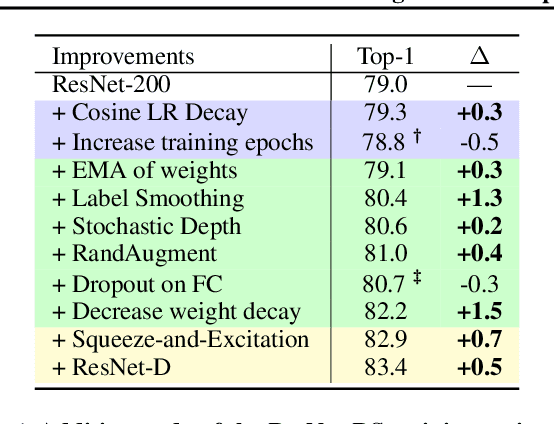
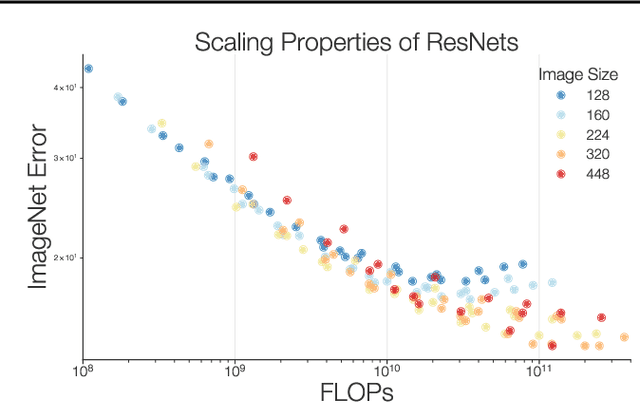
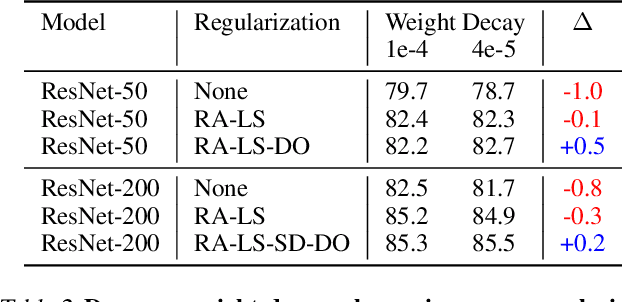
Novel computer vision architectures monopolize the spotlight, but the impact of the model architecture is often conflated with simultaneous changes to training methodology and scaling strategies. Our work revisits the canonical ResNet (He et al., 2015) and studies these three aspects in an effort to disentangle them. Perhaps surprisingly, we find that training and scaling strategies may matter more than architectural changes, and further, that the resulting ResNets match recent state-of-the-art models. We show that the best performing scaling strategy depends on the training regime and offer two new scaling strategies: (1) scale model depth in regimes where overfitting can occur (width scaling is preferable otherwise); (2) increase image resolution more slowly than previously recommended (Tan & Le, 2019). Using improved training and scaling strategies, we design a family of ResNet architectures, ResNet-RS, which are 1.7x - 2.7x faster than EfficientNets on TPUs, while achieving similar accuracies on ImageNet. In a large-scale semi-supervised learning setup, ResNet-RS achieves 86.2% top-1 ImageNet accuracy, while being 4.7x faster than EfficientNet NoisyStudent. The training techniques improve transfer performance on a suite of downstream tasks (rivaling state-of-the-art self-supervised algorithms) and extend to video classification on Kinetics-400. We recommend practitioners use these simple revised ResNets as baselines for future research.
Shuffler: A Large Scale Data Management Tool for ML in Computer Vision
Apr 11, 2021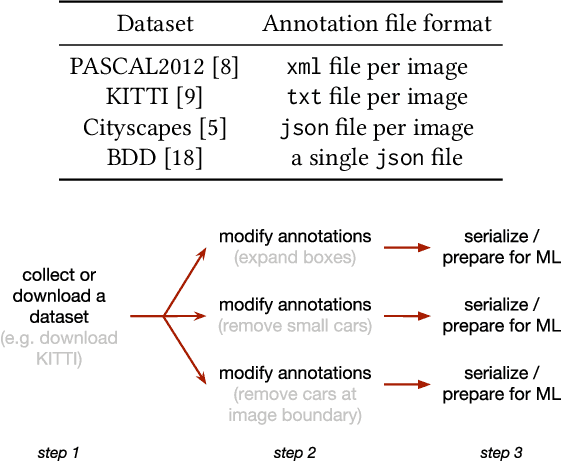

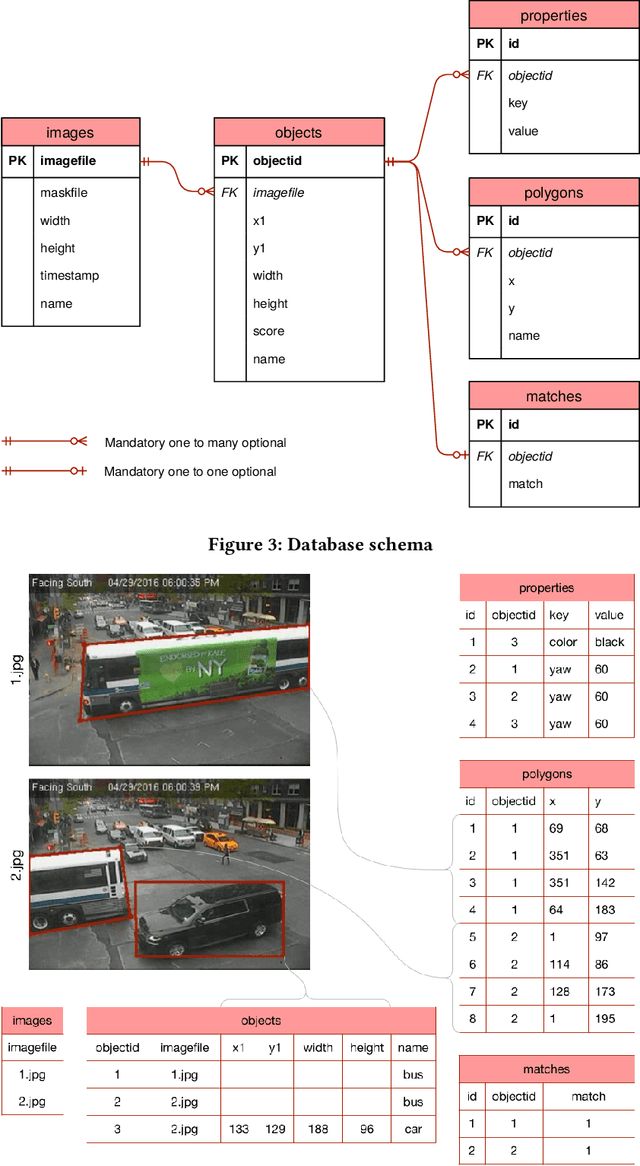
Datasets in the computer vision academic research community are primarily static. Once a dataset is accepted as a benchmark for a computer vision task, researchers working on this task will not alter it in order to make their results reproducible. At the same time, when exploring new tasks and new applications, datasets tend to be an ever changing entity. A practitioner may combine existing public datasets, filter images or objects in them, change annotations or add new ones to fit a task at hand, visualize sample images, or perhaps output statistics in the form of text or plots. In fact, datasets change as practitioners experiment with data as much as with algorithms, trying to make the most out of machine learning models. Given that ML and deep learning call for large volumes of data to produce satisfactory results, it is no surprise that the resulting data and software management associated to dealing with live datasets can be quite complex. As far as we know, there is no flexible, publicly available instrument to facilitate manipulating image data and their annotations throughout a ML pipeline. In this work, we present Shuffler, an open source tool that makes it easy to manage large computer vision datasets. It stores annotations in a relational, human-readable database. Shuffler defines over 40 data handling operations with annotations that are commonly useful in supervised learning applied to computer vision and supports some of the most well-known computer vision datasets. Finally, it is easily extensible, making the addition of new operations and datasets a task that is fast and easy to accomplish.
MALI: A memory efficient and reverse accurate integrator for Neural ODEs
Mar 03, 2021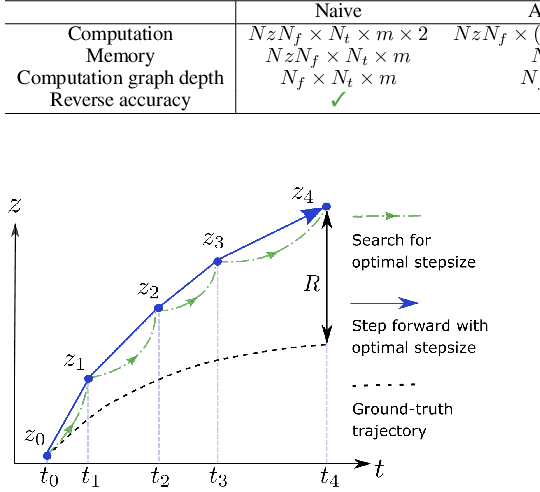
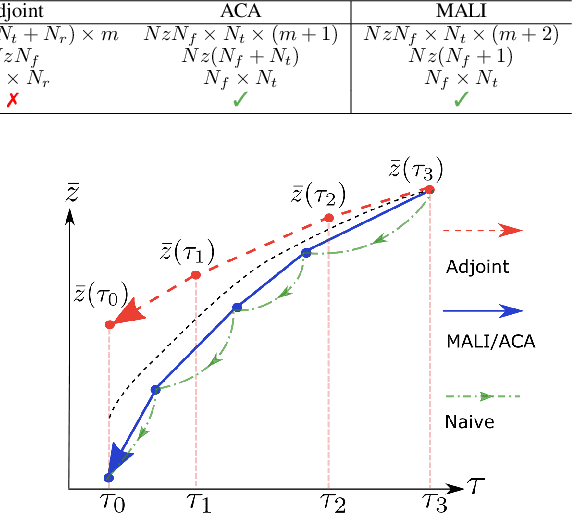
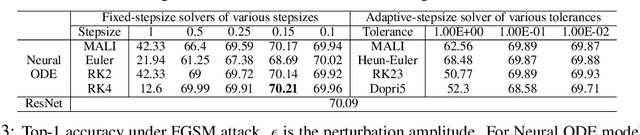
Neural ordinary differential equations (Neural ODEs) are a new family of deep-learning models with continuous depth. However, the numerical estimation of the gradient in the continuous case is not well solved: existing implementations of the adjoint method suffer from inaccuracy in reverse-time trajectory, while the naive method and the adaptive checkpoint adjoint method (ACA) have a memory cost that grows with integration time. In this project, based on the asynchronous leapfrog (ALF) solver, we propose the Memory-efficient ALF Integrator (MALI), which has a constant memory cost \textit{w.r.t} number of solver steps in integration similar to the adjoint method, and guarantees accuracy in reverse-time trajectory (hence accuracy in gradient estimation). We validate MALI in various tasks: on image recognition tasks, to our knowledge, MALI is the first to enable feasible training of a Neural ODE on ImageNet and outperform a well-tuned ResNet, while existing methods fail due to either heavy memory burden or inaccuracy; for time series modeling, MALI significantly outperforms the adjoint method; and for continuous generative models, MALI achieves new state-of-the-art performance. We provide a pypi package at \url{https://jzkay12.github.io/TorchDiffEqPack/}
* https://openreview.net/forum?id=blfSjHeFM_e
Using Machine Learning to Automate Mammogram Images Analysis
Dec 06, 2020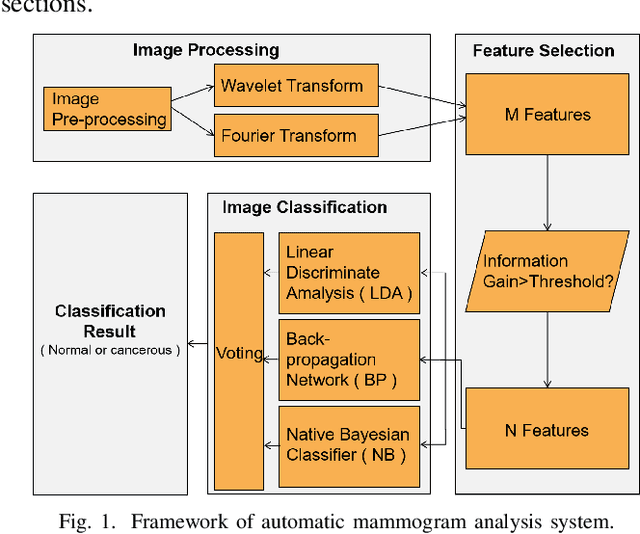
Breast cancer is the second leading cause of cancer-related death after lung cancer in women. Early detection of breast cancer in X-ray mammography is believed to have effectively reduced the mortality rate. However, a relatively high false positive rate and a low specificity in mammography technology still exist. In this work, a computer-aided automatic mammogram analysis system is proposed to process the mammogram images and automatically discriminate them as either normal or cancerous, consisting of three consecutive image processing, feature selection, and image classification stages. In designing the system, the discrete wavelet transforms (Daubechies 2, Daubechies 4, and Biorthogonal 6.8) and the Fourier cosine transform were first used to parse the mammogram images and extract statistical features. Then, an entropy-based feature selection method was implemented to reduce the number of features. Finally, different pattern recognition methods (including the Back-propagation Network, the Linear Discriminant Analysis, and the Naive Bayes Classifier) and a voting classification scheme were employed. The performance of each classification strategy was evaluated for sensitivity, specificity, and accuracy and for general performance using the Receiver Operating Curve. Our method is validated on the dataset from the Eastern Health in Newfoundland and Labrador of Canada. The experimental results demonstrated that the proposed automatic mammogram analysis system could effectively improve the classification performances.
Image Processing in Floriculture Using a robotic Mobile Platform
Jun 26, 2017Colombia has a privileged geographical location which makes it a cornerstone and equidistant point to all regional markets. The country has a great ecological diversity and it is one of the largest suppliers of flowers for US. Colombian flower companies have made innovations in the marketing process, using methods to reach all conditions for final consumers. This article develops a monitoring system for floriculture industries. The system was implemented in a robotic platform. This device has the ability to be programmed in different programming languages. The robot takes the necessary environment information from its camera. The algorithm of the monitoring system was developed with the image processing toolbox on Matlab. The implemented algorithm acquires images through its camera, it performs a preprocessing of the image, noise filter, enhancing of the color and adjusting the dimension in order to increase processing speed. Then, the image is segmented by color and with the binarized version of the image using morphological operations (erosion and dilation), extract relevant features such as centroid, perimeter and area. The data obtained from the image processing helps the robot with the automatic identification of objectives, orientation and move towards them. Also, the results generate a diagnostic quality of each object scanned.
Hierarchical Domain Invariant Variational Auto-Encoding with weak domain supervision
Jan 23, 2021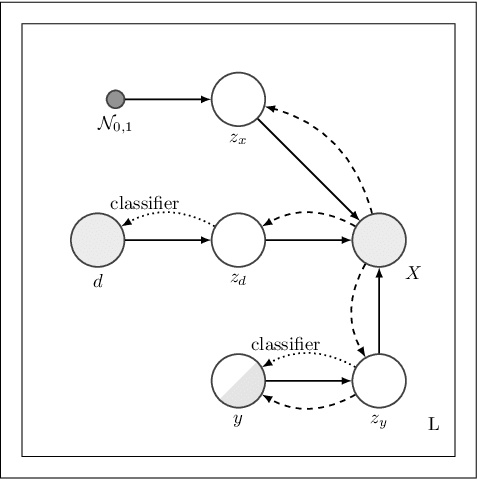

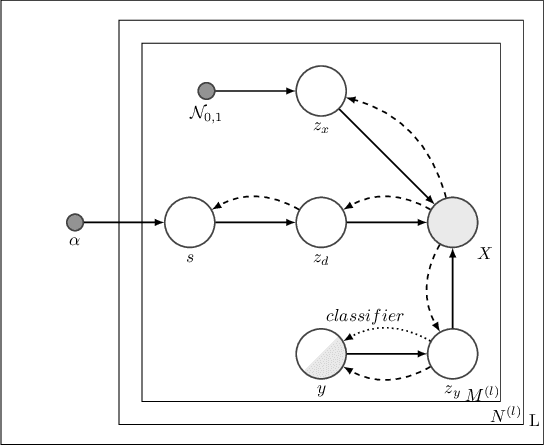

We address the task of domain generalization, where the goal is to train a predictive model based on a number of domains such that it is able to generalize to a new, previously unseen domain. We choose a generative approach within the framework of variational autoencoders and propose a weakly supervised algorithm that is able to account for incomplete and hierarchical domain information. We show that our method is able to learn representations that disentangle domain-specific information from class-label specific information even in complex settings where an unobserved substructure is present in domains. Our interpretable method outperforms previously proposed generative algorithms for domain generalization and achieves competitive performance compared to state-of-the-art approaches, which are based on complex image-processing steps, on the standard domain generalization benchmark dataset PACS.
Automatic Detection of Cardiac Chambers Using an Attention-based YOLOv4 Framework from Four-chamber View of Fetal Echocardiography
Nov 26, 2020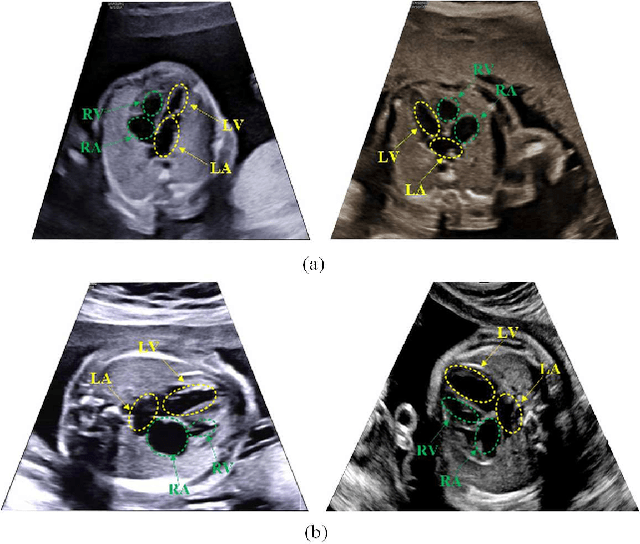
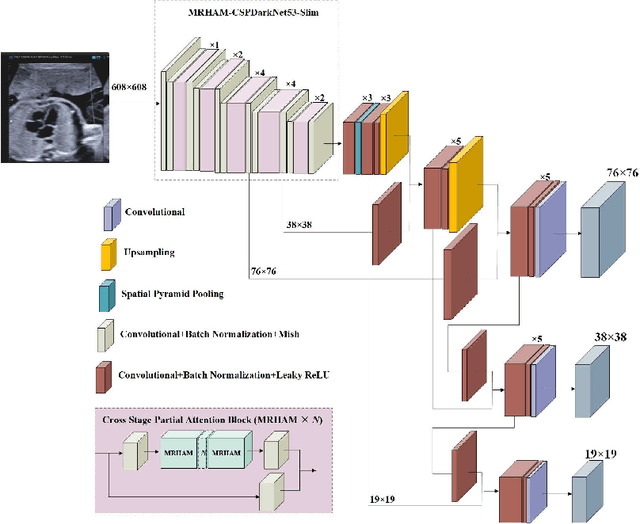
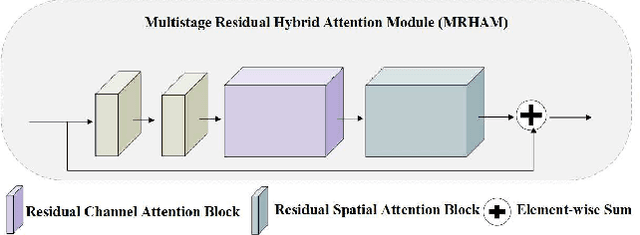
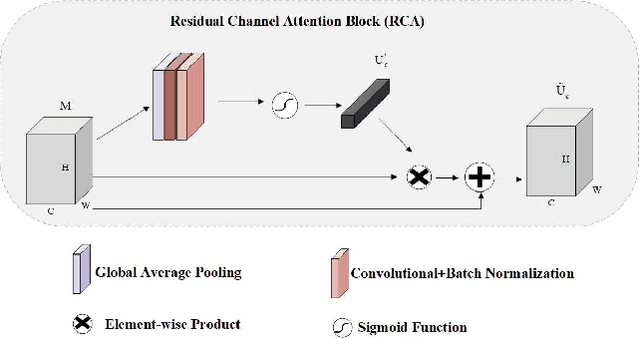
Echocardiography is a powerful prenatal examination tool for early diagnosis of fetal congenital heart diseases (CHDs). The four-chamber (FC) view is a crucial and easily accessible ultrasound (US) image among echocardiography images. Automatic analysis of FC views contributes significantly to the early diagnosis of CHDs. The first step to automatically analyze fetal FC views is locating the fetal four crucial chambers of heart in a US image. However, it is a greatly challenging task due to several key factors, such as numerous speckles in US images, the fetal cardiac chambers with small size and unfixed positions, and category indistinction caused by the similarity of cardiac chambers. These factors hinder the process of capturing robust and discriminative features, hence destroying fetal cardiac anatomical chambers precise localization. Therefore, we first propose a multistage residual hybrid attention module (MRHAM) to improve the feature learning. Then, we present an improved YOLOv4 detection model, namely MRHAM-YOLOv4-Slim. Specially, the residual identity mapping is replaced with the MRHAM in the backbone of MRHAM-YOLOv4-Slim, accurately locating the four important chambers in fetal FC views. Extensive experiments demonstrate that our proposed method outperforms current state-of-the-art, including the precision of 0.890, the recall of 0.920, the F1 score of 0.907 and the mAP of 0.913.
OpenPifPaf: Composite Fields for Semantic Keypoint Detection and Spatio-Temporal Association
Mar 03, 2021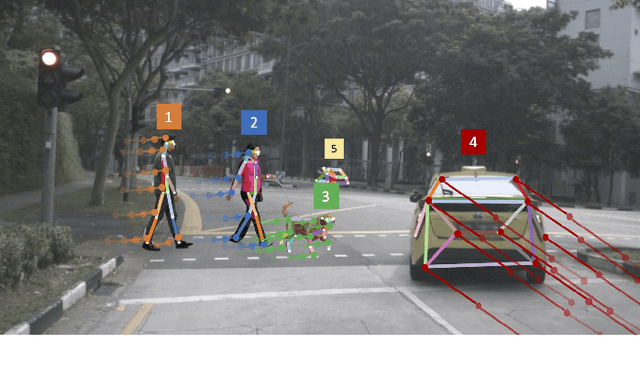


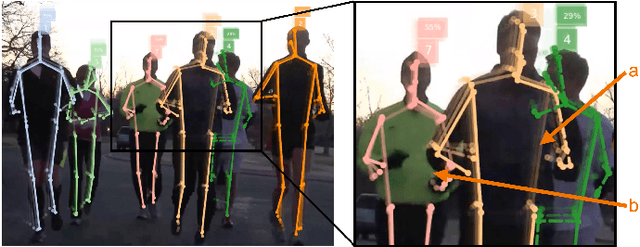
Many image-based perception tasks can be formulated as detecting, associating and tracking semantic keypoints, e.g., human body pose estimation and tracking. In this work, we present a general framework that jointly detects and forms spatio-temporal keypoint associations in a single stage, making this the first real-time pose detection and tracking algorithm. We present a generic neural network architecture that uses Composite Fields to detect and construct a spatio-temporal pose which is a single, connected graph whose nodes are the semantic keypoints (e.g., a person's body joints) in multiple frames. For the temporal associations, we introduce the Temporal Composite Association Field (TCAF) which requires an extended network architecture and training method beyond previous Composite Fields. Our experiments show competitive accuracy while being an order of magnitude faster on multiple publicly available datasets such as COCO, CrowdPose and the PoseTrack 2017 and 2018 datasets. We also show that our method generalizes to any class of semantic keypoints such as car and animal parts to provide a holistic perception framework that is well suited for urban mobility such as self-driving cars and delivery robots.
Dynamic Fusion Module Evolves Drivable Area and Road Anomaly Detection: A Benchmark and Algorithms
Mar 03, 2021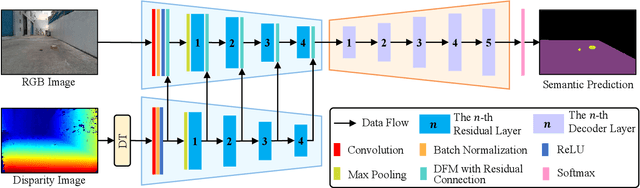



Joint detection of drivable areas and road anomalies is very important for mobile robots. Recently, many semantic segmentation approaches based on convolutional neural networks (CNNs) have been proposed for pixel-wise drivable area and road anomaly detection. In addition, some benchmark datasets, such as KITTI and Cityscapes, have been widely used. However, the existing benchmarks are mostly designed for self-driving cars. There lacks a benchmark for ground mobile robots, such as robotic wheelchairs. Therefore, in this paper, we first build a drivable area and road anomaly detection benchmark for ground mobile robots, evaluating the existing state-of-the-art single-modal and data-fusion semantic segmentation CNNs using six modalities of visual features. Furthermore, we propose a novel module, referred to as the dynamic fusion module (DFM), which can be easily deployed in existing data-fusion networks to fuse different types of visual features effectively and efficiently. The experimental results show that the transformed disparity image is the most informative visual feature and the proposed DFM-RTFNet outperforms the state-of-the-arts. Additionally, our DFM-RTFNet achieves competitive performance on the KITTI road benchmark. Our benchmark is publicly available at https://sites.google.com/view/gmrb.