 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Rapid AI Development Cycle for the Coronavirus (COVID-19) Pandemic: Initial Results for Automated Detection & Patient Monitoring using Deep Learning CT Image Analysis
Mar 24, 2020
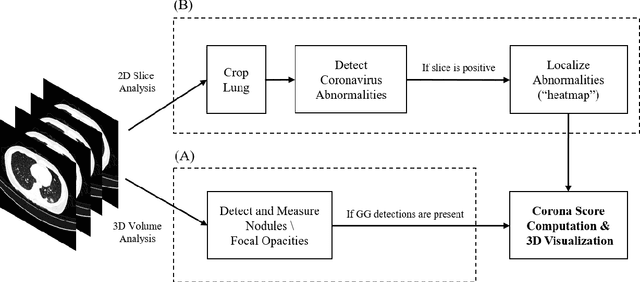
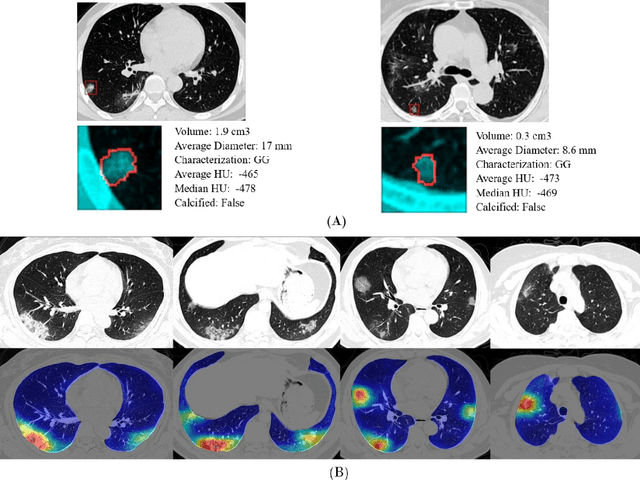
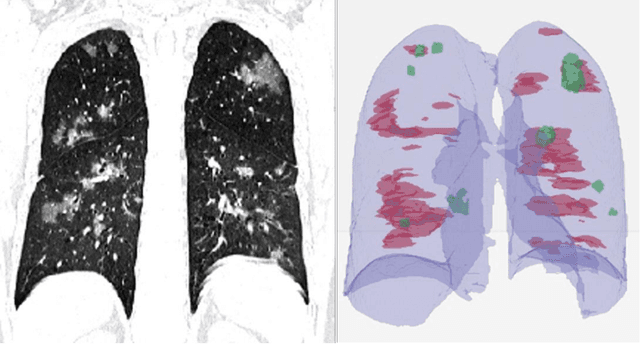
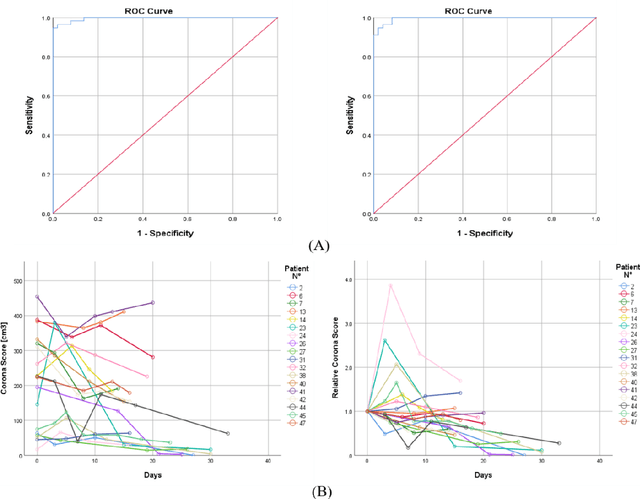
Purpose: Develop AI-based automated CT image analysis tools for detection, quantification, and tracking of Coronavirus; demonstrate they can differentiate coronavirus patients from non-patients. Materials and Methods: Multiple international datasets, including from Chinese disease-infected areas were included. We present a system that utilizes robust 2D and 3D deep learning models, modifying and adapting existing AI models and combining them with clinical understanding. We conducted multiple retrospective experiments to analyze the performance of the system in the detection of suspected COVID-19 thoracic CT features and to evaluate evolution of the disease in each patient over time using a 3D volume review, generating a Corona score. The study includes a testing set of 157 international patients (China and U.S). Results: Classification results for Coronavirus vs Non-coronavirus cases per thoracic CT studies were 0.996 AUC (95%CI: 0.989-1.00) ; on datasets of Chinese control and infected patients. Possible working point: 98.2% sensitivity, 92.2% specificity. For time analysis of Coronavirus patients, the system output enables quantitative measurements for smaller opacities (volume, diameter) and visualization of the larger opacities in a slice-based heat map or a 3D volume display. Our suggested Corona score measures the progression of disease over time. Conclusion: This initial study, which is currently being expanded to a larger population, demonstrated that rapidly developed AI-based image analysis can achieve high accuracy in detection of Coronavirus as well as quantification and tracking of disease burden.
When Dictionary Learning Meets Deep Learning: Deep Dictionary Learning and Coding Network for Image Recognition with Limited Data
May 21, 2020
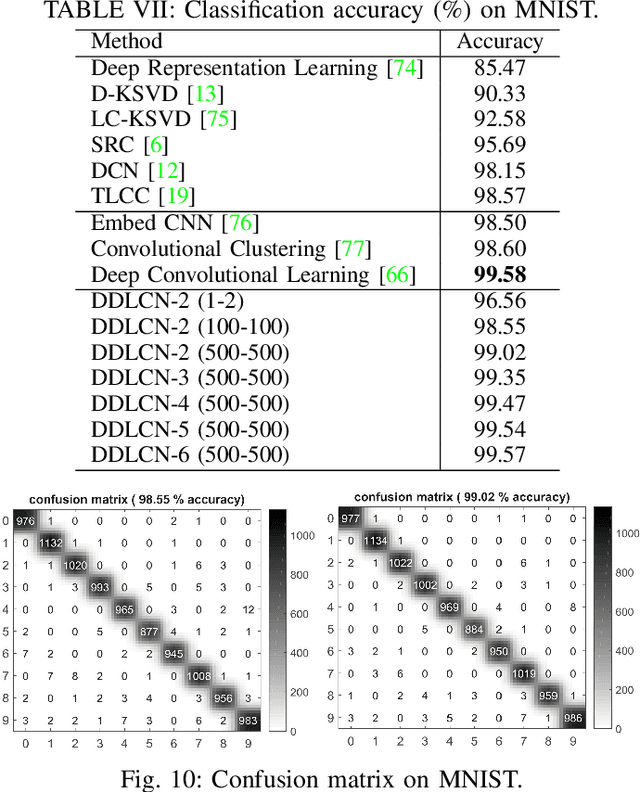


We present a new Deep Dictionary Learning and Coding Network (DDLCN) for image recognition tasks with limited data. The proposed DDLCN has most of the standard deep learning layers (e.g., input/output, pooling, fully connected, etc.), but the fundamental convolutional layers are replaced by our proposed compound dictionary learning and coding layers. The dictionary learning learns an over-complete dictionary for input training data. At the deep coding layer, a locality constraint is added to guarantee that the activated dictionary bases are close to each other. Then the activated dictionary atoms are assembled and passed to the compound dictionary learning and coding layers. In this way, the activated atoms in the first layer can be represented by the deeper atoms in the second dictionary. Intuitively, the second dictionary is designed to learn the fine-grained components shared among the input dictionary atoms, thus a more informative and discriminative low-level representation of the dictionary atoms can be obtained. We empirically compare DDLCN with several leading dictionary learning methods and deep learning models. Experimental results on five popular datasets show that DDLCN achieves competitive results compared with state-of-the-art methods when the training data is limited. Code is available at https://github.com/Ha0Tang/DDLCN.
Explainable Abstract Trains Dataset
Dec 15, 2020
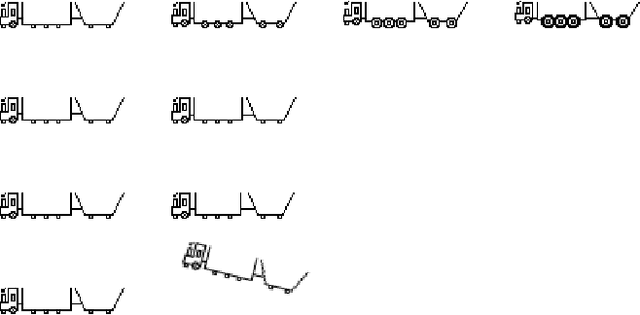

The Explainable Abstract Trains Dataset is an image dataset containing simplified representations of trains. It aims to provide a platform for the application and research of algorithms for justification and explanation extraction. The dataset is accompanied by an ontology that conceptualizes and classifies the depicted trains based on their visual characteristics, allowing for a precise understanding of how each train was labeled. Each image in the dataset is annotated with multiple attributes describing the trains' features and with bounding boxes for the train elements.
A Machine Learning Approach to Optimal Inverse Discrete Cosine Transform (IDCT) Design
Jan 31, 2021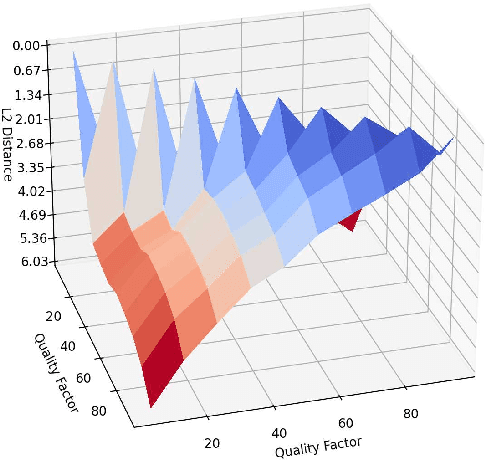
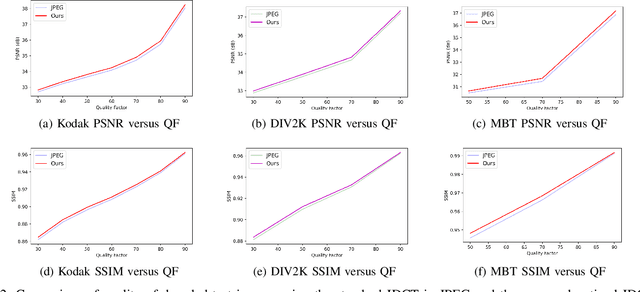


The design of the optimal inverse discrete cosine transform (IDCT) to compensate the quantization error is proposed for effective lossy image compression in this work. The forward and inverse DCTs are designed in pair in current image/video coding standards without taking the quantization effect into account. Yet, the distribution of quantized DCT coefficients deviate from that of original DCT coefficients. This is particularly obvious when the quality factor of JPEG compressed images is small. To address this problem, we first use a set of training images to learn the compound effect of forward DCT, quantization and dequantization in cascade. Then, a new IDCT kernel is learned to reverse the effect of such a pipeline. Experiments are conducted to demonstrate that the advantage of the new method, which has a gain of 0.11-0.30dB over the standard JPEG over a wide range of quality factors.
The emergence of visual semantics through communication games
Jan 25, 2021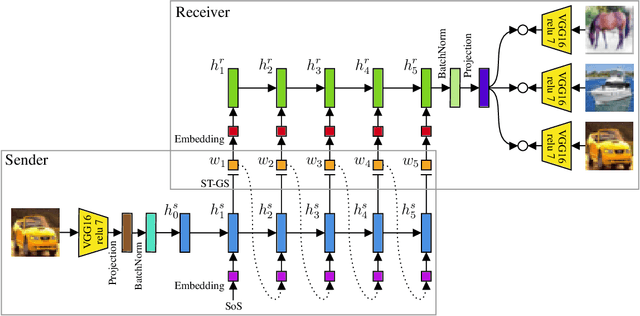

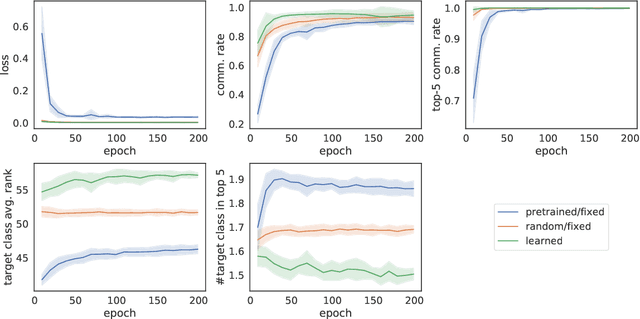
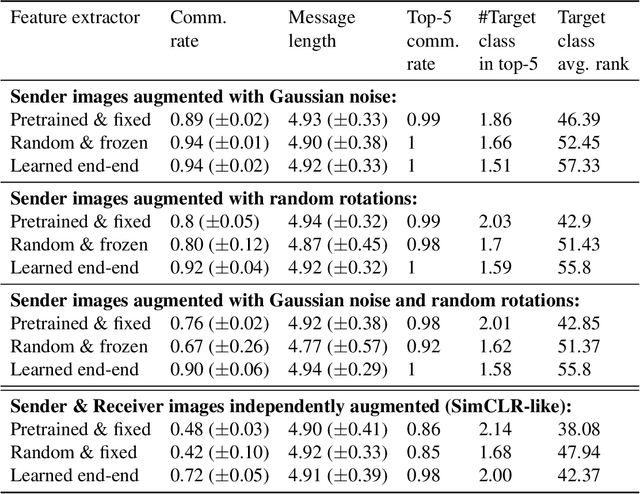
The emergence of communication systems between agents which learn to play referential signalling games with realistic images has attracted a lot of attention recently. The majority of work has focused on using fixed, pretrained image feature extraction networks which potentially bias the information the agents learn to communicate. In this work, we consider a signalling game setting in which a `sender' agent must communicate the information about an image to a `receiver' who must select the correct image from many distractors. We investigate the effect of the feature extractor's weights and of the task being solved on the visual semantics learned by the models. We first demonstrate to what extent the use of pretrained feature extraction networks inductively bias the visual semantics conveyed by emergent communication channel and quantify the visual semantics that are induced. We then go on to explore ways in which inductive biases can be introduced to encourage the emergence of semantically meaningful communication without the need for any form of supervised pretraining of the visual feature extractor. We impose various augmentations to the input images and additional tasks in the game with the aim to induce visual representations which capture conceptual properties of images. Through our experiments, we demonstrate that communication systems which capture visual semantics can be learned in a completely self-supervised manner by playing the right types of game. Our work bridges a gap between emergent communication research and self-supervised feature learning.
Self-supervised Depth Estimation Leveraging Global Perception and Geometric Smoothness Using On-board Videos
Jun 07, 2021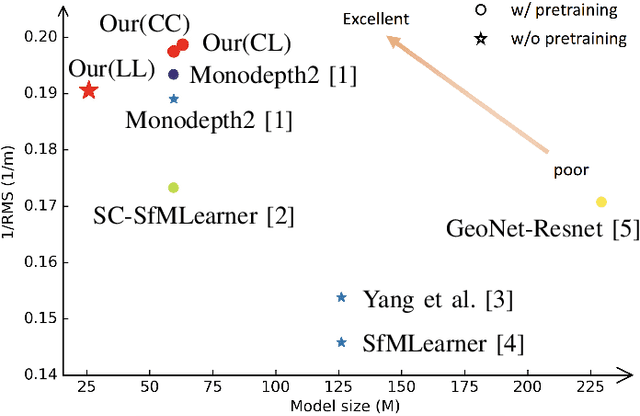
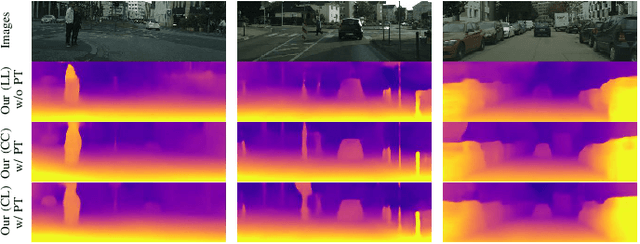
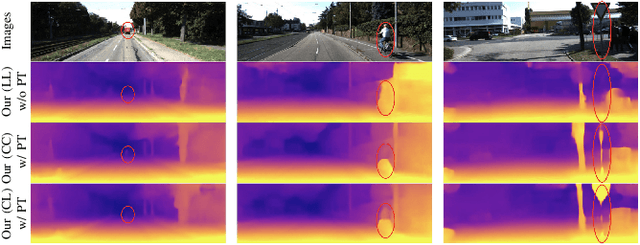
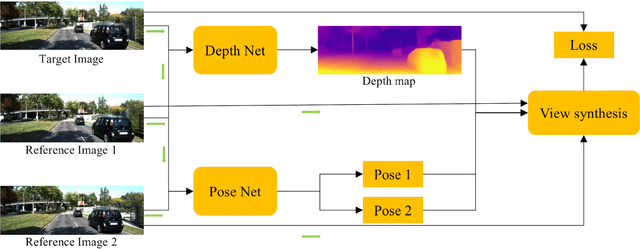
Self-supervised depth estimation has drawn much attention in recent years as it does not require labeled data but image sequences. Moreover, it can be conveniently used in various applications, such as autonomous driving, robotics, realistic navigation, and smart cities. However, extracting global contextual information from images and predicting a geometrically natural depth map remain challenging. In this paper, we present DLNet for pixel-wise depth estimation, which simultaneously extracts global and local features with the aid of our depth Linformer block. This block consists of the Linformer and innovative soft split multi-layer perceptron blocks. Moreover, a three-dimensional geometry smoothness loss is proposed to predict a geometrically natural depth map by imposing the second-order smoothness constraint on the predicted three-dimensional point clouds, thereby realizing improved performance as a byproduct. Finally, we explore the multi-scale prediction strategy and propose the maximum margin dual-scale prediction strategy for further performance improvement. In experiments on the KITTI and Make3D benchmarks, the proposed DLNet achieves performance competitive to those of the state-of-the-art methods, reducing time and space complexities by more than $62\%$ and $56\%$, respectively. Extensive testing on various real-world situations further demonstrates the strong practicality and generalization capability of the proposed model.
Vector Image Generation by Learning Parametric Layer Decomposition
Dec 13, 2018
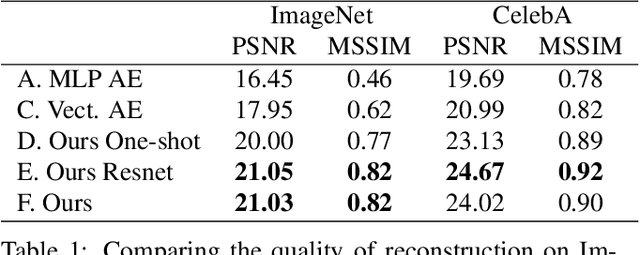
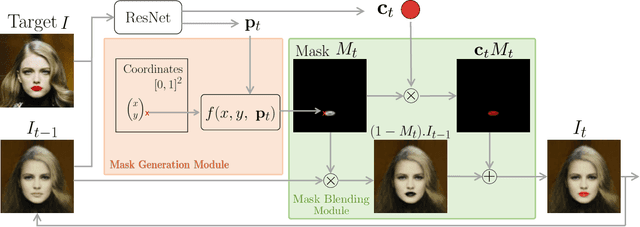
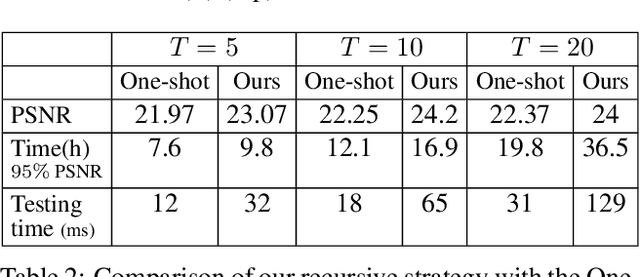
Deep image generation is becoming a tool to enhance artists and designers creativity potential. In this paper, we aim at making the generation process easier to understand and interact with. Inspired by vector graphics systems, we propose a new deep generation paradigm where the images are composed of simple layers, defined by their color and a parametric transparency mask. This presents a number of advantages compared to the commonly used convolutional network architectures. In particular, our layered decomposition allows simple user interaction, for example to update a given mask, or change the color of a selected layer. From a compact code, our architecture also generates images with a virtually infinite resolution, the color at each point in an image being a parametric function of its coordinates. We validate the viability of our approach in the auto-encoding framework by comparing reconstructions with state-of-the-art baselines given similar memory resources on CIFAR10, CelebA and ImageNet datasets and demonstrate several applications. We also show Generative Adversarial Network (GAN) results qualitatively different from the ones obtained with common approaches.
Flow-based Video Segmentation for Human Head and Shoulders
Apr 20, 2021
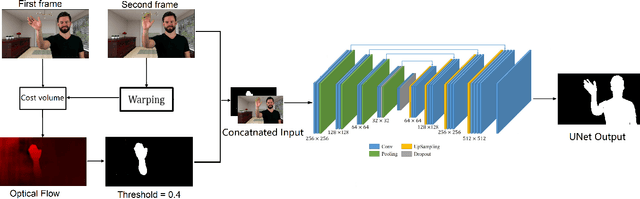
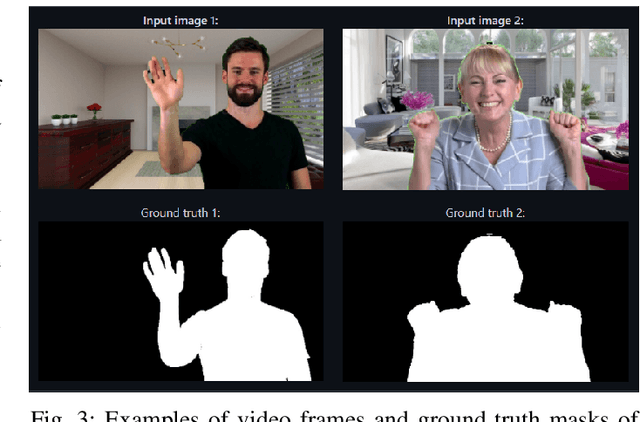

Video segmentation for the human head and shoulders is essential in creating elegant media for videoconferencing and virtual reality applications. The main challenge is to process high-quality background subtraction in a real-time manner and address the segmentation issues under motion blurs, e.g., shaking the head or waving hands during conference video. To overcome the motion blur problem in video segmentation, we propose a novel flow-based encoder-decoder network (FUNet) that combines both traditional Horn-Schunck optical-flow estimation technique and convolutional neural networks to perform robust real-time video segmentation. We also introduce a video and image segmentation dataset: ConferenceVideoSegmentationDataset. Code and pre-trained models are available on our GitHub repository: \url{https://github.com/kuangzijian/Flow-Based-Video-Matting}.
Exploring Adversarial Robustness of Multi-Sensor Perception Systems in Self Driving
Jan 17, 2021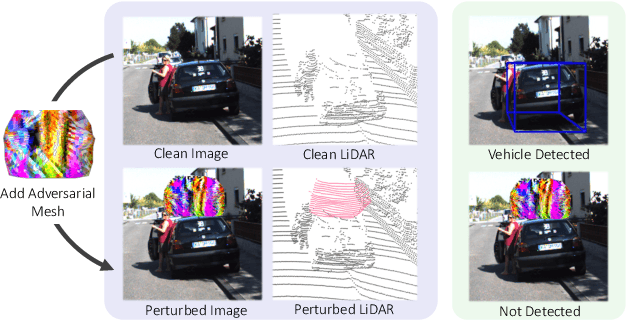
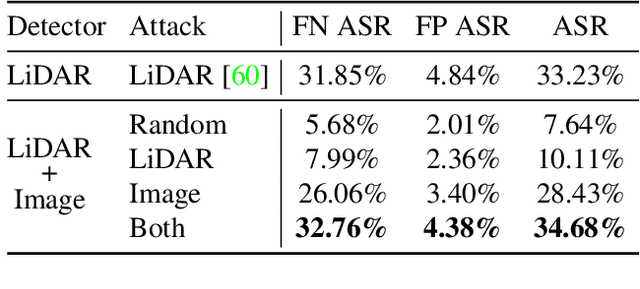
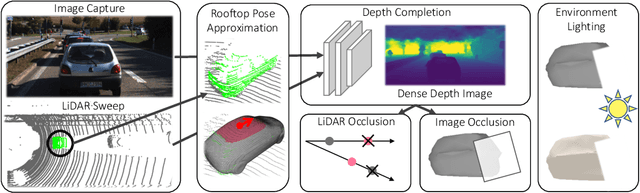
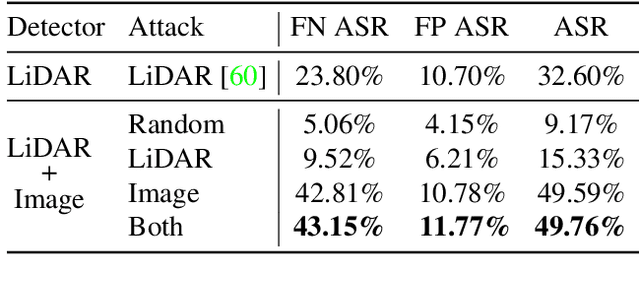
Modern self-driving perception systems have been shown to improve upon processing complementary inputs such as LiDAR with images. In isolation, 2D images have been found to be extremely vulnerable to adversarial attacks. Yet, there have been limited studies on the adversarial robustness of multi-modal models that fuse LiDAR features with image features. Furthermore, existing works do not consider physically realizable perturbations that are consistent across the input modalities. In this paper, we showcase practical susceptibilities of multi-sensor detection by placing an adversarial object on top of a host vehicle. We focus on physically realizable and input-agnostic attacks as they are feasible to execute in practice, and show that a single universal adversary can hide different host vehicles from state-of-the-art multi-modal detectors. Our experiments demonstrate that successful attacks are primarily caused by easily corrupted image features. Furthermore, we find that in modern sensor fusion methods which project image features into 3D, adversarial attacks can exploit the projection process to generate false positives across distant regions in 3D. Towards more robust multi-modal perception systems, we show that adversarial training with feature denoising can boost robustness to such attacks significantly. However, we find that standard adversarial defenses still struggle to prevent false positives which are also caused by inaccurate associations between 3D LiDAR points and 2D pixels.
X-volution: On the unification of convolution and self-attention
Jun 07, 2021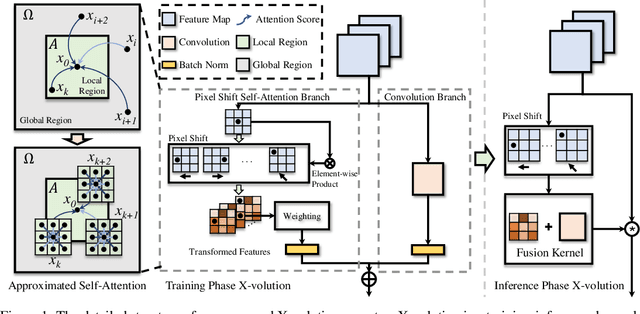
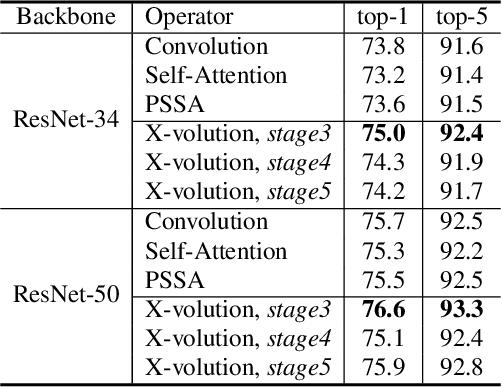
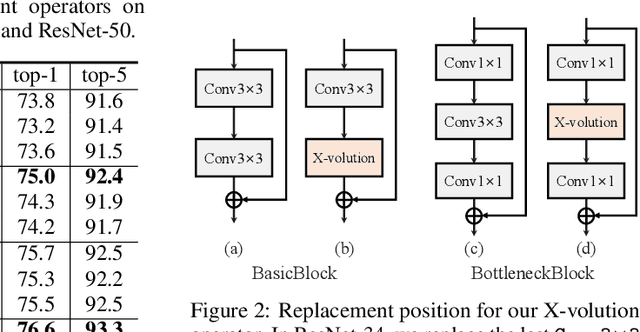
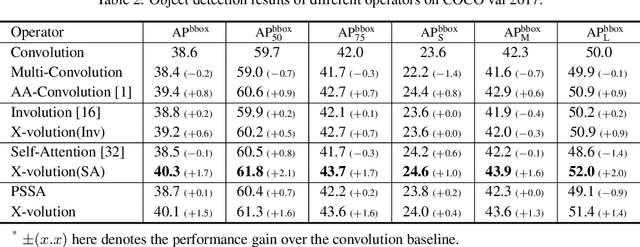
Convolution and self-attention are acting as two fundamental building blocks in deep neural networks, where the former extracts local image features in a linear way while the latter non-locally encodes high-order contextual relationships. Though essentially complementary to each other, i.e., first-/high-order, stat-of-the-art architectures, i.e., CNNs or transformers lack a principled way to simultaneously apply both operations in a single computational module, due to their heterogeneous computing pattern and excessive burden of global dot-product for visual tasks. In this work, we theoretically derive a global self-attention approximation scheme, which approximates a self-attention via the convolution operation on transformed features. Based on the approximated scheme, we establish a multi-branch elementary module composed of both convolution and self-attention operation, capable of unifying both local and non-local feature interaction. Importantly, once trained, this multi-branch module could be conditionally converted into a single standard convolution operation via structural re-parameterization, rendering a pure convolution styled operator named X-volution, ready to be plugged into any modern networks as an atomic operation. Extensive experiments demonstrate that the proposed X-volution, achieves highly competitive visual understanding improvements (+1.2% top-1 accuracy on ImageNet classification, +1.7 box AP and +1.5 mask AP on COCO detection and segmentation).