 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFractional-Order Federated Learning
Feb 17, 2026Federated learning (FL) allows remote clients to train a global model collaboratively while protecting client privacy. Despite its privacy-preserving benefits, FL has significant drawbacks, including slow convergence, high communication cost, and non-independent-and-identically-distributed (non-IID) data. In this work, we present a novel FedAvg variation called Fractional-Order Federated Averaging (FOFedAvg), which incorporates Fractional-Order Stochastic Gradient Descent (FOSGD) to capture long-range relationships and deeper historical information. By introducing memory-aware fractional-order updates, FOFedAvg improves communication efficiency and accelerates convergence while mitigating instability caused by heterogeneous, non-IID client data. We compare FOFedAvg against a broad set of established federated optimization algorithms on benchmark datasets including MNIST, FEMNIST, CIFAR-10, CIFAR-100, EMNIST, the Cleveland heart disease dataset, Sent140, PneumoniaMNIST, and Edge-IIoTset. Across a range of non-IID partitioning schemes, FOFedAvg is competitive with, and often outperforms, these baselines in terms of test performance and convergence speed. On the theoretical side, we prove that FOFedAvg converges to a stationary point under standard smoothness and bounded-variance assumptions for fractional order $0<α\le 1$. Together, these results show that fractional-order, memory-aware updates can substantially improve the robustness and effectiveness of federated learning, offering a practical path toward distributed training on heterogeneous data.
Fractional Order Federated Learning for Battery Electric Vehicle Energy Consumption Modeling
Feb 13, 2026Federated learning on connected electric vehicles (BEVs) faces severe instability due to intermittent connectivity, time-varying client participation, and pronounced client-to-client variation induced by diverse operating conditions. Conventional FedAvg and many advanced methods can suffer from excessive drift and degraded convergence under these realistic constraints. This work introduces Fractional-Order Roughness-Informed Federated Averaging (FO-RI-FedAvg), a lightweight and modular extension of FedAvg that improves stability through two complementary client-side mechanisms: (i) adaptive roughness-informed proximal regularization, which dynamically tunes the pull toward the global model based on local loss-landscape roughness, and (ii) non-integer-order local optimization, which incorporates short-term memory to smooth conflicting update directions. The approach preserves standard FedAvg server aggregation, adds only element-wise operations with amortizable overhead, and allows independent toggling of each component. Experiments on two real-world BEV energy prediction datasets, VED and its extended version eVED, show that FO-RI-FedAvg achieves improved accuracy and more stable convergence compared to strong federated baselines, particularly under reduced client participation.
Roughness-Informed Federated Learning
Feb 11, 2026Federated Learning (FL) enables collaborative model training across distributed clients while preserving data privacy, yet faces challenges in non-independent and identically distributed (non-IID) settings due to client drift, which impairs convergence. We propose RI-FedAvg, a novel FL algorithm that mitigates client drift by incorporating a Roughness Index (RI)-based regularization term into the local objective, adaptively penalizing updates based on the fluctuations of local loss landscapes. This paper introduces RI-FedAvg, leveraging the RI to quantify the roughness of high-dimensional loss functions, ensuring robust optimization in heterogeneous settings. We provide a rigorous convergence analysis for non-convex objectives, establishing that RI-FedAvg converges to a stationary point under standard assumptions. Extensive experiments on MNIST, CIFAR-10, and CIFAR-100 demonstrate that RI-FedAvg outperforms state-of-the-art baselines, including FedAvg, FedProx, FedDyn, SCAFFOLD, and DP-FedAvg, achieving higher accuracy and faster convergence in non-IID scenarios. Our results highlight RI-FedAvg's potential to enhance the robustness and efficiency of federated learning in practical, heterogeneous environments.
When Gradient Clipping Becomes a Control Mechanism for Differential Privacy in Deep Learning
Feb 11, 2026Privacy-preserving training on sensitive data commonly relies on differentially private stochastic optimization with gradient clipping and Gaussian noise. The clipping threshold is a critical control knob: if set too small, systematic over-clipping induces optimization bias; if too large, injected noise dominates updates and degrades accuracy. Existing adaptive clipping methods often depend on per-example gradient norm statistics, adding computational overhead and introducing sensitivity to datasets and architectures. We propose a control-driven clipping strategy that adapts the threshold using a lightweight, weight-only spectral diagnostic computed from model parameters. At periodic probe steps, the method analyzes a designated weight matrix via spectral decomposition and estimates a heavy-tailed spectral indicator associated with training stability. This indicator is smoothed over time and fed into a bounded feedback controller that updates the clipping threshold multiplicatively in the log domain. Because the controller uses only parameters produced during privacy-preserving training, the resulting threshold updates are post-processing and do not increase privacy loss beyond that of the underlying DP optimizer under standard composition accounting.
Statistical Roughness-Informed Machine Unlearning
Feb 10, 2026Machine unlearning aims to remove the influence of a designated forget set from a trained model while preserving utility on the retained data. In modern deep networks, approximate unlearning frequently fails under large or adversarial deletions due to pronounced layer-wise heterogeneity: some layers exhibit stable, well-regularized representations while others are brittle, undertrained, or overfit, so naive update allocation can trigger catastrophic forgetting or unstable dynamics. We propose Statistical-Roughness Adaptive Gradient Unlearning (SRAGU), a mechanism-first unlearning algorithm that reallocates unlearning updates using layer-wise statistical roughness operationalized via heavy-tailed spectral diagnostics of layer weight matrices. Starting from an Adaptive Gradient Unlearning (AGU) sensitivity signal computed on the forget set, SRAGU estimates a WeightWatcher-style heavy-tailed exponent for each layer, maps it to a bounded spectral stability weight, and uses this stability signal to spectrally reweight the AGU sensitivities before applying the same minibatch update form. This concentrates unlearning motion in spectrally stable layers while damping updates in unstable or overfit layers, improving stability under hard deletions. We evaluate unlearning via behavioral alignment to a gold retrained reference model trained from scratch on the retained data, using empirical prediction-divergence and KL-to-gold proxies on a forget-focused query set; we additionally report membership inference auditing as a complementary leakage signal, treating forget-set points as should-be-forgotten members during evaluation.
More Optimal Fractional-Order Stochastic Gradient Descent for Non-Convex Optimization Problems
May 05, 2025Fractional-order stochastic gradient descent (FOSGD) leverages fractional exponents to capture long-memory effects in optimization. However, its utility is often limited by the difficulty of tuning and stabilizing these exponents. We propose 2SED Fractional-Order Stochastic Gradient Descent (2SEDFOSGD), which integrates the Two-Scale Effective Dimension (2SED) algorithm with FOSGD to adapt the fractional exponent in a data-driven manner. By tracking model sensitivity and effective dimensionality, 2SEDFOSGD dynamically modulates the exponent to mitigate oscillations and hasten convergence. Theoretically, for onoconvex optimization problems, this approach preserves the advantages of fractional memory without the sluggish or unstable behavior observed in na\"ive fractional SGD. Empirical evaluations in Gaussian and $\alpha$-stable noise scenarios using an autoregressive (AR) model highlight faster convergence and more robust parameter estimates compared to baseline methods, underscoring the potential of dimension-aware fractional techniques for advanced modeling and estimation tasks.
Effective Dimension Aware Fractional-Order Stochastic Gradient Descent for Convex Optimization Problems
Mar 17, 2025



Fractional-order stochastic gradient descent (FOSGD) leverages a fractional exponent to capture long-memory effects in optimization, yet its practical impact is often constrained by the difficulty of tuning and stabilizing this exponent. In this work, we introduce 2SED Fractional-Order Stochastic Gradient Descent (2SEDFOSGD), a novel method that synergistically combines the Two-Scale Effective Dimension (2SED) algorithm with FOSGD to automatically calibrate the fractional exponent in a data-driven manner. By continuously gauging model sensitivity and effective dimensionality, 2SED dynamically adjusts the exponent to curb erratic oscillations and enhance convergence rates. Theoretically, we demonstrate how this dimension-aware adaptation retains the benefits of fractional memory while averting the sluggish or unstable behaviors frequently observed in naive fractional SGD. Empirical evaluations across multiple benchmarks confirm that our 2SED-driven fractional exponent approach not only converges faster but also achieves more robust final performance, suggesting broad applicability for fractional-order methodologies in large-scale machine learning and related domains.
Self-optimizing loop sifting and majorization for 3D reconstruction
Apr 22, 2021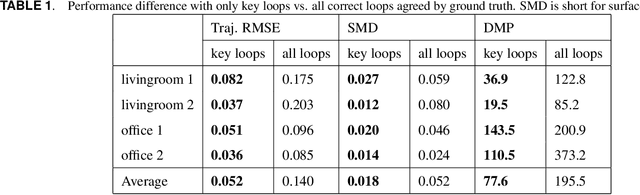
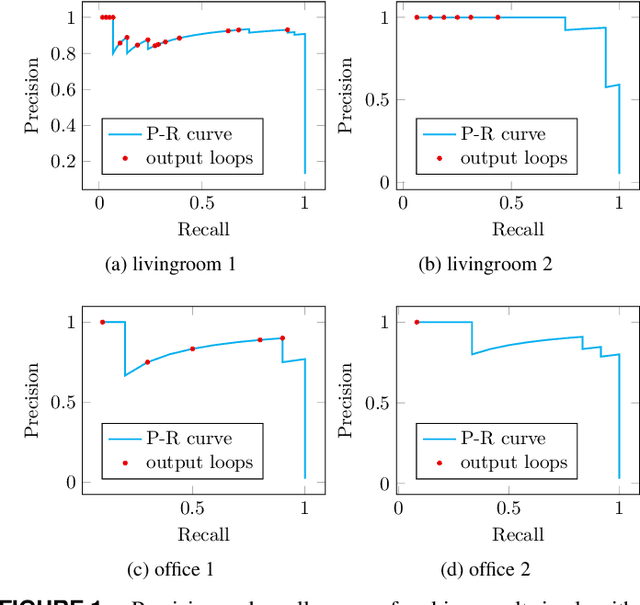
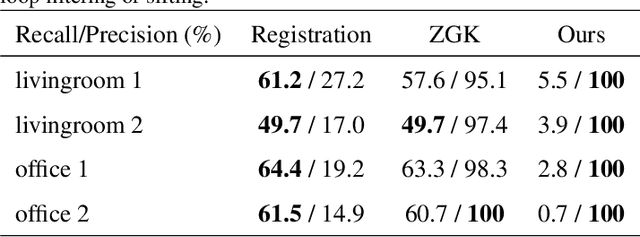

Visual simultaneous localization and mapping (vSLAM) and 3D reconstruction methods have gone through impressive progress. These methods are very promising for autonomous vehicle and consumer robot applications because they can map large-scale environments such as cities and indoor environments without the need for much human effort. However, when it comes to loop detection and optimization, there is still room for improvement. vSLAM systems tend to add the loops very conservatively to reduce the severe influence of the false loops. These conservative checks usually lead to correct loops rejected, thus decrease performance. In this paper, an algorithm that can sift and majorize loop detections is proposed. Our proposed algorithm can compare the usefulness and effectiveness of different loops with the dense map posterior (DMP) metric. The algorithm tests and decides the acceptance of each loop without a single user-defined threshold. Thus it is adaptive to different data conditions. The proposed method is general and agnostic to sensor type (as long as depth or LiDAR reading presents), loop detection, and optimization methods. Neither does it require a specific type of SLAM system. Thus it has great potential to be applied to various application scenarios. Experiments are conducted on public datasets. Results show that the proposed method outperforms state-of-the-art methods.
A metric for evaluating 3D reconstruction and mapping performance with no ground truthing
Jan 25, 2021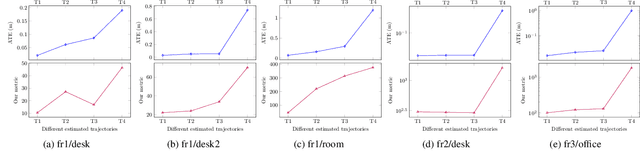
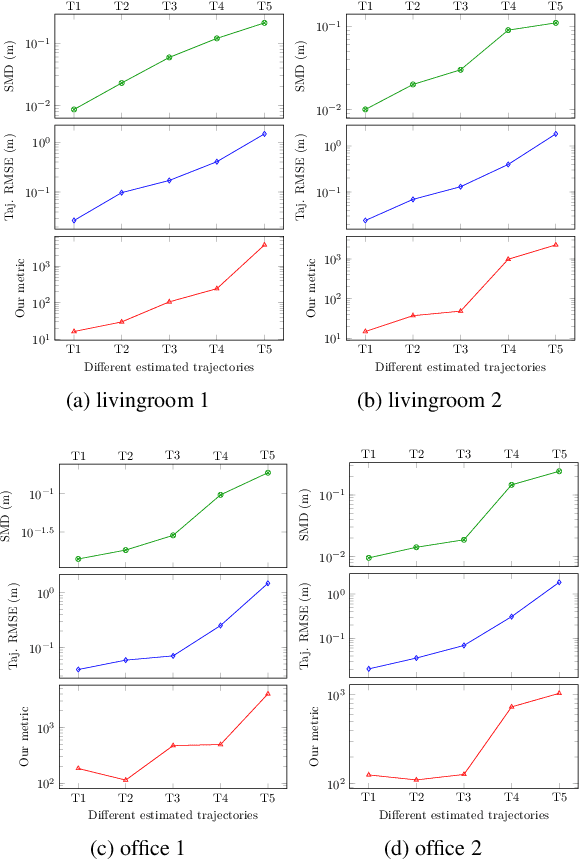
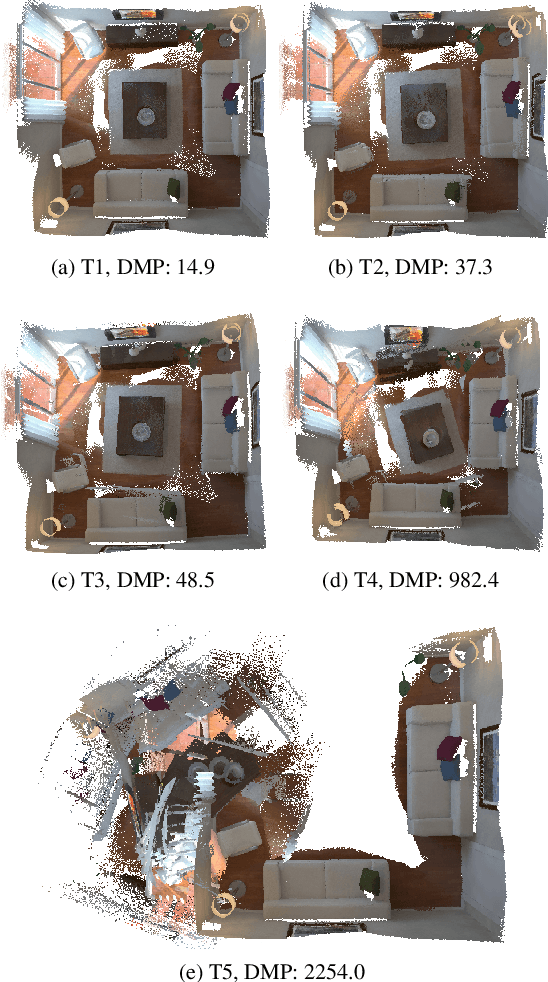
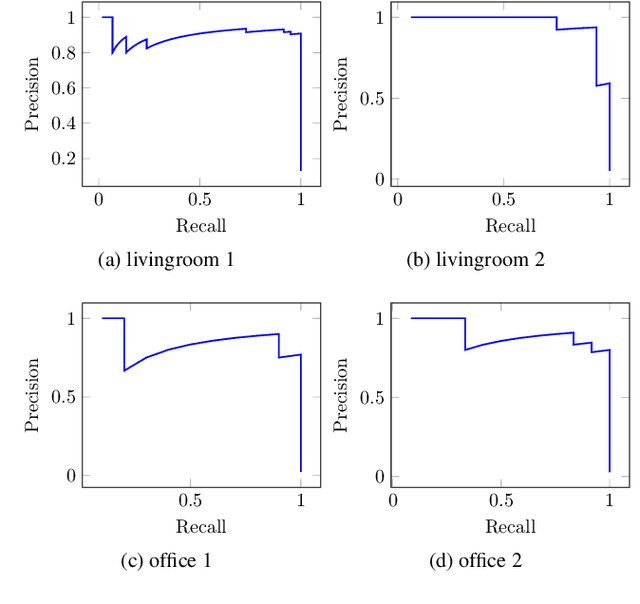
It is not easy when evaluating 3D mapping performance because existing metrics require ground truth data that can only be collected with special instruments. In this paper, we propose a metric, dense map posterior (DMP), for this evaluation. It can work without any ground truth data. Instead, it calculates a comparable value, reflecting a map posterior probability, from dense point cloud observations. In our experiments, the proposed DMP is benchmarked against ground truth-based metrics. Results show that DMP can provide a similar evaluation capability. The proposed metric makes evaluating different methods more flexible and opens many new possibilities, such as self-supervised methods and more available datasets.
More Informed Random Sample Consensus
Nov 18, 2020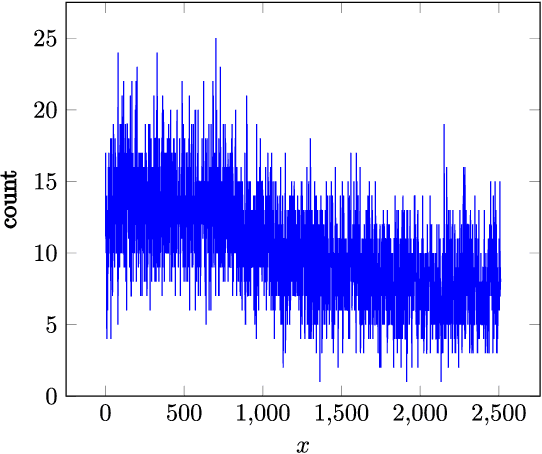
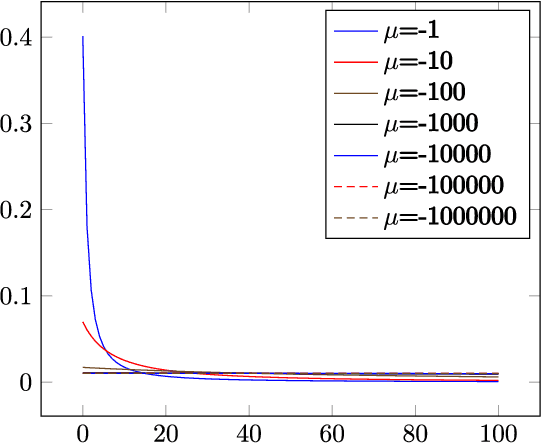
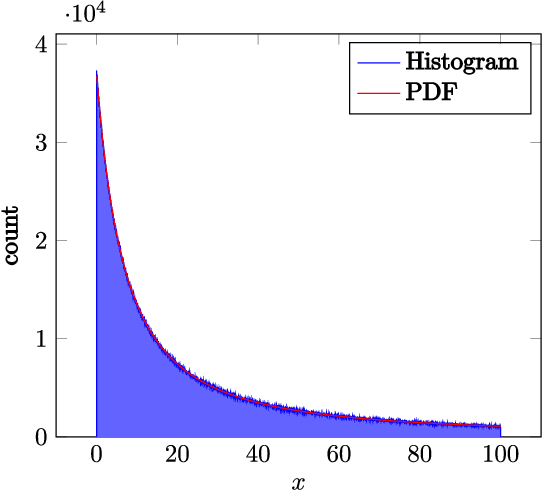
Random sample consensus (RANSAC) is a robust model-fitting algorithm. It is widely used in many fields including image-stitching and point cloud registration. In RANSAC, data is uniformly sampled for hypothesis generation. However, this uniform sampling strategy does not fully utilize all the information on many problems. In this paper, we propose a method that samples data with a L\'{e}vy distribution together with a data sorting algorithm. In the hypothesis sampling step of the proposed method, data is sorted with a sorting algorithm we proposed, which sorts data based on the likelihood of a data point being in the inlier set. Then, hypotheses are sampled from the sorted data with L\'{e}vy distribution. The proposed method is evaluated on both simulation and real-world public datasets. Our method shows better results compared with the uniform baseline method.