 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Point Cloud Processing with High-Dimensional Positional Encoding and Non-Local MLPs
Mar 04, 2026Multi-Layer Perceptron (MLP) models are the foundation of contemporary point cloud processing. However, their complex network architectures obscure the source of their strength and limit the application of these models. In this article, we develop a two-stage abstraction and refinement (ABS-REF) view for modular feature extraction in point cloud processing. This view elucidates that whereas the early models focused on ABS stages, the more recent techniques devise sophisticated REF stages to attain performance advantages. Then, we propose a High-dimensional Positional Encoding (HPE) module to explicitly utilize intrinsic positional information, extending the ``positional encoding'' concept from Transformer literature. HPE can be readily deployed in MLP-based architectures and is compatible with transformer-based methods. Within our ABS-REF view, we rethink local aggregation in MLP-based methods and propose replacing time-consuming local MLP operations, which are used to capture local relationships among neighbors. Instead, we use non-local MLPs for efficient non-local information updates, combined with the proposed HPE for effective local information representation. We leverage our modules to develop HPENets, a suite of MLP networks that follow the ABS-REF paradigm, incorporating a scalable HPE-based REF stage. Extensive experiments on seven public datasets across four different tasks show that HPENets deliver a strong balance between efficiency and effectiveness. Notably, HPENet surpasses PointNeXt, a strong MLP-based counterpart, by 1.1% mAcc, 4.0% mIoU, 1.8% mIoU, and 0.2% Cls. mIoU, with only 50.0%, 21.5%, 23.1%, 44.4% of FLOPs on ScanObjectNN, S3DIS, ScanNet, and ShapeNetPart, respectively. Source code is available at https://github.com/zouyanmei/HPENet_v2.git.
Deep Learning based 3D Segmentation: A Survey
Mar 10, 2021
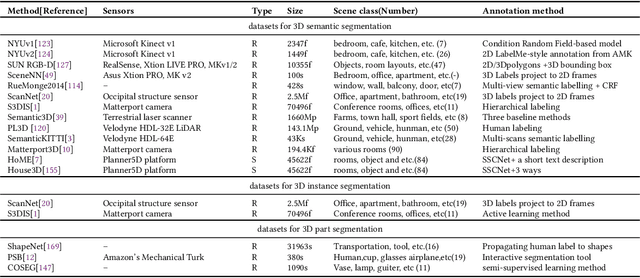
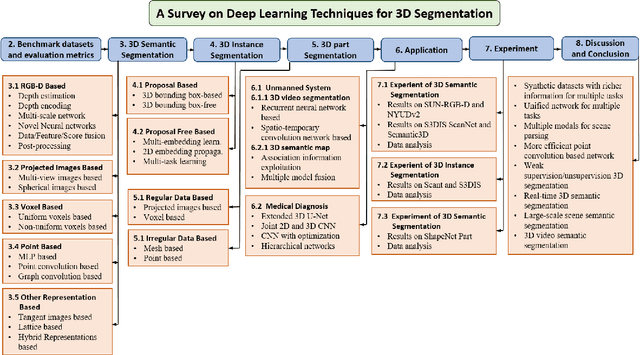
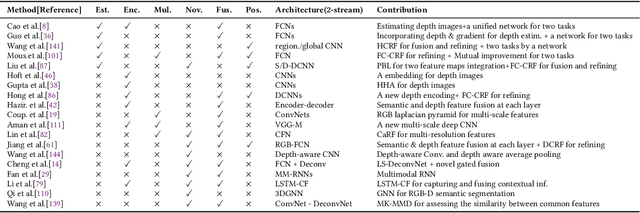
3D object segmentation is a fundamental and challenging problem in computer vision with applications in autonomous driving, robotics, augmented reality and medical image analysis. It has received significant attention from the computer vision, graphics and machine learning communities. Traditionally, 3D segmentation was performed with hand-crafted features and engineered methods which failed to achieve acceptable accuracy and could not generalize to large-scale data. Driven by their great success in 2D computer vision, deep learning techniques have recently become the tool of choice for 3D segmentation tasks as well. This has led to an influx of a large number of methods in the literature that have been evaluated on different benchmark datasets. This paper provides a comprehensive survey of recent progress in deep learning based 3D segmentation covering over 150 papers. It summarizes the most commonly used pipelines, discusses their highlights and shortcomings, and analyzes the competitive results of these segmentation methods. Based on the analysis, it also provides promising research directions for the future.