 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSE-MD: A Single-encoder multiple-decoder deep network for point cloud generation from 2D images
Jun 17, 2021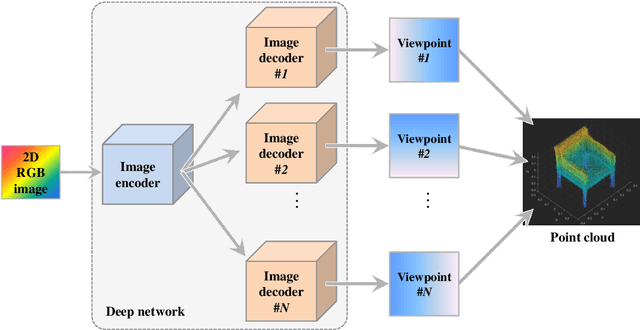



3D model generation from single 2D RGB images is a challenging and actively researched computer vision task. Various techniques using conventional network architectures have been proposed for the same. However, the body of research work is limited and there are various issues like using inefficient 3D representation formats, weak 3D model generation backbones, inability to generate dense point clouds, dependence of post-processing for generation of dense point clouds, and dependence on silhouettes in RGB images. In this paper, a novel 2D RGB image to point cloud conversion technique is proposed, which improves the state of art in the field due to its efficient, robust and simple model by using the concept of parallelization in network architecture. It not only uses the efficient and rich 3D representation of point clouds, but also uses a novel and robust point cloud generation backbone in order to address the prevalent issues. This involves using a single-encoder multiple-decoder deep network architecture wherein each decoder generates certain fixed viewpoints. This is followed by fusing all the viewpoints to generate a dense point cloud. Various experiments are conducted on the technique and its performance is compared with those of other state of the art techniques and impressive gains in performance are demonstrated. Code is available at https://github.com/mueedhafiz1982/
Attention mechanisms and deep learning for machine vision: A survey of the state of the art
Jun 03, 2021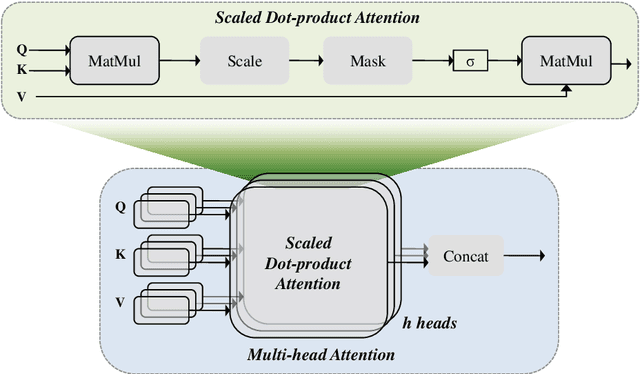
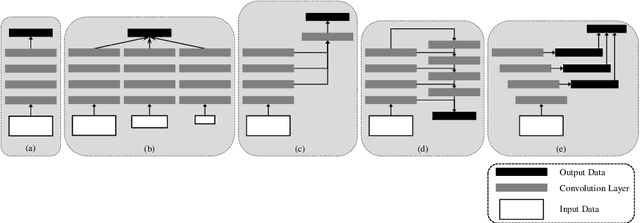
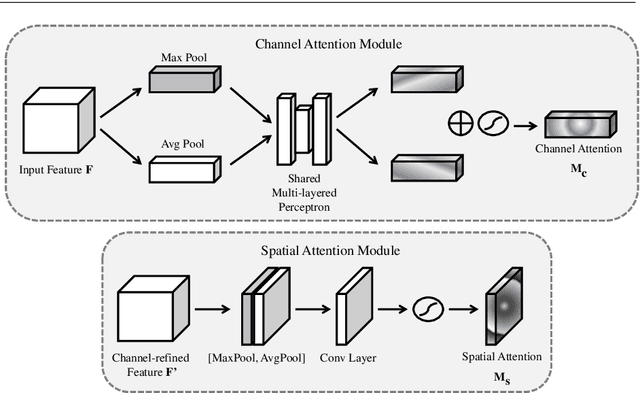

With the advent of state of the art nature-inspired pure attention based models i.e. transformers, and their success in natural language processing (NLP), their extension to machine vision (MV) tasks was inevitable and much felt. Subsequently, vision transformers (ViTs) were introduced which are giving quite a challenge to the established deep learning based machine vision techniques. However, pure attention based models/architectures like transformers require huge data, large training times and large computational resources. Some recent works suggest that combinations of these two varied fields can prove to build systems which have the advantages of both these fields. Accordingly, this state of the art survey paper is introduced which hopefully will help readers get useful information about this interesting and potential research area. A gentle introduction to attention mechanisms is given, followed by a discussion of the popular attention based deep architectures. Subsequently, the major categories of the intersection of attention mechanisms and deep learning for machine vision (MV) based are discussed. Afterwards, the major algorithms, issues and trends within the scope of the paper are discussed.