 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoverage-Driven KV Cache Eviction for Efficient and Improved Inference of LLM
Jun 28, 2026Large language models (LLMs) excel at complex tasks like question answering and summarization, thanks to their ability to handle long-context inputs. However, deploying LLMs is costly, not only due to the high computational demands of quadratic complexity of self-attention and auto-regressive generation, but also because of the significant memory overhead required for storing the key-value (KV) cache during inference. To reduce the memory cost, existing KV-cache eviction strategies leverage the sparsity in attention to selectively store a subset of tokens. While reducing the memory footprint, such approaches show a considerable drop in performance, especially in tasks that require long-context reasoning. We identify that the drop in performance is linked to a reduction in the coverage of unique tokens. Additionally, we theoretically show that reduced coverage limits the mutual information between inputs and outputs, thereby impairing predictive accuracy. To this end, we introduce K-VEC, a novel coverage-aware KV-cache eviction strategy that prioritizes token coverage while evicting tokens in the cache. K-VEC introduces a cross-head and a cross-layer coverage module to enhance token retention across attention heads and model layers, mitigating performance degradation caused by low coverage. Evaluated on 16 LongBench subsets, K-VEC exhibit up to 10.35 points improvement over the existing methods under the same eviction rate and memory constraint. Comprehensive evaluations validate the effectiveness of our approach and demonstrate its potential for efficient LLM deployment in resource-constrained settings.
You Need Reasoning to Learn Reasoning: The Limitations of Label-Free RL in Weak Base Models
Nov 07, 2025



Recent advances in large language models have demonstrated the promise of unsupervised reinforcement learning (RL) methods for enhancing reasoning capabilities without external supervision. However, the generalizability of these label-free RL approaches to smaller base models with limited reasoning capabilities remains unexplored. In this work, we systematically investigate the performance of label-free RL methods across different model sizes and reasoning strengths, from 0.5B to 7B parameters. Our empirical analysis reveals critical limitations: label-free RL is highly dependent on the base model's pre-existing reasoning capability, with performance often degrading below baseline levels for weaker models. We find that smaller models fail to generate sufficiently long or diverse chain-of-thought reasoning to enable effective self-reflection, and that training data difficulty plays a crucial role in determining success. To address these challenges, we propose a simple yet effective method for label-free RL that utilizes curriculum learning to progressively introduce harder problems during training and mask no-majority rollouts during training. Additionally, we introduce a data curation pipeline to generate samples with predefined difficulty. Our approach demonstrates consistent improvements across all model sizes and reasoning capabilities, providing a path toward more robust unsupervised RL that can bootstrap reasoning abilities in resource-constrained models. We make our code available at https://github.com/BorealisAI/CuMa
Radar: Fast Long-Context Decoding for Any Transformer
Mar 13, 2025Transformer models have demonstrated exceptional performance across a wide range of applications. Though forming the foundation of Transformer models, the dot-product attention does not scale well to long-context data since its time requirement grows quadratically with context length. In this work, we propose Radar, a training-free approach that accelerates inference by dynamically searching for the most important context tokens. For any pre-trained Transformer, Radar can reduce the decoding time complexity without training or heuristically evicting tokens. Moreover, we provide theoretical justification for our approach, demonstrating that Radar can reliably identify the most important tokens with high probability. We conduct extensive comparisons with the previous methods on a wide range of tasks. The results demonstrate that Radar achieves the state-of-the-art performance across different architectures with reduced time complexity, offering a practical solution for efficient long-context processing of Transformers.
Prompting-based Efficient Temporal Domain Generalization
Oct 03, 2023



Machine learning traditionally assumes that training and testing data are distributed independently and identically. However, in many real-world settings, the data distribution can shift over time, leading to poor generalization of trained models in future time periods. Our paper presents a novel prompting-based approach to temporal domain generalization that is parameter-efficient, time-efficient, and does not require access to the target domain data (i.e., unseen future time periods) during training. Our method adapts a target pre-trained model to temporal drift by learning global prompts, domain-specific prompts, and drift-aware prompts that capture underlying temporal dynamics. It is compatible across diverse tasks, such as classification, regression, and time series forecasting, and sets a new state-of-the-art benchmark in temporal domain generalization. The code repository will be publicly shared.
Ranking Regularization for Critical Rare Classes: Minimizing False Positives at a High True Positive Rate
Mar 31, 2023



In many real-world settings, the critical class is rare and a missed detection carries a disproportionately high cost. For example, tumors are rare and a false negative diagnosis could have severe consequences on treatment outcomes; fraudulent banking transactions are rare and an undetected occurrence could result in significant losses or legal penalties. In such contexts, systems are often operated at a high true positive rate, which may require tolerating high false positives. In this paper, we present a novel approach to address the challenge of minimizing false positives for systems that need to operate at a high true positive rate. We propose a ranking-based regularization (RankReg) approach that is easy to implement, and show empirically that it not only effectively reduces false positives, but also complements conventional imbalanced learning losses. With this novel technique in hand, we conduct a series of experiments on three broadly explored datasets (CIFAR-10&100 and Melanoma) and show that our approach lifts the previous state-of-the-art performance by notable margins.
Piggyback GAN: Efficient Lifelong Learning for Image Conditioned Generation
Apr 24, 2021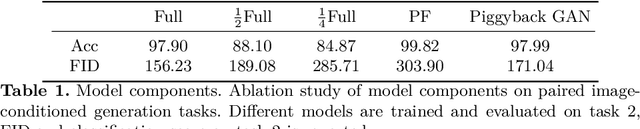
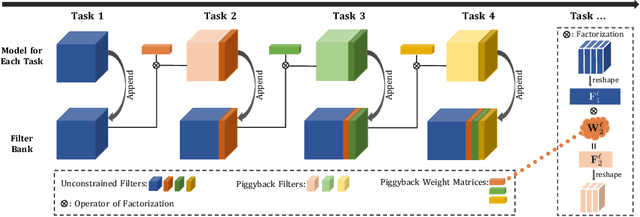
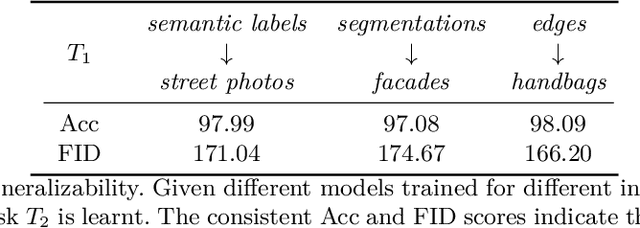
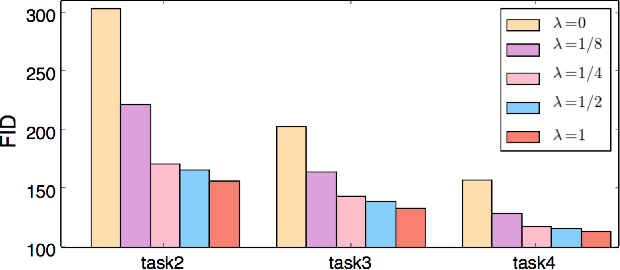
Humans accumulate knowledge in a lifelong fashion. Modern deep neural networks, on the other hand, are susceptible to catastrophic forgetting: when adapted to perform new tasks, they often fail to preserve their performance on previously learned tasks. Given a sequence of tasks, a naive approach addressing catastrophic forgetting is to train a separate standalone model for each task, which scales the total number of parameters drastically without efficiently utilizing previous models. In contrast, we propose a parameter efficient framework, Piggyback GAN, which learns the current task by building a set of convolutional and deconvolutional filters that are factorized into filters of the models trained on previous tasks. For the current task, our model achieves high generation quality on par with a standalone model at a lower number of parameters. For previous tasks, our model can also preserve generation quality since the filters for previous tasks are not altered. We validate Piggyback GAN on various image-conditioned generation tasks across different domains, and provide qualitative and quantitative results to show that the proposed approach can address catastrophic forgetting effectively and efficiently.
Adaptive Appearance Rendering
Apr 24, 2021
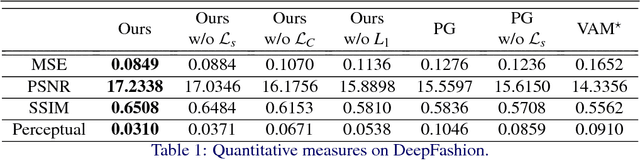
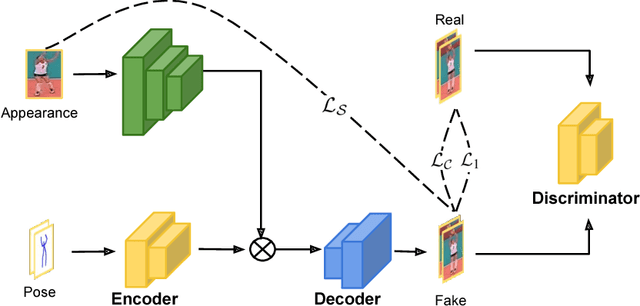
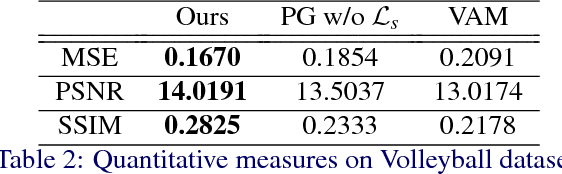
We propose an approach to generate images of people given a desired appearance and pose. Disentangled representations of pose and appearance are necessary to handle the compound variability in the resulting generated images. Hence, we develop an approach based on intermediate representations of poses and appearance: our pose-guided appearance rendering network firstly encodes the targets' poses using an encoder-decoder neural network. Then the targets' appearances are encoded by learning adaptive appearance filters using a fully convolutional network. Finally, these filters are placed in the encoder-decoder neural networks to complete the rendering. We demonstrate that our model can generate images and videos that are superior to state-of-the-art methods, and can handle pose guided appearance rendering in both image and video generation.
Zero-Shot Generation of Human-Object Interaction Videos
Dec 09, 2019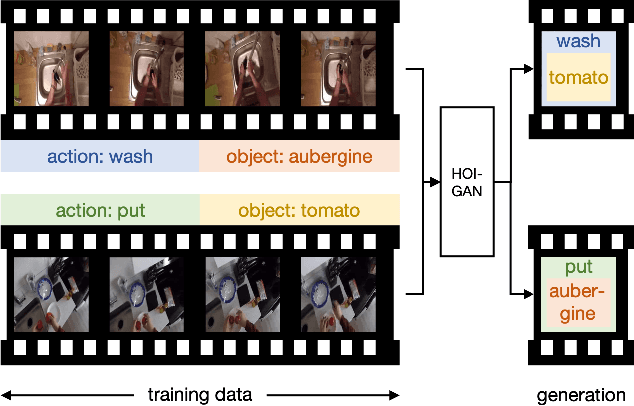
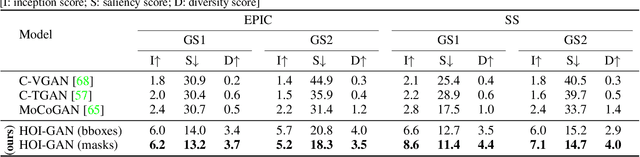
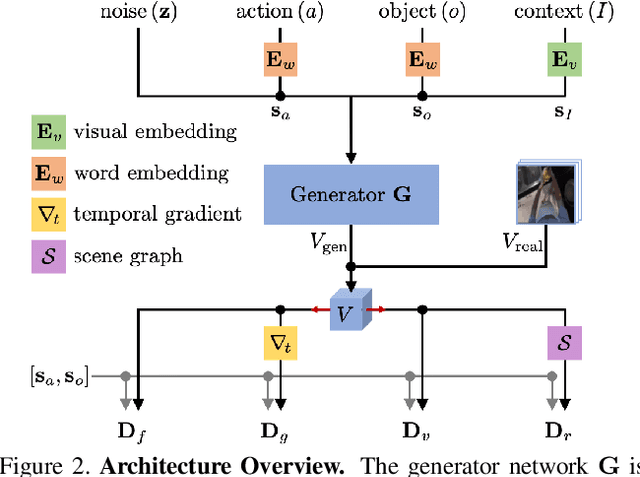
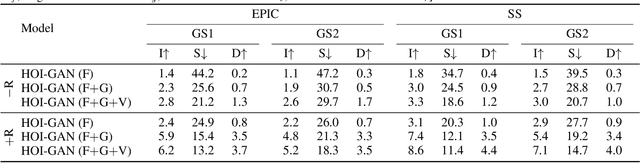
Generation of videos of complex scenes is an important open problem in computer vision research. Human activity videos are a good example of such complex scenes. Human activities are typically formed as compositions of actions applied to objects -- modeling interactions between people and the physical world are a core part of visual understanding. In this paper, we introduce the task of generating human-object interaction videos in a zero-shot compositional setting, i.e., generating videos for action-object compositions that are unseen during training, having seen the target action and target object independently. To generate human-object interaction videos, we propose a novel adversarial framework HOI-GAN which includes multiple discriminators focusing on different aspects of a video. To demonstrate the effectiveness of our proposed framework, we perform extensive quantitative and qualitative evaluation on two challenging datasets: EPIC-Kitchens and 20BN-Something-Something v2.
Lifelong GAN: Continual Learning for Conditional Image Generation
Aug 22, 2019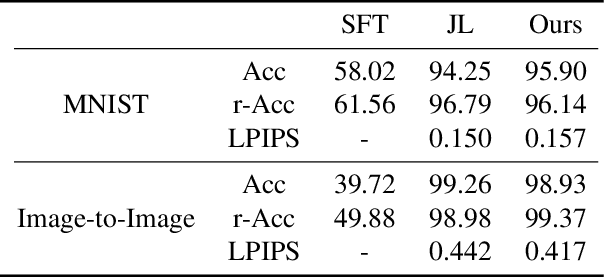
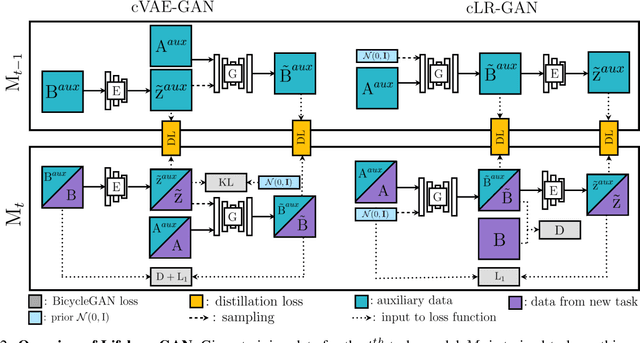
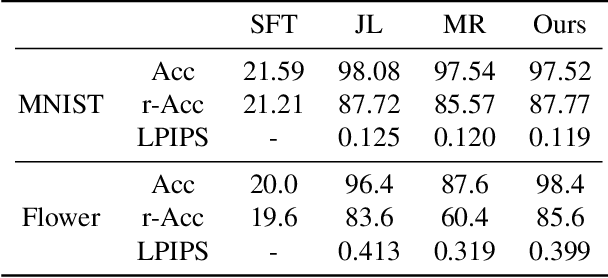

Lifelong learning is challenging for deep neural networks due to their susceptibility to catastrophic forgetting. Catastrophic forgetting occurs when a trained network is not able to maintain its ability to accomplish previously learned tasks when it is trained to perform new tasks. We study the problem of lifelong learning for generative models, extending a trained network to new conditional generation tasks without forgetting previous tasks, while assuming access to the training data for the current task only. In contrast to state-of-the-art memory replay based approaches which are limited to label-conditioned image generation tasks, a more generic framework for continual learning of generative models under different conditional image generation settings is proposed in this paper. Lifelong GAN employs knowledge distillation to transfer learned knowledge from previous networks to the new network. This makes it possible to perform image-conditioned generation tasks in a lifelong learning setting. We validate Lifelong GAN for both image-conditioned and label-conditioned generation tasks, and provide qualitative and quantitative results to show the generality and effectiveness of our method.
Learning to Forecast Videos of Human Activity with Multi-granularity Models and Adaptive Rendering
Dec 05, 2017
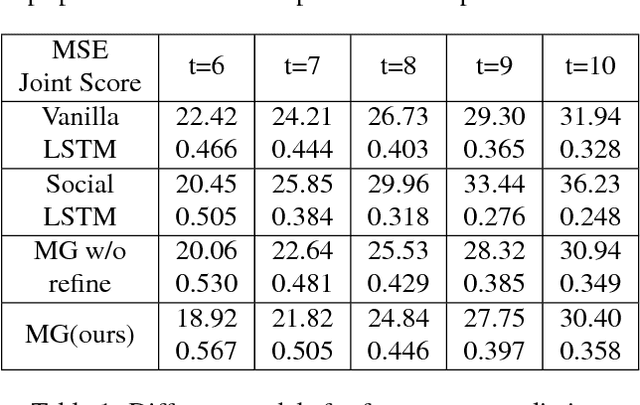
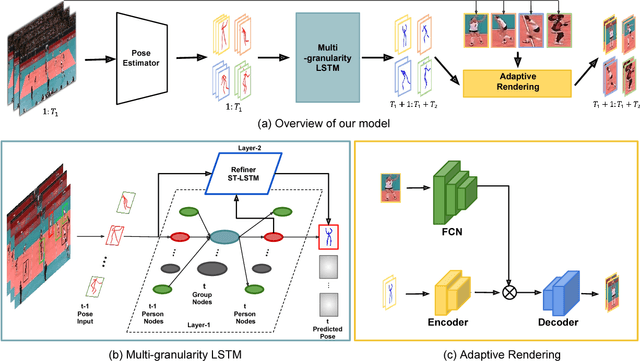
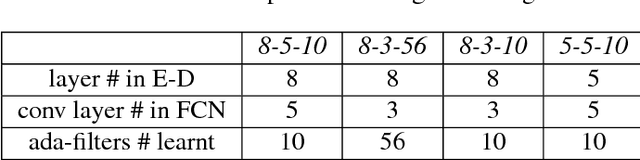
We propose an approach for forecasting video of complex human activity involving multiple people. Direct pixel-level prediction is too simple to handle the appearance variability in complex activities. Hence, we develop novel intermediate representations. An architecture combining a hierarchical temporal model for predicting human poses and encoder-decoder convolutional neural networks for rendering target appearances is proposed. Our hierarchical model captures interactions among people by adopting a dynamic group-based interaction mechanism. Next, our appearance rendering network encodes the targets' appearances by learning adaptive appearance filters using a fully convolutional network. Finally, these filters are placed in encoder-decoder neural networks to complete the rendering. We demonstrate that our model can generate videos that are superior to state-of-the-art methods, and can handle complex human activity scenarios in video forecasting.