 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Analysis and Applications of Class-wise Robustness in Adversarial Training
May 29, 2021
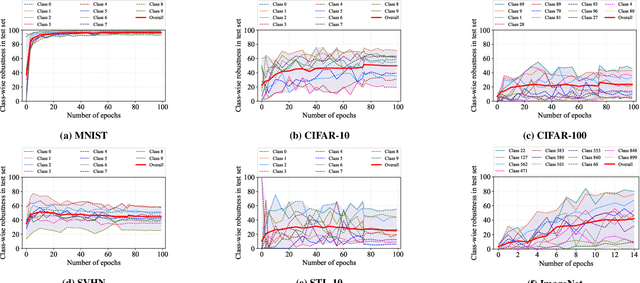
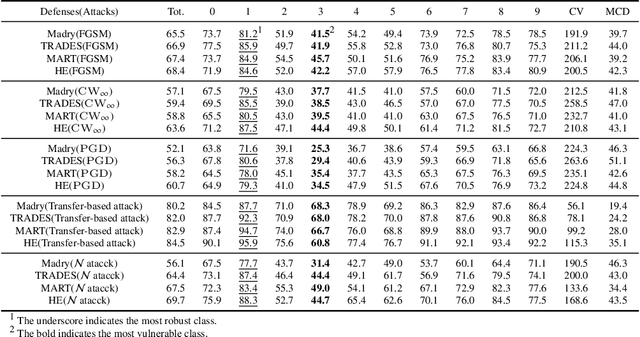

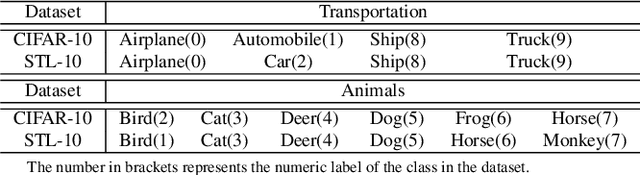
Adversarial training is one of the most effective approaches to improve model robustness against adversarial examples. However, previous works mainly focus on the overall robustness of the model, and the in-depth analysis on the role of each class involved in adversarial training is still missing. In this paper, we propose to analyze the class-wise robustness in adversarial training. First, we provide a detailed diagnosis of adversarial training on six benchmark datasets, i.e., MNIST, CIFAR-10, CIFAR-100, SVHN, STL-10 and ImageNet. Surprisingly, we find that there are remarkable robustness discrepancies among classes, leading to unbalance/unfair class-wise robustness in the robust models. Furthermore, we keep investigating the relations between classes and find that the unbalanced class-wise robustness is pretty consistent among different attack and defense methods. Moreover, we observe that the stronger attack methods in adversarial learning achieve performance improvement mainly from a more successful attack on the vulnerable classes (i.e., classes with less robustness). Inspired by these interesting findings, we design a simple but effective attack method based on the traditional PGD attack, named Temperature-PGD attack, which proposes to enlarge the robustness disparity among classes with a temperature factor on the confidence distribution of each image. Experiments demonstrate our method can achieve a higher attack rate than the PGD attack. Furthermore, from the defense perspective, we also make some modifications in the training and inference phases to improve the robustness of the most vulnerable class, so as to mitigate the large difference in class-wise robustness. We believe our work can contribute to a more comprehensive understanding of adversarial training as well as rethinking the class-wise properties in robust models.
Multi-modal Ensemble Models for Predicting Video Memorability
Feb 01, 2021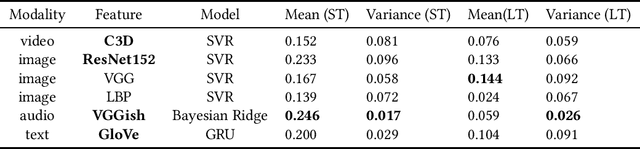
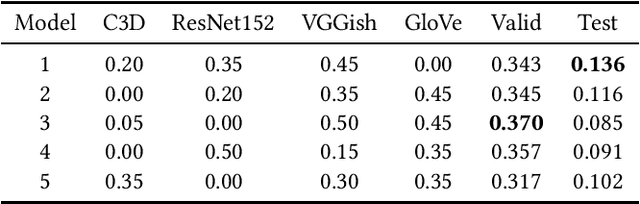
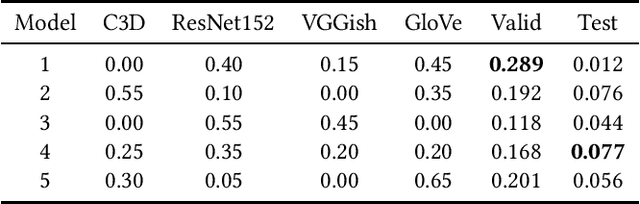
Modeling media memorability has been a consistent challenge in the field of machine learning. The Predicting Media Memorability task in MediaEval2020 is the latest benchmark among similar challenges addressing this topic. Building upon techniques developed in previous iterations of the challenge, we developed ensemble methods with the use of extracted video, image, text, and audio features. Critically, in this work we introduce and demonstrate the efficacy and high generalizability of extracted audio embeddings as a feature for the task of predicting media memorability.
Visual Search at Alibaba
Feb 09, 2021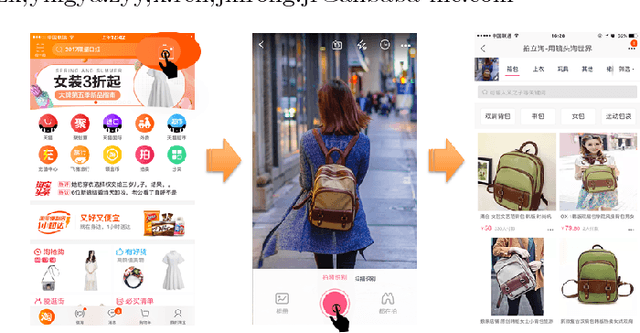

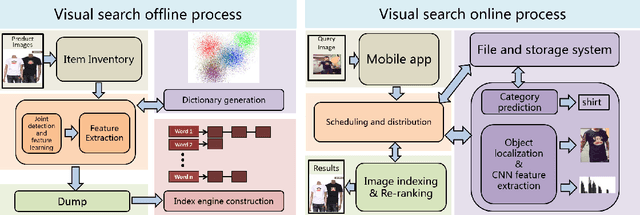
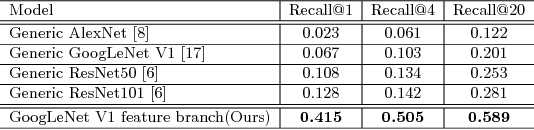
This paper introduces the large scale visual search algorithm and system infrastructure at Alibaba. The following challenges are discussed under the E-commercial circumstance at Alibaba (a) how to handle heterogeneous image data and bridge the gap between real-shot images from user query and the online images. (b) how to deal with large scale indexing for massive updating data. (c) how to train deep models for effective feature representation without huge human annotations. (d) how to improve the user engagement by considering the quality of the content. We take advantage of large image collection of Alibaba and state-of-the-art deep learning techniques to perform visual search at scale. We present solutions and implementation details to overcome those problems and also share our learnings from building such a large scale commercial visual search engine. Specifically, model and search-based fusion approach is introduced to effectively predict categories. Also, we propose a deep CNN model for joint detection and feature learning by mining user click behavior. The binary index engine is designed to scale up indexing without compromising recall and precision. Finally, we apply all the stages into an end-to-end system architecture, which can simultaneously achieve highly efficient and scalable performance adapting to real-shot images. Extensive experiments demonstrate the advancement of each module in our system. We hope visual search at Alibaba becomes more widely incorporated into today's commercial applications.
* accepted by KDD 2018
Automatic segmentation of vertebral features on ultrasound spine images using Stacked Hourglass Network
May 09, 2021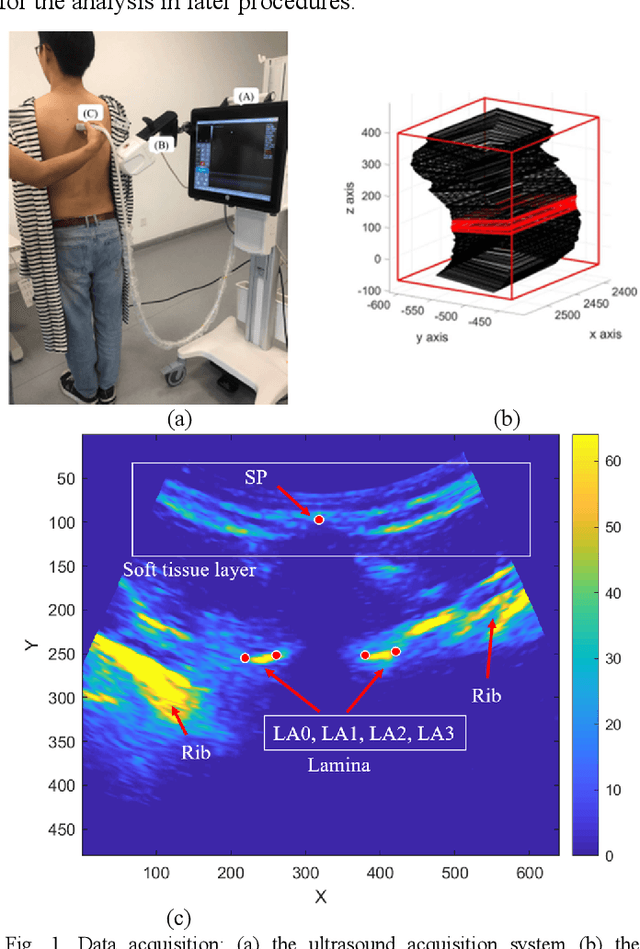
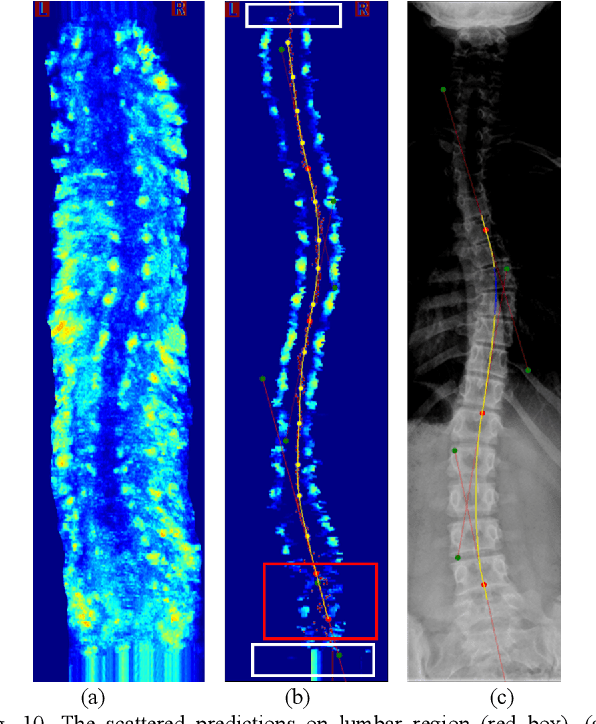
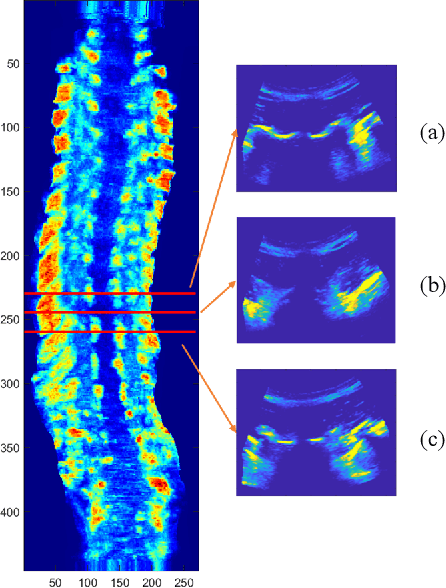
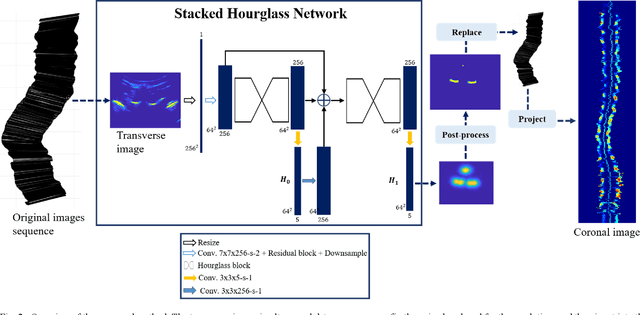
Objective: The spinous process angle (SPA) is one of the essential parameters to denote three-dimensional (3-D) deformity of spine. We propose an automatic segmentation method based on Stacked Hourglass Network (SHN) to detect the spinous processes (SP) on ultrasound (US) spine images and to measure the SPAs of clinical scoliotic subjects. Methods: The network was trained to detect vertebral SP and laminae as five landmarks on 1200 ultrasound transverse images and validated on 100 images. All the processed transverse images with highlighted SP and laminae were reconstructed into a 3D image volume, and the SPAs were measured on the projected coronal images. The trained network was tested on 400 images by calculating the percentage of correct keypoints (PCK); and the SPA measurements were evaluated on 50 scoliotic subjects by comparing the results from US images and radiographs. Results: The trained network achieved a high average PCK (86.8%) on the test datasets, particularly the PCK of SP detection was 90.3%. The SPAs measured from US and radiographic methods showed good correlation (r>0.85), and the mean absolute differences (MAD) between two modalities were 3.3{\deg}, which was less than the clinical acceptance error (5{\deg}). Conclusion: The vertebral features can be accurately segmented on US spine images using SHN, and the measurement results of SPA from US data was comparable to the gold standard from radiography.
Large Scale Long-tailed Product Recognition System at Alibaba
Feb 09, 2021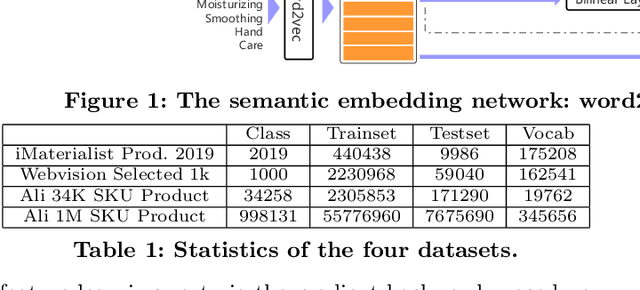

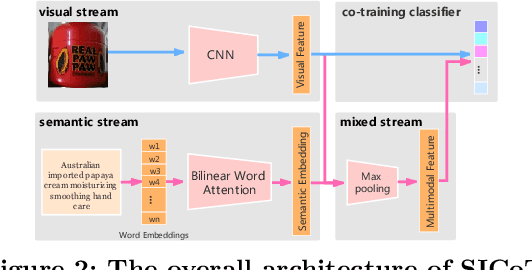
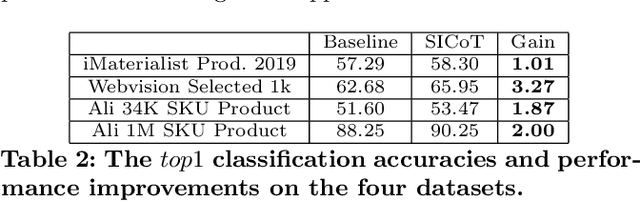
A practical large scale product recognition system suffers from the phenomenon of long-tailed imbalanced training data under the E-commercial circumstance at Alibaba. Besides product images at Alibaba, plenty of image related side information (e.g. title, tags) reveal rich semantic information about images. Prior works mainly focus on addressing the long tail problem in visual perspective only, but lack of consideration of leveraging the side information. In this paper, we present a novel side information based large scale visual recognition co-training~(SICoT) system to deal with the long tail problem by leveraging the image related side information. In the proposed co-training system, we firstly introduce a bilinear word attention module aiming to construct a semantic embedding over the noisy side information. A visual feature and semantic embedding co-training scheme is then designed to transfer knowledge from classes with abundant training data (head classes) to classes with few training data (tail classes) in an end-to-end fashion. Extensive experiments on four challenging large scale datasets, whose numbers of classes range from one thousand to one million, demonstrate the scalable effectiveness of the proposed SICoT system in alleviating the long tail problem. In the visual search platform Pailitao\footnote{http://www.pailitao.com} at Alibaba, we settle a practical large scale product recognition application driven by the proposed SICoT system, and achieve a significant gain of unique visitor~(UV) conversion rate.
* Acccepted by CIKM 2020
BARF: Bundle-Adjusting Neural Radiance Fields
Apr 13, 2021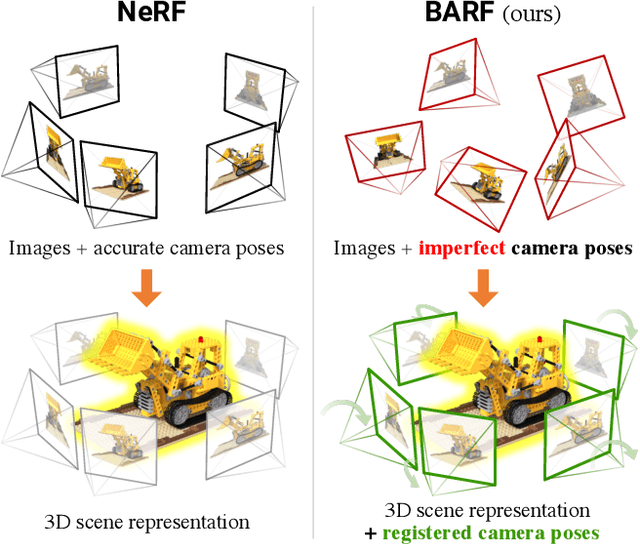
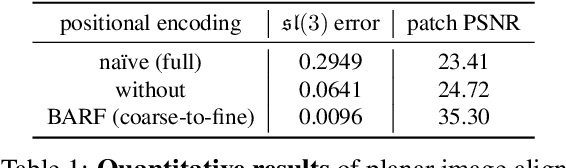
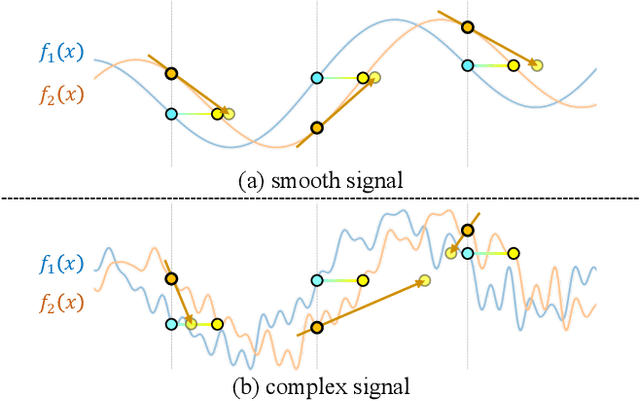
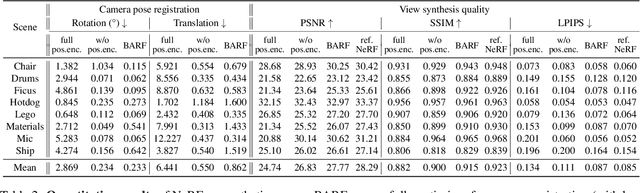
Neural Radiance Fields (NeRF) have recently gained a surge of interest within the computer vision community for its power to synthesize photorealistic novel views of real-world scenes. One limitation of NeRF, however, is its requirement of accurate camera poses to learn the scene representations. In this paper, we propose Bundle-Adjusting Neural Radiance Fields (BARF) for training NeRF from imperfect (or even unknown) camera poses -- the joint problem of learning neural 3D representations and registering camera frames. We establish a theoretical connection to classical image alignment and show that coarse-to-fine registration is also applicable to NeRF. Furthermore, we show that na\"ively applying positional encoding in NeRF has a negative impact on registration with a synthesis-based objective. Experiments on synthetic and real-world data show that BARF can effectively optimize the neural scene representations and resolve large camera pose misalignment at the same time. This enables view synthesis and localization of video sequences from unknown camera poses, opening up new avenues for visual localization systems (e.g. SLAM) and potential applications for dense 3D mapping and reconstruction.
A deep learning pipeline for identification of motor units in musculoskeletal ultrasound
Sep 23, 2020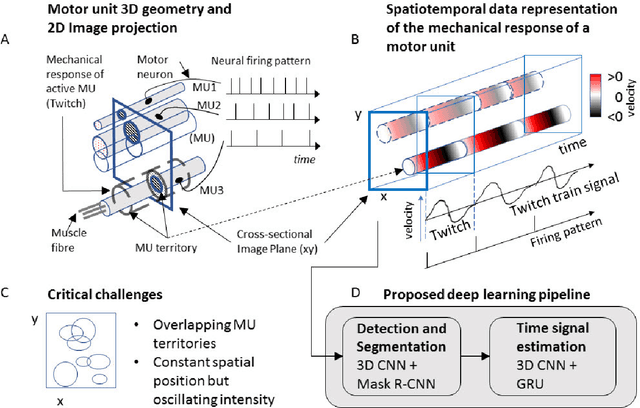
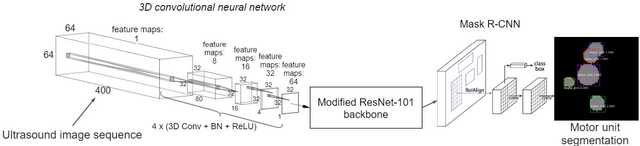
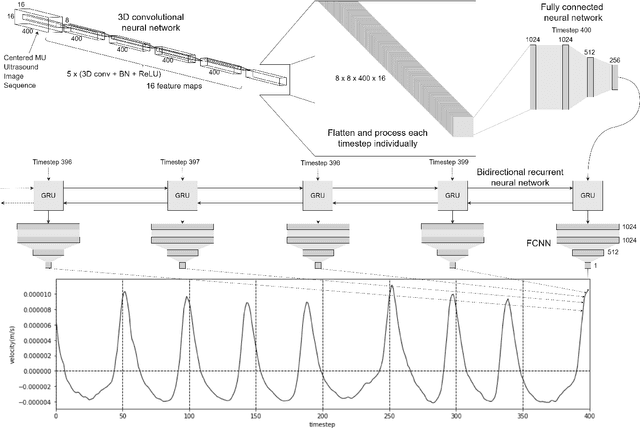
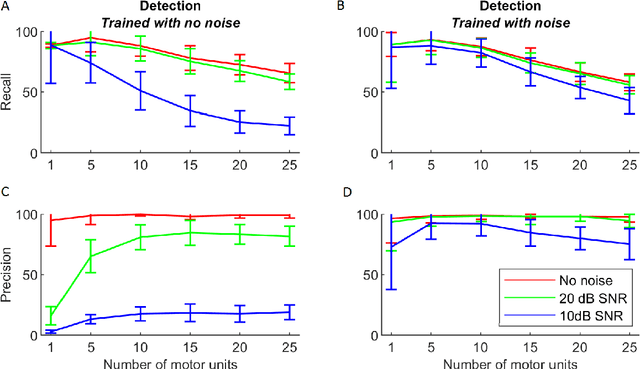
Ultrasound imaging provides information from a large part of the muscle. It has recently been shown that ultrafast ultrasound imaging can be used to record and analyze the mechanical response of individual MUs using blind source separation. In this work, we present an alternative method - a deep learning pipeline - to identify active MUs in ultrasound image sequences, including segmentation of their territories and signal estimation of their mechanical responses (twitch train). We train and evaluate the model using simulated data mimicking the complex activation pattern of tens of activated MUs with overlapping territories and partially synchronized activation patterns. Using a slow fusion approach (based on 3D CNNs), we transform the spatiotemporal image sequence data to 2D representations and apply a deep neural network architecture for segmentation. Next, we employ a second deep neural network architecture for signal estimation. The results show that the proposed pipeline can effectively identify individual MUs, estimate their territories, and estimate their twitch train signal at low contraction forces. The framework can retain spatio-temporal consistencies and information of the mechanical response of MU activity even when the ultrasound image sequences are transformed into a 2D representation for compatibility with more traditional computer vision and image processing techniques. The proposed pipeline is potentially useful to identify simultaneously active MUs in whole muscles in ultrasound image sequences of voluntary skeletal muscle contractions at low force levels.
Trainable Activation Function in Image Classification
Jun 05, 2020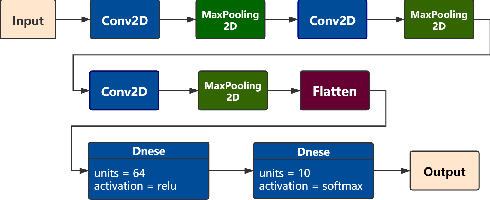
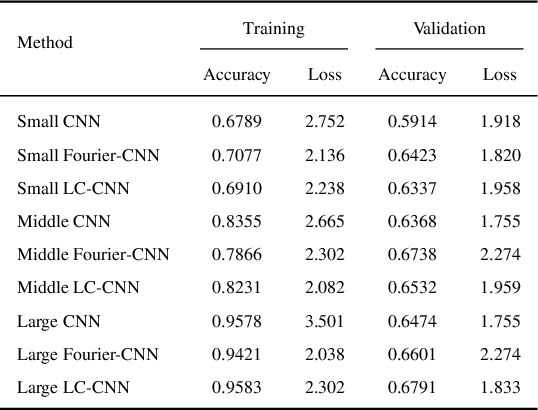
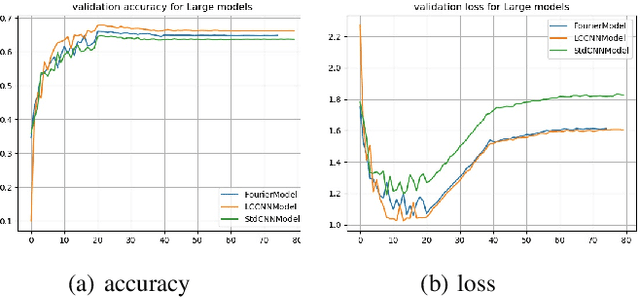
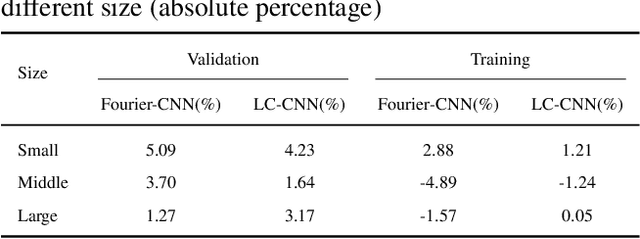
In the current research of neural networks, the activation function is manually specified by human and not able to change themselves during training. This paper focus on how to make the activation function trainable for deep neural networks. We use series and linear combination of different activation functions make activation functions continuously variable. Also, we test the performance of CNNs with Fourier series simulated activation(Fourier-CNN) and CNNs with linear combined activation function (LC-CNN) on Cifar-10 dataset. The result shows our trainable activation function reveals better performance than the most used ReLU activation function. Finally, we improves the performance of Fourier-CNN with Autoencoder, and test the performance of PSO algorithm in optimizing the parameters of networks
Continuous control of an underground loader using deep reinforcement learning
Mar 23, 2021
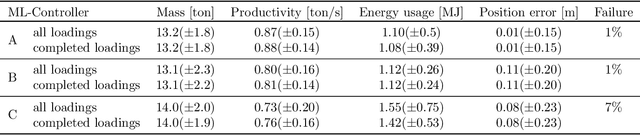

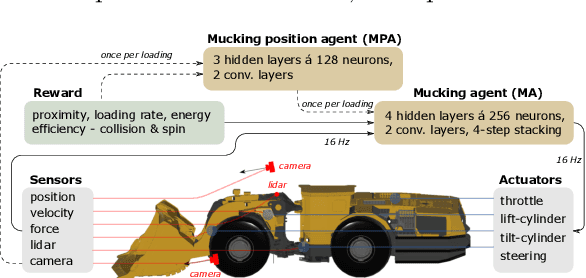
Reinforcement learning control of an underground loader is investigated in simulated environment, using a multi-agent deep neural network approach. At the start of each loading cycle, one agent selects the dig position from a depth camera image of the pile of fragmented rock. A second agent is responsible for continuous control of the vehicle, with the goal of filling the bucket at the selected loading point, while avoiding collisions, getting stuck, or losing ground traction. It relies on motion and force sensors, as well as on camera and lidar. Using a soft actor-critic algorithm the agents learn policies for efficient bucket filling over many subsequent loading cycles, with clear ability to adapt to the changing environment. The best results, on average 75% of the max capacity, are obtained when including a penalty for energy usage in the reward.
Adversarial Example Detection for DNN Models: A Review
May 01, 2021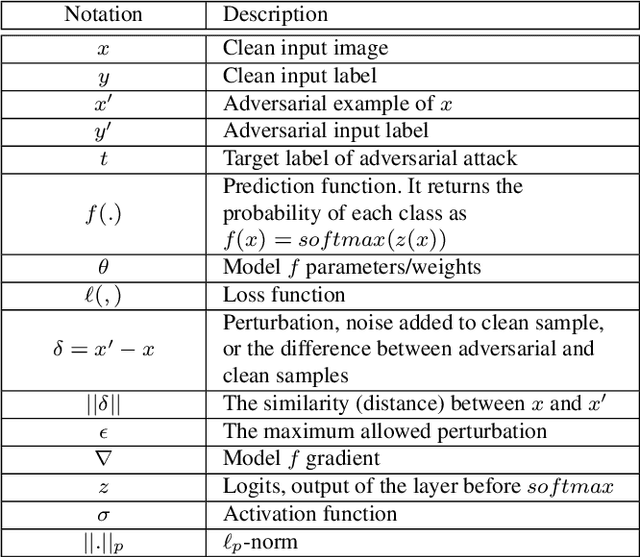
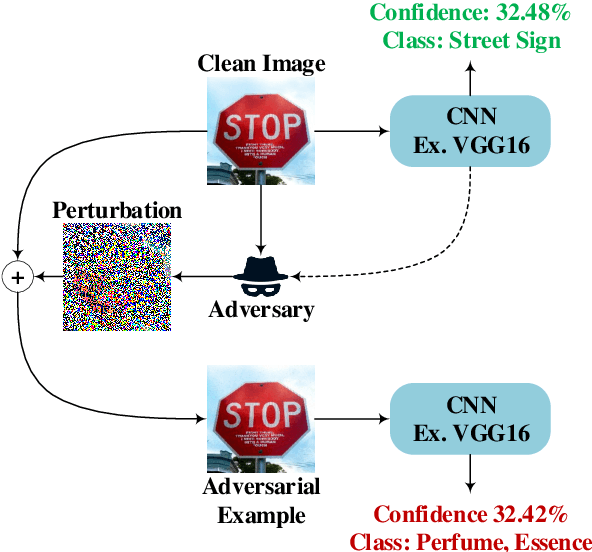
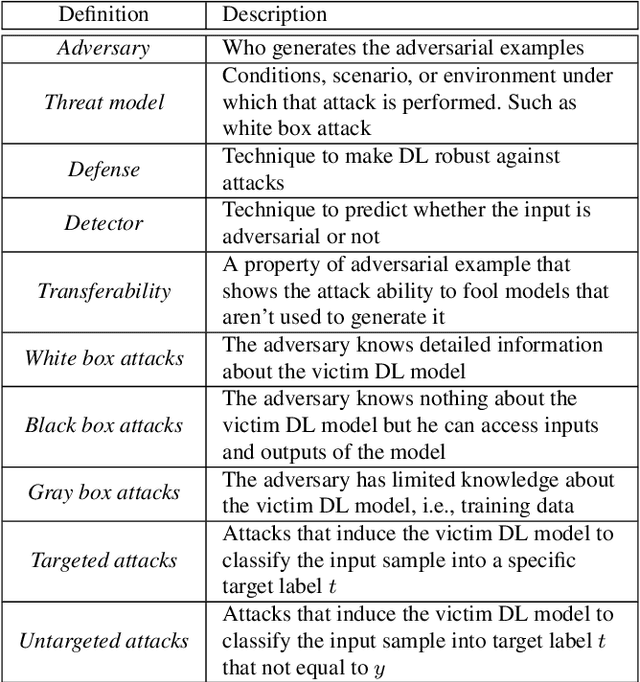
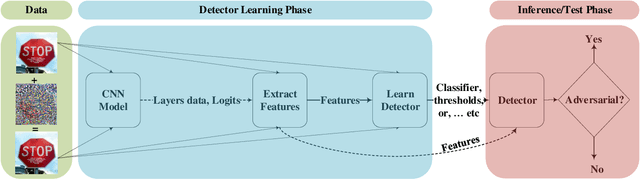
Deep Learning (DL) has shown great success in many human-related tasks, which has led to its adoption in many computer vision based applications, such as security surveillance system, autonomous vehicles and healthcare. Such safety-critical applications have to draw its path to success deployment once they have the capability to overcome safety-critical challenges. Among these challenges are the defense against or/and the detection of the adversarial example (AE). Adversary can carefully craft small, often imperceptible, noise called perturbations, to be added to the clean image to generate the AE. The aim of AE is to fool the DL model which makes it a potential risk for DL applications. Many test-time evasion attacks and countermeasures, i.e., defense or detection methods, are proposed in the literature. Moreover, few reviews and surveys were published and theoretically showed the taxonomy of the threats and the countermeasure methods with little focus in AE detection methods. In this paper, we attempt to provide a theoretical and experimental review for AE detection methods. A detailed discussion for such methods is provided and experimental results for eight state-of-the-art detectors are presented under different scenarios on four datasets. We also provide potential challenges and future perspectives for this research direction.