 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
KeepAugment: A Simple Information-Preserving Data Augmentation Approach
Nov 23, 2020

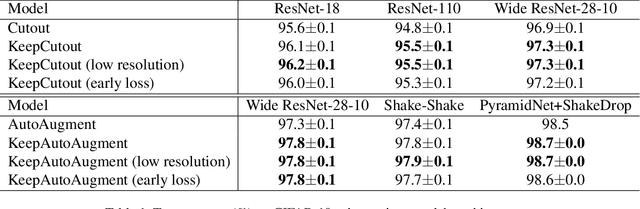
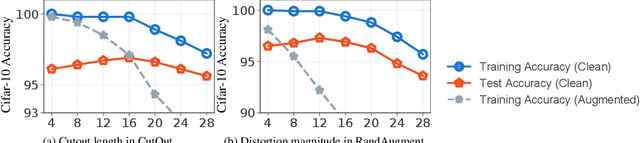
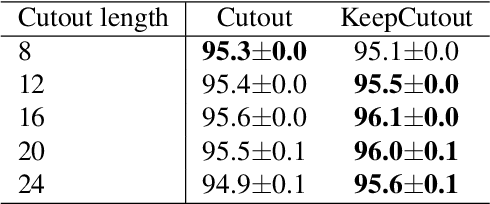
Data augmentation (DA) is an essential technique for training state-of-the-art deep learning systems. In this paper, we empirically show data augmentation might introduce noisy augmented examples and consequently hurt the performance on unaugmented data during inference. To alleviate this issue, we propose a simple yet highly effective approach, dubbed \emph{KeepAugment}, to increase augmented images fidelity. The idea is first to use the saliency map to detect important regions on the original images and then preserve these informative regions during augmentation. This information-preserving strategy allows us to generate more faithful training examples. Empirically, we demonstrate our method significantly improves on a number of prior art data augmentation schemes, e.g. AutoAugment, Cutout, random erasing, achieving promising results on image classification, semi-supervised image classification, multi-view multi-camera tracking and object detection.
Patch Shortcuts: Interpretable Proxy Models Efficiently Find Black-Box Vulnerabilities
Apr 22, 2021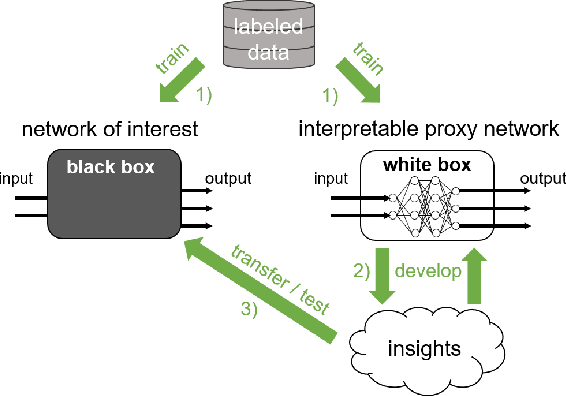
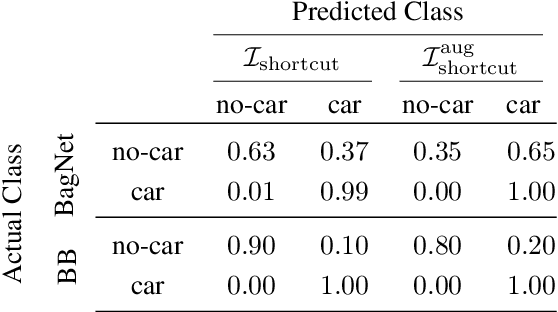

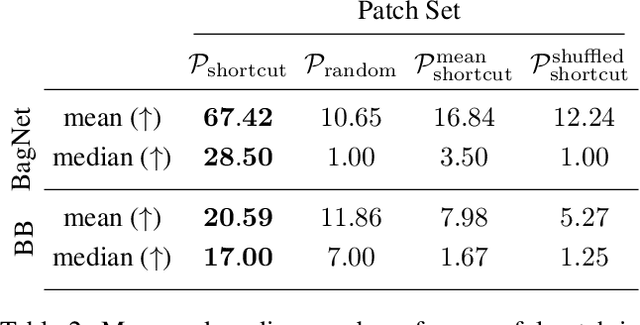
An important pillar for safe machine learning (ML) is the systematic mitigation of weaknesses in neural networks to afford their deployment in critical applications. An ubiquitous class of safety risks are learned shortcuts, i.e. spurious correlations a network exploits for its decisions that have no semantic connection to the actual task. Networks relying on such shortcuts bear the risk of not generalizing well to unseen inputs. Explainability methods help to uncover such network vulnerabilities. However, many of these techniques are not directly applicable if access to the network is constrained, in so-called black-box setups. These setups are prevalent when using third-party ML components. To address this constraint, we present an approach to detect learned shortcuts using an interpretable-by-design network as a proxy to the black-box model of interest. Leveraging the proxy's guarantees on introspection we automatically extract candidates for learned shortcuts. Their transferability to the black box is validated in a systematic fashion. Concretely, as proxy model we choose a BagNet, which bases its decisions purely on local image patches. We demonstrate on the autonomous driving dataset A2D2 that extracted patch shortcuts significantly influence the black box model. By efficiently identifying such patch-based vulnerabilities, we contribute to safer ML models.
PSF Estimation in Crowded Astronomical Imagery as a Convolutional Dictionary Learning Problem
Feb 07, 2021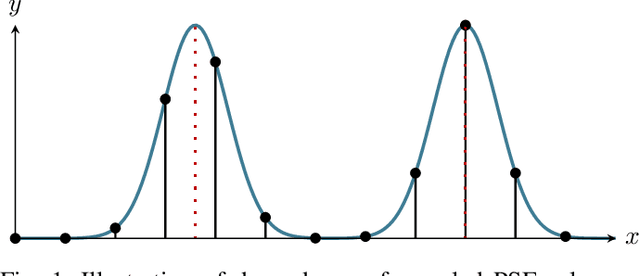
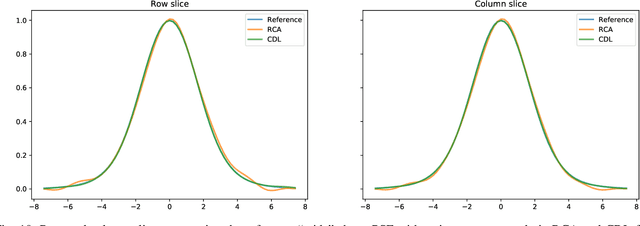
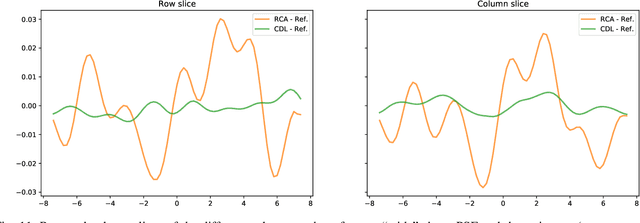
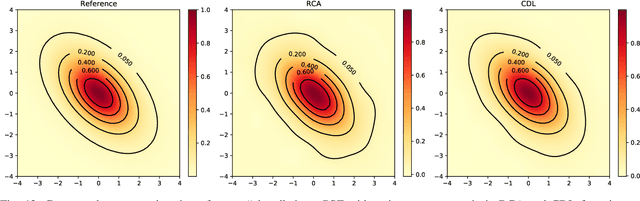
We present a new algorithm for estimating the Point Spread Function (PSF) in wide-field astronomical images with extreme source crowding. Robust and accurate PSF estimation in crowded astronomical images dramatically improves the fidelity of astrometric and photometric measurements extracted from wide-field sky monitoring imagery. Our radically new approach utilizes convolutional sparse representations to model the continuous functions involved in the image formation. This approach avoids the need to detect and precisely localize individual point sources that is shared by existing methods. In experiments involving simulated astronomical imagery, it significantly outperforms the recent alternative method with which it is compared.
Very Lightweight Photo Retouching Network with Conditional Sequential Modulation
Apr 13, 2021
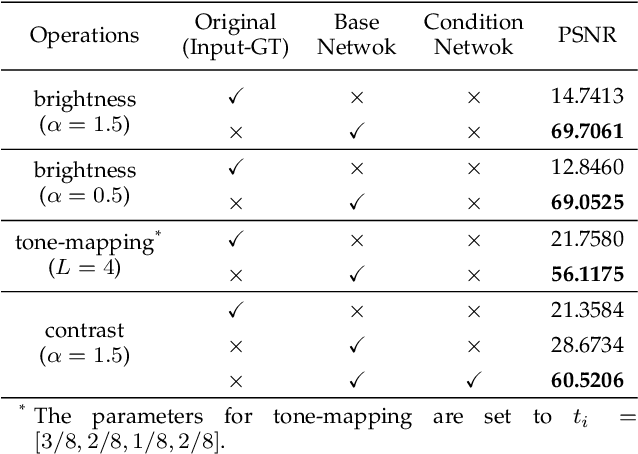
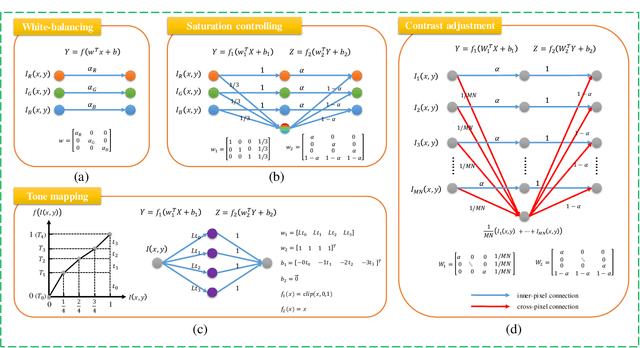
Photo retouching aims at improving the aesthetic visual quality of images that suffer from photographic defects such as poor contrast, over/under exposure, and inharmonious saturation. In practice, photo retouching can be accomplished by a series of image processing operations. As most commonly-used retouching operations are pixel-independent, i.e., the manipulation on one pixel is uncorrelated with its neighboring pixels, we can take advantage of this property and design a specialized algorithm for efficient global photo retouching. We analyze these global operations and find that they can be mathematically formulated by a Multi-Layer Perceptron (MLP). Based on this observation, we propose an extremely lightweight framework -- Conditional Sequential Retouching Network (CSRNet). Benefiting from the utilization of $1\times1$ convolution, CSRNet only contains less than 37K trainable parameters, which are orders of magnitude smaller than existing learning-based methods. Experiments show that our method achieves state-of-the-art performance on the benchmark MIT-Adobe FiveK dataset quantitively and qualitatively. In addition to achieve global photo retouching, the proposed framework can be easily extended to learn local enhancement effects. The extended model, namly CSRNet-L, also achieves competitive results in various local enhancement tasks. Codes will be available.
SSLM: Self-Supervised Learning for Medical Diagnosis from MR Video
Apr 22, 2021
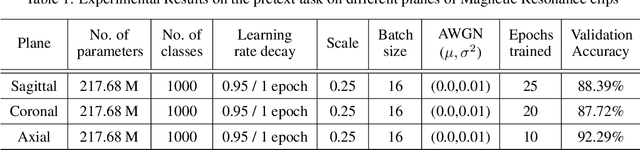
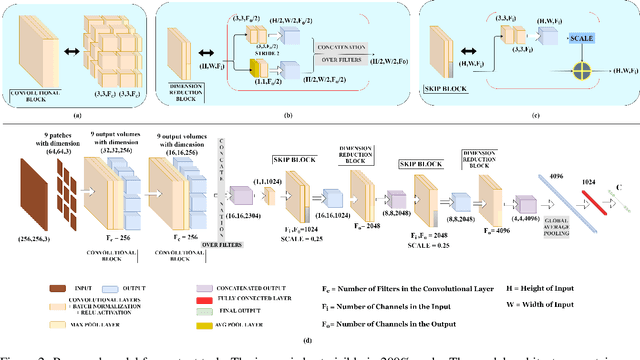
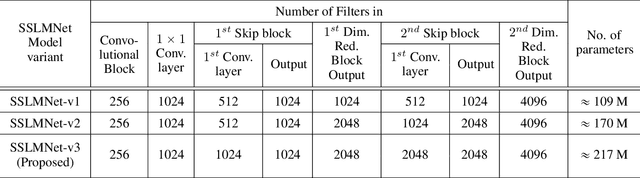
In medical image analysis, the cost of acquiring high-quality data and their annotation by experts is a barrier in many medical applications. Most of the techniques used are based on supervised learning framework and need a large amount of annotated data to achieve satisfactory performance. As an alternative, in this paper, we propose a self-supervised learning approach to learn the spatial anatomical representations from the frames of magnetic resonance (MR) video clips for the diagnosis of knee medical conditions. The pretext model learns meaningful spatial context-invariant representations. The downstream task in our paper is a class imbalanced multi-label classification. Different experiments show that the features learnt by the pretext model provide explainable performance in the downstream task. Moreover, the efficiency and reliability of the proposed pretext model in learning representations of minority classes without applying any strategy towards imbalance in the dataset can be seen from the results. To the best of our knowledge, this work is the first work of its kind in showing the effectiveness and reliability of self-supervised learning algorithms in class imbalanced multi-label classification tasks on MR video. The code for evaluation of the proposed work is available at https://github.com/sadimanna/sslm
Deep learning using Havrda-Charvat entropy for classification of pulmonary endomicroscopy
Apr 13, 2021
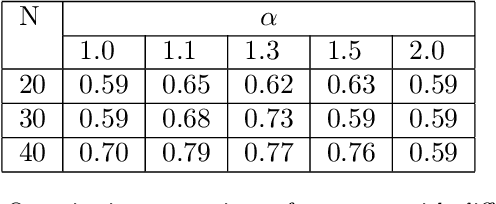
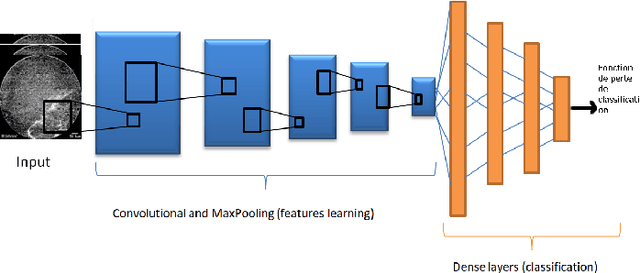
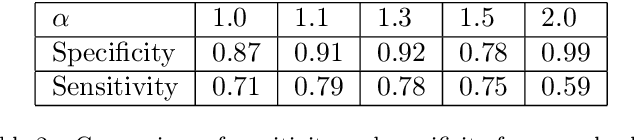
Pulmonary optical endomicroscopy (POE) is an imaging technology in real time. It allows to examine pulmonary alveoli at a microscopic level. Acquired in clinical settings, a POE image sequence can have as much as 25% of the sequence being uninformative frames (i.e. pure-noise and motion artefacts). For future data analysis, these uninformative frames must be first removed from the sequence. Therefore, the objective of our work is to develop an automatic detection method of uninformative images in endomicroscopy images. We propose to take the detection problem as a classification one. Considering advantages of deep learning methods, a classifier based on CNN (Convolutional Neural Network) is designed with a new loss function based on Havrda-Charvat entropy which is a parametrical generalization of the Shannon entropy. We propose to use this formula to get a better hold on all sorts of data since it provides a model more stable than the Shannon entropy. Our method is tested on one POE dataset including 2947 distinct images, is showing better results than using Shannon entropy and behaves better with regard to the problem of overfitting. Keywords: Deep Learning, CNN, Shannon entropy, Havrda-Charvat entropy, Pulmonary optical endomicroscopy.
* 8 pages, 7 figures
Training Medical Image Analysis Systems like Radiologists
Jun 12, 2018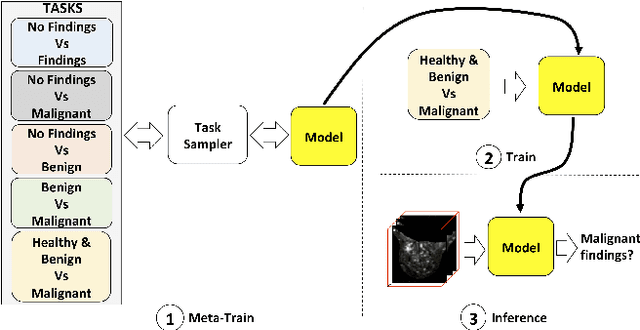
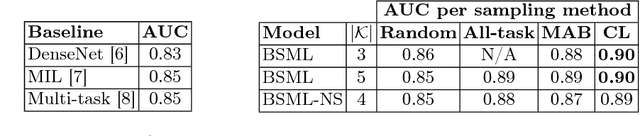

The training of medical image analysis systems using machine learning approaches follows a common script: collect and annotate a large dataset, train the classifier on the training set, and test it on a hold-out test set. This process bears no direct resemblance with radiologist training, which is based on solving a series of tasks of increasing difficulty, where each task involves the use of significantly smaller datasets than those used in machine learning. In this paper, we propose a novel training approach inspired by how radiologists are trained. In particular, we explore the use of meta-training that models a classifier based on a series of tasks. Tasks are selected using teacher-student curriculum learning, where each task consists of simple classification problems containing small training sets. We hypothesize that our proposed meta-training approach can be used to pre-train medical image analysis models. This hypothesis is tested on the automatic breast screening classification from DCE-MRI trained with weakly labeled datasets. The classification performance achieved by our approach is shown to be the best in the field for that application, compared to state of art baseline approaches: DenseNet, multiple instance learning and multi-task learning.
Optimized CNN for PolSAR Image Classification via Differentiable Neural Architecture Search
Nov 16, 2019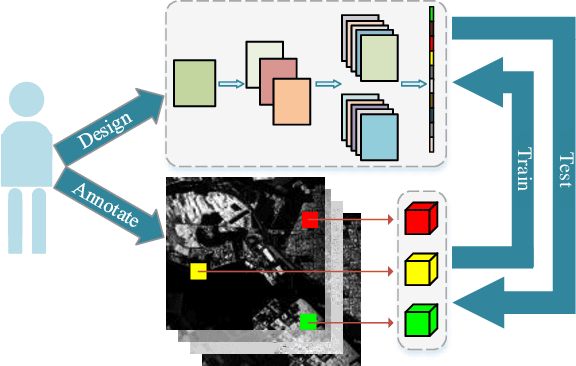
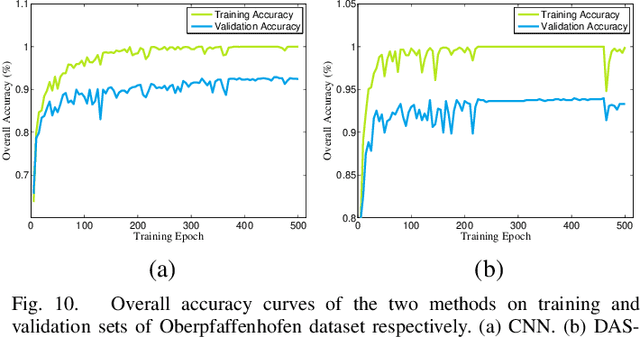
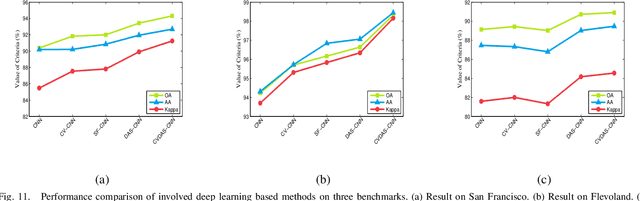
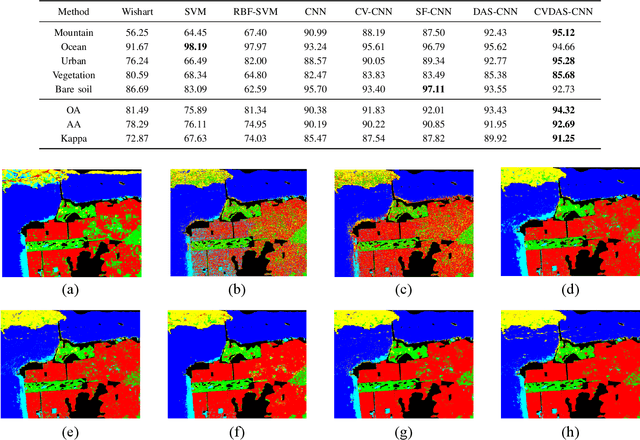
Convolutional neural networks (CNNs) realize the automation of feature engineering and their applications have shown good performance in polarimetric synthetic aperture radar (PolSAR) image classification. Excellent hand-crafted architectures of CNNs incorporated the wisdom of human experts, which is an important reason for CNN's success. However, the design of the architectures is a difficult problem, which needs a lot of professional knowledge as well as computational resources. Moreover, the architecture designed by hand must be suboptimal, because it is only one of thousands of unobserved but objective existed paths. Considering that the success of deep learning is largely due to its automation of the feature engineering process, how to design automatic architecture searching methods to replace the hand-crafted ones is an interesting topic. In this paper, we explore the application of neural architecture search (NAS) in PolSAR area for the first time. Different from the utilization of existing NAS methods, we propose a differentiable architecture search (DAS) method which is customized for PolSAR classification. The proposed DAS is equipped with a PolSAR tailored search space and an improved one-shot search strategy. By DAS, the weights parameters and architecture parameters (corresponds to the hyperparameters but not the topologies) can be optimized by stochastic gradient descent method during the training. The optimized architecture parameters should be transformed into corresponding CNN architecture and re-train to achieve high-precision PolSAR classification. In addition, complex-valued DAS is developed to take into account the characteristics of PolSAR images so as to further improve the performance. Experiments on three PolSAR benchmark datasets show that the CNNs obtained by searching have better classification performance than the hand-crafted ones.
Topology, homogeneity and scale factors for object detection: application of eCognition software for urban mapping using multispectral satellite image
Dec 06, 2018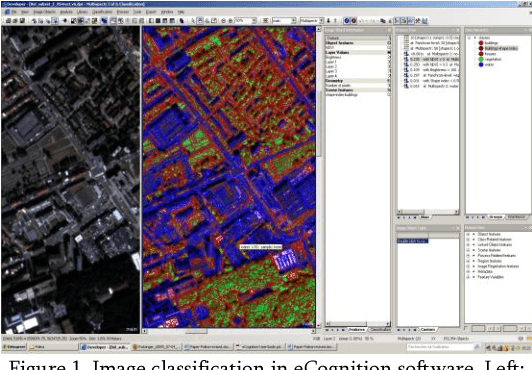
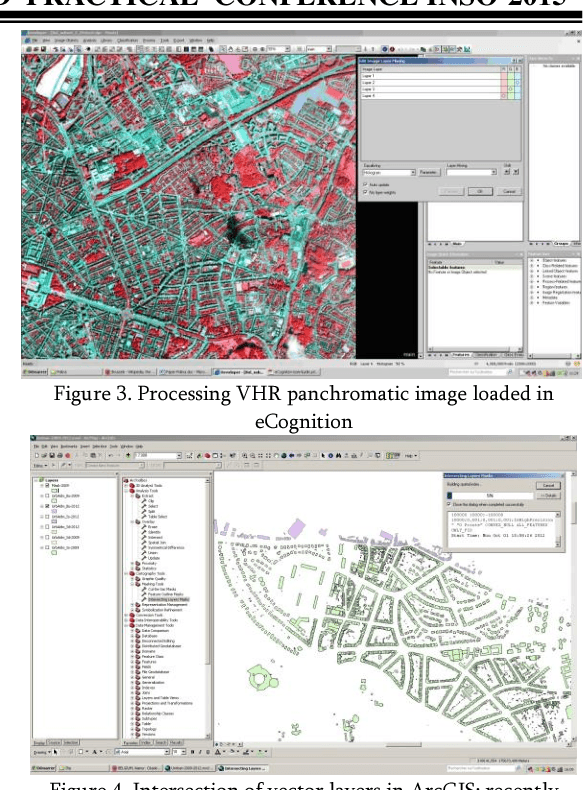
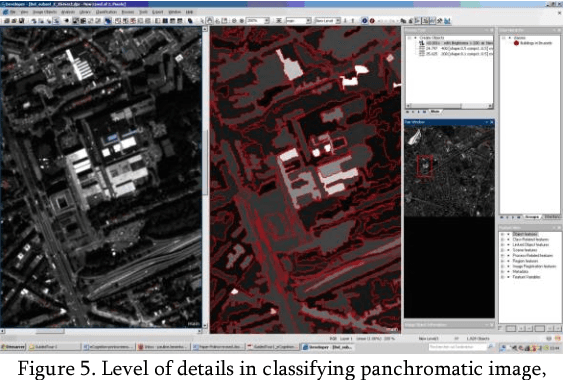
The research scope of this paper is to apply spatial object based image analysis (OBIA) method for processing panchromatic multispectral image covering study area of Brussels for urban mapping. The aim is to map different land cover types and more specifically, built-up areas from the very high resolution (VHR) satellite image using OBIA approach. A case study covers urban landscapes in the eastern areas of the city of Brussels, Belgium. Technically, this research was performed in eCognition raster processing software demonstrating excellent results of image segmentation and classification. The tools embedded in eCognition enabled to perform image segmentation and objects classification processes in a semi-automated regime, which is useful for the city planning, spatial analysis and urban growth analysis. The combination of the OBIA method together with technical tools of the eCognition demonstrated applicability of this method for urban mapping in densely populated areas, e.g. in megapolis and capital cities. The methodology included multiresolution segmentation and classification of the created objects.
* 6 pages, 12 figures, INSO2015, Ed. by A. Girgvliani et al. Akaki Tsereteli State University, Kutaisi (Imereti), Georgia
D$^2$IM-Net: Learning Detail Disentangled Implicit Fields from Single Images
Dec 11, 2020
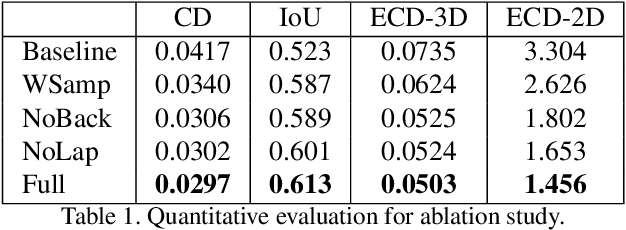
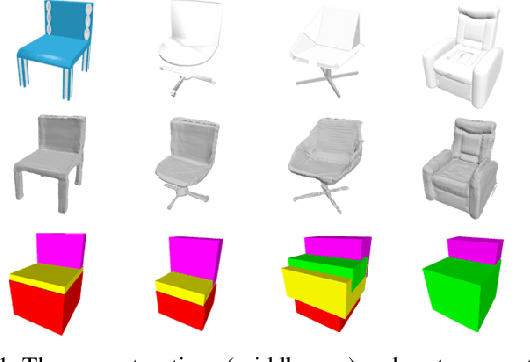
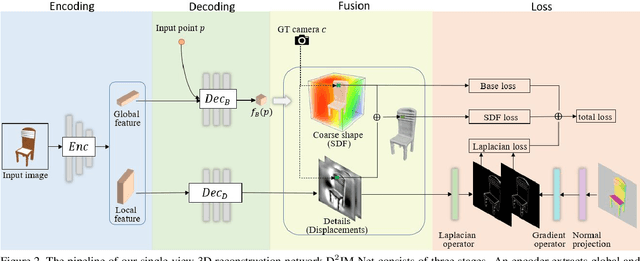
We present the first single-view 3D reconstruction network aimed at recovering geometric details from an input image which encompass both topological shape structures and surface features. Our key idea is to train the network to learn a detail disentangled reconstruction consisting of two functions, one implicit field representing the coarse 3D shape and the other capturing the details. Given an input image, our network, coined D$^2$IM-Net, encodes it into global and local features which are respectively fed into two decoders. The base decoder uses the global features to reconstruct a coarse implicit field, while the detail decoder reconstructs, from the local features, two displacement maps, defined over the front and back sides of the captured object. The final 3D reconstruction is a fusion between the base shape and the displacement maps, with three losses enforcing the recovery of coarse shape, overall structure, and surface details via a novel Laplacian term.