 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-Visual Dataset and Method for Anomaly Detection in Traffic Videos
May 24, 2023



We introduce the first audio-visual dataset for traffic anomaly detection taken from real-world scenes, called MAVAD, with a diverse range of weather and illumination conditions. In addition, we propose a novel method named AVACA that combines visual and audio features extracted from video sequences by means of cross-attention to detect anomalies. We demonstrate that the addition of audio improves the performance of AVACA by up to 5.2%. We also evaluate the impact of image anonymization, showing only a minor decrease in performance averaging at 1.7%.
KENGIC: KEyword-driven and N-Gram Graph based Image Captioning
Feb 07, 2023



This paper presents a Keyword-driven and N-gram Graph based approach for Image Captioning (KENGIC). Most current state-of-the-art image caption generators are trained end-to-end on large scale paired image-caption datasets which are very laborious and expensive to collect. Such models are limited in terms of their explainability and their applicability across different domains. To address these limitations, a simple model based on N-Gram graphs which does not require any end-to-end training on paired image captions is proposed. Starting with a set of image keywords considered as nodes, the generator is designed to form a directed graph by connecting these nodes through overlapping n-grams as found in a given text corpus. The model then infers the caption by maximising the most probable n-gram sequences from the constructed graph. To analyse the use and choice of keywords in context of this approach, this study analysed the generation of image captions based on (a) keywords extracted from gold standard captions and (b) from automatically detected keywords. Both quantitative and qualitative analyses demonstrated the effectiveness of KENGIC. The performance achieved is very close to that of current state-of-the-art image caption generators that are trained in the unpaired setting. The analysis of this approach could also shed light on the generation process behind current top performing caption generators trained in the paired setting, and in addition, provide insights on the limitations of the current most widely used evaluation metrics in automatic image captioning.
Face2Text revisited: Improved data set and baseline results
May 24, 2022
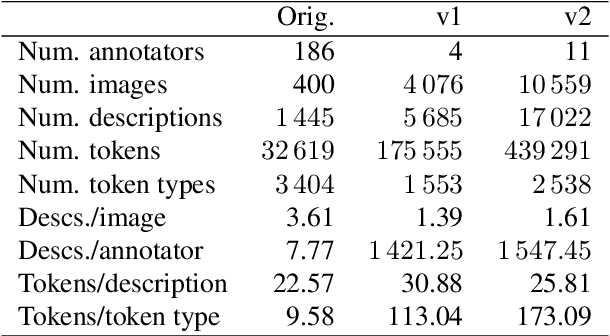

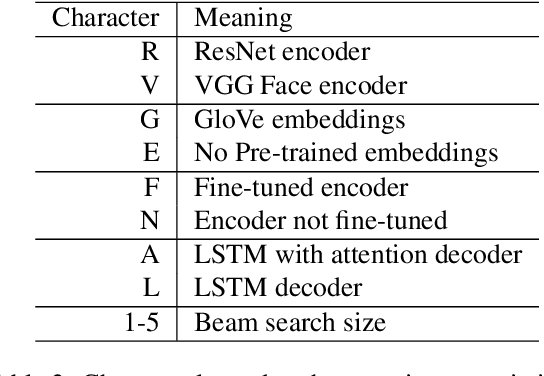
Current image description generation models do not transfer well to the task of describing human faces. To encourage the development of more human-focused descriptions, we developed a new data set of facial descriptions based on the CelebA image data set. We describe the properties of this data set, and present results from a face description generator trained on it, which explores the feasibility of using transfer learning from VGGFace/ResNet CNNs. Comparisons are drawn through both automated metrics and human evaluation by 76 English-speaking participants. The descriptions generated by the VGGFace-LSTM + Attention model are closest to the ground truth according to human evaluation whilst the ResNet-LSTM + Attention model obtained the highest CIDEr and CIDEr-D results (1.252 and 0.686 respectively). Together, the new data set and these experimental results provide data and baselines for future work in this area.
Automated segmentation of microtomography imaging of Egyptian mummies
May 14, 2021

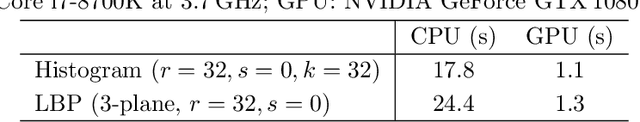
Propagation Phase Contrast Synchrotron Microtomography (PPC-SR${\mu}$CT) is the gold standard for non-invasive and non-destructive access to internal structures of archaeological remains. In this analysis, the virtual specimen needs to be segmented to separate different parts or materials, a process that normally requires considerable human effort. In the Automated SEgmentation of Microtomography Imaging (ASEMI) project, we developed a tool to automatically segment these volumetric images, using manually segmented samples to tune and train a machine learning model. For a set of four specimens of ancient Egyptian animal mummies we achieve an overall accuracy of 94-98% when compared with manually segmented slices, approaching the results of off-the-shelf commercial software using deep learning (97-99%) at much lower complexity. A qualitative analysis of the segmented output shows that our results are close in term of usability to those from deep learning, justifying the use of these techniques.
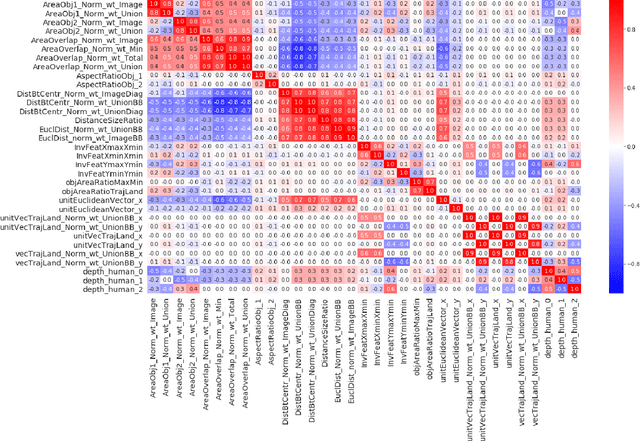
Predicting Relative Depth between Objects from Semantic Features
Jan 12, 2021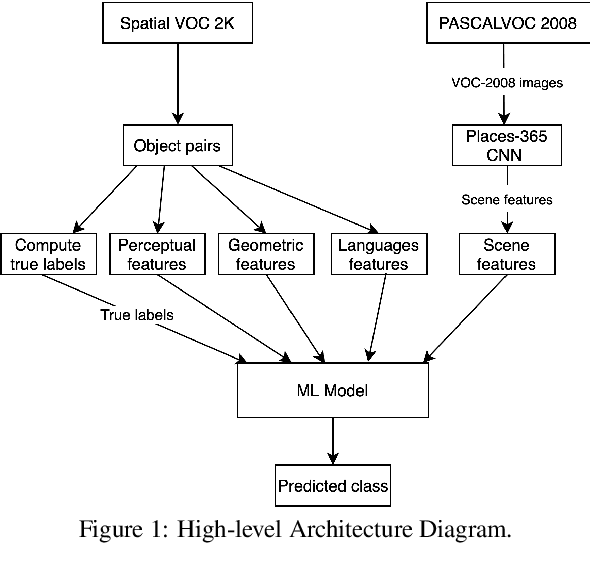

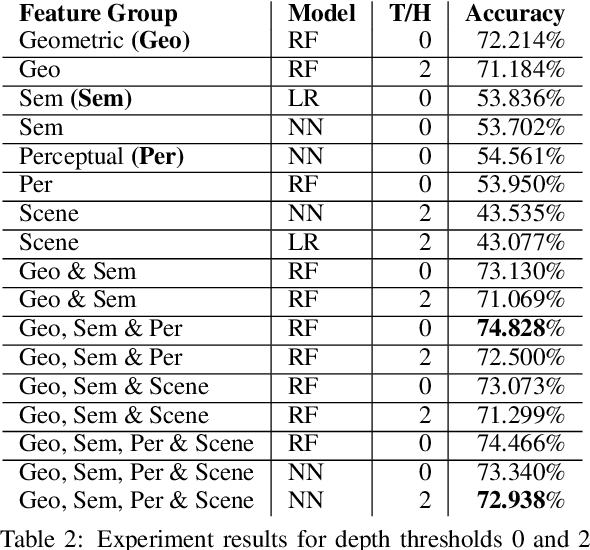
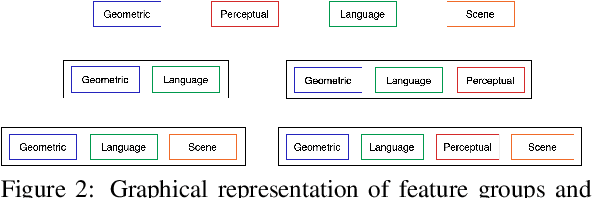
Vision and language tasks such as Visual Relation Detection and Visual Question Answering benefit from semantic features that afford proper grounding of language. The 3D depth of objects depicted in 2D images is one such feature. However it is very difficult to obtain accurate depth information without learning the appropriate features, which are scene dependent. The state of the art in this area are complex Neural Network models trained on stereo image data to predict depth per pixel. Fortunately, in some tasks, its only the relative depth between objects that is required. In this paper the extent to which semantic features can predict course relative depth is investigated. The problem is casted as a classification one and geometrical features based on object bounding boxes, object labels and scene attributes are computed and used as inputs to pattern recognition models to predict relative depth. i.e behind, in-front and neutral. The results are compared to those obtained from averaging the output of the monodepth neural network model, which represents the state-of-the art. An overall increase of 14% in relative depth accuracy over relative depth computed from the monodepth model derived results is achieved.
One vs Previous and Similar Classes Learning -- A Comparative Study
Jan 05, 2021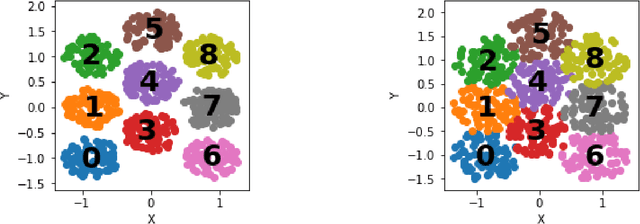
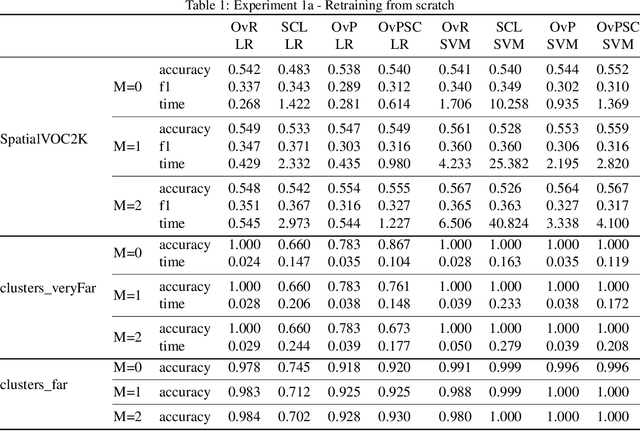
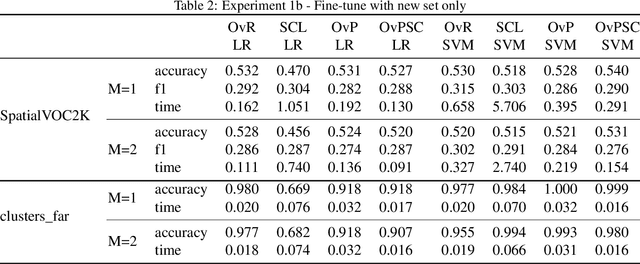
When dealing with multi-class classification problems, it is common practice to build a model consisting of a series of binary classifiers using a learning paradigm which dictates how the classifiers are built and combined to discriminate between the individual classes. As new data enters the system and the model needs updating, these models would often need to be retrained from scratch. This work proposes three learning paradigms which allow trained models to be updated without the need of retraining from scratch. A comparative analysis is performed to evaluate them against a baseline. Results show that the proposed paradigms are faster than the baseline at updating, with two of them being faster at training from scratch as well, especially on larger datasets, while retaining a comparable classification performance.
Optimising the Input Image to Improve Visual Relationship Detection
Mar 26, 2019
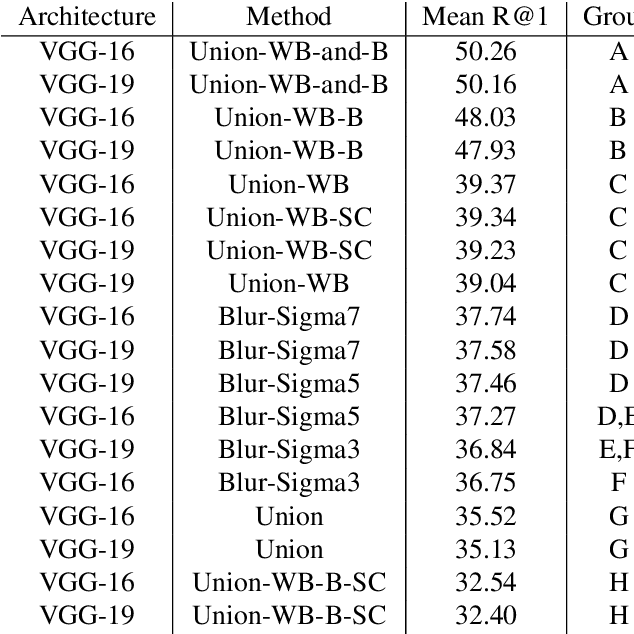

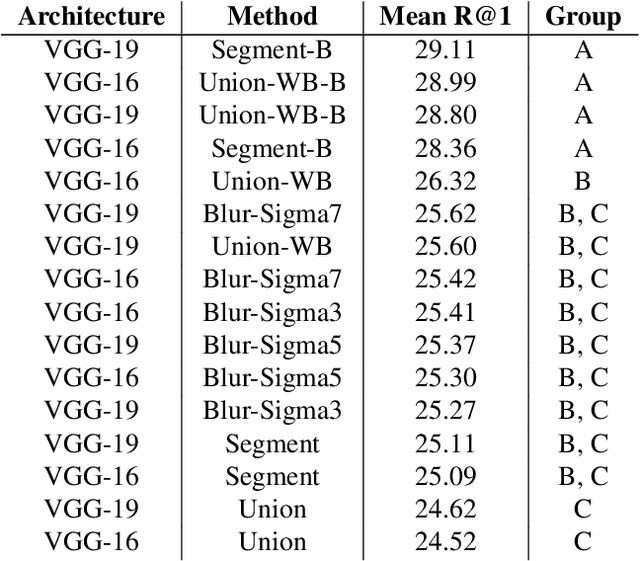
Visual Relationship Detection is defined as, given an image composed of a subject and an object, the correct relation is predicted. To improve the visual part of this difficult problem, ten preprocessing methods were tested to determine whether the widely used Union method yields the optimal results. Therefore, focusing solely on predicate prediction, no object detection and linguistic knowledge were used to prevent them from affecting the comparison results. Once fine-tuned, the Visual Geometry Group models were evaluated using Recall@1, per-predicate recall, activation maximisations, class activation maps, and error analysis. From this research it was found that using preprocessing methods such as the Union-Without-Background-and-with-Binary-mask (Union-WB-and-B) method yields significantly better results than the widely used Union method since, as designed, it enables the Convolutional Neural Network to also identify the subject and object in the convolutional layers instead of solely in the fully-connected layers.
Pre-gen metrics: Predicting caption quality metrics without generating captions
Oct 12, 2018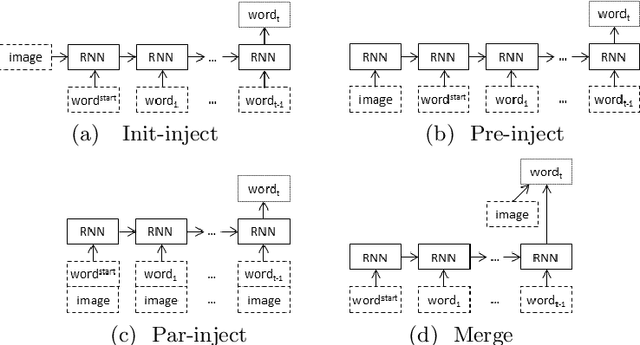
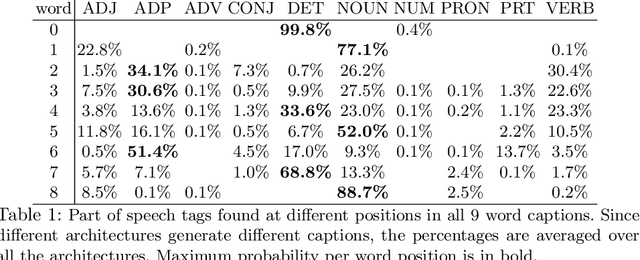
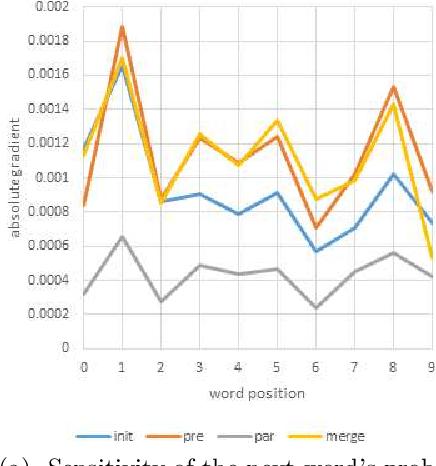
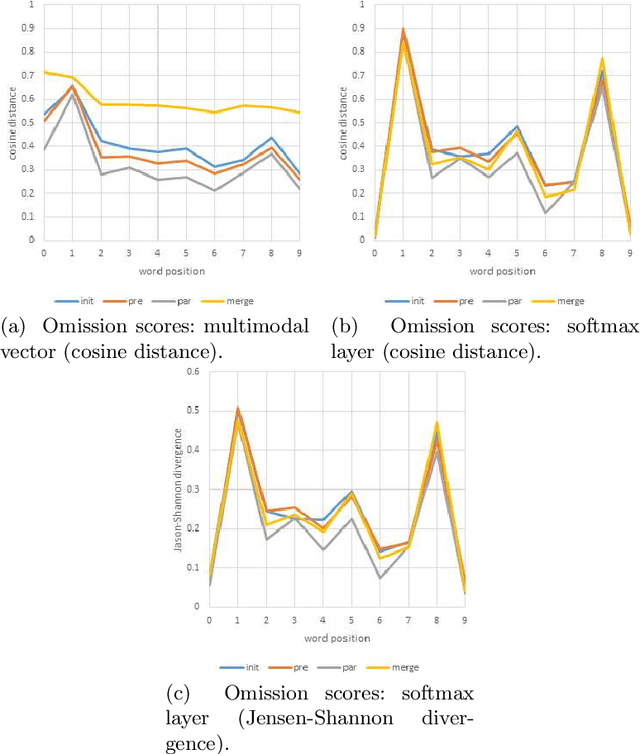
Image caption generation systems are typically evaluated against reference outputs. We show that it is possible to predict output quality without generating the captions, based on the probability assigned by the neural model to the reference captions. Such pre-gen metrics are strongly correlated to standard evaluation metrics.
Face2Text: Collecting an Annotated Image Description Corpus for the Generation of Rich Face Descriptions
Mar 10, 2018
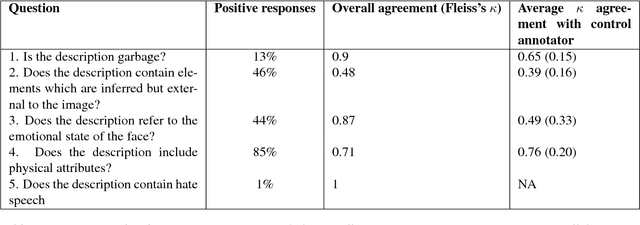
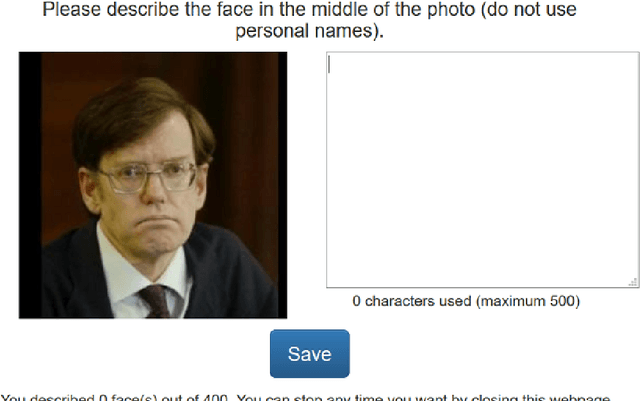
The past few years have witnessed renewed interest in NLP tasks at the interface between vision and language. One intensively-studied problem is that of automatically generating text from images. In this paper, we extend this problem to the more specific domain of face description. Unlike scene descriptions, face descriptions are more fine-grained and rely on attributes extracted from the image, rather than objects and relations. Given that no data exists for this task, we present an ongoing crowdsourcing study to collect a corpus of descriptions of face images taken `in the wild'. To gain a better understanding of the variation we find in face description and the possible issues that this may raise, we also conducted an annotation study on a subset of the corpus. Primarily, we found descriptions to refer to a mixture of attributes, not only physical, but also emotional and inferential, which is bound to create further challenges for current image-to-text methods.
Automatic Description Generation from Images: A Survey of Models, Datasets, and Evaluation Measures
Apr 24, 2017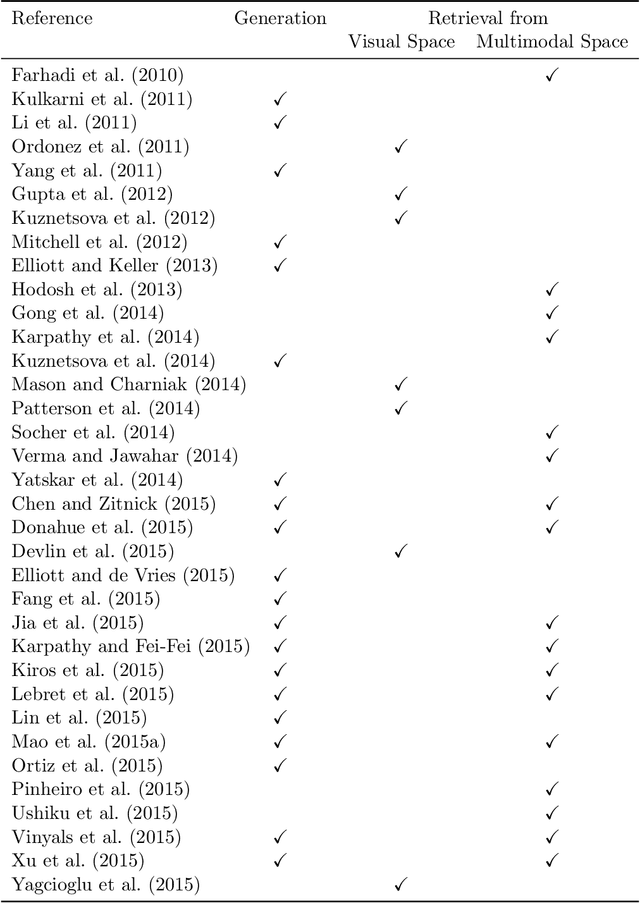
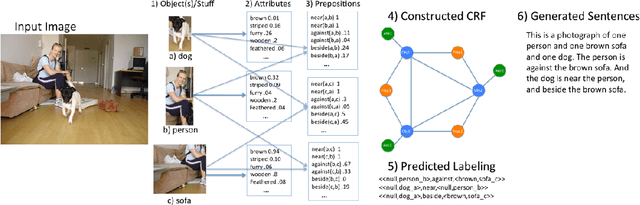

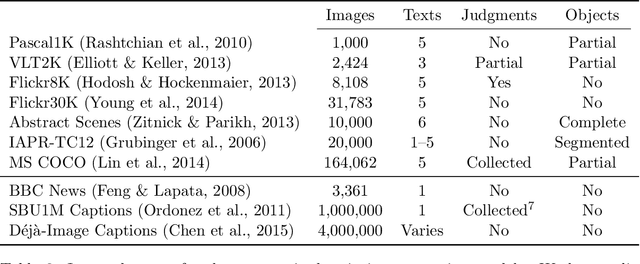
Automatic description generation from natural images is a challenging problem that has recently received a large amount of interest from the computer vision and natural language processing communities. In this survey, we classify the existing approaches based on how they conceptualize this problem, viz., models that cast description as either generation problem or as a retrieval problem over a visual or multimodal representational space. We provide a detailed review of existing models, highlighting their advantages and disadvantages. Moreover, we give an overview of the benchmark image datasets and the evaluation measures that have been developed to assess the quality of machine-generated image descriptions. Finally we extrapolate future directions in the area of automatic image description generation.