 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Learning based 3D Segmentation: A Survey
Mar 10, 2021

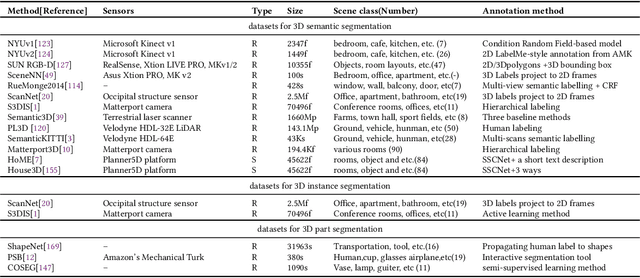
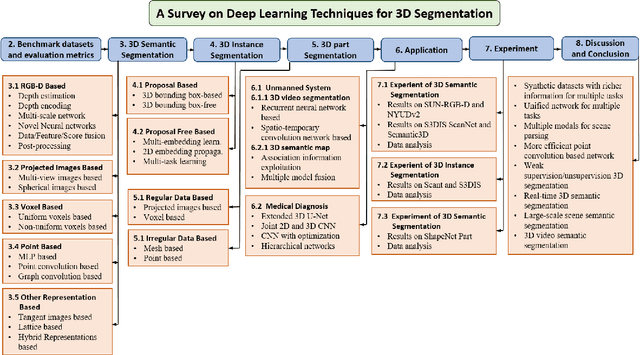
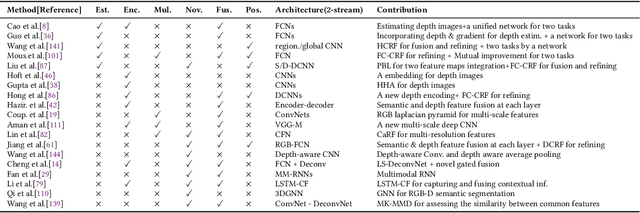
3D object segmentation is a fundamental and challenging problem in computer vision with applications in autonomous driving, robotics, augmented reality and medical image analysis. It has received significant attention from the computer vision, graphics and machine learning communities. Traditionally, 3D segmentation was performed with hand-crafted features and engineered methods which failed to achieve acceptable accuracy and could not generalize to large-scale data. Driven by their great success in 2D computer vision, deep learning techniques have recently become the tool of choice for 3D segmentation tasks as well. This has led to an influx of a large number of methods in the literature that have been evaluated on different benchmark datasets. This paper provides a comprehensive survey of recent progress in deep learning based 3D segmentation covering over 150 papers. It summarizes the most commonly used pipelines, discusses their highlights and shortcomings, and analyzes the competitive results of these segmentation methods. Based on the analysis, it also provides promising research directions for the future.
Image Super-Resolution Using VDSR-ResNeXt and SRCGAN
Oct 10, 2018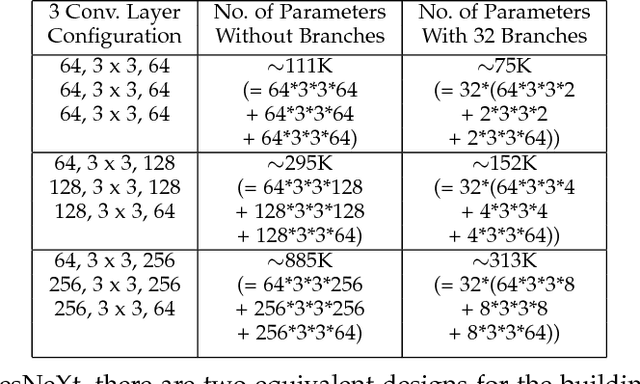
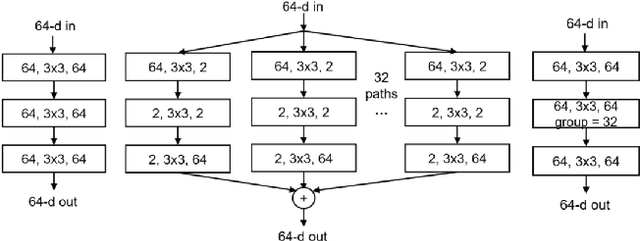
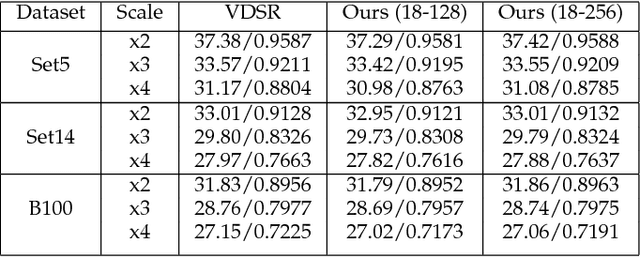
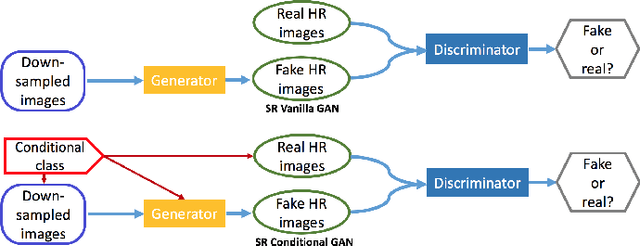
Over the past decade, many Super Resolution techniques have been developed using deep learning. Among those, generative adversarial networks (GAN) and very deep convolutional networks (VDSR) have shown promising results in terms of HR image quality and computational speed. In this paper, we propose two approaches based on these two algorithms: VDSR-ResNeXt, which is a deep multi-branch convolutional network inspired by VDSR and ResNeXt; and SRCGAN, which is a conditional GAN that explicitly passes class labels as input to the GAN. The two methods were implemented on common SR benchmark datasets for both quantitative and qualitative assessment.
Image-based Synthesis for Deep 3D Human Pose Estimation
Feb 12, 2018
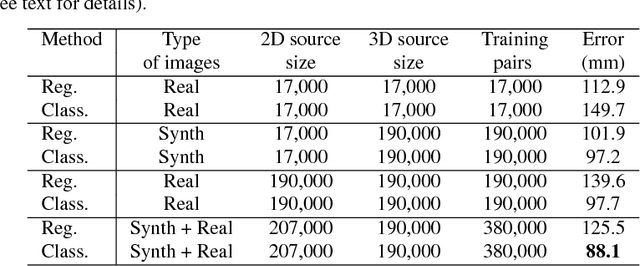
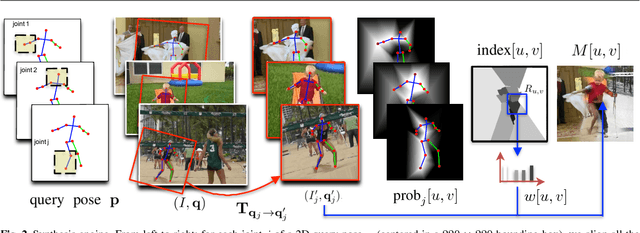
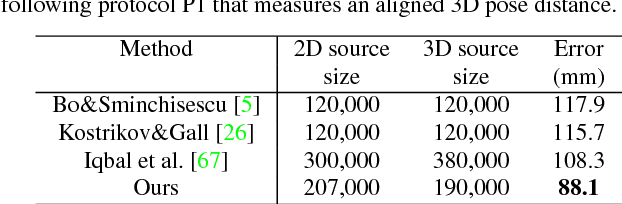
This paper addresses the problem of 3D human pose estimation in the wild. A significant challenge is the lack of training data, i.e., 2D images of humans annotated with 3D poses. Such data is necessary to train state-of-the-art CNN architectures. Here, we propose a solution to generate a large set of photorealistic synthetic images of humans with 3D pose annotations. We introduce an image-based synthesis engine that artificially augments a dataset of real images with 2D human pose annotations using 3D motion capture data. Given a candidate 3D pose, our algorithm selects for each joint an image whose 2D pose locally matches the projected 3D pose. The selected images are then combined to generate a new synthetic image by stitching local image patches in a kinematically constrained manner. The resulting images are used to train an end-to-end CNN for full-body 3D pose estimation. We cluster the training data into a large number of pose classes and tackle pose estimation as a $K$-way classification problem. Such an approach is viable only with large training sets such as ours. Our method outperforms most of the published works in terms of 3D pose estimation in controlled environments (Human3.6M) and shows promising results for real-world images (LSP). This demonstrates that CNNs trained on artificial images generalize well to real images. Compared to data generated from more classical rendering engines, our synthetic images do not require any domain adaptation or fine-tuning stage.
Learning to compose 6-DoF omnidirectional videos using multi-sphere images
Mar 10, 2021
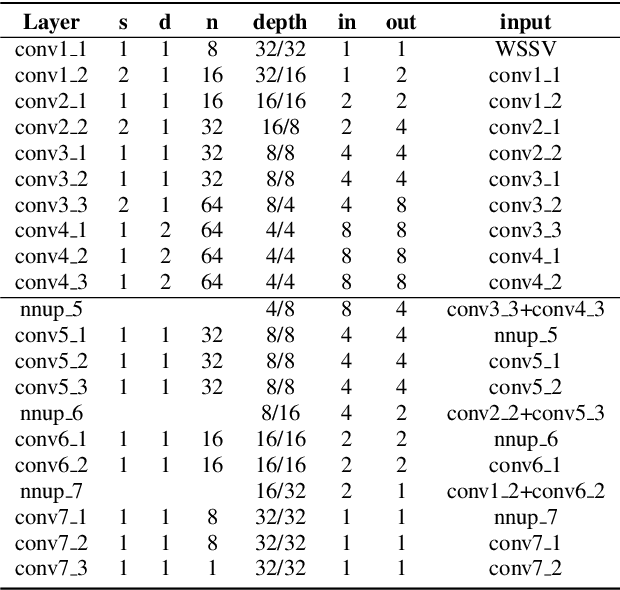
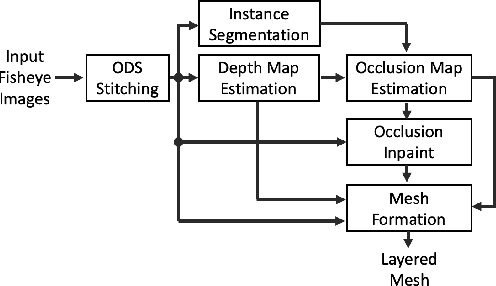
Omnidirectional video is an essential component of Virtual Reality. Although various methods have been proposed to generate content that can be viewed with six degrees of freedom (6-DoF), existing systems usually involve complex depth estimation, image in-painting or stitching pre-processing. In this paper, we propose a system that uses a 3D ConvNet to generate a multi-sphere images (MSI) representation that can be experienced in 6-DoF VR. The system utilizes conventional omnidirectional VR camera footage directly without the need for a depth map or segmentation mask, thereby significantly simplifying the overall complexity of the 6-DoF omnidirectional video composition. By using a newly designed weighted sphere sweep volume (WSSV) fusing technique, our approach is compatible with most panoramic VR camera setups. A ground truth generation approach for high-quality artifact-free 6-DoF contents is proposed and can be used by the research and development community for 6-DoF content generation.
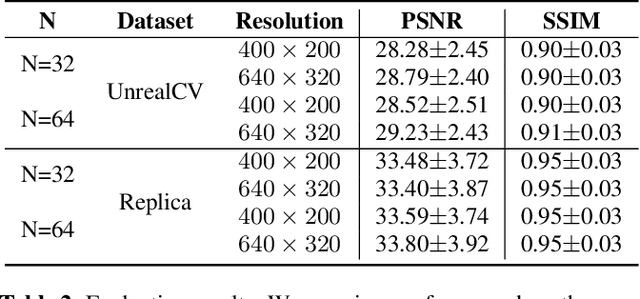
ACORN: Adaptive Coordinate Networks for Neural Scene Representation
May 06, 2021
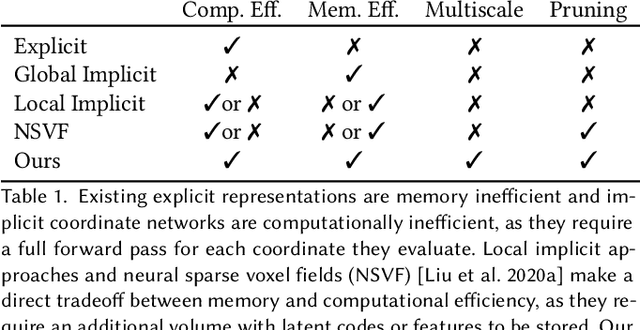
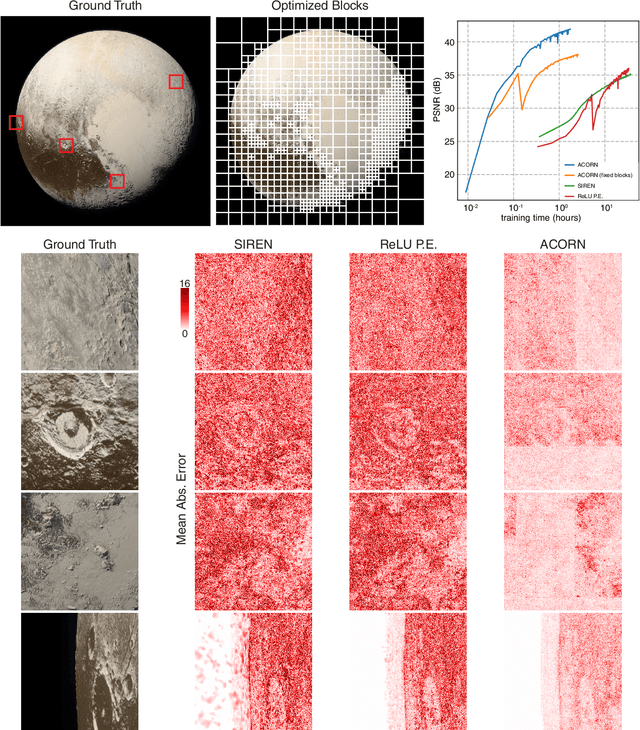
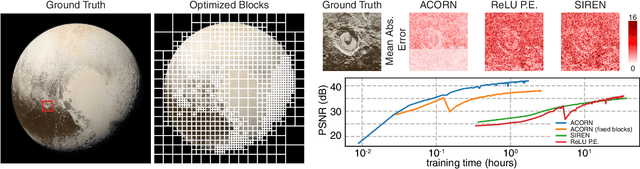
Neural representations have emerged as a new paradigm for applications in rendering, imaging, geometric modeling, and simulation. Compared to traditional representations such as meshes, point clouds, or volumes they can be flexibly incorporated into differentiable learning-based pipelines. While recent improvements to neural representations now make it possible to represent signals with fine details at moderate resolutions (e.g., for images and 3D shapes), adequately representing large-scale or complex scenes has proven a challenge. Current neural representations fail to accurately represent images at resolutions greater than a megapixel or 3D scenes with more than a few hundred thousand polygons. Here, we introduce a new hybrid implicit-explicit network architecture and training strategy that adaptively allocates resources during training and inference based on the local complexity of a signal of interest. Our approach uses a multiscale block-coordinate decomposition, similar to a quadtree or octree, that is optimized during training. The network architecture operates in two stages: using the bulk of the network parameters, a coordinate encoder generates a feature grid in a single forward pass. Then, hundreds or thousands of samples within each block can be efficiently evaluated using a lightweight feature decoder. With this hybrid implicit-explicit network architecture, we demonstrate the first experiments that fit gigapixel images to nearly 40 dB peak signal-to-noise ratio. Notably this represents an increase in scale of over 1000x compared to the resolution of previously demonstrated image-fitting experiments. Moreover, our approach is able to represent 3D shapes significantly faster and better than previous techniques; it reduces training times from days to hours or minutes and memory requirements by over an order of magnitude.
Optimising the Input Image to Improve Visual Relationship Detection
Mar 26, 2019
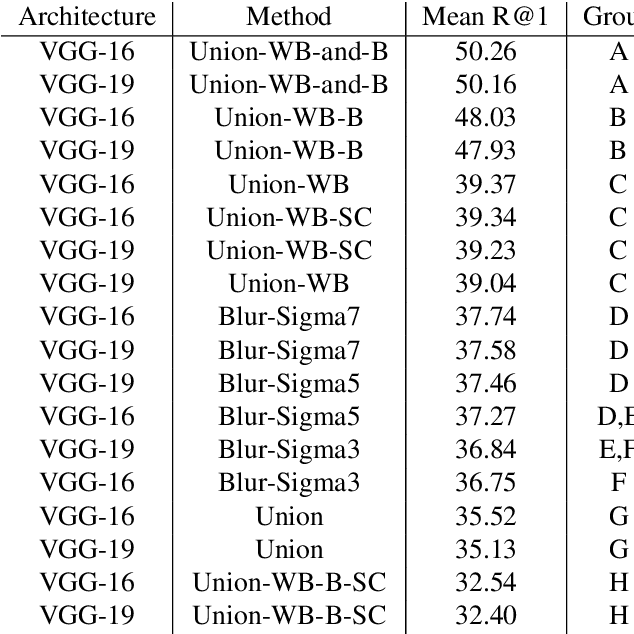

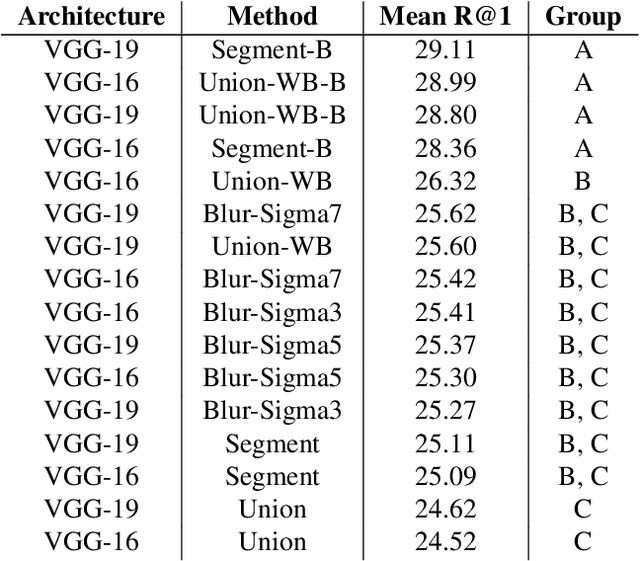
Visual Relationship Detection is defined as, given an image composed of a subject and an object, the correct relation is predicted. To improve the visual part of this difficult problem, ten preprocessing methods were tested to determine whether the widely used Union method yields the optimal results. Therefore, focusing solely on predicate prediction, no object detection and linguistic knowledge were used to prevent them from affecting the comparison results. Once fine-tuned, the Visual Geometry Group models were evaluated using Recall@1, per-predicate recall, activation maximisations, class activation maps, and error analysis. From this research it was found that using preprocessing methods such as the Union-Without-Background-and-with-Binary-mask (Union-WB-and-B) method yields significantly better results than the widely used Union method since, as designed, it enables the Convolutional Neural Network to also identify the subject and object in the convolutional layers instead of solely in the fully-connected layers.
SegBlocks: Block-Based Dynamic Resolution Networks for Real-Time Segmentation
Nov 24, 2020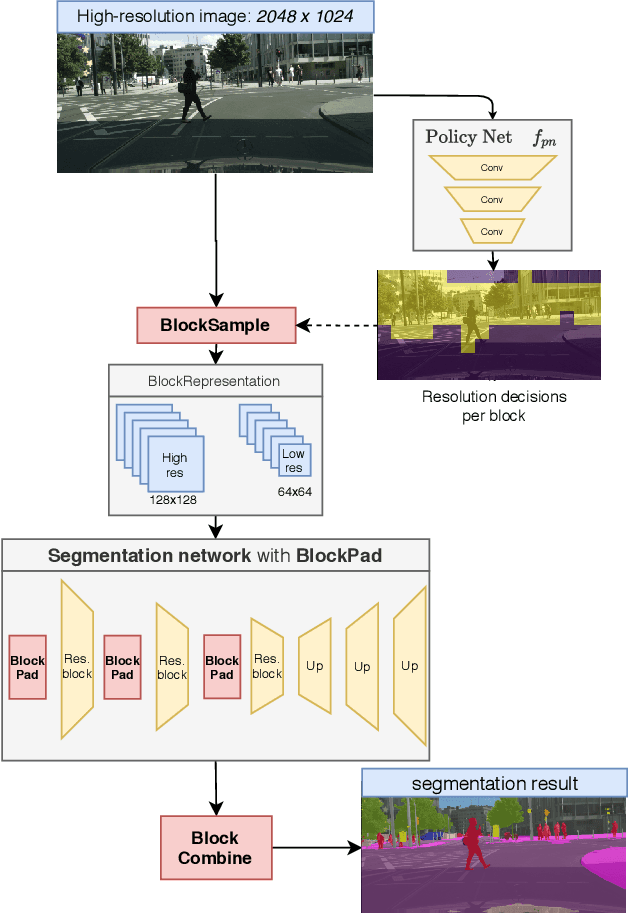
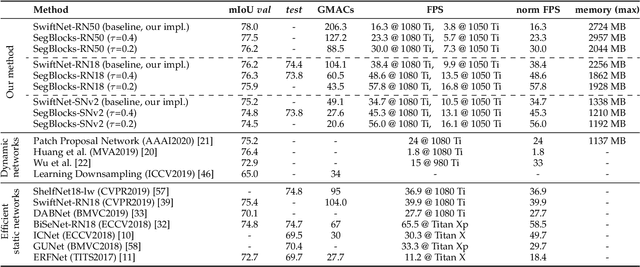
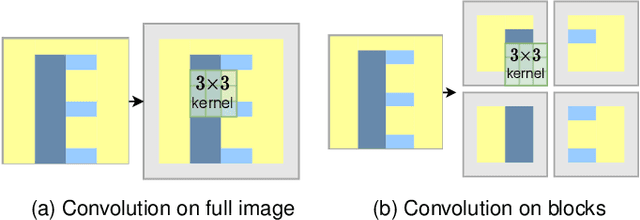

SegBlocks reduces the computational cost of existing neural networks, by dynamically adjusting the processing resolution of image regions based on their complexity. Our method splits an image into blocks and downsamples blocks of low complexity, reducing the number of operations and memory consumption. A lightweight policy network, selecting the complex regions, is trained using reinforcement learning. In addition, we introduce several modules implemented in CUDA to process images in blocks. Most important, our novel BlockPad module prevents the feature discontinuities at block borders of which existing methods suffer, while keeping memory consumption under control. Our experiments on Cityscapes and Mapillary Vistas semantic segmentation show that dynamically processing images offers a better accuracy versus complexity trade-off compared to static baselines of similar complexity. For instance, our method reduces the number of floating-point operations of SwiftNet-RN18 by 60% and increases the inference speed by 50%, with only 0.3% decrease in mIoU accuracy on Cityscapes.
Recent Advances in Domain Adaptation for the Classification of Remote Sensing Data
Apr 15, 2021
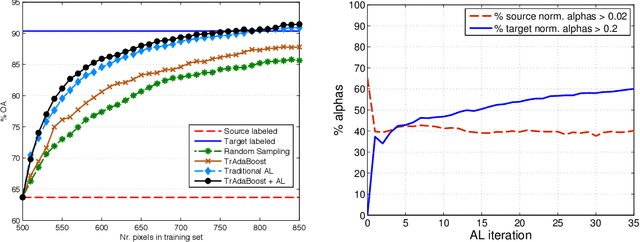
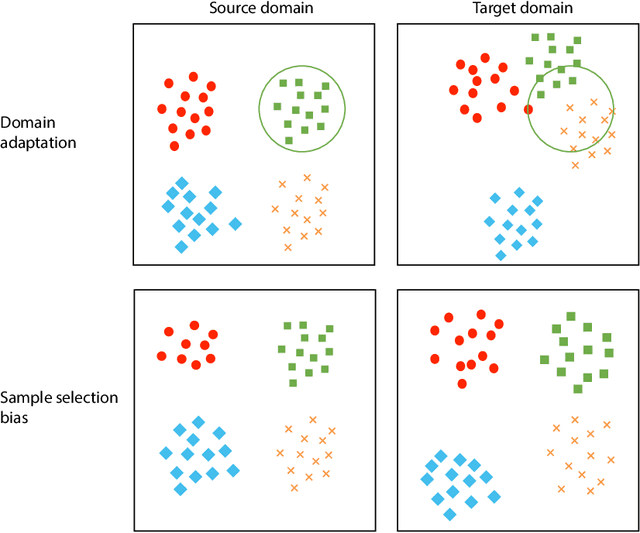
The success of supervised classification of remotely sensed images acquired over large geographical areas or at short time intervals strongly depends on the representativity of the samples used to train the classification algorithm and to define the model. When training samples are collected from an image (or a spatial region) different from the one used for mapping, spectral shifts between the two distributions are likely to make the model fail. Such shifts are generally due to differences in acquisition and atmospheric conditions or to changes in the nature of the object observed. In order to design classification methods that are robust to data-set shifts, recent remote sensing literature has considered solutions based on domain adaptation (DA) approaches. Inspired by machine learning literature, several DA methods have been proposed to solve specific problems in remote sensing data classification. This paper provides a critical review of the recent advances in DA for remote sensing and presents an overview of methods divided into four categories: i) invariant feature selection; ii) representation matching; iii) adaptation of classifiers and iv) selective sampling. We provide an overview of recent methodologies, as well as examples of application of the considered techniques to real remote sensing images characterized by very high spatial and spectral resolution. Finally, we propose guidelines to the selection of the method to use in real application scenarios.
Classification and Segmentation of Pulmonary Lesions in CT images using a combined VGG-XGBoost method, and an integrated Fuzzy Clustering-Level Set technique
Jan 04, 2021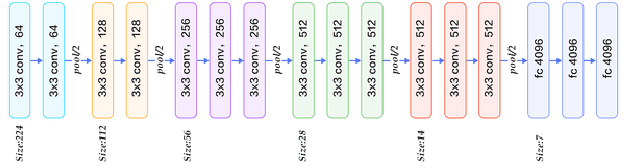
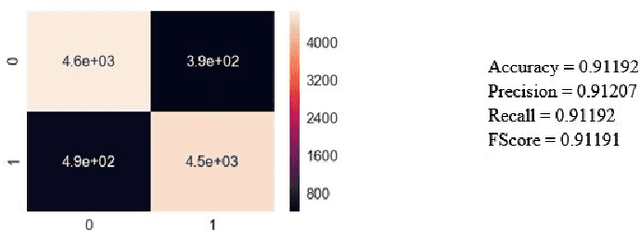
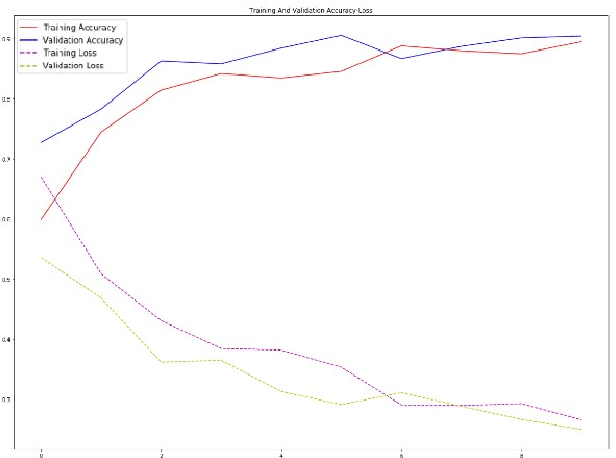
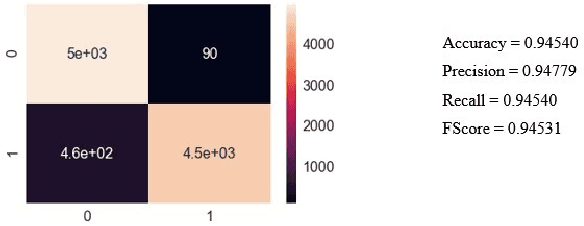
Given that lung cancer is one of the deadliest diseases, and many die from the disease every year, early detection and diagnosis of this disease are valuable, preventing cancer from growing and spreading. So if cancer is diagnosed in the early stage, the patient's life will be saved. However, the current pulmonary disease diagnosis is made by human resources, which is time-consuming and requires a specialist in this field. Also, there is a high level of errors in human diagnosis. Our goal is to develop a system that can detect and classify lung lesions with high accuracy and segment them in CT-scan images. In the proposed method, first, features are extracted automatically from the CT-scan image; then, the extracted features are classified by Ensemble Gradient Boosting methods. Finally, if there is a lesion in the CT-scan image, using a hybrid method based on [1], including Fuzzy Clustering and Level Set, the lesion is segmented. We collected a dataset, including CT-scan images of pulmonary lesions. The target community was the patients in Mashhad. The collected samples were then tagged by a specialist. We used this dataset for training and testing our models. Finally, we were able to achieve an accuracy of 96% for this dataset. This system can help physicians to diagnose pulmonary lesions and prevent possible mistakes.
Automatically Extract the Semi-transparent Motion-blurred Hand from a Single Image
Jun 27, 2019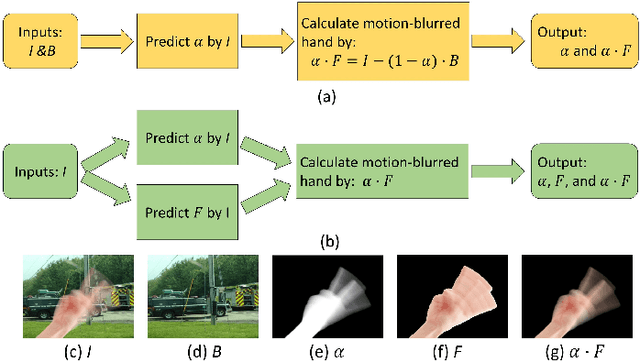
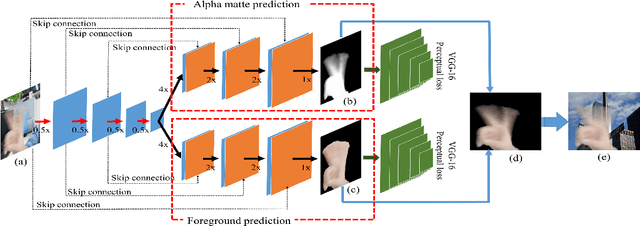


When we use video chat, video game, or other video applications, motion-blurred hands often appear. Accurately extracting these hands is very useful for video editing and behavior analysis. However, existing motion-blurred object extraction methods either need user interactions, such as user supplied trimaps and scribbles, or need additional information, such as background images. In this paper, a novel method which can automatically extract the semi-transparent motion-blurred hand just according to the original RGB image is proposed. The proposed method separates the extraction task into two subtasks: alpha matte prediction and foreground prediction. These two subtasks are implemented by Xception based encoder-decoder networks. The extracted motion-blurred hand images can be calculated by multiplying the predicted alpha mattes and foreground images. Experiments on synthetic and real datasets show that the proposed method has promising performance.