 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAUTOGATE: Automated Clock Gating via Toggling-Aware LLM-based RTL Rewriting
Jun 16, 2026Fine-grain clock gating (FGCG) is among the most effective techniques for reducing dynamic power, yet current FGCG optimization flows remain largely manual. Recent LLM-based RTL optimization approaches remain limited by two key drawbacks: (1) the inability to process long waveform traces spanning millions of cycles, and (2) the difficulty of scaling optimization to large hierarchical codebases while preserving correctness. In this work, we present AUTOGATE, the first agentic framework for industry-grade RTL power optimization, enabling workload-aware clock-gating optimization across large hierarchical codebases. AUTOGATE introduces a Machine Learning (ML)-LLM co-design that bridges waveform-level analysis and RTL rewriting. Specifically, we design an ML-based clustering algorithm that distills raw toggling traces into compact, structured representations that guide LLM-based RTL rewriting. This enables accurate identification and application of clock-gating opportunities without requiring LLMs to directly process raw waveform data. To enhance scalability, AUTOGATE employs a hierarchical multi-agent architecture that decomposes large designs into independently optimizable modules, enabling coordinated optimization across deep design hierarchies. We evaluate AUTOGATE on a diverse set of designs ranging from small RTL designs to large industrial-grade codebases. Experimental results show that AUTOGATE consistently reduces dynamic power relative to baselines. Across the small-design suite, AUTOGATE reduces dynamic power by 49.31% on average. On industry-scale designs, it achieves 19.34% and 7.96% dynamic power reductions on NVDLA and BlackParrot, respectively, and up to 6.86% on highly optimized proprietary production designs.
Energy Efficient Software Hardware CoDesign for Machine Learning: From TinyML to Large Language Models
Mar 24, 2026The rapid deployment of machine learning across platforms from milliwatt-class TinyML devices to large language models has made energy efficiency a primary constraint for sustainable AI. Across these scales, performance and energy are increasingly limited by data movement and memory-system behavior rather than by arithmetic throughput alone. This work reviews energy efficient software hardware codesign methods spanning edge inference and training to datacenter-scale LLM serving, covering accelerator architectures (e.g., ASIC/FPGA dataflows, processing-/compute-in-memory designs) and system-level techniques (e.g., partitioning, quantization, scheduling, and runtime adaptation). We distill common design levers and trade-offs, and highlight recurring gaps including limited cross-platform generalization, large and costly co-design search spaces, and inconsistent benchmarking across workloads and deployment settings. Finally, we outline a hierarchical decomposition perspective that maps optimization strategies to computational roles and supports incremental adaptation, offering practical guidance for building energy and carbon aware ML systems.
The Energy-Efficient Hierarchical Neural Network with Fast FPGA-Based Incremental Learning
Sep 18, 2025The rising computational and energy demands of deep learning, particularly in large-scale architectures such as foundation models and large language models (LLMs), pose significant challenges to sustainability. Traditional gradient-based training methods are inefficient, requiring numerous iterative updates and high power consumption. To address these limitations, we propose a hybrid framework that combines hierarchical decomposition with FPGA-based direct equation solving and incremental learning. Our method divides the neural network into two functional tiers: lower layers are optimized via single-step equation solving on FPGAs for efficient and parallelizable feature extraction, while higher layers employ adaptive incremental learning to support continual updates without full retraining. Building upon this foundation, we introduce the Compound LLM framework, which explicitly deploys LLM modules across both hierarchy levels. The lower-level LLM handles reusable representation learning with minimal energy overhead, while the upper-level LLM performs adaptive decision-making through energy-aware updates. This integrated design enhances scalability, reduces redundant computation, and aligns with the principles of sustainable AI. Theoretical analysis and architectural insights demonstrate that our method reduces computational costs significantly while preserving high model performance, making it well-suited for edge deployment and real-time adaptation in energy-constrained environments.
Forecasting and Visualizing Air Quality from Sky Images with Vision-Language Models
Sep 18, 2025Air pollution remains a critical threat to public health and environmental sustainability, yet conventional monitoring systems are often constrained by limited spatial coverage and accessibility. This paper proposes an AI-driven agent that predicts ambient air pollution levels from sky images and synthesizes realistic visualizations of pollution scenarios using generative modeling. Our approach combines statistical texture analysis with supervised learning for pollution classification, and leverages vision-language model (VLM)-guided image generation to produce interpretable representations of air quality conditions. The generated visuals simulate varying degrees of pollution, offering a foundation for user-facing interfaces that improve transparency and support informed environmental decision-making. These outputs can be seamlessly integrated into intelligent applications aimed at enhancing situational awareness and encouraging behavioral responses based on real-time forecasts. We validate our method using a dataset of urban sky images and demonstrate its effectiveness in both pollution level estimation and semantically consistent visual synthesis. The system design further incorporates human-centered user experience principles to ensure accessibility, clarity, and public engagement in air quality forecasting. To support scalable and energy-efficient deployment, future iterations will incorporate a green CNN architecture enhanced with FPGA-based incremental learning, enabling real-time inference on edge platforms.
BoolGebra: Attributed Graph-learning for Boolean Algebraic Manipulation
Jan 19, 2024



Boolean algebraic manipulation is at the core of logic synthesis in Electronic Design Automation (EDA) design flow. Existing methods struggle to fully exploit optimization opportunities, and often suffer from an explosive search space and limited scalability efficiency. This work presents BoolGebra, a novel attributed graph-learning approach for Boolean algebraic manipulation that aims to improve fundamental logic synthesis. BoolGebra incorporates Graph Neural Networks (GNNs) and takes initial feature embeddings from both structural and functional information as inputs. A fully connected neural network is employed as the predictor for direct optimization result predictions, significantly reducing the search space and efficiently locating the optimization space. The experiments involve training the BoolGebra model w.r.t design-specific and cross-design inferences using the trained model, where BoolGebra demonstrates generalizability for cross-design inference and its potential to scale from small, simple training datasets to large, complex inference datasets. Finally, BoolGebra is integrated with existing synthesis tool ABC to perform end-to-end logic minimization evaluation w.r.t SOTA baselines.
GATSPI: GPU Accelerated Gate-Level Simulation for Power Improvement
Mar 11, 2022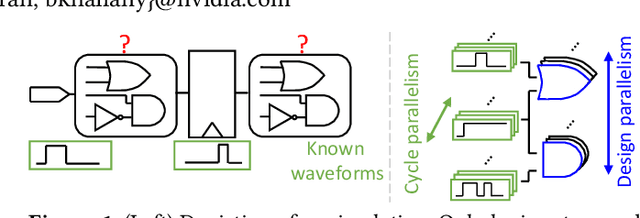

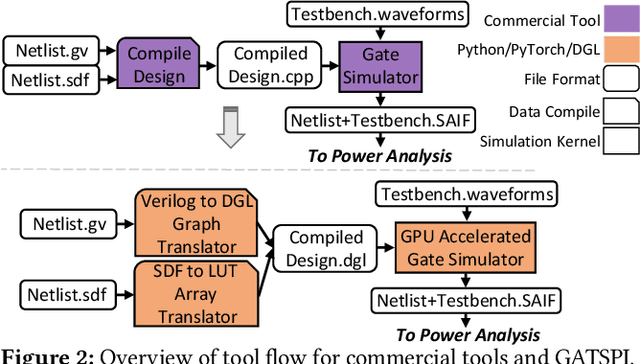
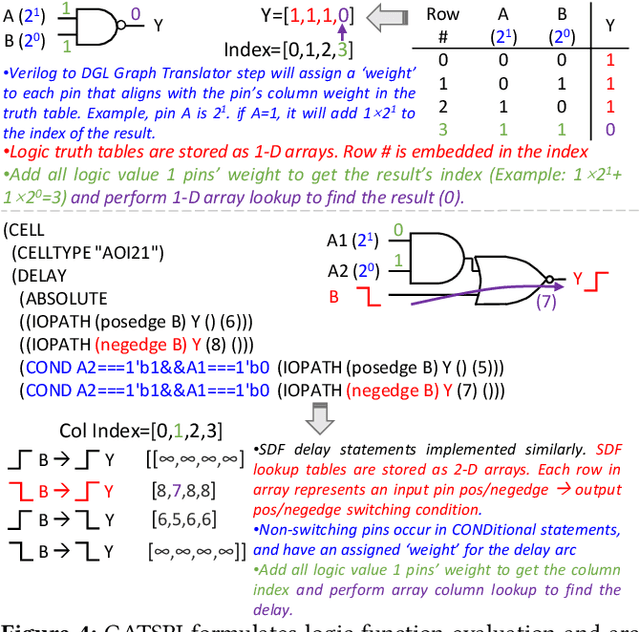
In this paper, we present GATSPI, a novel GPU accelerated logic gate simulator that enables ultra-fast power estimation for industry sized ASIC designs with millions of gates. GATSPI is written in PyTorch with custom CUDA kernels for ease of coding and maintainability. It achieves simulation kernel speedup of up to 1668X on a single-GPU system and up to 7412X on a multiple-GPU system when compared to a commercial gate-level simulator running on a single CPU core. GATSPI supports a range of simple to complex cell types from an industry standard cell library and SDF conditional delay statements without requiring prior calibration runs and produces industry-standard SAIF files from delay-aware gate-level simulation. Finally, we deploy GATSPI in a glitch-optimization flow, achieving a 1.4% power saving with a 449X speedup in turnaround time compared to a similar flow using a commercial simulator.
Covid-19 Detection from Chest X-ray and Patient Metadata using Graph Convolutional Neural Networks
May 21, 2021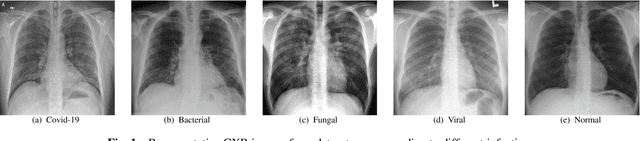
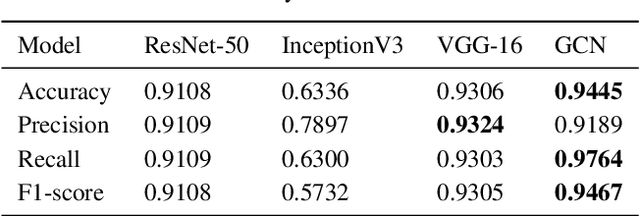
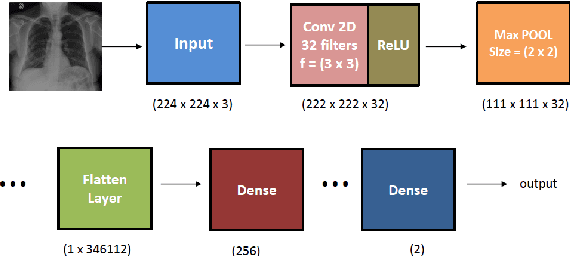
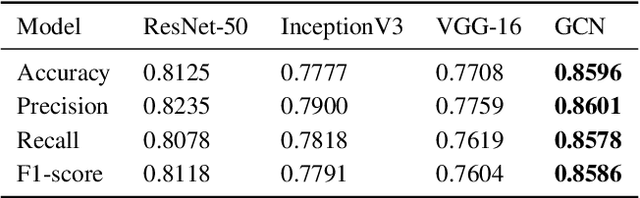
The novel corona virus (Covid-19) has introduced significant challenges due to its rapid spreading nature through respiratory transmission. As a result, there is a huge demand for Artificial Intelligence (AI) based quick disease diagnosis methods as an alternative to high demand tests such as Polymerase Chain Reaction (PCR). Chest X-ray (CXR) Image analysis is such cost-effective radiography technique due to resource availability and quick screening. But, a sufficient and systematic data collection that is required by complex deep leaning (DL) models is more difficult and hence there are recent efforts that utilize transfer learning to address this issue. Still these transfer learnt models suffer from lack of generalization and increased bias to the training dataset resulting poor performance for unseen data. Limited correlation of the transferred features from the pre-trained model to a specific medical imaging domain like X-ray and overfitting on fewer data can be reasons for this circumstance. In this work, we propose a novel Graph Convolution Neural Network (GCN) that is capable of identifying bio-markers of Covid-19 pneumonia from CXR images and meta information about patients. The proposed method exploits important relational knowledge between data instances and their features using graph representation and applies convolution to learn the graph data which is not possible with conventional convolution on Euclidean domain. The results of extensive experiments of proposed model on binary (Covid vs normal) and three class (Covid, normal, other pneumonia) classification problems outperform different benchmark transfer learnt models, hence overcoming the aforementioned drawbacks.
FIST: A Feature-Importance Sampling and Tree-Based Method for Automatic Design Flow Parameter Tuning
Nov 26, 2020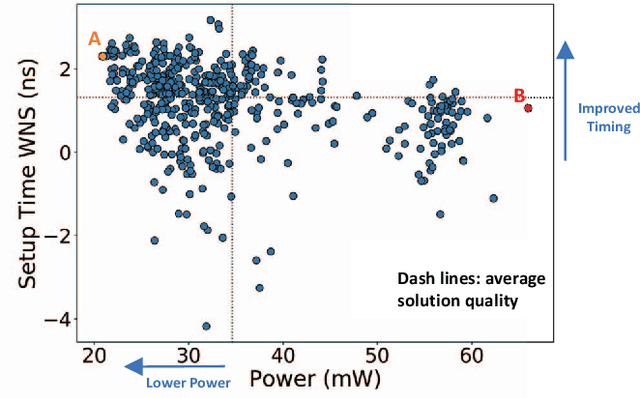
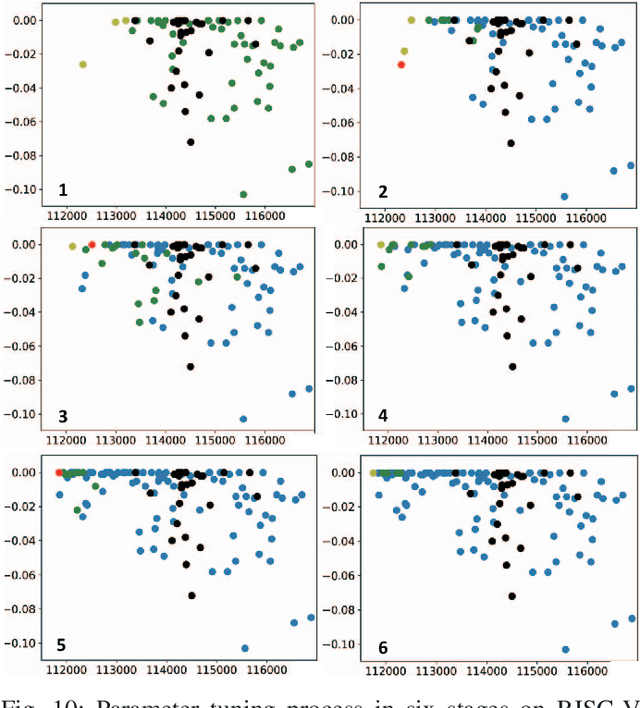
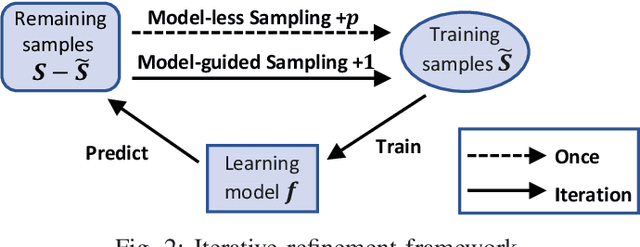
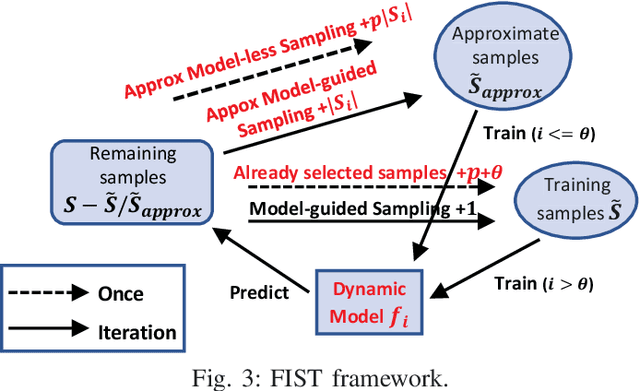
Design flow parameters are of utmost importance to chip design quality and require a painfully long time to evaluate their effects. In reality, flow parameter tuning is usually performed manually based on designers' experience in an ad hoc manner. In this work, we introduce a machine learning-based automatic parameter tuning methodology that aims to find the best design quality with a limited number of trials. Instead of merely plugging in machine learning engines, we develop clustering and approximate sampling techniques for improving tuning efficiency. The feature extraction in this method can reuse knowledge from prior designs. Furthermore, we leverage a state-of-the-art XGBoost model and propose a novel dynamic tree technique to overcome overfitting. Experimental results on benchmark circuits show that our approach achieves 25% improvement in design quality or 37% reduction in sampling cost compared to random forest method, which is the kernel of a highly cited previous work. Our approach is further validated on two industrial designs. By sampling less than 0.02% of possible parameter sets, it reduces area by 1.83% and 1.43% compared to the best solutions hand-tuned by experienced designers.
Graph Convolution Networks Using Message Passing and Multi-Source Similarity Features for Predicting circRNA-Disease Association
Sep 15, 2020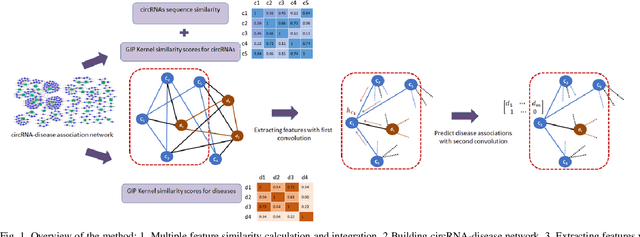
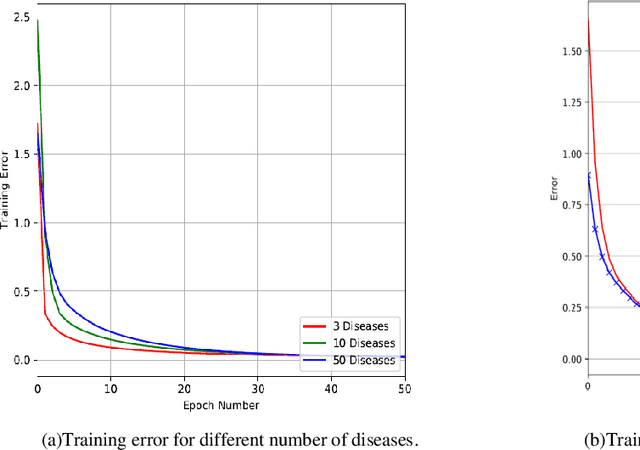
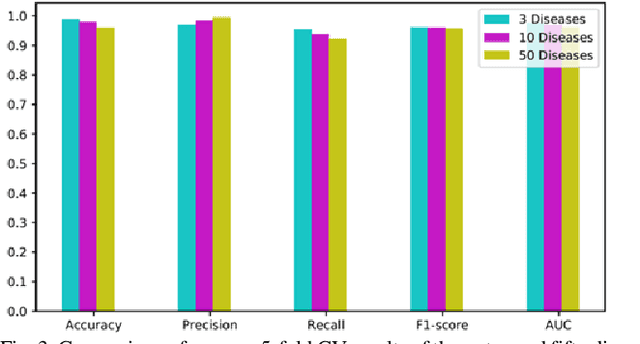
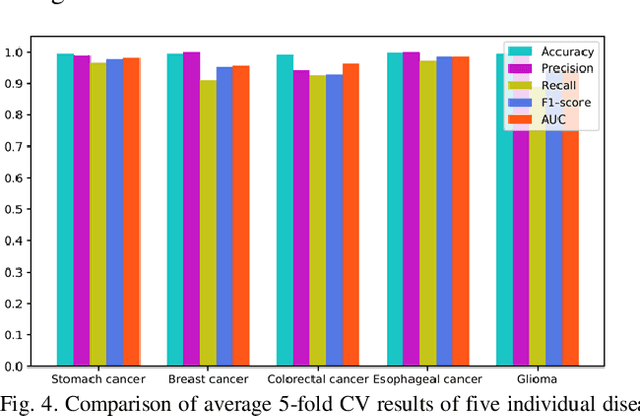
Graphs can be used to effectively represent complex data structures. Learning these irregular data in graphs is challenging and still suffers from shallow learning. Applying deep learning on graphs has recently showed good performance in many applications in social analysis, bioinformatics etc. A message passing graph convolution network is such a powerful method which has expressive power to learn graph structures. Meanwhile, circRNA is a type of non-coding RNA which plays a critical role in human diseases. Identifying the associations between circRNAs and diseases is important to diagnosis and treatment of complex diseases. However, there are limited number of known associations between them and conducting biological experiments to identify new associations is time consuming and expensive. As a result, there is a need of building efficient and feasible computation methods to predict potential circRNA-disease associations. In this paper, we propose a novel graph convolution network framework to learn features from a graph built with multi-source similarity information to predict circRNA-disease associations. First we use multi-source information of circRNA similarity, disease and circRNA Gaussian Interaction Profile (GIP) kernel similarity to extract the features using first graph convolution. Then we predict disease associations for each circRNA with second graph convolution. Proposed framework with five-fold cross validation on various experiments shows promising results in predicting circRNA-disease association and outperforms other existing methods.
Multicategory Angle-based Learning for Estimating Optimal Dynamic Treatment Regimes with Censored Data
Jan 14, 2020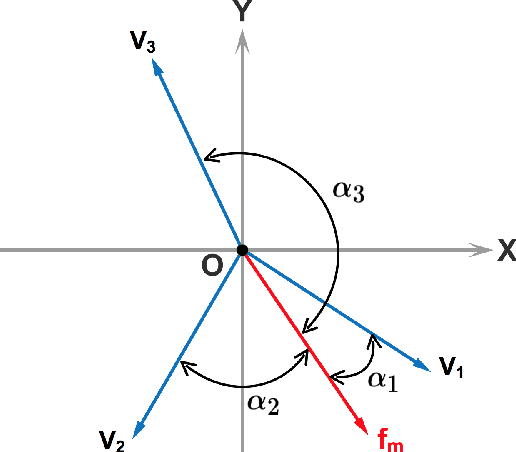
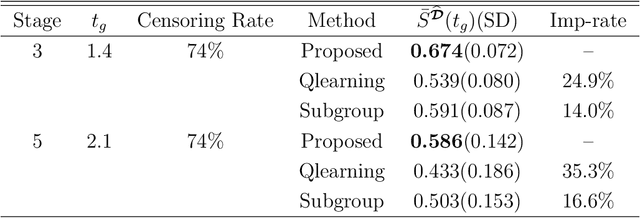
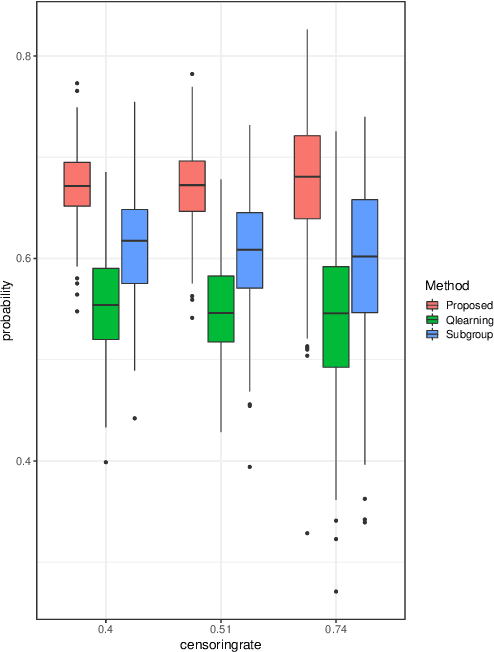
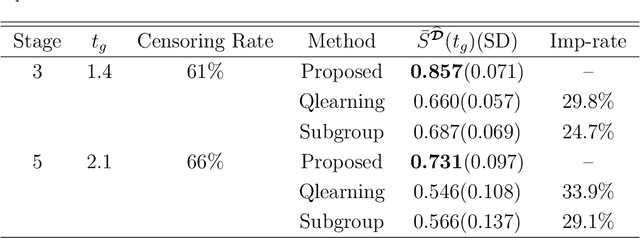
An optimal dynamic treatment regime (DTR) consists of a sequence of decision rules in maximizing long-term benefits, which is applicable for chronic diseases such as HIV infection or cancer. In this paper, we develop a novel angle-based approach to search the optimal DTR under a multicategory treatment framework for survival data. The proposed method targets maximization the conditional survival function of patients following a DTR. In contrast to most existing approaches which are designed to maximize the expected survival time under a binary treatment framework, the proposed method solves the multicategory treatment problem given multiple stages for censored data. Specifically, the proposed method obtains the optimal DTR via integrating estimations of decision rules at multiple stages into a single multicategory classification algorithm without imposing additional constraints, which is also more computationally efficient and robust. In theory, we establish Fisher consistency of the proposed method under regularity conditions. Our numerical studies show that the proposed method outperforms competing methods in terms of maximizing the conditional survival function. We apply the proposed method to two real datasets: Framingham heart study data and acquired immunodeficiency syndrome (AIDS) clinical data.