 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Space-time Mixing Attention for Video Transformer
Jun 11, 2021
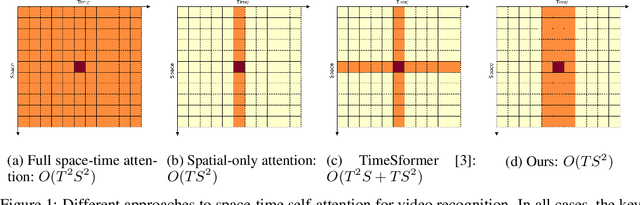
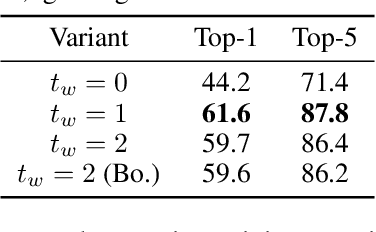
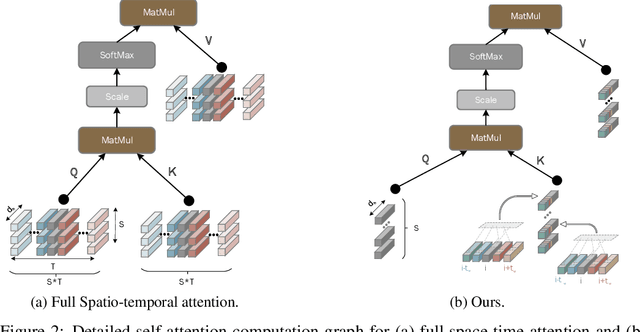
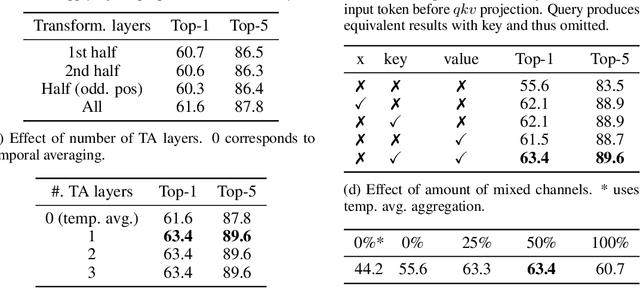
This paper is on video recognition using Transformers. Very recent attempts in this area have demonstrated promising results in terms of recognition accuracy, yet they have been also shown to induce, in many cases, significant computational overheads due to the additional modelling of the temporal information. In this work, we propose a Video Transformer model the complexity of which scales linearly with the number of frames in the video sequence and hence induces no overhead compared to an image-based Transformer model. To achieve this, our model makes two approximations to the full space-time attention used in Video Transformers: (a) It restricts time attention to a local temporal window and capitalizes on the Transformer's depth to obtain full temporal coverage of the video sequence. (b) It uses efficient space-time mixing to attend jointly spatial and temporal locations without inducing any additional cost on top of a spatial-only attention model. We also show how to integrate 2 very lightweight mechanisms for global temporal-only attention which provide additional accuracy improvements at minimal computational cost. We demonstrate that our model produces very high recognition accuracy on the most popular video recognition datasets while at the same time being significantly more efficient than other Video Transformer models. Code will be made available.
Saliency Driven Image Manipulation
Jan 17, 2018
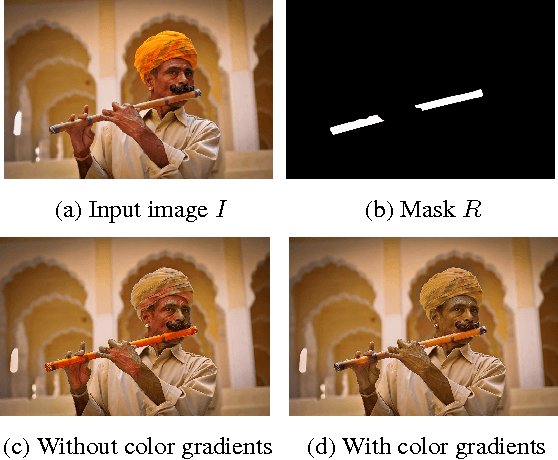
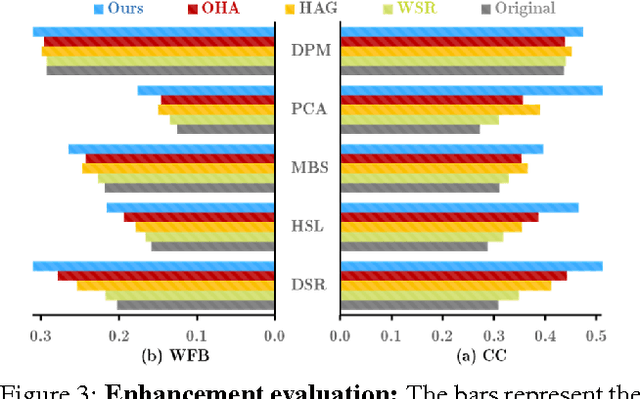
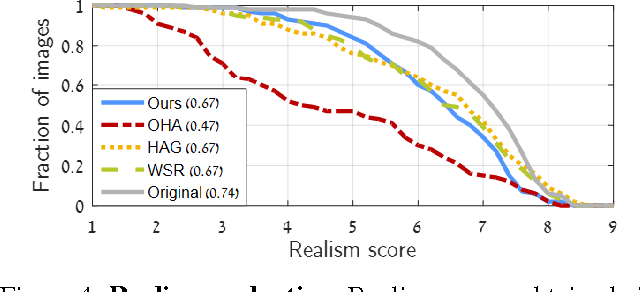
Have you ever taken a picture only to find out that an unimportant background object ended up being overly salient? Or one of those team sports photos where your favorite player blends with the rest? Wouldn't it be nice if you could tweak these pictures just a little bit so that the distractor would be attenuated and your favorite player will stand-out among her peers? Manipulating images in order to control the saliency of objects is the goal of this paper. We propose an approach that considers the internal color and saliency properties of the image. It changes the saliency map via an optimization framework that relies on patch-based manipulation using only patches from within the same image to achieve realistic looking results. Applications include object enhancement, distractors attenuation and background decluttering. Comparing our method to previous ones shows significant improvement, both in the achieved saliency manipulation and in the realistic appearance of the resulting images.
Residual Error: a New Performance Measure for Adversarial Robustness
Jun 18, 2021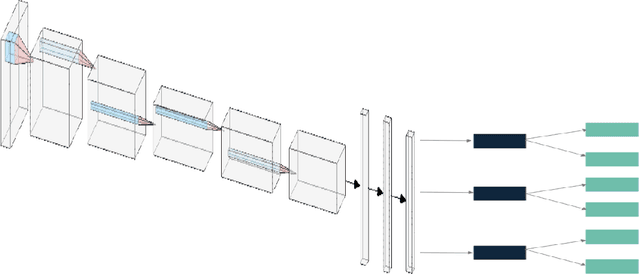
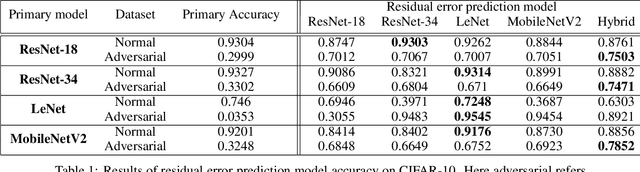
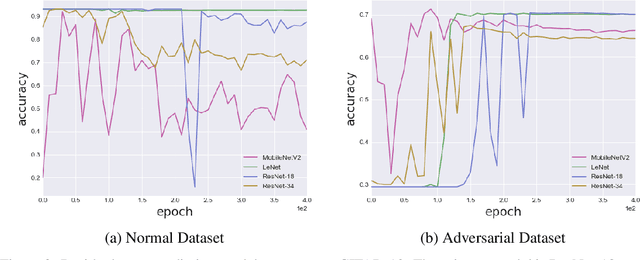
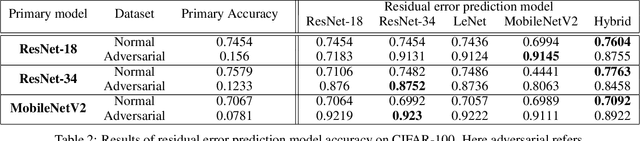
Despite the significant advances in deep learning over the past decade, a major challenge that limits the wide-spread adoption of deep learning has been their fragility to adversarial attacks. This sensitivity to making erroneous predictions in the presence of adversarially perturbed data makes deep neural networks difficult to adopt for certain real-world, mission-critical applications. While much of the research focus has revolved around adversarial example creation and adversarial hardening, the area of performance measures for assessing adversarial robustness is not well explored. Motivated by this, this study presents the concept of residual error, a new performance measure for not only assessing the adversarial robustness of a deep neural network at the individual sample level, but also can be used to differentiate between adversarial and non-adversarial examples to facilitate for adversarial example detection. Furthermore, we introduce a hybrid model for approximating the residual error in a tractable manner. Experimental results using the case of image classification demonstrates the effectiveness and efficacy of the proposed residual error metric for assessing several well-known deep neural network architectures. These results thus illustrate that the proposed measure could be a useful tool for not only assessing the robustness of deep neural networks used in mission-critical scenarios, but also in the design of adversarially robust models.
Adaptive Appearance Rendering
Apr 24, 2021
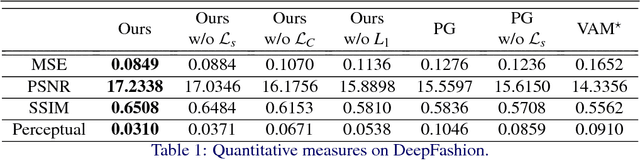
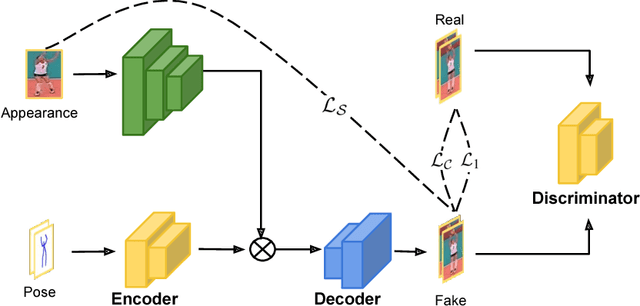
We propose an approach to generate images of people given a desired appearance and pose. Disentangled representations of pose and appearance are necessary to handle the compound variability in the resulting generated images. Hence, we develop an approach based on intermediate representations of poses and appearance: our pose-guided appearance rendering network firstly encodes the targets' poses using an encoder-decoder neural network. Then the targets' appearances are encoded by learning adaptive appearance filters using a fully convolutional network. Finally, these filters are placed in the encoder-decoder neural networks to complete the rendering. We demonstrate that our model can generate images and videos that are superior to state-of-the-art methods, and can handle pose guided appearance rendering in both image and video generation.
The Contextual Loss for Image Transformation with Non-Aligned Data
Jul 18, 2018

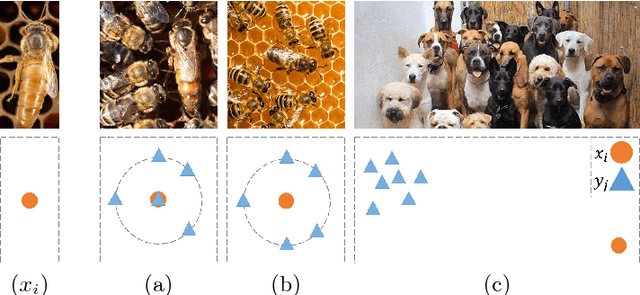
Feed-forward CNNs trained for image transformation problems rely on loss functions that measure the similarity between the generated image and a target image. Most of the common loss functions assume that these images are spatially aligned and compare pixels at corresponding locations. However, for many tasks, aligned training pairs of images will not be available. We present an alternative loss function that does not require alignment, thus providing an effective and simple solution for a new space of problems. Our loss is based on both context and semantics -- it compares regions with similar semantic meaning, while considering the context of the entire image. Hence, for example, when transferring the style of one face to another, it will translate eyes-to-eyes and mouth-to-mouth. Our code can be found at https://www.github.com/roimehrez/contextualLoss
Triple-cooperative Video Shadow Detection
Mar 11, 2021

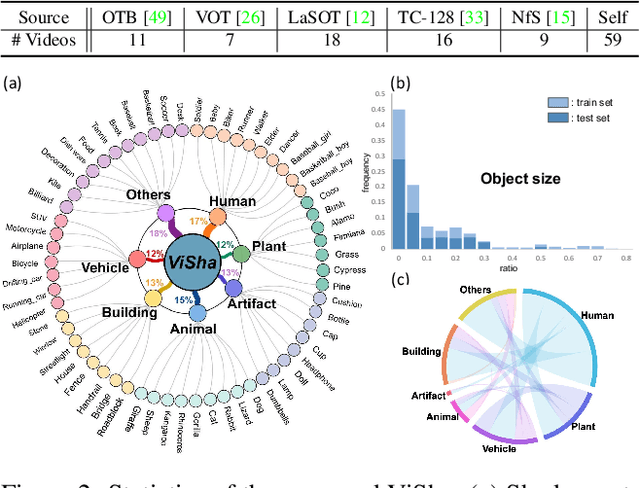
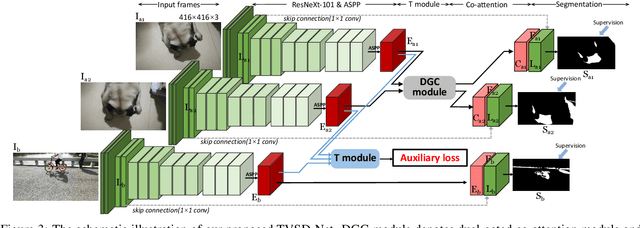
Shadow detection in a single image has received significant research interest in recent years. However, much fewer works have been explored in shadow detection over dynamic scenes. The bottleneck is the lack of a well-established dataset with high-quality annotations for video shadow detection. In this work, we collect a new video shadow detection dataset, which contains 120 videos with 11, 685 frames, covering 60 object categories, varying lengths, and different motion/lighting conditions. All the frames are annotated with a high-quality pixel-level shadow mask. To the best of our knowledge, this is the first learning-oriented dataset for video shadow detection. Furthermore, we develop a new baseline model, named triple-cooperative video shadow detection network (TVSD-Net). It utilizes triple parallel networks in a cooperative manner to learn discriminative representations at intra-video and inter-video levels. Within the network, a dual gated co-attention module is proposed to constrain features from neighboring frames in the same video, while an auxiliary similarity loss is introduced to mine semantic information between different videos. Finally, we conduct a comprehensive study on ViSha, evaluating 12 state-of-the-art models (including single image shadow detectors, video object segmentation, and saliency detection methods). Experiments demonstrate that our model outperforms SOTA competitors.
Self-Supervised VQ-VAE For One-Shot Music Style Transfer
Feb 10, 2021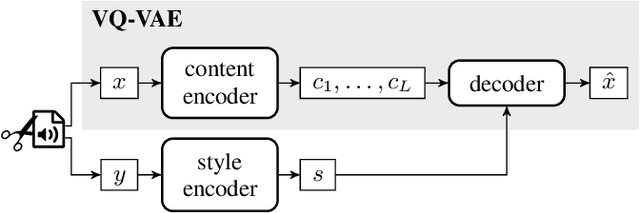
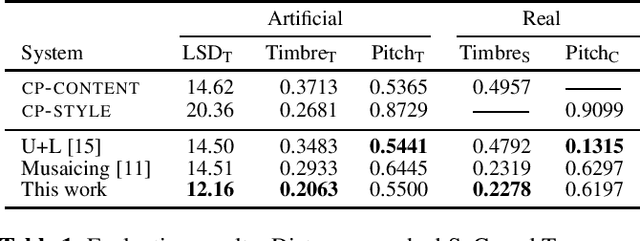
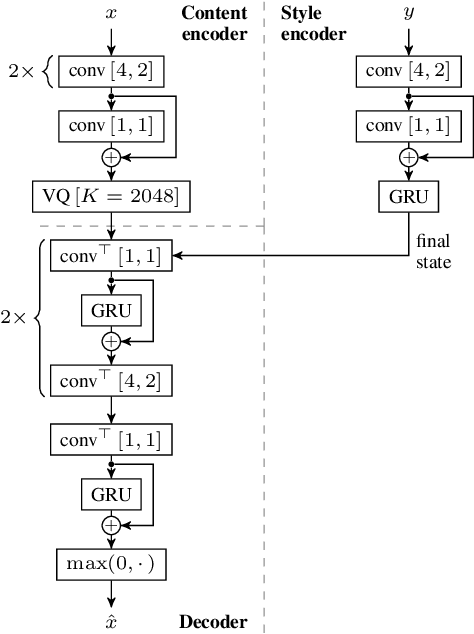
Neural style transfer, allowing to apply the artistic style of one image to another, has become one of the most widely showcased computer vision applications shortly after its introduction. In contrast, related tasks in the music audio domain remained, until recently, largely untackled. While several style conversion methods tailored to musical signals have been proposed, most lack the 'one-shot' capability of classical image style transfer algorithms. On the other hand, the results of existing one-shot audio style transfer methods on musical inputs are not as compelling. In this work, we are specifically interested in the problem of one-shot timbre transfer. We present a novel method for this task, based on an extension of the vector-quantized variational autoencoder (VQ-VAE), along with a simple self-supervised learning strategy designed to obtain disentangled representations of timbre and pitch. We evaluate the method using a set of objective metrics and show that it is able to outperform selected baselines.
Time-Dependent Deep Image Prior for Dynamic MRI
Oct 03, 2019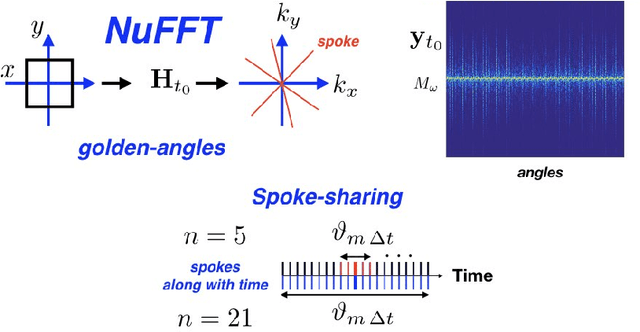


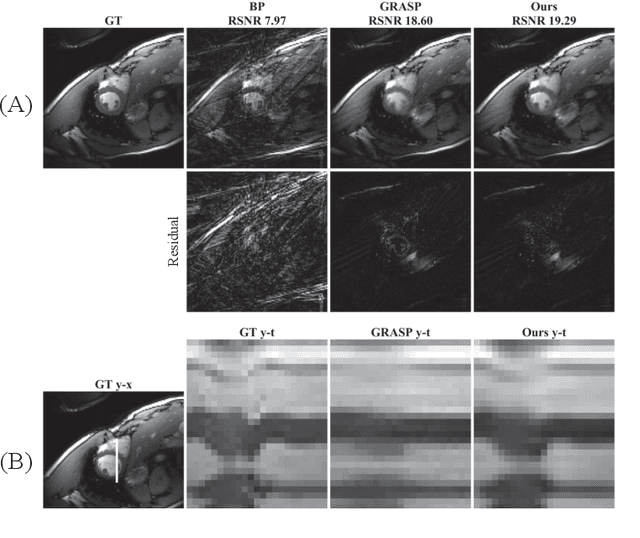
We propose a novel unsupervised deep-learning-based algorithm to solve the inverse problem found in dynamic magnetic resonance imaging (MRI). Our method needs neither prior training nor additional data; in particular, it does not require either electrocardiogram or spokes-reordering in the context of cardiac images. It generalizes to sequences of images the recently introduced deep-image-prior approach. The essence of the proposed algorithm is to proceed in two steps to fit k-space synthetic measurements to sparsely acquired dynamic MRI data. In the first step, we deploy a convolutional neural network (CNN) driven by a sequence of low-dimensional latent variables to generate a dynamic series of MRI images. In the second step, we submit the generated images to a nonuniform fast Fourier transform that represents the forward model of the MRI system. By manipulating the weights of the CNN, we fit our synthetic measurements to the acquired MRI data. The corresponding images from the CNN then provide the output of our system; their evolution through time is driven by controlling the sequence of latent variables whose interpolation gives access to the sub-frame---or even continuous---temporal control of reconstructed dynamic images. We perform experiments on simulated and real cardiac images of a fetus acquired through 5-spoke-based golden-angle measurements. Our results show improvement over the current state-of-the-art.
Animating Pictures with Eulerian Motion Fields
Nov 30, 2020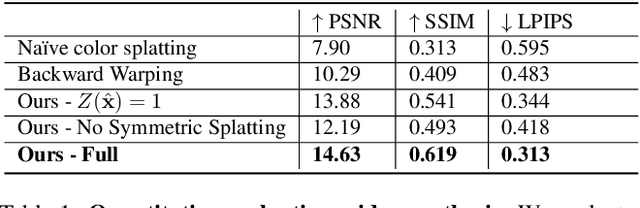
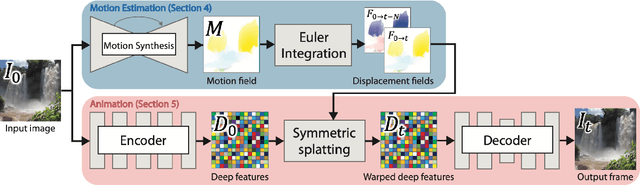
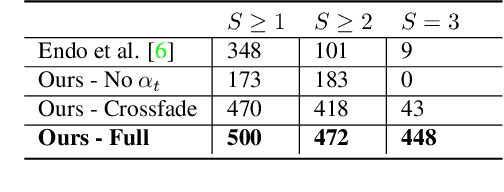

In this paper, we demonstrate a fully automatic method for converting a still image into a realistic animated looping video. We target scenes with continuous fluid motion, such as flowing water and billowing smoke. Our method relies on the observation that this type of natural motion can be convincingly reproduced from a static Eulerian motion description, i.e. a single, temporally constant flow field that defines the immediate motion of a particle at a given 2D location. We use an image-to-image translation network to encode motion priors of natural scenes collected from online videos, so that for a new photo, we can synthesize a corresponding motion field. The image is then animated using the generated motion through a deep warping technique: pixels are encoded as deep features, those features are warped via Eulerian motion, and the resulting warped feature maps are decoded as images. In order to produce continuous, seamlessly looping video textures, we propose a novel video looping technique that flows features both forward and backward in time and then blends the results. We demonstrate the effectiveness and robustness of our method by applying it to a large collection of examples including beaches, waterfalls, and flowing rivers.
Few-Shot Video Object Detection
Apr 30, 2021
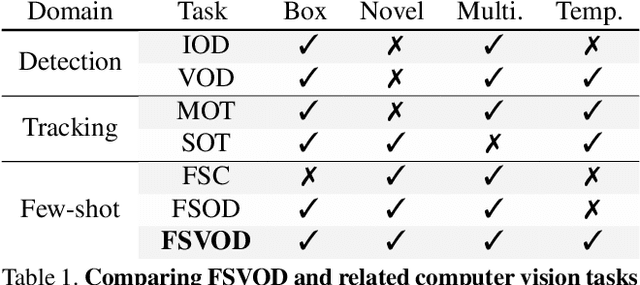
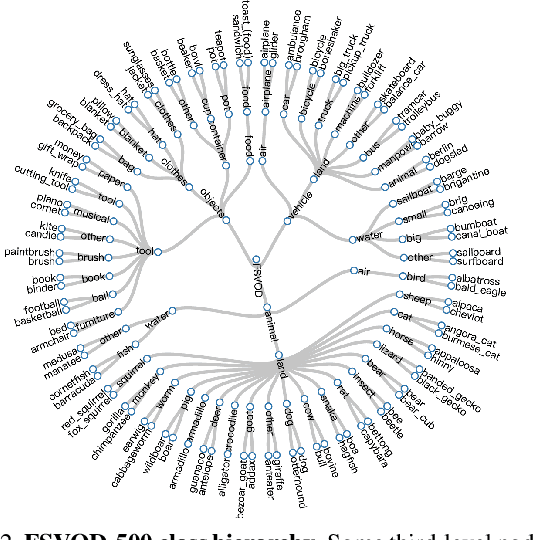
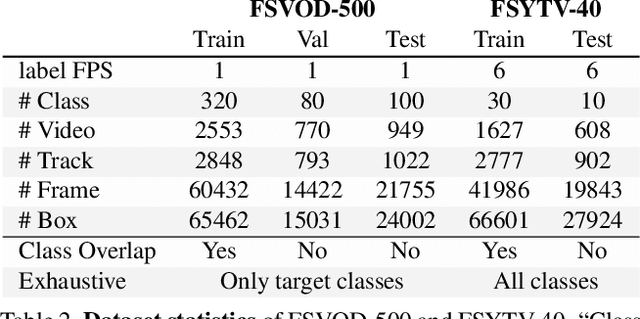
We introduce Few-Shot Video Object Detection (FSVOD) with three important contributions: 1) a large-scale video dataset FSVOD-500 comprising of 500 classes with class-balanced videos in each category for few-shot learning; 2) a novel Tube Proposal Network (TPN) to generate high-quality video tube proposals to aggregate feature representation for the target video object; 3) a strategically improved Temporal Matching Network (TMN+) to match representative query tube features and supports with better discriminative ability. Our TPN and TMN+ are jointly and end-to-end trained. Extensive experiments demonstrate that our method produces significantly better detection results on two few-shot video object detection datasets compared to image-based methods and other naive video-based extensions. Codes and datasets will be released at https://github.com/fanq15/FewX.