 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Improving Generation and Evaluation of Visual Stories via Semantic Consistency
May 20, 2021

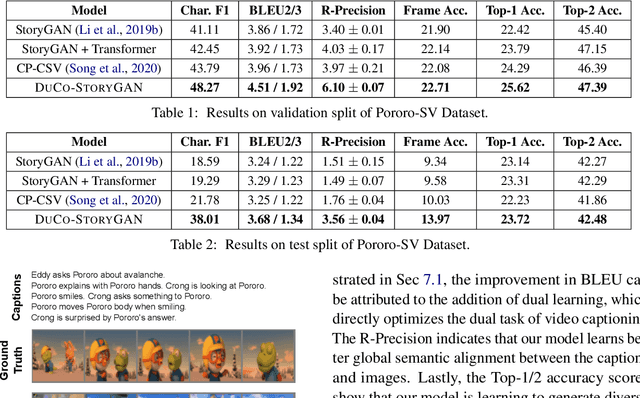
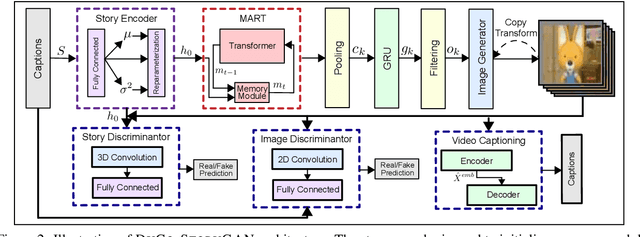
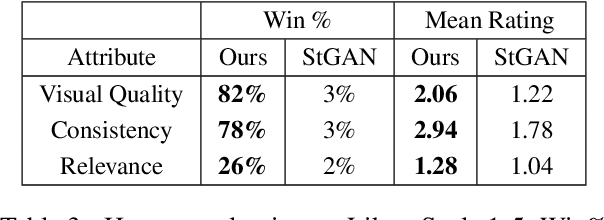
Story visualization is an under-explored task that falls at the intersection of many important research directions in both computer vision and natural language processing. In this task, given a series of natural language captions which compose a story, an agent must generate a sequence of images that correspond to the captions. Prior work has introduced recurrent generative models which outperform text-to-image synthesis models on this task. However, there is room for improvement of generated images in terms of visual quality, coherence and relevance. We present a number of improvements to prior modeling approaches, including (1) the addition of a dual learning framework that utilizes video captioning to reinforce the semantic alignment between the story and generated images, (2) a copy-transform mechanism for sequentially-consistent story visualization, and (3) MART-based transformers to model complex interactions between frames. We present ablation studies to demonstrate the effect of each of these techniques on the generative power of the model for both individual images as well as the entire narrative. Furthermore, due to the complexity and generative nature of the task, standard evaluation metrics do not accurately reflect performance. Therefore, we also provide an exploration of evaluation metrics for the model, focused on aspects of the generated frames such as the presence/quality of generated characters, the relevance to captions, and the diversity of the generated images. We also present correlation experiments of our proposed automated metrics with human evaluations. Code and data available at: https://github.com/adymaharana/StoryViz
CIE XYZ Net: Unprocessing Images for Low-Level Computer Vision Tasks
Jun 23, 2020



Cameras currently allow access to two image states: (i) a minimally processed linear raw-RGB image state (i.e., raw sensor data) or (ii) a highly-processed nonlinear image state (e.g., sRGB). There are many computer vision tasks that work best with a linear image state, such as image deblurring and image dehazing. Unfortunately, the vast majority of images are saved in the nonlinear image state. Because of this, a number of methods have been proposed to "unprocess" nonlinear images back to a raw-RGB state. However, existing unprocessing methods have a drawback because raw-RGB images are sensor-specific. As a result, it is necessary to know which camera produced the sRGB output and use a method or network tailored for that sensor to properly unprocess it. This paper addresses this limitation by exploiting another camera image state that is not available as an output, but it is available inside the camera pipeline. In particular, cameras apply a colorimetric conversion step to convert the raw-RGB image to a device-independent space based on the CIE XYZ color space before they apply the nonlinear photo-finishing. Leveraging this canonical image state, we propose a deep learning framework, CIE XYZ Net, that can unprocess a nonlinear image back to the canonical CIE XYZ image. This image can then be processed by any low-level computer vision operator and re-rendered back to the nonlinear image. We demonstrate the usefulness of the CIE XYZ Net on several low-level vision tasks and show significant gains that can be obtained by this processing framework. Code and dataset are publicly available at https://github.com/mahmoudnafifi/CIE_XYZ_NET.
Diverse and Controllable Image Captioning with Part-of-Speech Guidance
May 31, 2018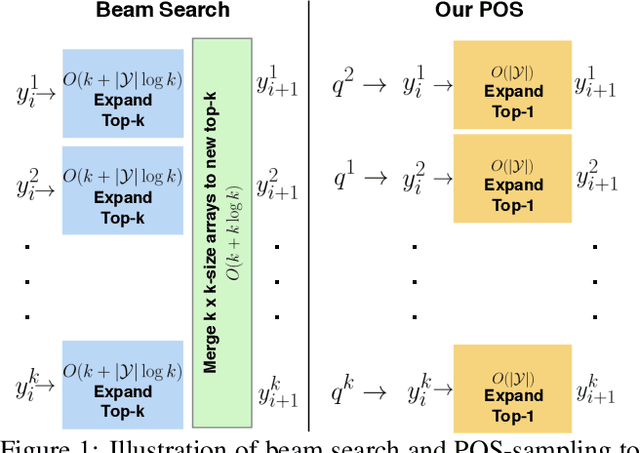
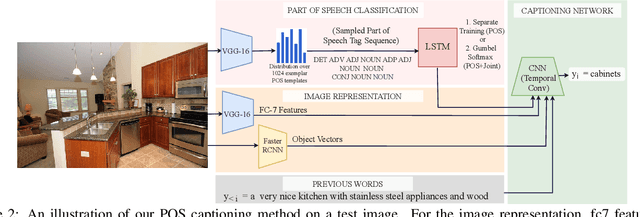
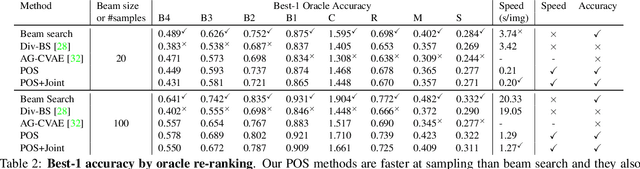
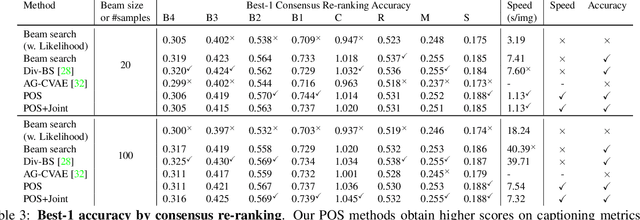
Automatically describing an image is an important capability for virtual assistants. Significant progress has been achieved in recent years on this task of image captioning. However, classical prediction techniques based on maximum likelihood trained LSTM nets don't embrace the inherent ambiguity of image captioning. To address this concern, recent variational auto-encoder and generative adversarial network based methods produce a set of captions by sampling from an abstract latent space. But, this latent space has limited interpretability and therefore, a control mechanism for captioning remains an open problem. This paper proposes a captioning technique conditioned on part-of-speech. Our method provides human interpretable control in form of part-of-speech. Importantly, part-of-speech is a language prior, and conditioning on it provides: (i) more diversity as evaluated by counting n-grams and the novel sentences generated, (ii) achieves high accuracy for the diverse captions on standard captioning metrics.
Unsupervised Person Re-identification via Simultaneous Clustering and Consistency Learning
Apr 01, 2021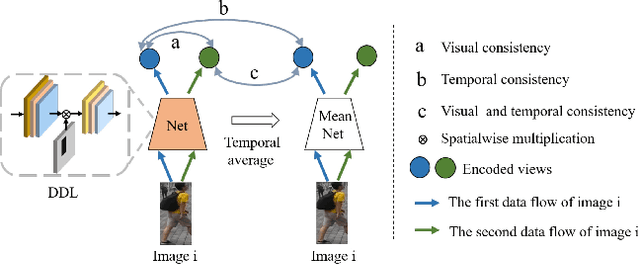
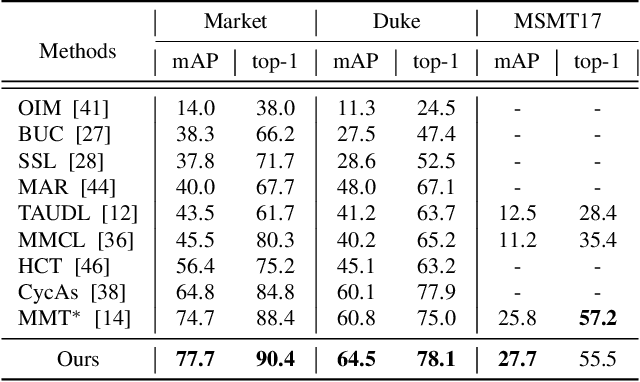
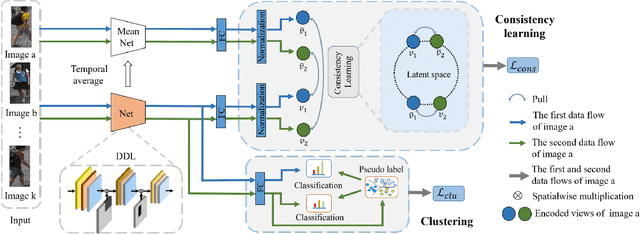
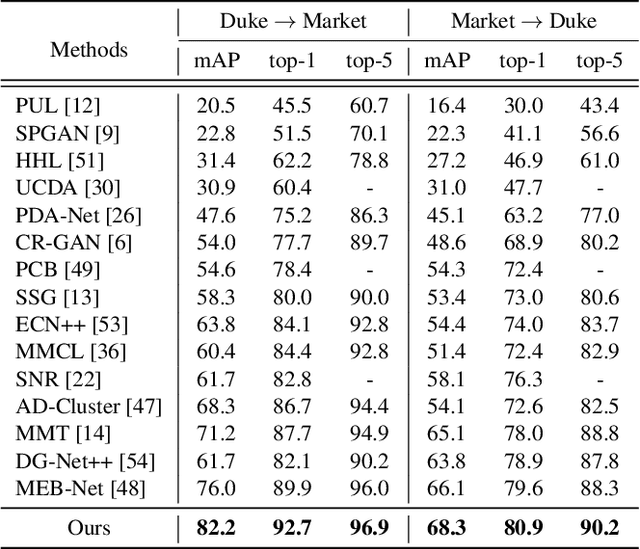
Unsupervised person re-identification (re-ID) has become an important topic due to its potential to resolve the scalability problem of supervised re-ID models. However, existing methods simply utilize pseudo labels from clustering for supervision and thus have not yet fully explored the semantic information in data itself, which limits representation capabilities of learned models. To address this problem, we design a pretext task for unsupervised re-ID by learning visual consistency from still images and temporal consistency during training process, such that the clustering network can separate the images into semantic clusters automatically. Specifically, the pretext task learns semantically meaningful representations by maximizing the agreement between two encoded views of the same image via a consistency loss in latent space. Meanwhile, we optimize the model by grouping the two encoded views into same cluster, thus enhancing the visual consistency between views. Experiments on Market-1501, DukeMTMC-reID and MSMT17 datasets demonstrate that our proposed approach outperforms the state-of-the-art methods by large margins.
Learning to Guide Decoding for Image Captioning
Apr 03, 2018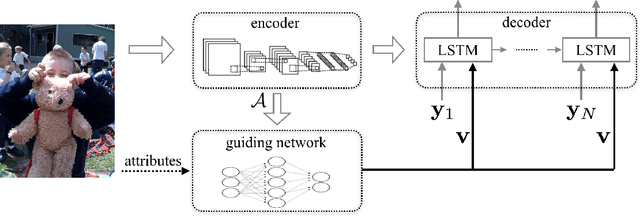
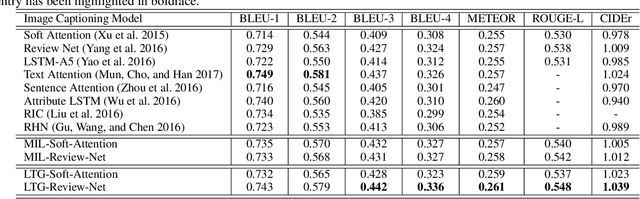
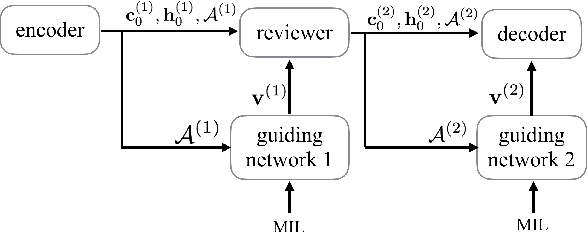
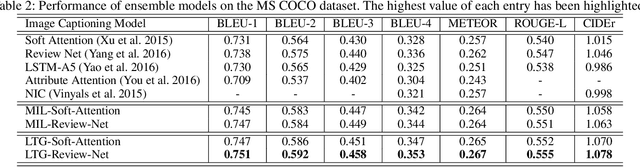
Recently, much advance has been made in image captioning, and an encoder-decoder framework has achieved outstanding performance for this task. In this paper, we propose an extension of the encoder-decoder framework by adding a component called guiding network. The guiding network models the attribute properties of input images, and its output is leveraged to compose the input of the decoder at each time step. The guiding network can be plugged into the current encoder-decoder framework and trained in an end-to-end manner. Hence, the guiding vector can be adaptively learned according to the signal from the decoder, making itself to embed information from both image and language. Additionally, discriminative supervision can be employed to further improve the quality of guidance. The advantages of our proposed approach are verified by experiments carried out on the MS COCO dataset.
Shadow Neural Radiance Fields for Multi-view Satellite Photogrammetry
Apr 20, 2021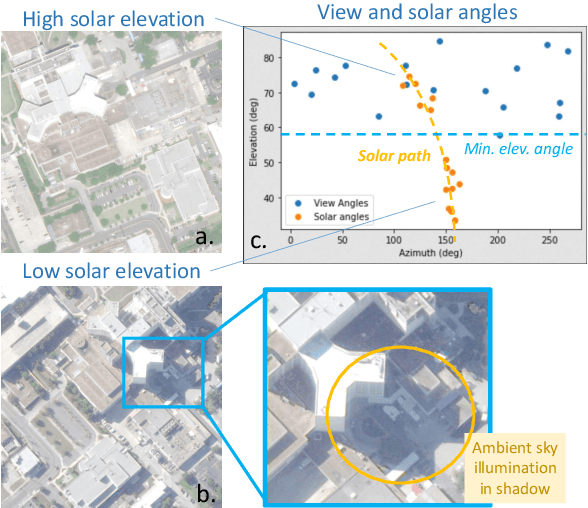
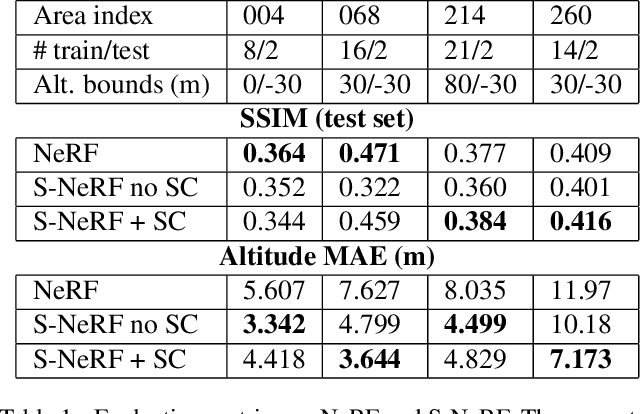
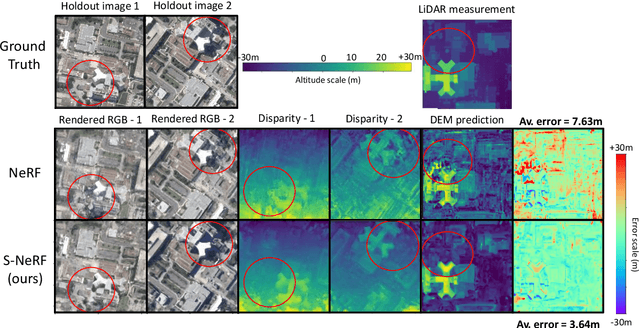

We present a new generic method for shadow-aware multi-view satellite photogrammetry of Earth Observation scenes. Our proposed method, the Shadow Neural Radiance Field (S-NeRF) follows recent advances in implicit volumetric representation learning. For each scene, we train S-NeRF using very high spatial resolution optical images taken from known viewing angles. The learning requires no labels or shape priors: it is self-supervised by an image reconstruction loss. To accommodate for changing light source conditions both from a directional light source (the Sun) and a diffuse light source (the sky), we extend the NeRF approach in two ways. First, direct illumination from the Sun is modeled via a local light source visibility field. Second, indirect illumination from a diffuse light source is learned as a non-local color field as a function of the position of the Sun. Quantitatively, the combination of these factors reduces the altitude and color errors in shaded areas, compared to NeRF. The S-NeRF methodology not only performs novel view synthesis and full 3D shape estimation, it also enables shadow detection, albedo synthesis, and transient object filtering, without any explicit shape supervision.
MedAug: Contrastive learning leveraging patient metadata improves representations for chest X-ray interpretation
Feb 21, 2021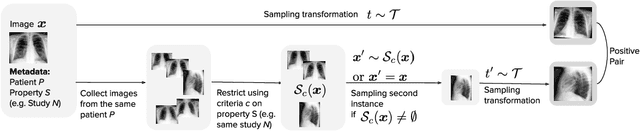
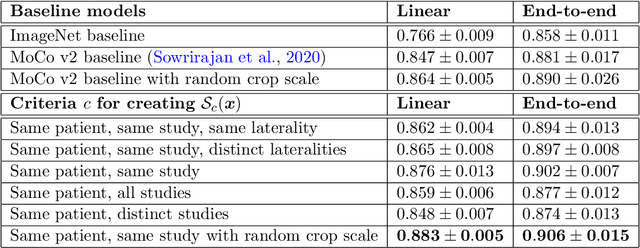

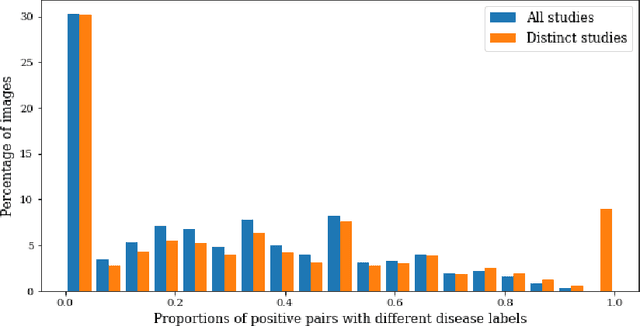
Self-supervised contrastive learning between pairs of multiple views of the same image has been shown to successfully leverage unlabeled data to produce meaningful visual representations for both natural and medical images. However, there has been limited work on determining how to select pairs for medical images, where availability of patient metadata can be leveraged to improve representations. In this work, we develop a method to select positive pairs coming from views of possibly different images through the use of patient metadata. We compare strategies for selecting positive pairs for chest X-ray interpretation including requiring them to be from the same patient, imaging study or laterality. We evaluate downstream task performance by fine-tuning the linear layer on 1% of the labeled dataset for pleural effusion classification. Our best performing positive pair selection strategy, which involves using images from the same patient from the same study across all lateralities, achieves a performance increase of 3.4% and 14.4% in mean AUC from both a previous contrastive method and ImageNet pretrained baseline respectively. Our controlled experiments show that the keys to improving downstream performance on disease classification are (1) using patient metadata to appropriately create positive pairs from different images with the same underlying pathologies, and (2) maximizing the number of different images used in query pairing. In addition, we explore leveraging patient metadata to select hard negative pairs for contrastive learning, but do not find improvement over baselines that do not use metadata. Our method is broadly applicable to medical image interpretation and allows flexibility for incorporating medical insights in choosing pairs for contrastive learning.
Passive Inter-Photon Imaging
Apr 11, 2021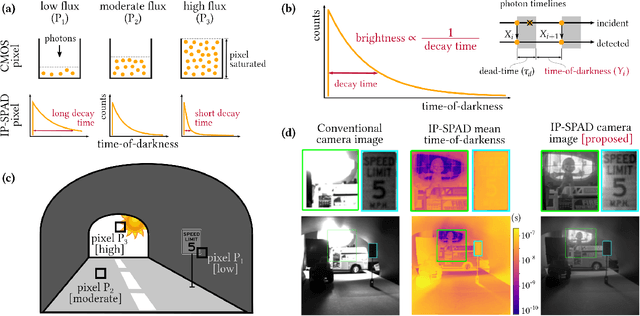

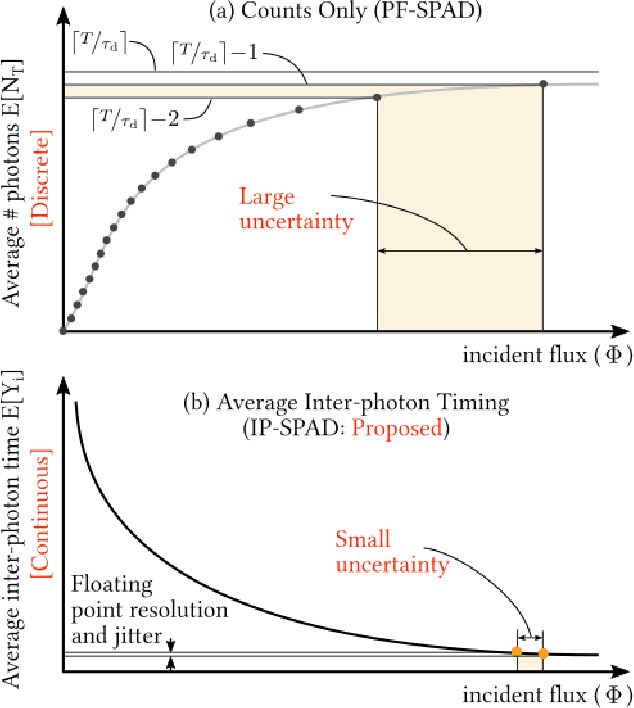
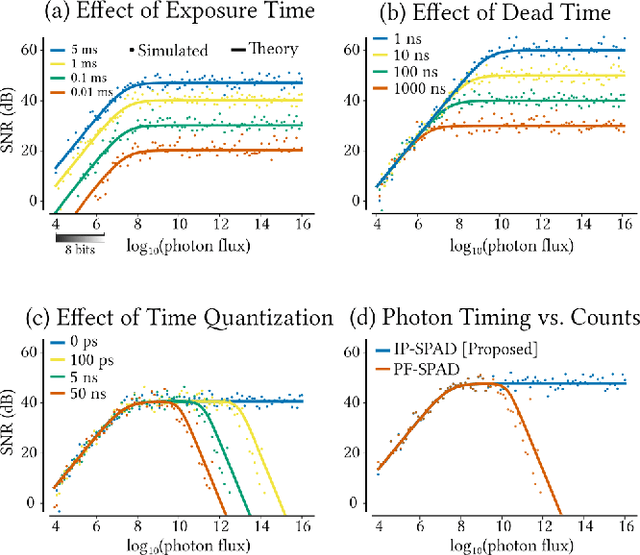
Digital camera pixels measure image intensities by converting incident light energy into an analog electrical current, and then digitizing it into a fixed-width binary representation. This direct measurement method, while conceptually simple, suffers from limited dynamic range and poor performance under extreme illumination -- electronic noise dominates under low illumination, and pixel full-well capacity results in saturation under bright illumination. We propose a novel intensity cue based on measuring inter-photon timing, defined as the time delay between detection of successive photons. Based on the statistics of inter-photon times measured by a time-resolved single-photon sensor, we develop theory and algorithms for a scene brightness estimator which works over extreme dynamic range; we experimentally demonstrate imaging scenes with a dynamic range of over ten million to one. The proposed techniques, aided by the emergence of single-photon sensors such as single-photon avalanche diodes (SPADs) with picosecond timing resolution, will have implications for a wide range of imaging applications: robotics, consumer photography, astronomy, microscopy and biomedical imaging.
Covid-19 Detection from Chest X-ray and Patient Metadata using Graph Convolutional Neural Networks
May 20, 2021
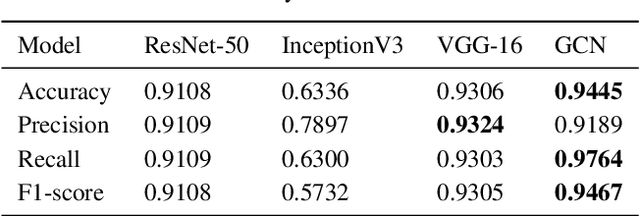
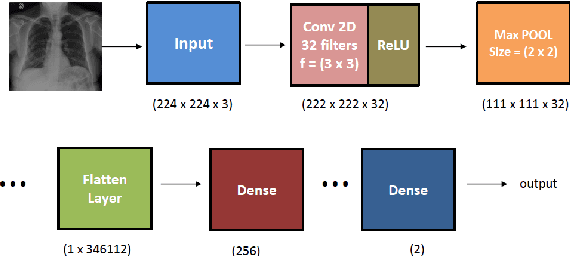
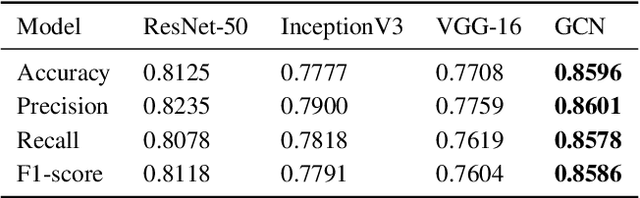
The novel corona virus (Covid-19) has introduced significant challenges due to its rapid spreading nature through respiratory transmission. As a result, there is a huge demand for Artificial Intelligence (AI) based quick disease diagnosis methods as an alternative to high demand tests such as Polymerase Chain Reaction (PCR). Chest X-ray (CXR) Image analysis is such cost-effective radiography technique due to resource availability and quick screening. But, a sufficient and systematic data collection that is required by complex deep leaning (DL) models is more difficult and hence there are recent efforts that utilize transfer learning to address this issue. Still these transfer learnt models suffer from lack of generalization and increased bias to the training dataset resulting poor performance for unseen data. Limited correlation of the transferred features from the pre-trained model to a specific medical imaging domain like X-ray and overfitting on fewer data can be reasons for this circumstance. In this work, we propose a novel Graph Convolution Neural Network (GCN) that is capable of identifying bio-markers of Covid-19 pneumonia from CXR images and meta information about patients. The proposed method exploits important relational knowledge between data instances and their features using graph representation and applies convolution to learn the graph data which is not possible with conventional convolution on Euclidean domain. The results of extensive experiments of proposed model on binary (Covid vs normal) and three class (Covid, normal, other pneumonia) classification problems outperform different benchmark transfer learnt models, hence overcoming the aforementioned drawbacks.
Deep learning to estimate the physical proportion of infected region of lung for COVID-19 pneumonia with CT image set
Jun 09, 2020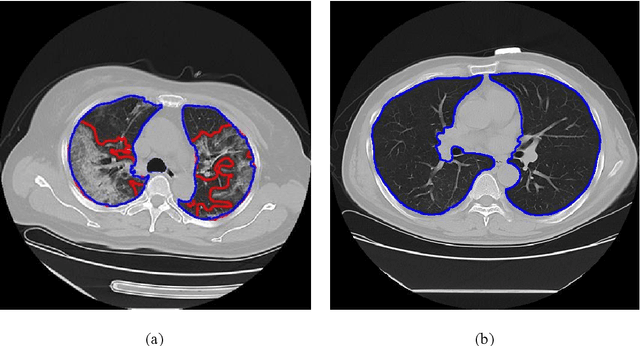
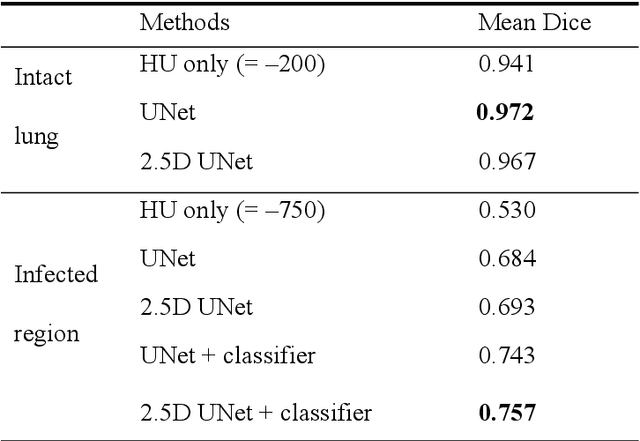
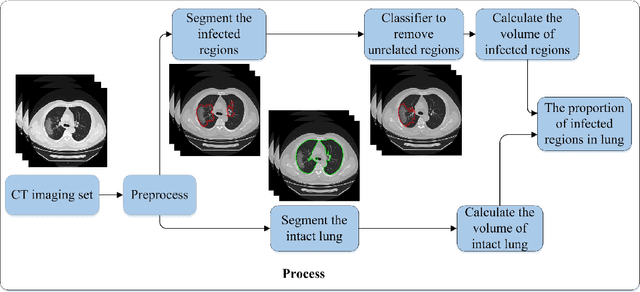
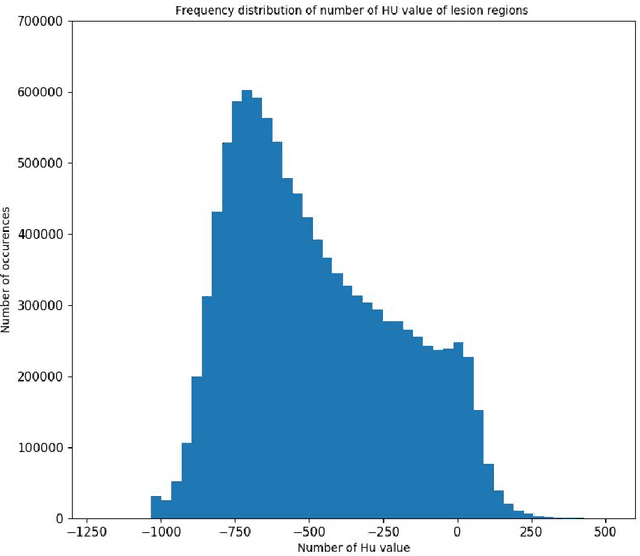
Utilizing computed tomography (CT) images to quickly estimate the severity of cases with COVID-19 is one of the most straightforward and efficacious methods. Two tasks were studied in this present paper. One was to segment the mask of intact lung in case of pneumonia. Another was to generate the masks of regions infected by COVID-19. The masks of these two parts of images then were converted to corresponding volumes to calculate the physical proportion of infected region of lung. A total of 129 CT image set were herein collected and studied. The intrinsic Hounsfiled value of CT images was firstly utilized to generate the initial dirty version of labeled masks both for intact lung and infected regions. Then, the samples were carefully adjusted and improved by two professional radiologists to generate the final training set and test benchmark. Two deep learning models were evaluated: UNet and 2.5D UNet. For the segment of infected regions, a deep learning based classifier was followed to remove unrelated blur-edged regions that were wrongly segmented out such as air tube and blood vessel tissue etc. For the segmented masks of intact lung and infected regions, the best method could achieve 0.972 and 0.757 measure in mean Dice similarity coefficient on our test benchmark. As the overall proportion of infected region of lung, the final result showed 0.961 (Pearson's correlation coefficient) and 11.7% (mean absolute percent error). The instant proportion of infected regions of lung could be used as a visual evidence to assist clinical physician to determine the severity of the case. Furthermore, a quantified report of infected regions can help predict the prognosis for COVID-19 cases which were scanned periodically within the treatment cycle.