 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Data Collection for Efficient Semiparametric Inference
Nov 05, 2024



While many works have studied statistical data fusion, they typically assume that the various datasets are given in advance. However, in practice, estimation requires difficult data collection decisions like determining the available data sources, their costs, and how many samples to collect from each source. Moreover, this process is often sequential because the data collected at a given time can improve collection decisions in the future. In our setup, given access to multiple data sources and budget constraints, the agent must sequentially decide which data source to query to efficiently estimate a target parameter. We formalize this task using Online Moment Selection, a semiparametric framework that applies to any parameter identified by a set of moment conditions. Interestingly, the optimal budget allocation depends on the (unknown) true parameters. We present two online data collection policies, Explore-then-Commit and Explore-then-Greedy, that use the parameter estimates at a given time to optimally allocate the remaining budget in the future steps. We prove that both policies achieve zero regret (assessed by asymptotic MSE) relative to an oracle policy. We empirically validate our methods on both synthetic and real-world causal effect estimation tasks, demonstrating that the online data collection policies outperform their fixed counterparts.
Failure Modes of LLMs for Causal Reasoning on Narratives
Oct 31, 2024



In this work, we investigate the causal reasoning abilities of large language models (LLMs) through the representative problem of inferring causal relationships from narratives. We find that even state-of-the-art language models rely on unreliable shortcuts, both in terms of the narrative presentation and their parametric knowledge. For example, LLMs tend to determine causal relationships based on the topological ordering of events (i.e., earlier events cause later ones), resulting in lower performance whenever events are not narrated in their exact causal order. Similarly, we demonstrate that LLMs struggle with long-term causal reasoning and often fail when the narratives are long and contain many events. Additionally, we show LLMs appear to rely heavily on their parametric knowledge at the expense of reasoning over the provided narrative. This degrades their abilities whenever the narrative opposes parametric knowledge. We extensively validate these failure modes through carefully controlled synthetic experiments, as well as evaluations on real-world narratives. Finally, we observe that explicitly generating a causal graph generally improves performance while naive chain-of-thought is ineffective. Collectively, our results distill precise failure modes of current state-of-the-art models and can pave the way for future techniques to enhance causal reasoning in LLMs.
Photon Inhibition for Energy-Efficient Single-Photon Imaging
Sep 26, 2024



Single-photon cameras (SPCs) are emerging as sensors of choice for various challenging imaging applications. One class of SPCs based on the single-photon avalanche diode (SPAD) detects individual photons using an avalanche process; the raw photon data can then be processed to extract scene information under extremely low light, high dynamic range, and rapid motion. Yet, single-photon sensitivity in SPADs comes at a cost -- each photon detection consumes more energy than that of a CMOS camera. This avalanche power significantly limits sensor resolution and could restrict widespread adoption of SPAD-based SPCs. We propose a computational-imaging approach called \emph{photon inhibition} to address this challenge. Photon inhibition strategically allocates detections in space and time based on downstream inference task goals and resource constraints. We develop lightweight, on-sensor computational inhibition policies that use past photon data to disable SPAD pixels in real-time, to select the most informative future photons. As case studies, we design policies tailored for image reconstruction and edge detection, and demonstrate, both via simulations and real SPC captured data, considerable reduction in photon detections (over 90\% of photons) while maintaining task performance metrics. Our work raises the question of ``which photons should be detected?'', and paves the way for future energy-efficient single-photon imaging.
Learned Causal Method Prediction
Nov 08, 2023



For a given causal question, it is important to efficiently decide which causal inference method to use for a given dataset. This is challenging because causal methods typically rely on complex and difficult-to-verify assumptions, and cross-validation is not applicable since ground truth causal quantities are unobserved. In this work, we propose CAusal Method Predictor (CAMP), a framework for predicting the best method for a given dataset. To this end, we generate datasets from a diverse set of synthetic causal models, score the candidate methods, and train a model to directly predict the highest-scoring method for that dataset. Next, by formulating a self-supervised pre-training objective centered on dataset assumptions relevant for causal inference, we significantly reduce the need for costly labeled data and enhance training efficiency. Our strategy learns to map implicit dataset properties to the best method in a data-driven manner. In our experiments, we focus on method prediction for causal discovery. CAMP outperforms selecting any individual candidate method and demonstrates promising generalization to unseen semi-synthetic and real-world benchmarks.
Local Discovery by Partitioning: Polynomial-Time Causal Discovery Around Exposure-Outcome Pairs
Oct 25, 2023



This work addresses the problem of automated covariate selection under limited prior knowledge. Given an exposure-outcome pair {X,Y} and a variable set Z of unknown causal structure, the Local Discovery by Partitioning (LDP) algorithm partitions Z into subsets defined by their relation to {X,Y}. We enumerate eight exhaustive and mutually exclusive partitions of any arbitrary Z and leverage this taxonomy to differentiate confounders from other variable types. LDP is motivated by valid adjustment set identification, but avoids the pretreatment assumption commonly made by automated covariate selection methods. We provide theoretical guarantees that LDP returns a valid adjustment set for any Z that meets sufficient graphical conditions. Under stronger conditions, we prove that partition labels are asymptotically correct. Total independence tests is worst-case quadratic in |Z|, with sub-quadratic runtimes observed empirically. We numerically validate our theoretical guarantees on synthetic and semi-synthetic graphs. Adjustment sets from LDP yield less biased and more precise average treatment effect estimates than baselines, with LDP outperforming on confounder recall, test count, and runtime for valid adjustment set discovery.
Discovering Optimal Scoring Mechanisms in Causal Strategic Prediction
Feb 21, 2023



Faced with data-driven policies, individuals will manipulate their features to obtain favorable decisions. While earlier works cast these manipulations as undesirable gaming, recent works have adopted a more nuanced causal framing in which manipulations can improve outcomes of interest, and setting coherent mechanisms requires accounting for both predictive accuracy and improvement of the outcome. Typically, these works focus on known causal graphs, consisting only of an outcome and its parents. In this paper, we introduce a general framework in which an outcome and n observed features are related by an arbitrary unknown graph and manipulations are restricted by a fixed budget and cost structure. We develop algorithms that leverage strategic responses to discover the causal graph in a finite number of steps. Given this graph structure, we can then derive mechanisms that trade off between accuracy and improvement. Altogether, our work deepens links between causal discovery and incentive design and provides a more nuanced view of learning under causal strategic prediction.
Local Causal Discovery for Estimating Causal Effects
Feb 18, 2023



Even when the causal graph underlying our data is unknown, we can use observational data to narrow down the possible values that an average treatment effect (ATE) can take by (1) identifying the graph up to a Markov equivalence class; and (2) estimating that ATE for each graph in the class. While the PC algorithm can identify this class under strong faithfulness assumptions, it can be computationally prohibitive. Fortunately, only the local graph structure around the treatment is required to identify the set of possible ATE values, a fact exploited by local discovery algorithms to improve computational efficiency. In this paper, we introduce Local Discovery using Eager Collider Checks (LDECC), a new local causal discovery algorithm that leverages unshielded colliders to orient the treatment's parents differently from existing methods. We show that there exist graphs where LDECC exponentially outperforms existing local discovery algorithms and vice versa. Moreover, we show that LDECC and existing algorithms rely on different faithfulness assumptions, leveraging this insight to weaken the assumptions for identifying the set of possible ATE values.
Efficient Online Estimation of Causal Effects by Deciding What to Observe
Aug 20, 2021

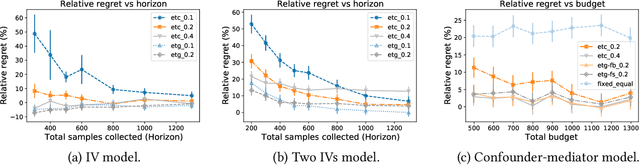
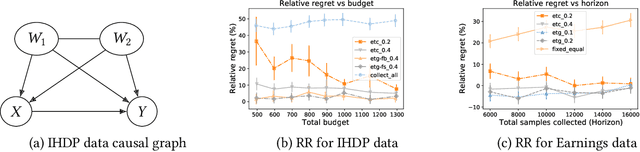
Researchers often face data fusion problems, where multiple data sources are available, each capturing a distinct subset of variables. While problem formulations typically take the data as given, in practice, data acquisition can be an ongoing process. In this paper, we aim to estimate any functional of a probabilistic model (e.g., a causal effect) as efficiently as possible, by deciding, at each time, which data source to query. We propose online moment selection (OMS), a framework in which structural assumptions are encoded as moment conditions. The optimal action at each step depends, in part, on the very moments that identify the functional of interest. Our algorithms balance exploration with choosing the best action as suggested by current estimates of the moments. We propose two selection strategies: (1) explore-then-commit (OMS-ETC) and (2) explore-then-greedy (OMS-ETG), proving that both achieve zero asymptotic regret as assessed by MSE. We instantiate our setup for average treatment effect estimation, where structural assumptions are given by a causal graph and data sources may include subsets of mediators, confounders, and instrumental variables.
Correcting Exposure Bias for Link Recommendation
Jun 13, 2021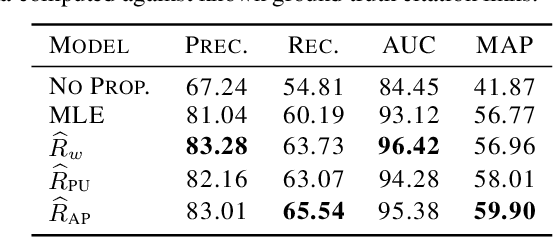
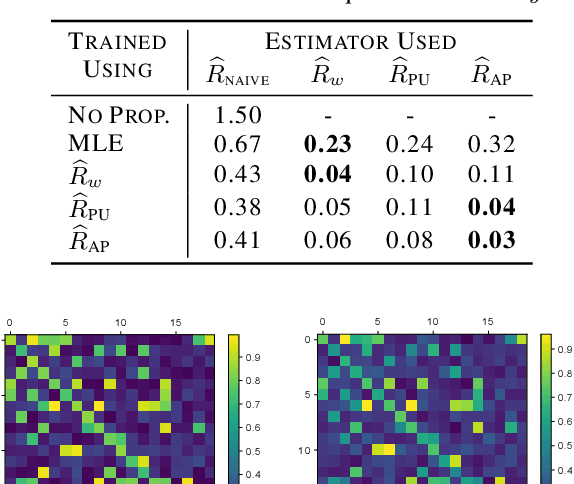
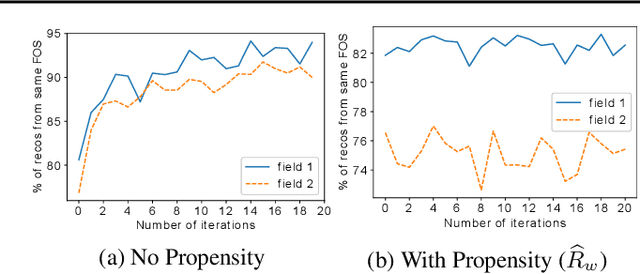
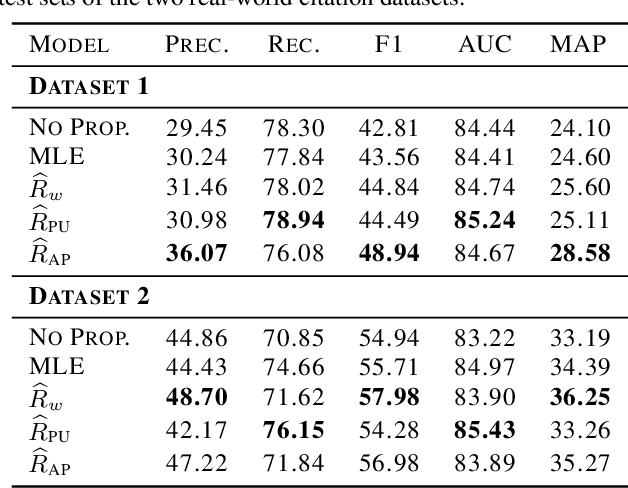
Link prediction methods are frequently applied in recommender systems, e.g., to suggest citations for academic papers or friends in social networks. However, exposure bias can arise when users are systematically underexposed to certain relevant items. For example, in citation networks, authors might be more likely to encounter papers from their own field and thus cite them preferentially. This bias can propagate through naively trained link predictors, leading to both biased evaluation and high generalization error (as assessed by true relevance). Moreover, this bias can be exacerbated by feedback loops. We propose estimators that leverage known exposure probabilities to mitigate this bias and consequent feedback loops. Next, we provide a loss function for learning the exposure probabilities from data. Finally, experiments on semi-synthetic data based on real-world citation networks, show that our methods reliably identify (truly) relevant citations. Additionally, our methods lead to greater diversity in the recommended papers' fields of study. The code is available at https://github.com/shantanu95/exposure-bias-link-rec.
Passive Inter-Photon Imaging
Apr 11, 2021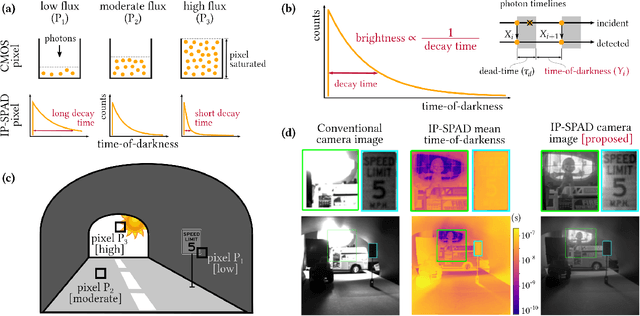

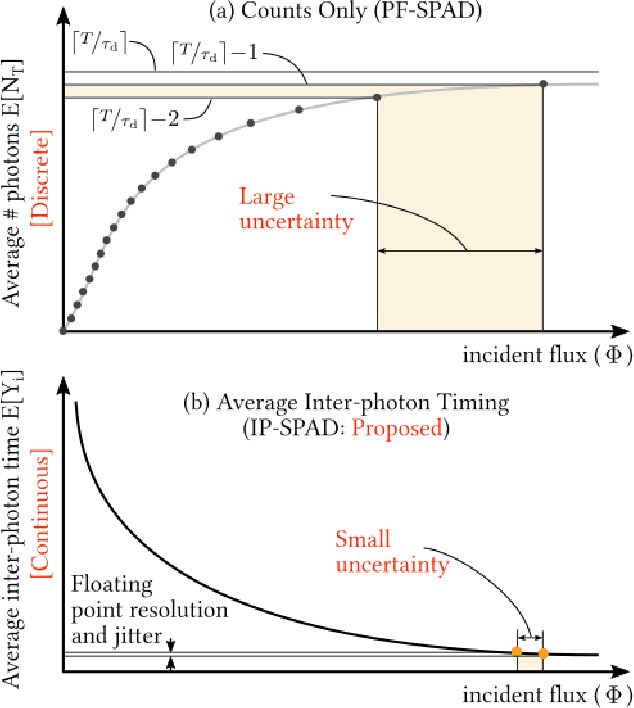
Digital camera pixels measure image intensities by converting incident light energy into an analog electrical current, and then digitizing it into a fixed-width binary representation. This direct measurement method, while conceptually simple, suffers from limited dynamic range and poor performance under extreme illumination -- electronic noise dominates under low illumination, and pixel full-well capacity results in saturation under bright illumination. We propose a novel intensity cue based on measuring inter-photon timing, defined as the time delay between detection of successive photons. Based on the statistics of inter-photon times measured by a time-resolved single-photon sensor, we develop theory and algorithms for a scene brightness estimator which works over extreme dynamic range; we experimentally demonstrate imaging scenes with a dynamic range of over ten million to one. The proposed techniques, aided by the emergence of single-photon sensors such as single-photon avalanche diodes (SPADs) with picosecond timing resolution, will have implications for a wide range of imaging applications: robotics, consumer photography, astronomy, microscopy and biomedical imaging.