 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Modeling Deep Learning Based Privacy Attacks on Physical Mail
Dec 22, 2020
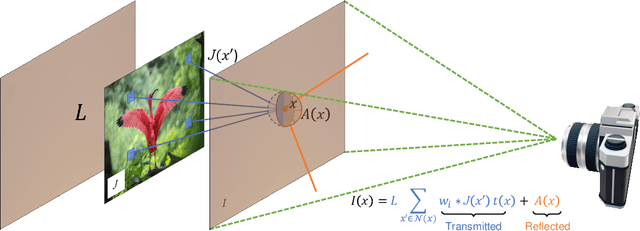

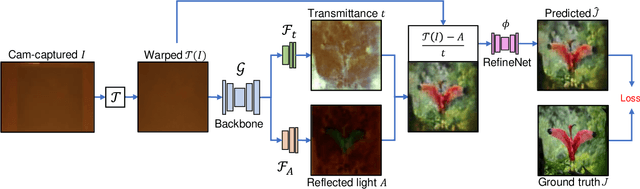

Mail privacy protection aims to prevent unauthorized access to hidden content within an envelope since normal paper envelopes are not as safe as we think. In this paper, for the first time, we show that with a well designed deep learning model, the hidden content may be largely recovered without opening the envelope. We start by modeling deep learning-based privacy attacks on physical mail content as learning the mapping from the camera-captured envelope front face image to the hidden content, then we explicitly model the mapping as a combination of perspective transformation, image dehazing and denoising using a deep convolutional neural network, named Neural-STE (See-Through-Envelope). We show experimentally that hidden content details, such as texture and image structure, can be clearly recovered. Finally, our formulation and model allow us to design envelopes that can counter deep learning-based privacy attacks on physical mail.
More About Covariance Descriptors for Image Set Coding: Log-Euclidean Framework based Kernel Matrix Representation
Sep 26, 2019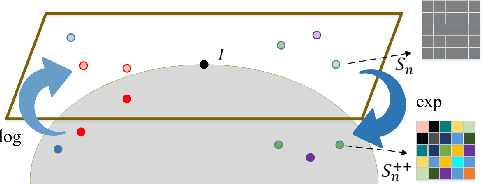
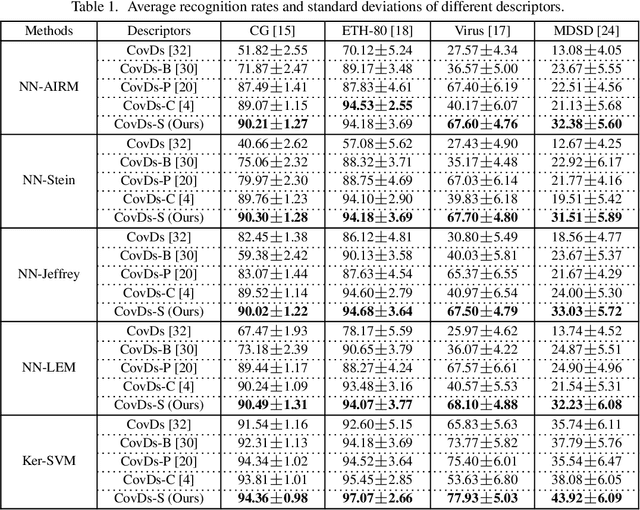
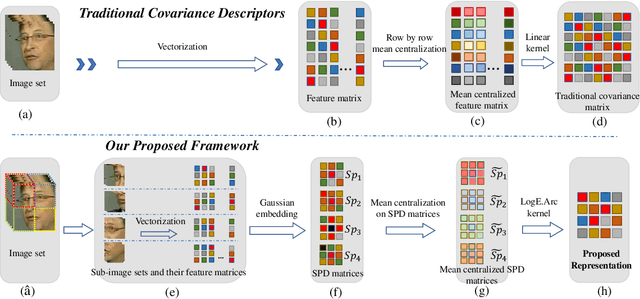
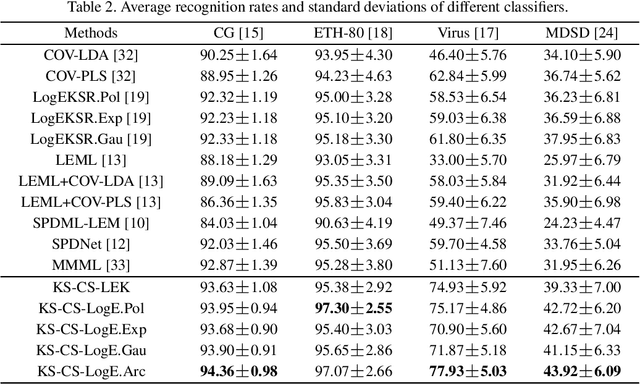
We consider a family of structural descriptors for visual data, namely covariance descriptors (CovDs) that lie on a non-linear symmetric positive definite (SPD) manifold, a special type of Riemannian manifolds. We propose an improved version of CovDs for image set coding by extending the traditional CovDs from Euclidean space to the SPD manifold. Specifically, the manifold of SPD matrices is a complete inner product space with the operations of logarithmic multiplication and scalar logarithmic multiplication defined in the Log-Euclidean framework. In this framework, we characterise covariance structure in terms of the arc-cosine kernel which satisfies Mercer's condition and propose the operation of mean centralization on SPD matrices. Furthermore, we combine arc-cosine kernels of different orders using mixing parameters learnt by kernel alignment in a supervised manner. Our proposed framework provides a lower-dimensional and more discriminative data representation for the task of image set classification. The experimental results demonstrate its superior performance, measured in terms of recognition accuracy, as compared with the state-of-the-art methods.
Deep Learning Methods for Event Verification and Image Repurposing Detection
Feb 11, 2019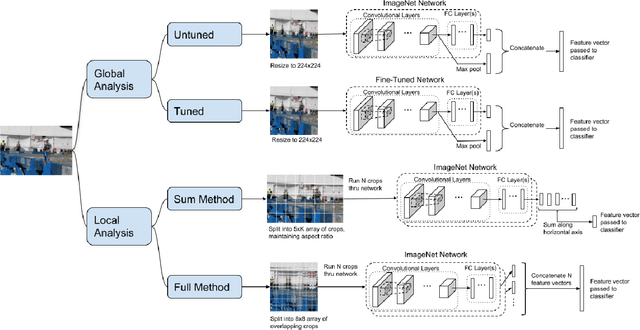


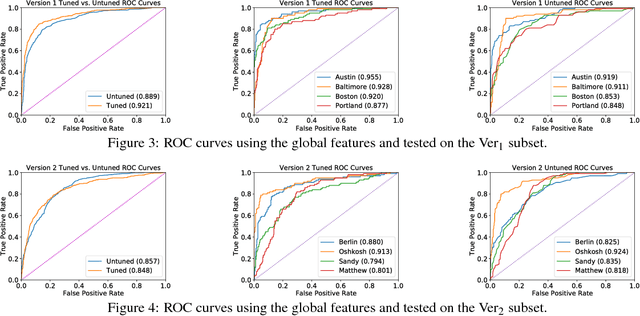
The authenticity of images posted on social media is an issue of growing concern. Many algorithms have been developed to detect manipulated images, but few have investigated the ability of deep neural network based approaches to verify the authenticity of image labels, such as event names. In this paper, we propose several novel methods to predict if an image was captured at one of several noteworthy events. We use a set of images from several recorded events such as storms, marathons, protests, and other large public gatherings. Two strategies of applying pre-trained Imagenet network for event verification are presented, with two modifications for each strategy. The first method uses the features from the last convolutional layer of a pre-trained network as input to a classifier. We also consider the effects of tuning the convolutional weights of the pre-trained network to improve classification. The second method combines many features extracted from smaller scales and uses the output of a pre-trained network as the input to a second classifier. For both methods, we investigated several different classifiers and tested many different pre-trained networks. Our experiments demonstrate both these approaches are effective for event verification and image re-purposing detection. The classification at the global scale tends to marginally outperform our tested local methods and fine tuning the network further improves the results.
SE-MD: A Single-encoder multiple-decoder deep network for point cloud generation from 2D images
Jun 17, 2021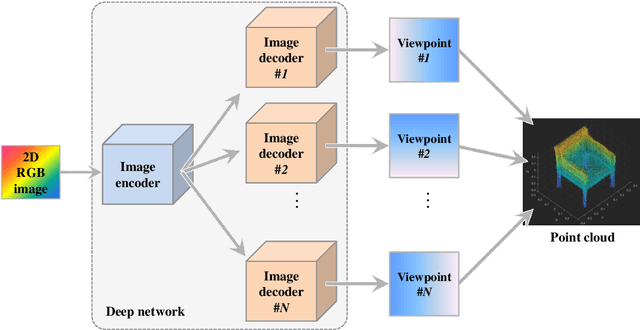



3D model generation from single 2D RGB images is a challenging and actively researched computer vision task. Various techniques using conventional network architectures have been proposed for the same. However, the body of research work is limited and there are various issues like using inefficient 3D representation formats, weak 3D model generation backbones, inability to generate dense point clouds, dependence of post-processing for generation of dense point clouds, and dependence on silhouettes in RGB images. In this paper, a novel 2D RGB image to point cloud conversion technique is proposed, which improves the state of art in the field due to its efficient, robust and simple model by using the concept of parallelization in network architecture. It not only uses the efficient and rich 3D representation of point clouds, but also uses a novel and robust point cloud generation backbone in order to address the prevalent issues. This involves using a single-encoder multiple-decoder deep network architecture wherein each decoder generates certain fixed viewpoints. This is followed by fusing all the viewpoints to generate a dense point cloud. Various experiments are conducted on the technique and its performance is compared with those of other state of the art techniques and impressive gains in performance are demonstrated. Code is available at https://github.com/mueedhafiz1982/
Rethinking Pseudo Labels for Semi-Supervised Object Detection
Jun 01, 2021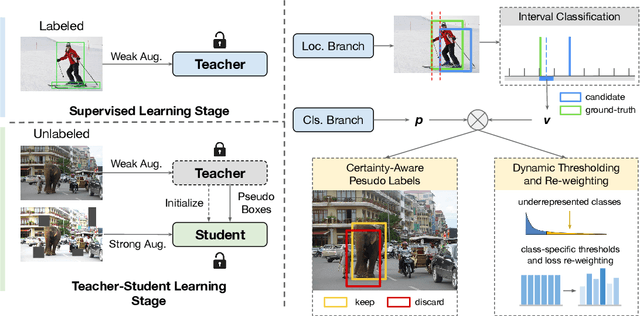
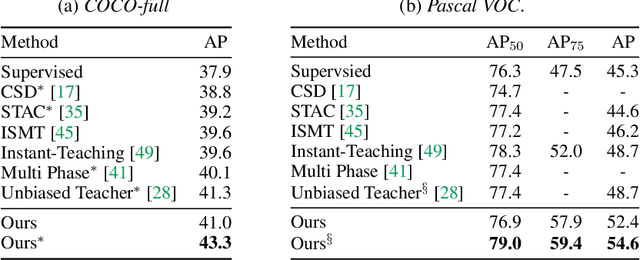
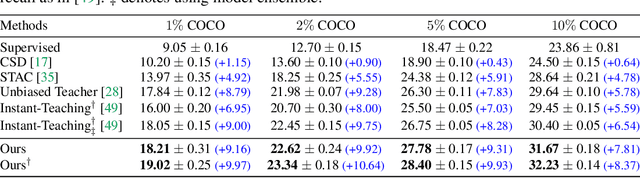
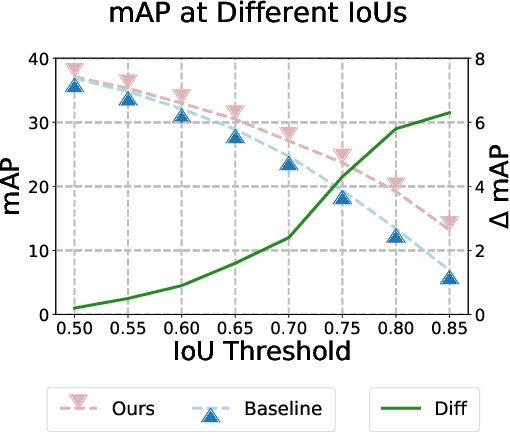
Recent advances in semi-supervised object detection (SSOD) are largely driven by consistency-based pseudo-labeling methods for image classification tasks, producing pseudo labels as supervisory signals. However, when using pseudo labels, there is a lack of consideration in localization precision and amplified class imbalance, both of which are critical for detection tasks. In this paper, we introduce certainty-aware pseudo labels tailored for object detection, which can effectively estimate the classification and localization quality of derived pseudo labels. This is achieved by converting conventional localization as a classification task followed by refinement. Conditioned on classification and localization quality scores, we dynamically adjust the thresholds used to generate pseudo labels and reweight loss functions for each category to alleviate the class imbalance problem. Extensive experiments demonstrate that our method improves state-of-the-art SSOD performance by 1-2% and 4-6% AP on COCO and PASCAL VOC, respectively. In the limited-annotation regime, our approach improves supervised baselines by up to 10% AP using only 1-10% labeled data from COCO.
Unknown-box Approximation to Improve Optical Character Recognition Performance
May 17, 2021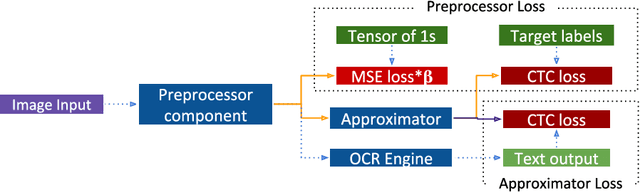
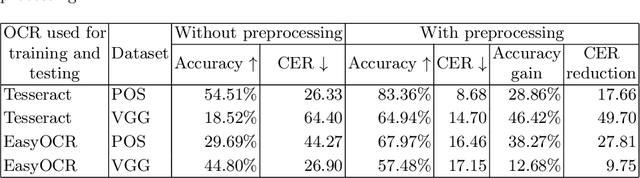
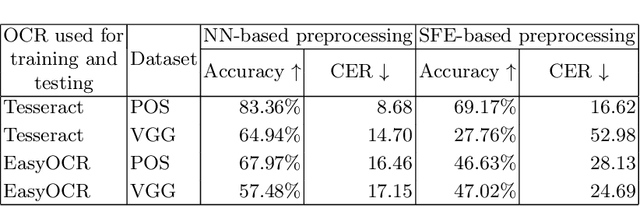

Optical character recognition (OCR) is a widely used pattern recognition application in numerous domains. There are several feature-rich, general-purpose OCR solutions available for consumers, which can provide moderate to excellent accuracy levels. However, accuracy can diminish with difficult and uncommon document domains. Preprocessing of document images can be used to minimize the effect of domain shift. In this paper, a novel approach is presented for creating a customized preprocessor for a given OCR engine. Unlike the previous OCR agnostic preprocessing techniques, the proposed approach approximates the gradient of a particular OCR engine to train a preprocessor module. Experiments with two datasets and two OCR engines show that the presented preprocessor is able to improve the accuracy of the OCR up to 46% from the baseline by applying pixel-level manipulations to the document image. The implementation of the proposed method and the enhanced public datasets are available for download.
VIVO: Surpassing Human Performance in Novel Object Captioning with Visual Vocabulary Pre-Training
Sep 28, 2020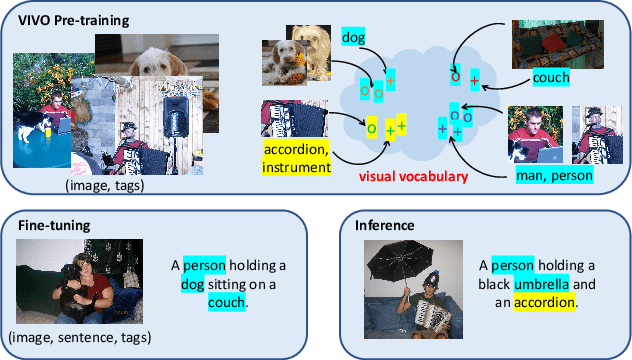
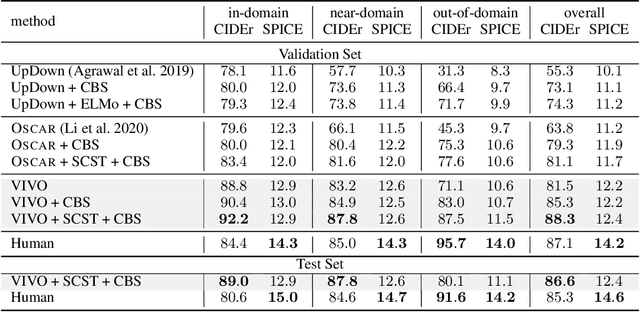
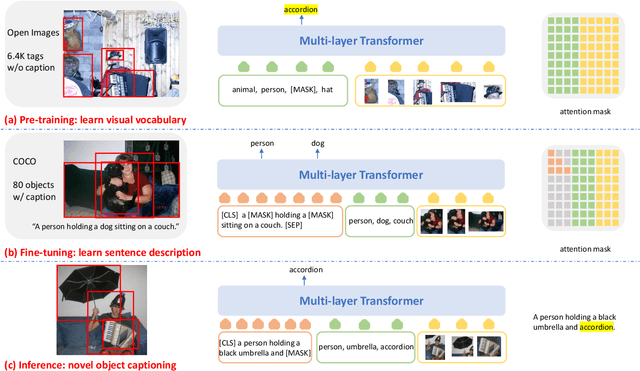

It is highly desirable yet challenging to generate image captions that can describe novel objects which are unseen in caption-labeled training data, a capability that is evaluated in the novel object captioning challenge (nocaps). In this challenge, no additional image-caption training data, other than COCO Captions, is allowed for model training. Thus, conventional Vision-Language Pre-training (VLP) methods cannot be applied. This paper presents VIsual VOcabulary pre-training (VIVO) that performs pre-training in the absence of caption annotations. By breaking the dependency of paired image-caption training data in VLP, VIVO can leverage large amounts of paired image-tag data to learn a visual vocabulary. This is done by pre-training a multi-layer Transformer model that learns to align image-level tags with their corresponding image region features. To address the unordered nature of image tags, VIVO uses a Hungarian matching loss with masked tag prediction to conduct pre-training. We validate the effectiveness of VIVO by fine-tuning the pre-trained model for image captioning. In addition, we perform an analysis of the visual-text alignment inferred by our model. The results show that our model can not only generate fluent image captions that describe novel objects, but also identify the locations of these objects. Our single model has achieved new state-of-the-art results on nocaps and surpassed the human CIDEr score.
ShuffleBlock: Shuffle to Regularize Deep Convolutional Neural Networks
Jun 17, 2021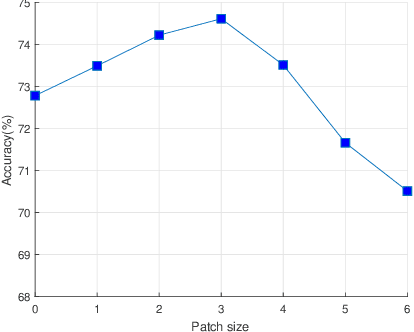
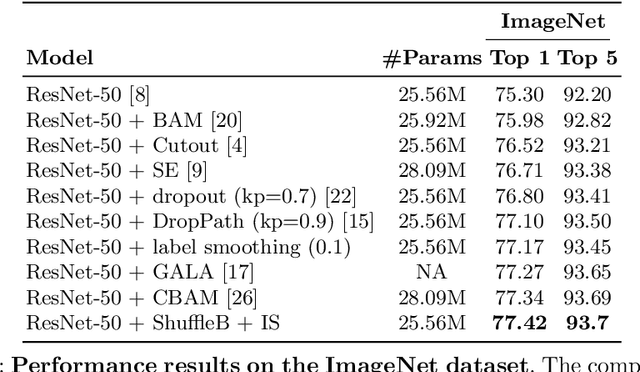
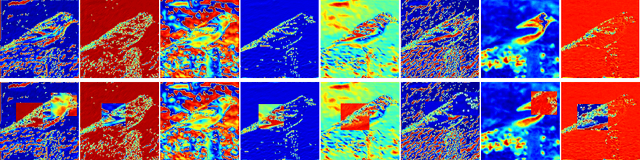
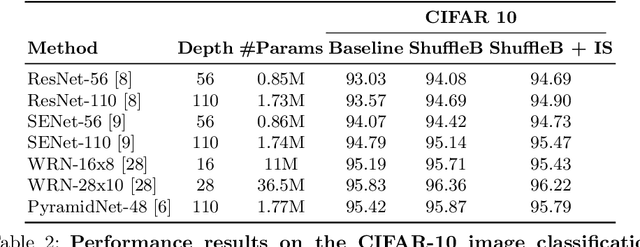
Deep neural networks have enormous representational power which leads them to overfit on most datasets. Thus, regularizing them is important in order to reduce overfitting and enhance their generalization capabilities. Recently, channel shuffle operation has been introduced for mixing channels in group convolutions in resource efficient networks in order to reduce memory and computations. This paper studies the operation of channel shuffle as a regularization technique in deep convolutional networks. We show that while random shuffling of channels during training drastically reduce their performance, however, randomly shuffling small patches between channels significantly improves their performance. The patches to be shuffled are picked from the same spatial locations in the feature maps such that a patch, when transferred from one channel to another, acts as structured noise for the later channel. We call this method "ShuffleBlock". The proposed ShuffleBlock module is easy to implement and improves the performance of several baseline networks on the task of image classification on CIFAR and ImageNet datasets. It also achieves comparable and in many cases better performance than many other regularization methods. We provide several ablation studies on selecting various hyperparameters of the ShuffleBlock module and propose a new scheduling method that further enhances its performance.
Towards Keypoint Guided Self-Supervised Depth Estimation
Nov 05, 2020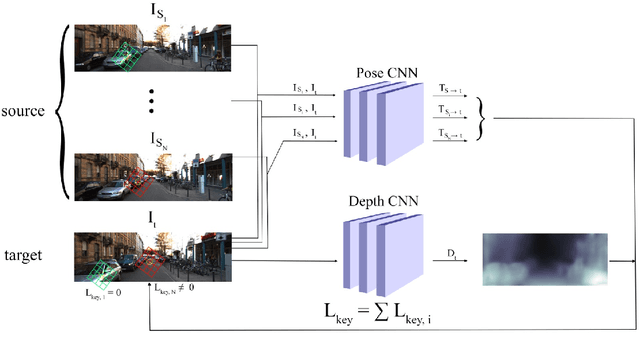
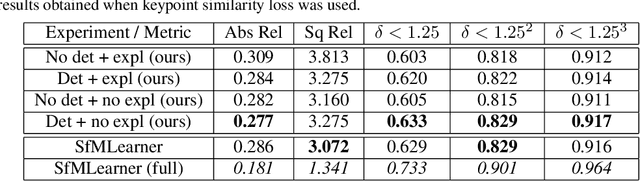
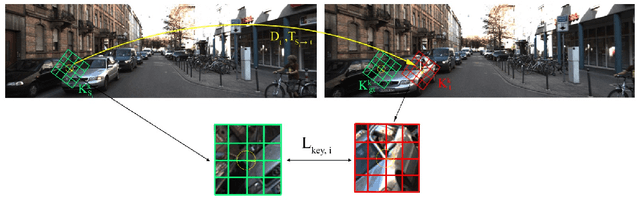
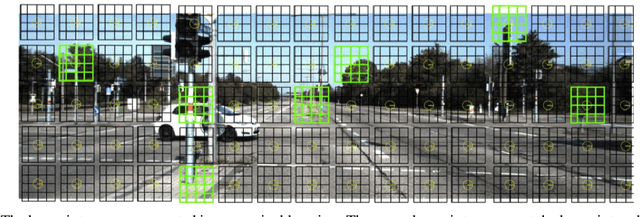
This paper proposes to use keypoints as a self-supervision clue for learning depth map estimation from a collection of input images. As ground truth depth from real images is difficult to obtain, there are many unsupervised and self-supervised approaches to depth estimation that have been proposed. Most of these unsupervised approaches use depth map and ego-motion estimations to reproject the pixels from the current image into the adjacent image from the image collection. Depth and ego-motion estimations are evaluated based on pixel intensity differences between the correspondent original and reprojected pixels. Instead of reprojecting the individual pixels, we propose to first select image keypoints in both images and then reproject and compare the correspondent keypoints of the two images. The keypoints should describe the distinctive image features well. By learning a deep model with and without the keypoint extraction technique, we show that using the keypoints improve the depth estimation learning. We also propose some future directions for keypoint-guided learning of structure-from-motion problems.
Unsupervised Learning of Depth and Depth-of-Field Effect from Natural Images with Aperture Rendering Generative Adversarial Networks
Jun 24, 2021
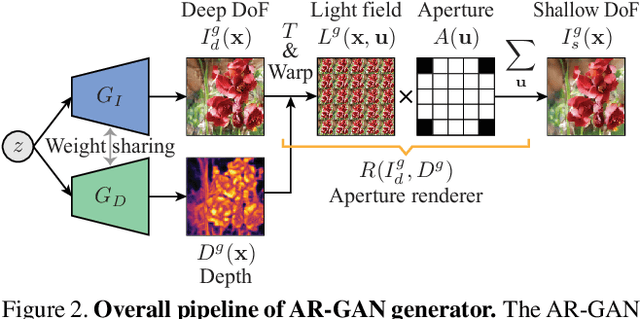
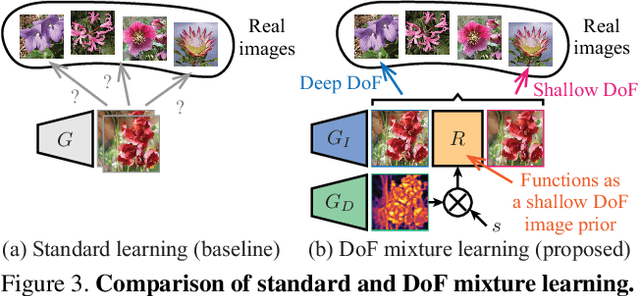
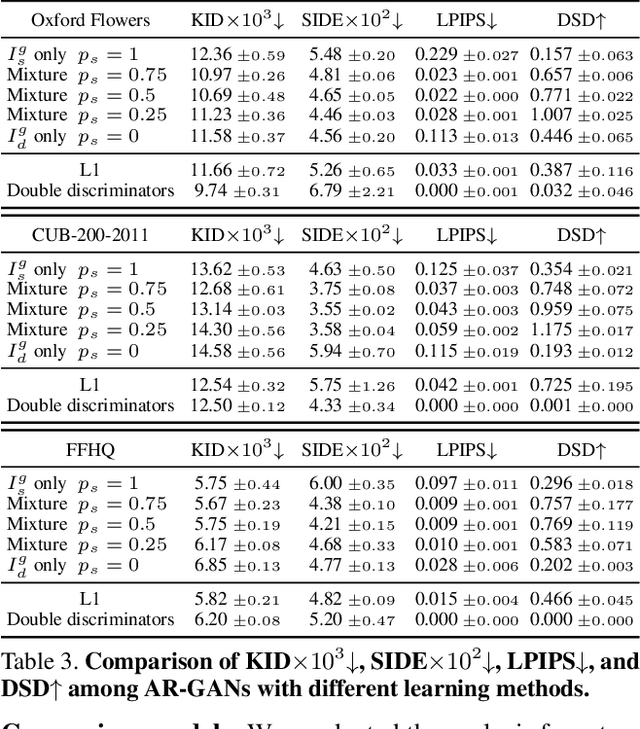
Understanding the 3D world from 2D projected natural images is a fundamental challenge in computer vision and graphics. Recently, an unsupervised learning approach has garnered considerable attention owing to its advantages in data collection. However, to mitigate training limitations, typical methods need to impose assumptions for viewpoint distribution (e.g., a dataset containing various viewpoint images) or object shape (e.g., symmetric objects). These assumptions often restrict applications; for instance, the application to non-rigid objects or images captured from similar viewpoints (e.g., flower or bird images) remains a challenge. To complement these approaches, we propose aperture rendering generative adversarial networks (AR-GANs), which equip aperture rendering on top of GANs, and adopt focus cues to learn the depth and depth-of-field (DoF) effect of unlabeled natural images. To address the ambiguities triggered by unsupervised setting (i.e., ambiguities between smooth texture and out-of-focus blurs, and between foreground and background blurs), we develop DoF mixture learning, which enables the generator to learn real image distribution while generating diverse DoF images. In addition, we devise a center focus prior to guiding the learning direction. In the experiments, we demonstrate the effectiveness of AR-GANs in various datasets, such as flower, bird, and face images, demonstrate their portability by incorporating them into other 3D representation learning GANs, and validate their applicability in shallow DoF rendering.