 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobile GUI Agent Privacy Personalization with Trajectory Induced Preference Optimization
Apr 13, 2026Mobile GUI agents powered by Multimodal Large Language Models (MLLMs) can execute complex tasks on mobile devices. Despite this progress, most existing systems still optimize task success or efficiency, neglecting users' privacy personalization. In this paper, we study the often-overlooked problem of agent personalization. We observe that personalization can induce systematic structural heterogeneity in execution trajectories. For example, privacy-first users often prefer protective actions, e.g., refusing permissions, logging out, and minimizing exposure, leading to logically different execution trajectories from utility-first users. Such variable-length and structurally different trajectories make standard preference optimization unstable and less informative. To address this issue, we propose Trajectory Induced Preference Optimization (TIPO), which uses preference-intensity weighting to emphasize key privacy-related steps and padding gating to suppress alignment noise. Results on our Privacy Preference Dataset show that TIPO improves persona alignment and distinction while preserving strong task executability, achieving 65.60% SR, 46.22 Compliance, and 66.67% PD, outperforming existing optimization methods across various GUI tasks. The code and dataset will be publicly released at https://github.com/Zhixin-L/TIPO.
ACT Now: Preempting LVLM Hallucinations via Adaptive Context Integration
Apr 01, 2026Large Vision-Language Models (LVLMs) frequently suffer from severe hallucination issues. Existing mitigation strategies predominantly rely on isolated, single-step states to enhance visual focus or suppress strong linguistic priors. However, these static approaches neglect dynamic context changes across the generation process and struggles to correct inherited information loss. To address this limitation, we propose Adaptive Context inTegration (ACT), a training-free inference intervention method that mitigates hallucination through the adaptive integration of contextual information. Specifically, we first propose visual context exploration, which leverages spatio-temporal profiling to adaptively amplify attention heads responsible for visual exploration. To further facilitate vision-language alignment, we propose semantic context aggregation that marginalizes potential semantic queries to effectively aggregate visual evidence, thereby resolving the information loss caused by the discrete nature of token prediction. Extensive experiments across diverse LVLMs demonstrate that ACT significantly reduces hallucinations and achieves competitive results on both discriminative and generative benchmarks, acting as a robust and highly adaptable solution without compromising fundamental generation capabilities.
INFACT: A Diagnostic Benchmark for Induced Faithfulness and Factuality Hallucinations in Video-LLMs
Mar 12, 2026Despite rapid progress, Video Large Language Models (Video-LLMs) remain unreliable due to hallucinations, which are outputs that contradict either video evidence (faithfulness) or verifiable world knowledge (factuality). Existing benchmarks provide limited coverage of factuality hallucinations and predominantly evaluate models only in clean settings. We introduce \textsc{INFACT}, a diagnostic benchmark comprising 9{,}800 QA instances with fine-grained taxonomies for faithfulness and factuality, spanning real and synthetic videos. \textsc{INFACT} evaluates models in four modes: Base (clean), Visual Degradation, Evidence Corruption, and Temporal Intervention for order-sensitive items. Reliability under induced modes is quantified using Resist Rate (RR) and Temporal Sensitivity Score (TSS). Experiments on 14 representative Video-LLMs reveal that higher Base-mode accuracy does not reliably translate to higher reliability in the induced modes, with evidence corruption reducing stability and temporal intervention yielding the largest degradation. Notably, many open-source baselines exhibit near-zero TSS on factuality, indicating pronounced temporal inertia on order-sensitive questions.
T2VAttack: Adversarial Attack on Text-to-Video Diffusion Models
Dec 30, 2025The rapid evolution of Text-to-Video (T2V) diffusion models has driven remarkable advancements in generating high-quality, temporally coherent videos from natural language descriptions. Despite these achievements, their vulnerability to adversarial attacks remains largely unexplored. In this paper, we introduce T2VAttack, a comprehensive study of adversarial attacks on T2V diffusion models from both semantic and temporal perspectives. Considering the inherently dynamic nature of video data, we propose two distinct attack objectives: a semantic objective to evaluate video-text alignment and a temporal objective to assess the temporal dynamics. To achieve an effective and efficient attack process, we propose two adversarial attack methods: (i) T2VAttack-S, which identifies semantically or temporally critical words in prompts and replaces them with synonyms via greedy search, and (ii) T2VAttack-I, which iteratively inserts optimized words with minimal perturbation to the prompt. By combining these objectives and strategies, we conduct a comprehensive evaluation on the adversarial robustness of several state-of-the-art T2V models, including ModelScope, CogVideoX, Open-Sora, and HunyuanVideo. Our experiments reveal that even minor prompt modifications, such as the substitution or insertion of a single word, can cause substantial degradation in semantic fidelity and temporal dynamics, highlighting critical vulnerabilities in current T2V diffusion models.
Visual Alignment Constraint for Continuous Sign Language Recognition
Apr 06, 2021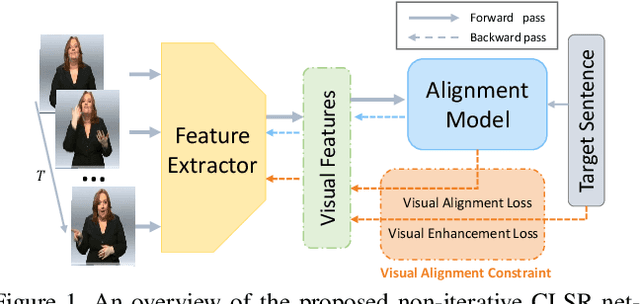

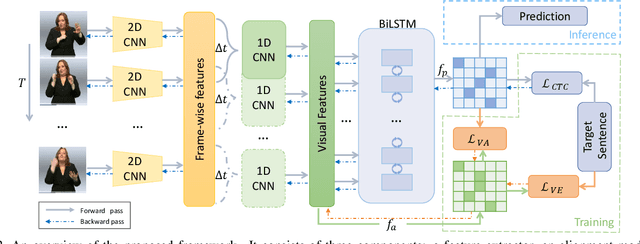
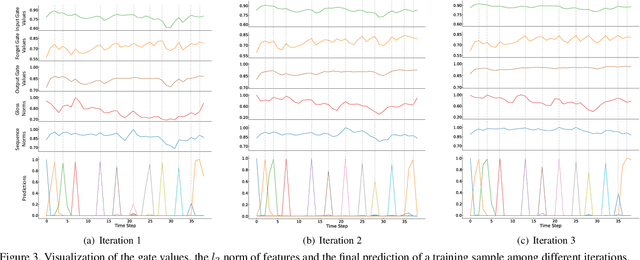
Vision-based Continuous Sign Language Recognition (CSLR) aims to recognize unsegmented gestures from image sequences. To better train CSLR models, the iterative training scheme is widely adopted to alleviate the overfitting of the alignment model. Although the iterative training scheme can improve performance, it will also increase the training time. In this work, we revisit the overfitting problem in recent CTC-based CSLR works and attribute it to the insufficient training of the feature extractor. To solve this problem, we propose a Visual Alignment Constraint (VAC) to enhance the feature extractor with more alignment supervision. Specifically, the proposed VAC is composed of two auxiliary losses: one makes predictions based on visual features only, and the other aligns short-term visual and long-term contextual features. Moreover, we further propose two metrics to evaluate the contributions of the feature extractor and the alignment model, which provide evidence for the overfitting problem. The proposed VAC achieves competitive performance on two challenging CSLR datasets and experimental results show its effectiveness.