 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning Spatial Context with Graph Neural Network for Multi-Person Pose Grouping
Apr 06, 2021
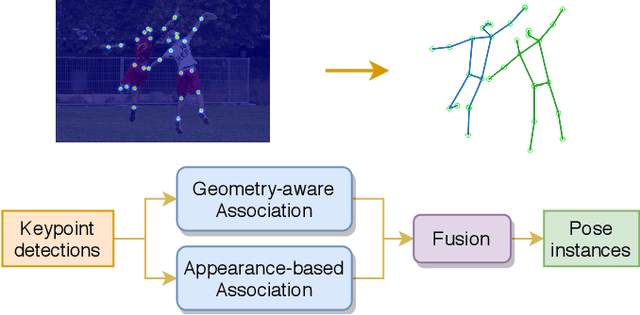
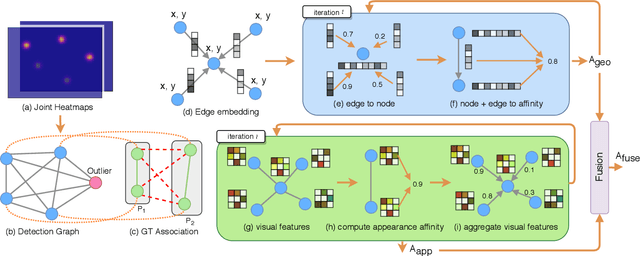


Bottom-up approaches for image-based multi-person pose estimation consist of two stages: (1) keypoint detection and (2) grouping of the detected keypoints to form person instances. Current grouping approaches rely on learned embedding from only visual features that completely ignore the spatial configuration of human poses. In this work, we formulate the grouping task as a graph partitioning problem, where we learn the affinity matrix with a Graph Neural Network (GNN). More specifically, we design a Geometry-aware Association GNN that utilizes spatial information of the keypoints and learns local affinity from the global context. The learned geometry-based affinity is further fused with appearance-based affinity to achieve robust keypoint association. Spectral clustering is used to partition the graph for the formation of the pose instances. Experimental results on two benchmark datasets show that our proposed method outperforms existing appearance-only grouping frameworks, which shows the effectiveness of utilizing spatial context for robust grouping. Source code is available at: https://github.com/jiahaoLjh/PoseGrouping.
Multi-Instance Aware Localization for End-to-End Imitation Learning
Dec 26, 2020

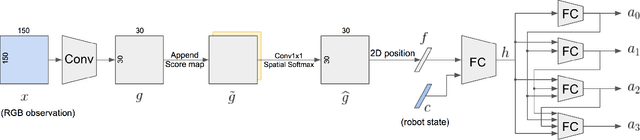
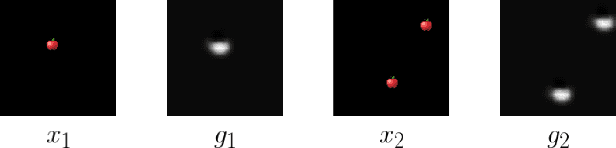
Existing architectures for imitation learning using image-to-action policy networks perform poorly when presented with an input image containing multiple instances of the object of interest, especially when the number of expert demonstrations available for training are limited. We show that end-to-end policy networks can be trained in a sample efficient manner by (a) appending the feature map output of the vision layers with an embedding that can indicate instance preference or take advantage of an implicit preference present in the expert demonstrations, and (b) employing an autoregressive action generator network for the control layers. The proposed architecture for localization has improved accuracy and sample efficiency and can generalize to the presence of more instances of objects than seen during training. When used for end-to-end imitation learning to perform reach, push, and pick-and-place tasks on a real robot, training is achieved with as few as 15 expert demonstrations.
Unsupervised Noisy Tracklet Person Re-identification
Jan 16, 2021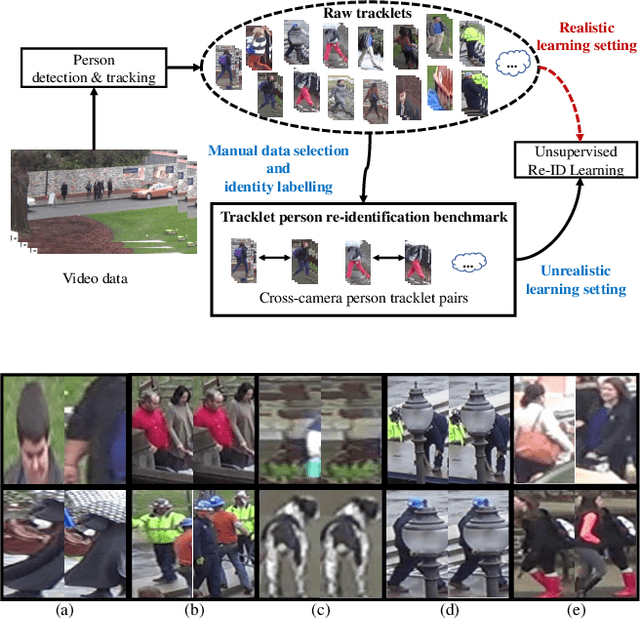

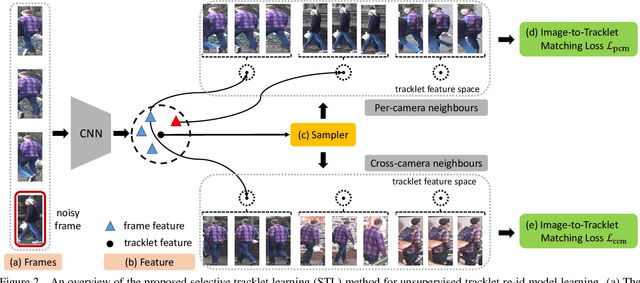
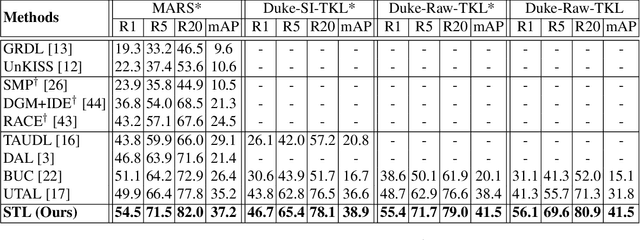
Existing person re-identification (re-id) methods mostly rely on supervised model learning from a large set of person identity labelled training data per domain. This limits their scalability and usability in large scale deployments. In this work, we present a novel selective tracklet learning (STL) approach that can train discriminative person re-id models from unlabelled tracklet data in an unsupervised manner. This avoids the tedious and costly process of exhaustively labelling person image/tracklet true matching pairs across camera views. Importantly, our method is particularly more robust against arbitrary noisy data of raw tracklets therefore scalable to learning discriminative models from unconstrained tracking data. This differs from a handful of existing alternative methods that often assume the existence of true matches and balanced tracklet samples per identity class. This is achieved by formulating a data adaptive image-to-tracklet selective matching loss function explored in a multi-camera multi-task deep learning model structure. Extensive comparative experiments demonstrate that the proposed STL model surpasses significantly the state-of-the-art unsupervised learning and one-shot learning re-id methods on three large tracklet person re-id benchmarks.
Visual Alignment Constraint for Continuous Sign Language Recognition
Apr 06, 2021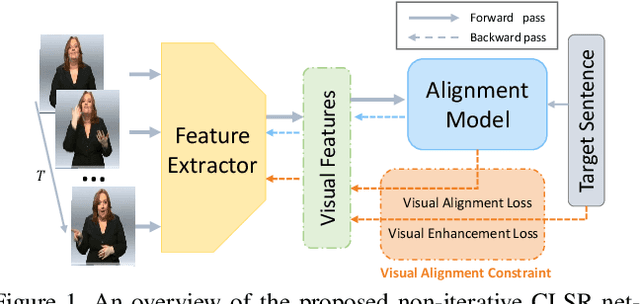

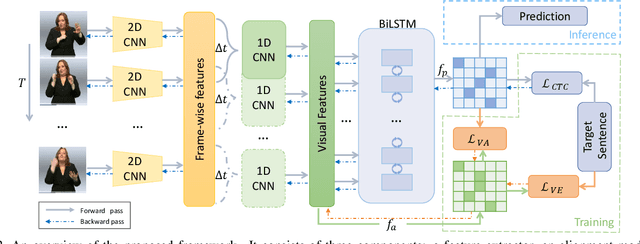
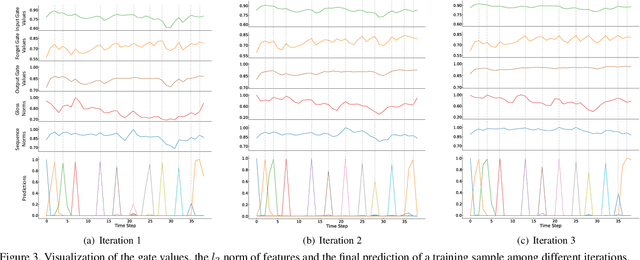
Vision-based Continuous Sign Language Recognition (CSLR) aims to recognize unsegmented gestures from image sequences. To better train CSLR models, the iterative training scheme is widely adopted to alleviate the overfitting of the alignment model. Although the iterative training scheme can improve performance, it will also increase the training time. In this work, we revisit the overfitting problem in recent CTC-based CSLR works and attribute it to the insufficient training of the feature extractor. To solve this problem, we propose a Visual Alignment Constraint (VAC) to enhance the feature extractor with more alignment supervision. Specifically, the proposed VAC is composed of two auxiliary losses: one makes predictions based on visual features only, and the other aligns short-term visual and long-term contextual features. Moreover, we further propose two metrics to evaluate the contributions of the feature extractor and the alignment model, which provide evidence for the overfitting problem. The proposed VAC achieves competitive performance on two challenging CSLR datasets and experimental results show its effectiveness.
Objects are Different: Flexible Monocular 3D Object Detection
Apr 06, 2021
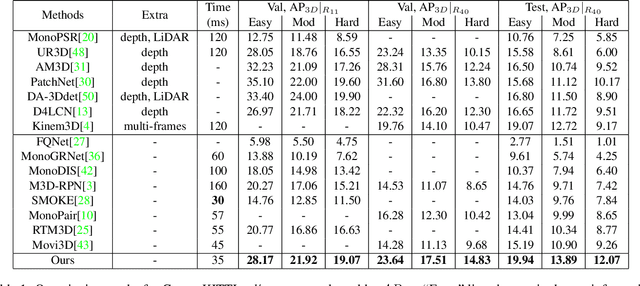
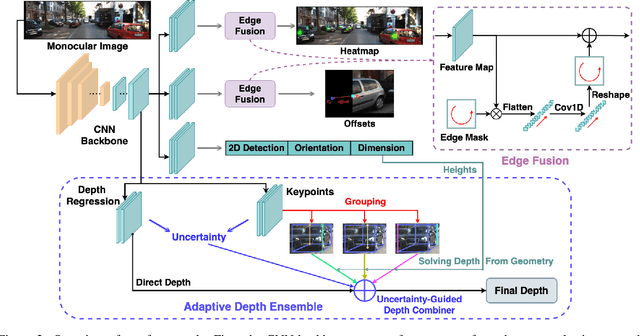
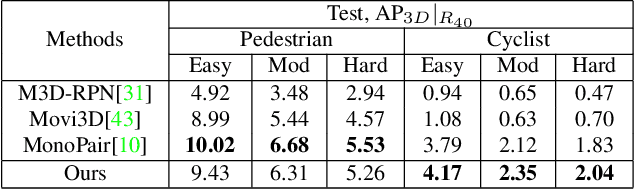
The precise localization of 3D objects from a single image without depth information is a highly challenging problem. Most existing methods adopt the same approach for all objects regardless of their diverse distributions, leading to limited performance for truncated objects. In this paper, we propose a flexible framework for monocular 3D object detection which explicitly decouples the truncated objects and adaptively combines multiple approaches for object depth estimation. Specifically, we decouple the edge of the feature map for predicting long-tail truncated objects so that the optimization of normal objects is not influenced. Furthermore, we formulate the object depth estimation as an uncertainty-guided ensemble of directly regressed object depth and solved depths from different groups of keypoints. Experiments demonstrate that our method outperforms the state-of-the-art method by relatively 27\% for the moderate level and 30\% for the hard level in the test set of KITTI benchmark while maintaining real-time efficiency. Code will be available at \url{https://github.com/zhangyp15/MonoFlex}.
Fractional Calculus In Image Processing: A Review
Aug 10, 2016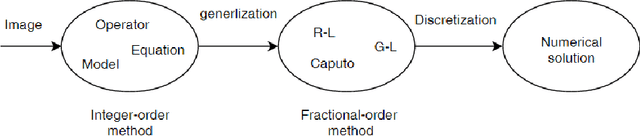
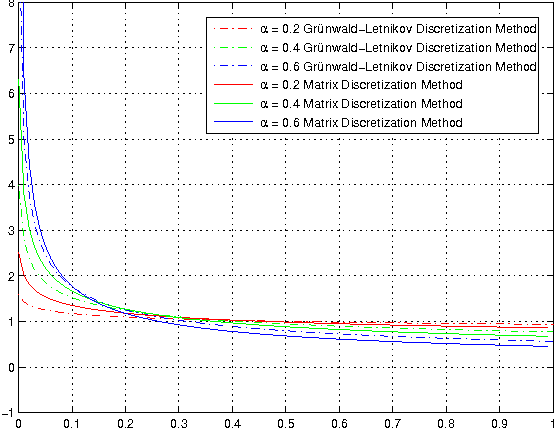

Over the last decade, it has been demonstrated that many systems in science and engineering can be modeled more accurately by fractional-order than integer-order derivatives, and many methods are developed to solve the problem of fractional systems. Due to the extra free parameter order, fractional-order based methods provide additional degree of freedom in optimization performance. Not surprisingly, many fractional-order based methods have been used in image processing field. Herein recent studies are reviewed in ten sub-fields, which include image enhancement, image denoising, image edge detection, image segmentation, image registration, image recognition, image fusion, image encryption, image compression and image restoration. In sum, it is well proved that as a fundamental mathematic tool, fractional-order derivative shows great success in image processing.
Super-Resolving Compressed Video in Coding Chain
Mar 26, 2021
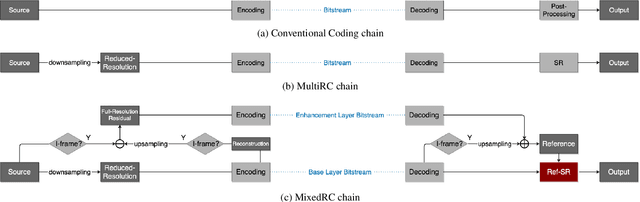

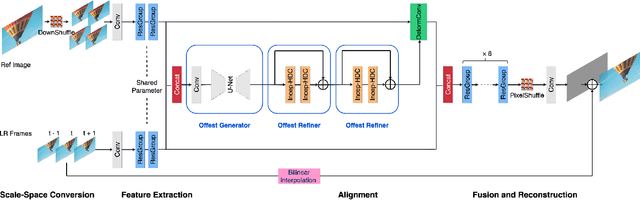
Scaling and lossy coding are widely used in video transmission and storage. Previous methods for enhancing the resolution of such videos often ignore the inherent interference between resolution loss and compression artifacts, which compromises perceptual video quality. To address this problem, we present a mixed-resolution coding framework, which cooperates with a reference-based DCNN. In this novel coding chain, the reference-based DCNN learns the direct mapping from low-resolution (LR) compressed video to their high-resolution (HR) clean version at the decoder side. We further improve reconstruction quality by devising an efficient deformable alignment module with receptive field block to handle various motion distances and introducing a disentangled loss that helps networks distinguish the artifact patterns from texture. Extensive experiments demonstrate the effectiveness of proposed innovations by comparing with state-of-the-art single image, video and reference-based restoration methods.
DTNN: Energy-efficient Inference with Dendrite Tree Inspired Neural Networks for Edge Vision Applications
May 25, 2021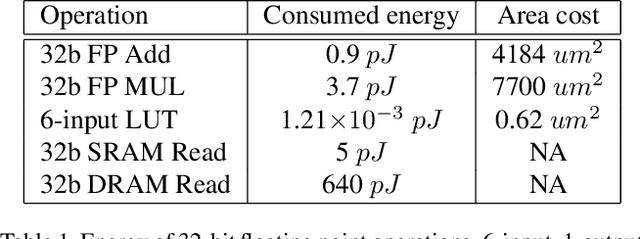
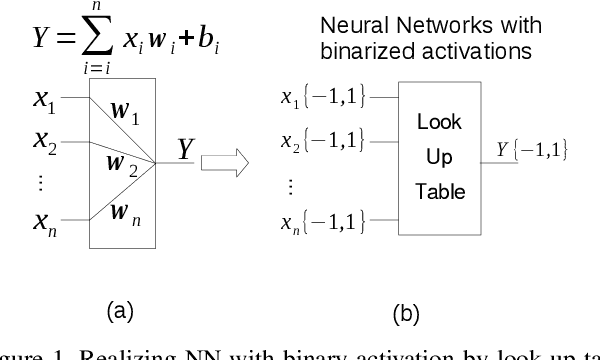

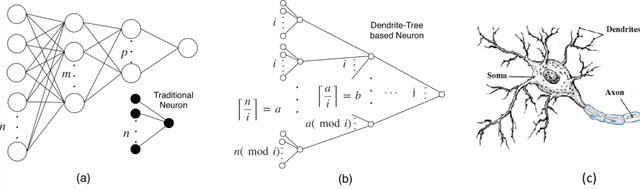
Deep neural networks (DNN) have achieved remarkable success in computer vision (CV). However, training and inference of DNN models are both memory and computation intensive, incurring significant overhead in terms of energy consumption and silicon area. In particular, inference is much more cost-sensitive than training because training can be done offline with powerful platforms, while inference may have to be done on battery powered devices with constrained form factors, especially for mobile or edge vision applications. In order to accelerate DNN inference, model quantization was proposed. However previous works only focus on the quantization rate without considering the efficiency of operations. In this paper, we propose Dendrite-Tree based Neural Network (DTNN) for energy-efficient inference with table lookup operations enabled by activation quantization. In DTNN both costly weight access and arithmetic computations are eliminated for inference. We conducted experiments on various kinds of DNN models such as LeNet-5, MobileNet, VGG, and ResNet with different datasets, including MNIST, Cifar10/Cifar100, SVHN, and ImageNet. DTNN achieved significant energy saving (19.4X and 64.9X improvement on ResNet-18 and VGG-11 with ImageNet, respectively) with negligible loss of accuracy. To further validate the effectiveness of DTNN and compare with state-of-the-art low energy implementation for edge vision, we design and implement DTNN based MLP image classifiers using off-the-shelf FPGAs. The results show that DTNN on the FPGA, with higher accuracy, could achieve orders of magnitude better energy consumption and latency compared with the state-of-the-art low energy approaches reported that use ASIC chips.
mustGAN: Multi-Stream Generative Adversarial Networks for MR Image Synthesis
Sep 25, 2019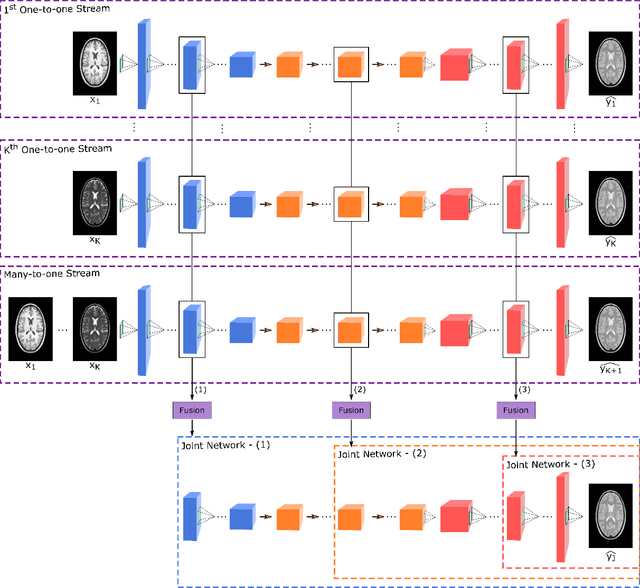
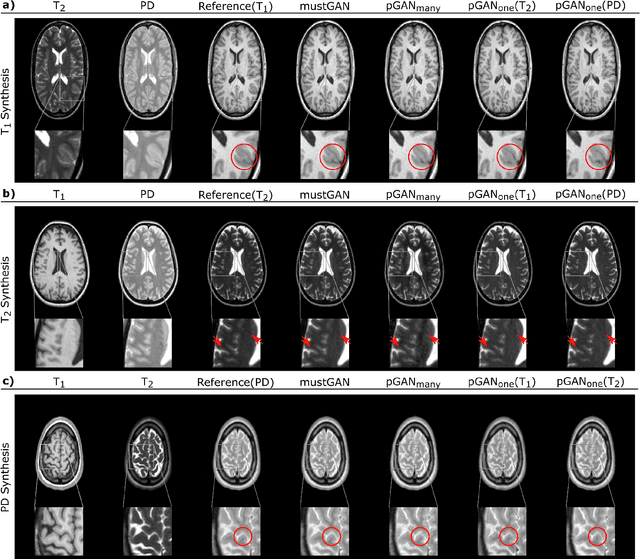
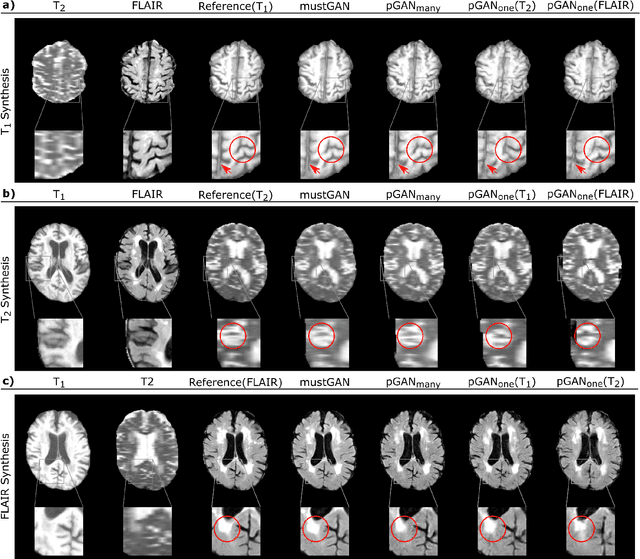
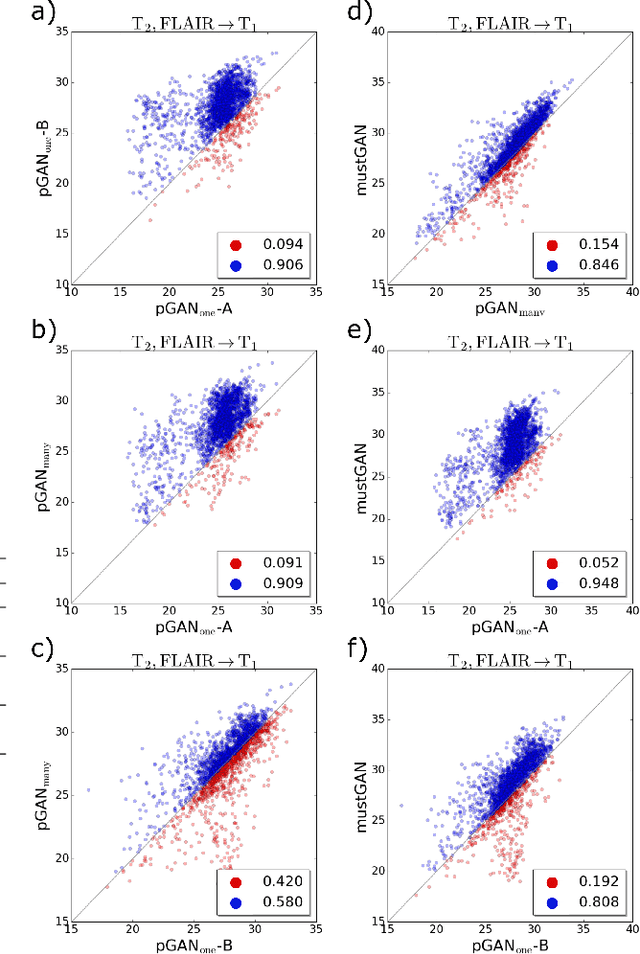
Multi-contrast MRI protocols increase the level of morphological information available for diagnosis. Yet, the number and quality of contrasts is limited in practice by various factors including scan time and patient motion. Synthesis of missing or corrupted contrasts can alleviate this limitation to improve clinical utility. Common approaches for multi-contrast MRI involve either one-to-one and many-to-one synthesis methods. One-to-one methods take as input a single source contrast, and they learn a latent representation sensitive to unique features of the source. Meanwhile, many-to-one methods receive multiple distinct sources, and they learn a shared latent representation more sensitive to common features across sources. For enhanced image synthesis, here we propose a multi-stream approach that aggregates information across multiple source images via a mixture of multiple one-to-one streams and a joint many-to-one stream. The shared feature maps generated in the many-to-one stream and the complementary feature maps generated in the one-to-one streams are combined with a fusion block. The location of the fusion block is adaptively modified to maximize task-specific performance. Qualitative and quantitative assessments on T1-, T2-, PD-weighted and FLAIR images clearly demonstrate the superior performance of the proposed method compared to previous state-of-the-art one-to-one and many-to-one methods.
ISP Distillation
Jan 25, 2021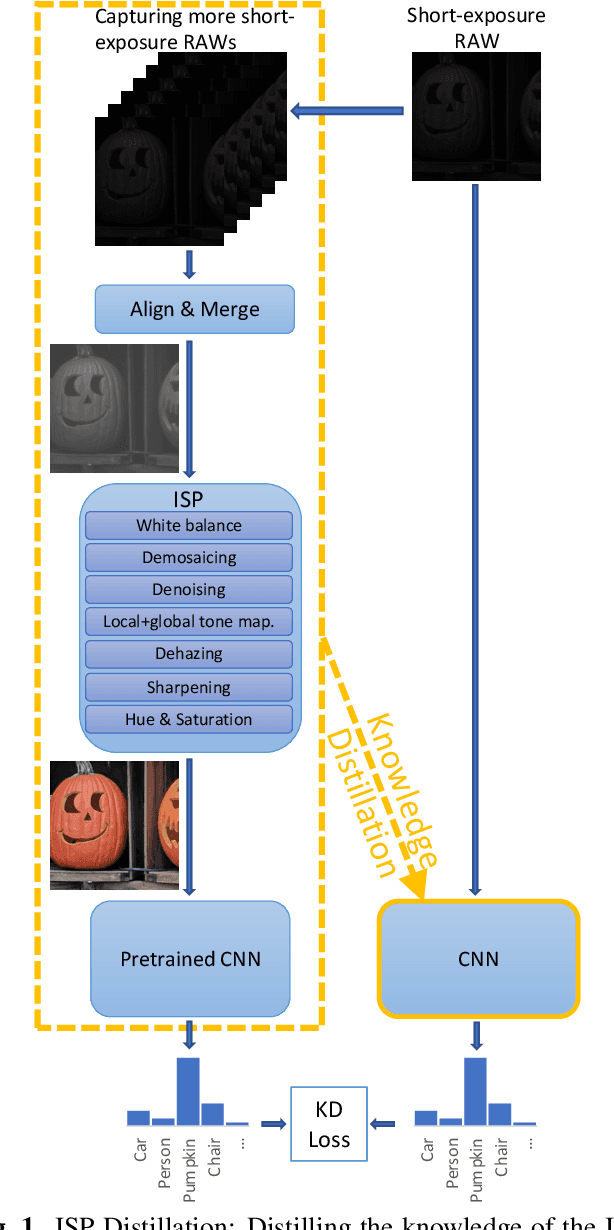
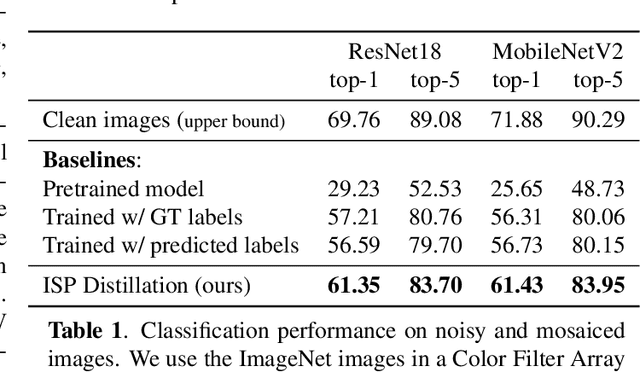
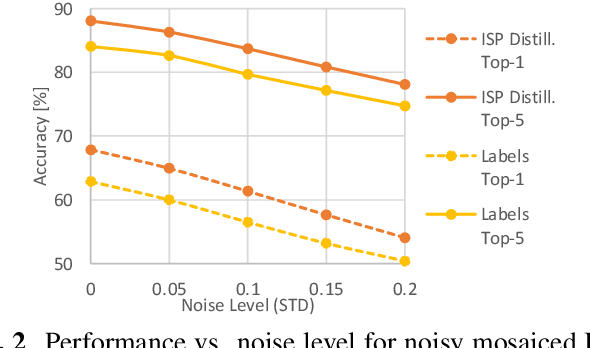
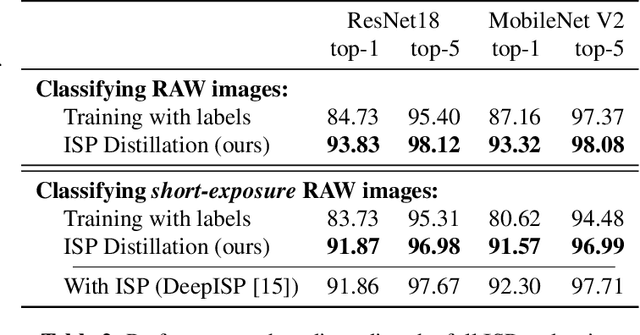
Nowadays, many of the images captured are "observed" by machines only and not by humans, for example, robots' or autonomous cars' cameras. High-level machine vision models, such as object recognition, assume images are transformed to some canonical image space by the camera ISP. However, the camera ISP is optimized for producing visually pleasing images to human observers and not for machines, thus, one may spare the ISP compute time and apply the vision models directly to the raw data. Yet, it has been shown that training such models directly on the RAW images results in a performance drop. To mitigate this drop in performance (without the need to annotate RAW data), we use a dataset of RAW and RGB image pairs, which can be easily acquired with no human labeling. We then train a model that is applied directly to the RAW data by using knowledge distillation such that the model predictions for RAW images will be aligned with the predictions of an off-the-shelf pre-trained model for processed RGB images. Our experiments show that our performance on RAW images is significantly better than a model trained on labeled RAW images. It also reasonably matches the predictions of a pre-trained model on processed RGB images, while saving the ISP compute overhead.