 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Music Source Separation for Automatic Lyrics Transcription with Whisper
Jun 18, 2025Automatic lyrics transcription (ALT) remains a challenging task in the field of music information retrieval, despite great advances in automatic speech recognition (ASR) brought about by transformer-based architectures in recent years. One of the major challenges in ALT is the high amplitude of interfering audio signals relative to conventional ASR due to musical accompaniment. Recent advances in music source separation have enabled automatic extraction of high-quality separated vocals, which could potentially improve ALT performance. However, the effect of source separation has not been systematically investigated in order to establish best practices for its use. This work examines the impact of source separation on ALT using Whisper, a state-of-the-art open source ASR model. We evaluate Whisper's performance on original audio, separated vocals, and vocal stems across short-form and long-form transcription tasks. For short-form, we suggest a concatenation method that results in a consistent reduction in Word Error Rate (WER). For long-form, we propose an algorithm using source separation as a vocal activity detector to derive segment boundaries, which results in a consistent reduction in WER relative to Whisper's native long-form algorithm. Our approach achieves state-of-the-art results for an open source system on the Jam-ALT long-form ALT benchmark, without any training or fine-tuning. We also publish MUSDB-ALT, the first dataset of long-form lyric transcripts following the Jam-ALT guidelines for which vocal stems are publicly available.
Jam-ALT: A Formatting-Aware Lyrics Transcription Benchmark
Nov 23, 2023



Current automatic lyrics transcription (ALT) benchmarks focus exclusively on word content and ignore the finer nuances of written lyrics including formatting and punctuation, which leads to a potential misalignment with the creative products of musicians and songwriters as well as listeners' experiences. For example, line breaks are important in conveying information about rhythm, emotional emphasis, rhyme, and high-level structure. To address this issue, we introduce Jam-ALT, a new lyrics transcription benchmark based on the JamendoLyrics dataset. Our contribution is twofold. Firstly, a complete revision of the transcripts, geared specifically towards ALT evaluation by following a newly created annotation guide that unifies the music industry's guidelines, covering aspects such as punctuation, line breaks, spelling, background vocals, and non-word sounds. Secondly, a suite of evaluation metrics designed, unlike the traditional word error rate, to capture such phenomena. We hope that the proposed benchmark contributes to the ALT task, enabling more precise and reliable assessments of transcription systems and enhancing the user experience in lyrics applications such as subtitle renderings for live captioning or karaoke.
Black-box language model explanation by context length probing
Dec 30, 2022



The increasingly widespread adoption of large language models has highlighted the need for improving their explainability. We present context length probing, a novel explanation technique for causal language models, based on tracking the predictions of a model as a function of the length of available context, and allowing to assign differential importance scores to different contexts. The technique is model-agnostic and does not rely on access to model internals beyond computing token-level probabilities. We apply context length probing to large pre-trained language models and offer some initial analyses and insights, including the potential for studying long-range dependencies. The source code and a demo of the method are available.
Relative Positional Encoding for Transformers with Linear Complexity
Jun 10, 2021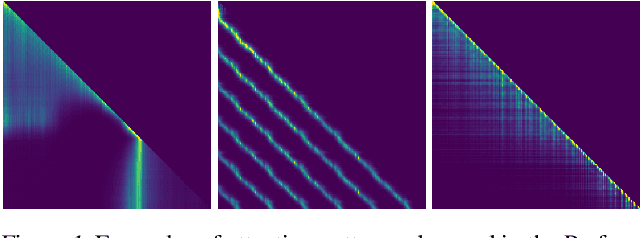
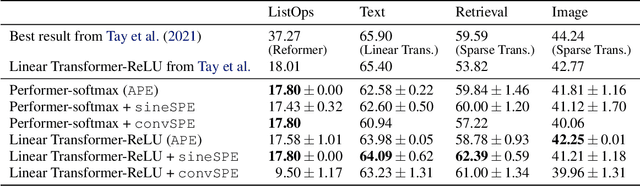

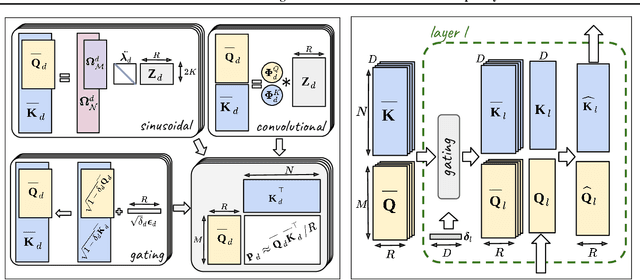
Recent advances in Transformer models allow for unprecedented sequence lengths, due to linear space and time complexity. In the meantime, relative positional encoding (RPE) was proposed as beneficial for classical Transformers and consists in exploiting lags instead of absolute positions for inference. Still, RPE is not available for the recent linear-variants of the Transformer, because it requires the explicit computation of the attention matrix, which is precisely what is avoided by such methods. In this paper, we bridge this gap and present Stochastic Positional Encoding as a way to generate PE that can be used as a replacement to the classical additive (sinusoidal) PE and provably behaves like RPE. The main theoretical contribution is to make a connection between positional encoding and cross-covariance structures of correlated Gaussian processes. We illustrate the performance of our approach on the Long-Range Arena benchmark and on music generation.
Self-Supervised VQ-VAE For One-Shot Music Style Transfer
Feb 10, 2021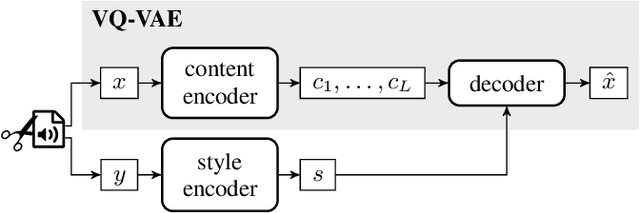
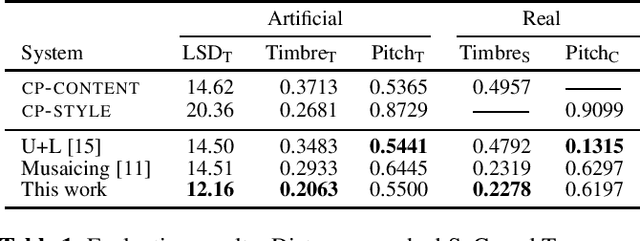
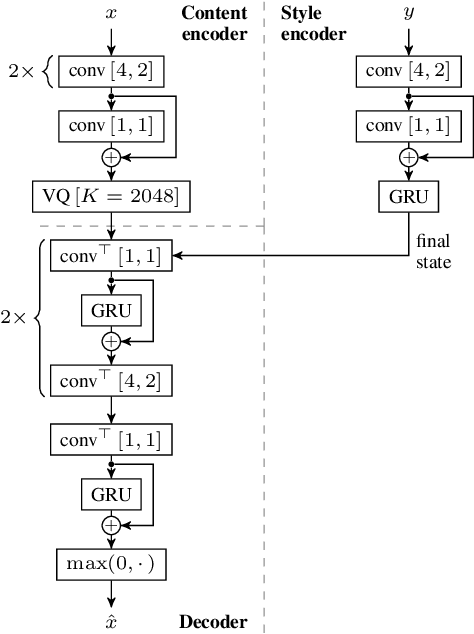
Neural style transfer, allowing to apply the artistic style of one image to another, has become one of the most widely showcased computer vision applications shortly after its introduction. In contrast, related tasks in the music audio domain remained, until recently, largely untackled. While several style conversion methods tailored to musical signals have been proposed, most lack the 'one-shot' capability of classical image style transfer algorithms. On the other hand, the results of existing one-shot audio style transfer methods on musical inputs are not as compelling. In this work, we are specifically interested in the problem of one-shot timbre transfer. We present a novel method for this task, based on an extension of the vector-quantized variational autoencoder (VQ-VAE), along with a simple self-supervised learning strategy designed to obtain disentangled representations of timbre and pitch. We evaluate the method using a set of objective metrics and show that it is able to outperform selected baselines.
Supervised Symbolic Music Style Translation Using Synthetic Data
Jul 04, 2019

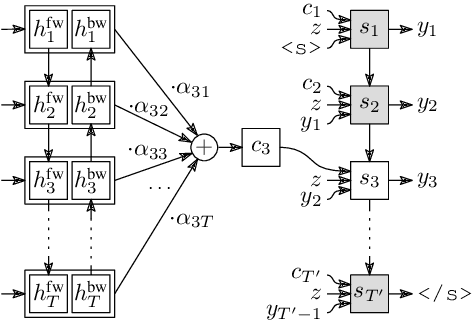

Research on style transfer and domain translation has clearly demonstrated the ability of deep learning-based algorithms to manipulate images in terms of artistic style. More recently, several attempts have been made to extend such approaches to music (both symbolic and audio) in order to enable transforming musical style in a similar manner. In this study, we focus on symbolic music with the goal of altering the 'style' of a piece while keeping its original 'content'. As opposed to the current methods, which are inherently restricted to be unsupervised due to the lack of 'aligned' data (i.e. the same musical piece played in multiple styles), we develop the first fully supervised algorithm for this task. At the core of our approach lies a synthetic data generation scheme which allows us to produce virtually unlimited amounts of aligned data, and hence avoid the above issue. In view of this data generation scheme, we propose an encoder-decoder model for translating symbolic music accompaniments between a number of different styles. Our experiments show that our models, although trained entirely on synthetic data, are capable of producing musically meaningful accompaniments even for real (non-synthetic) MIDI recordings.
Eval all, trust a few, do wrong to none: Comparing sentence generation models
Oct 30, 2018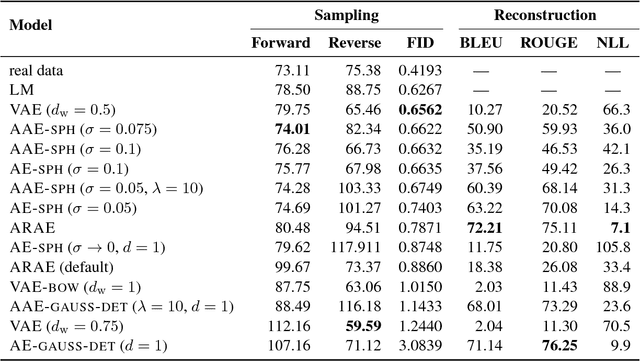
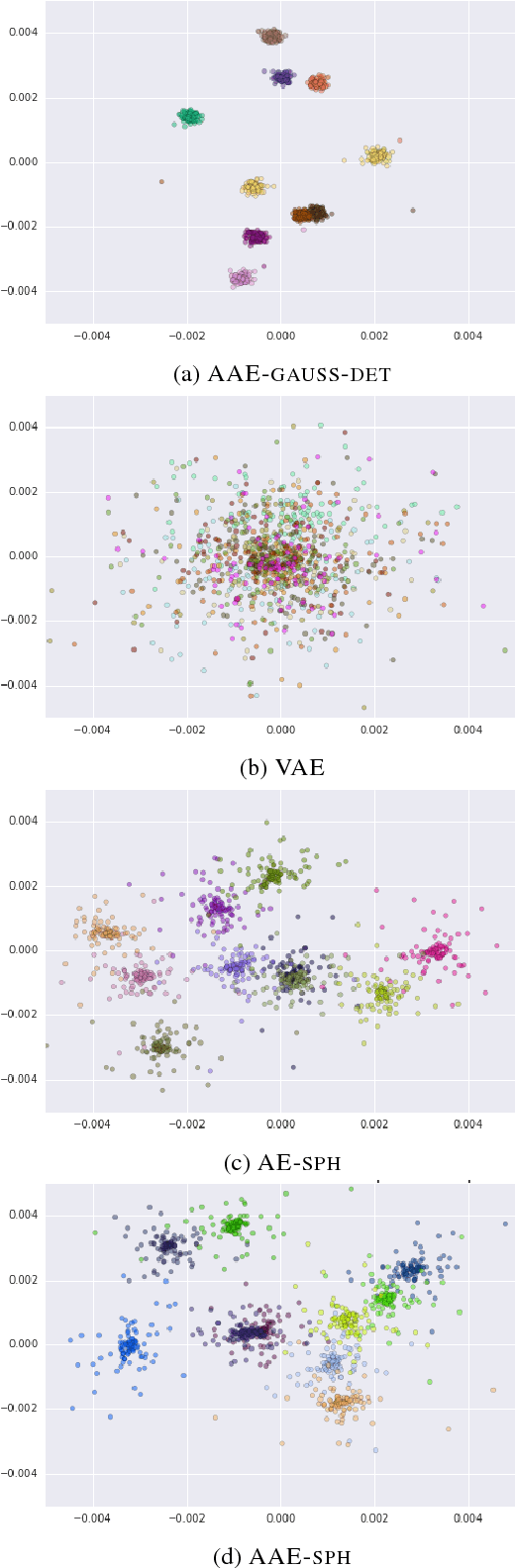


In this paper, we study recent neural generative models for text generation related to variational autoencoders. Previous works have employed various techniques to control the prior distribution of the latent codes in these models, which is important for sampling performance, but little attention has been paid to reconstruction error. In our study, we follow a rigorous evaluation protocol using a large set of previously used and novel automatic and human evaluation metrics, applied to both generated samples and reconstructions. We hope that it will become the new evaluation standard when comparing neural generative models for text.
Are BLEU and Meaning Representation in Opposition?
May 16, 2018
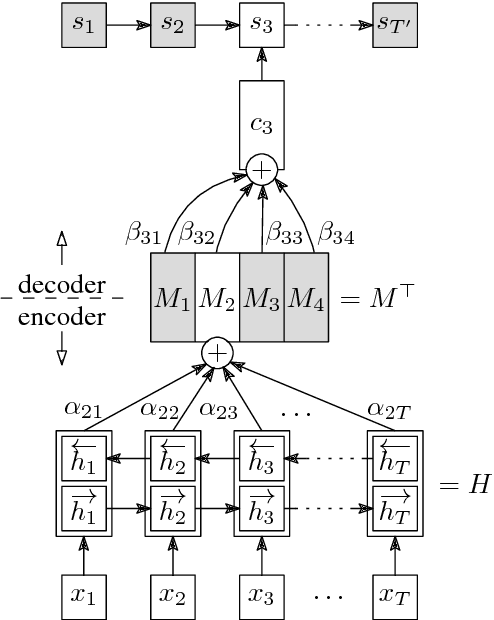
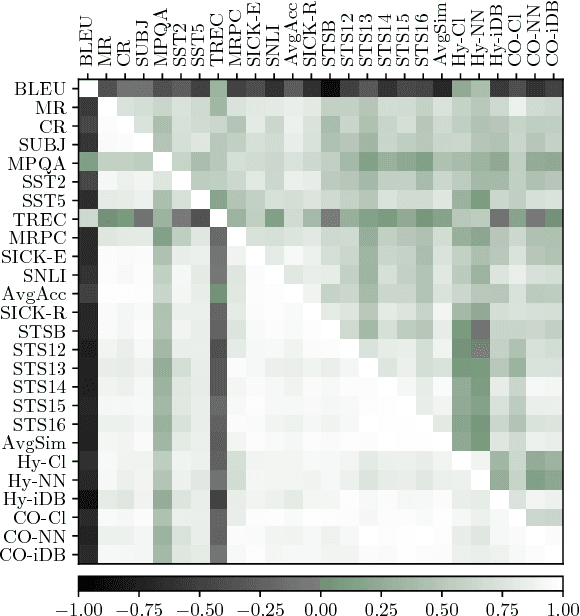
One of possible ways of obtaining continuous-space sentence representations is by training neural machine translation (NMT) systems. The recent attention mechanism however removes the single point in the neural network from which the source sentence representation can be extracted. We propose several variations of the attentive NMT architecture bringing this meeting point back. Empirical evaluation suggests that the better the translation quality, the worse the learned sentence representations serve in a wide range of classification and similarity tasks.