 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image denoising with generalized Gaussian mixture model patch priors
Jun 11, 2018
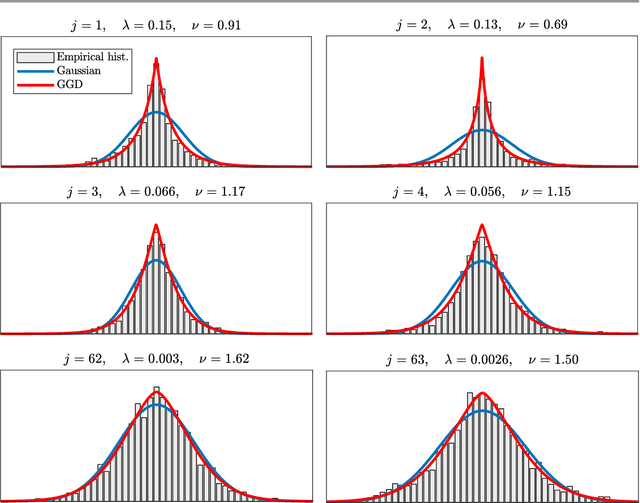

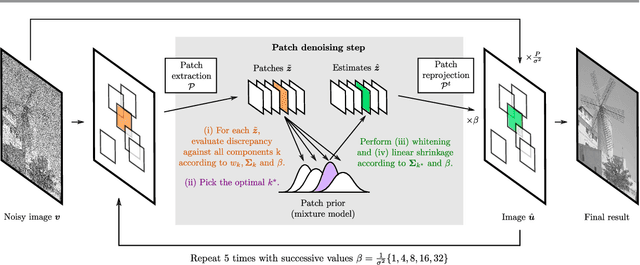
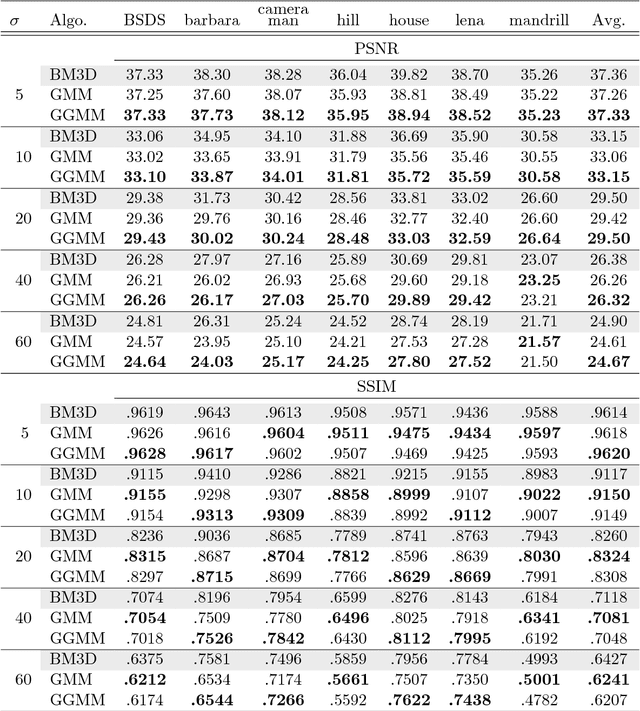
Patch priors have become an important component of image restoration. A powerful approach in this category of restoration algorithms is the popular Expected Patch Log-Likelihood (EPLL) algorithm. EPLL uses a Gaussian mixture model (GMM) prior learned on clean image patches as a way to regularize degraded patches. In this paper, we show that a generalized Gaussian mixture model (GGMM) captures the underlying distribution of patches better than a GMM. Even though GGMM is a powerful prior to combine with EPLL, the non-Gaussianity of its components presents major challenges to be applied to a computationally intensive process of image restoration. Specifically, each patch has to undergo a patch classification step and a shrinkage step. These two steps can be efficiently solved with a GMM prior but are computationally impractical when using a GGMM prior. In this paper, we provide approximations and computational recipes for fast evaluation of these two steps, so that EPLL can embed a GGMM prior on an image with more than tens of thousands of patches. Our main contribution is to analyze the accuracy of our approximations based on thorough theoretical analysis. Our evaluations indicate that the GGMM prior is consistently a better fit formodeling image patch distribution and performs better on average in image denoising task.
Fuzzy clustering algorithms with distance metric learning and entropy regularization
Feb 18, 2021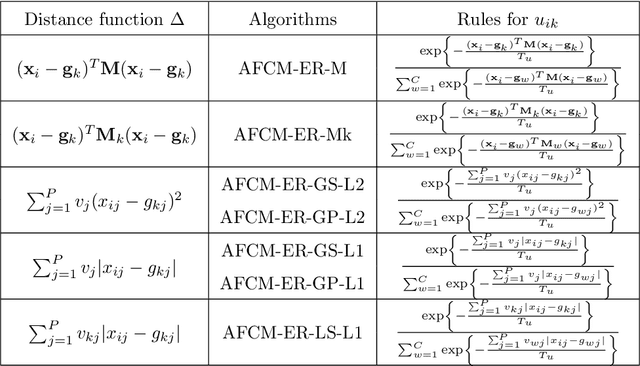
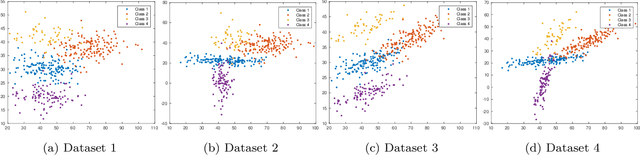
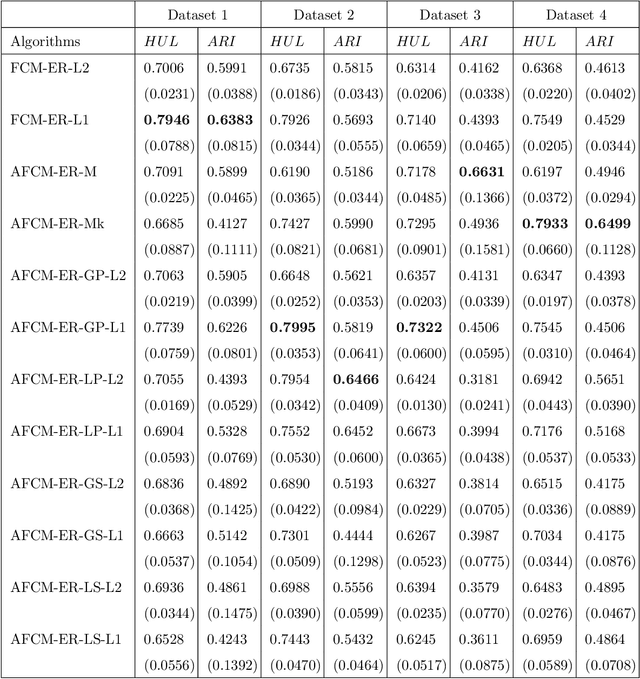
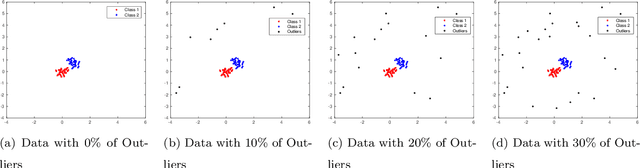
The clustering methods have been used in a variety of fields such as image processing, data mining, pattern recognition, and statistical analysis. Generally, the clustering algorithms consider all variables equally relevant or not correlated for the clustering task. Nevertheless, in real situations, some variables can be correlated or may be more or less relevant or even irrelevant for this task. This paper proposes partitioning fuzzy clustering algorithms based on Euclidean, City-block and Mahalanobis distances and entropy regularization. These methods are an iterative three steps algorithms which provide a fuzzy partition, a representative for each fuzzy cluster, and the relevance weight of the variables or their correlation by minimizing a suitable objective function. Several experiments on synthetic and real datasets, including its application to noisy image texture segmentation, demonstrate the usefulness of these adaptive clustering methods.
Few-Shot Domain Adaptation with Polymorphic Transformers
Jul 10, 2021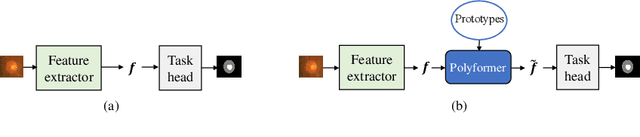

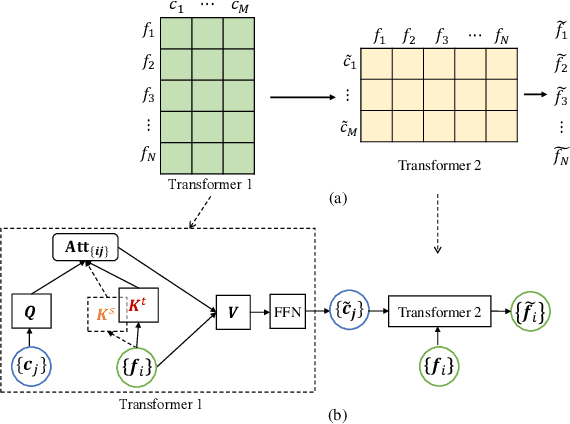
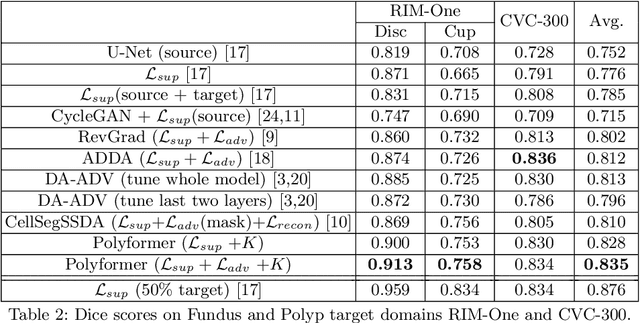
Deep neural networks (DNNs) trained on one set of medical images often experience severe performance drop on unseen test images, due to various domain discrepancy between the training images (source domain) and the test images (target domain), which raises a domain adaptation issue. In clinical settings, it is difficult to collect enough annotated target domain data in a short period. Few-shot domain adaptation, i.e., adapting a trained model with a handful of annotations, is highly practical and useful in this case. In this paper, we propose a Polymorphic Transformer (Polyformer), which can be incorporated into any DNN backbones for few-shot domain adaptation. Specifically, after the polyformer layer is inserted into a model trained on the source domain, it extracts a set of prototype embeddings, which can be viewed as a "basis" of the source-domain features. On the target domain, the polyformer layer adapts by only updating a projection layer which controls the interactions between image features and the prototype embeddings. All other model weights (except BatchNorm parameters) are frozen during adaptation. Thus, the chance of overfitting the annotations is greatly reduced, and the model can perform robustly on the target domain after being trained on a few annotated images. We demonstrate the effectiveness of Polyformer on two medical segmentation tasks (i.e., optic disc/cup segmentation, and polyp segmentation). The source code of Polyformer is released at https://github.com/askerlee/segtran.
Separated-Spectral-Distribution Estimation Based on Bayesian Inference with Single RGB Camera
Jun 01, 2021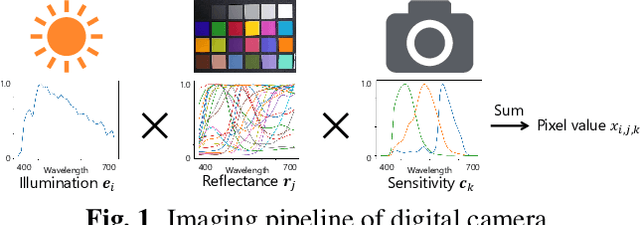
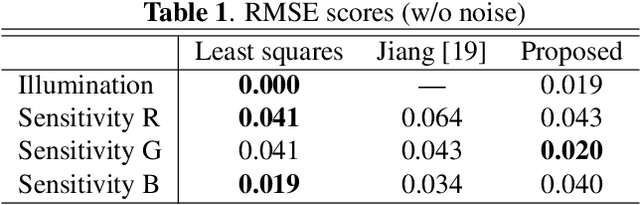
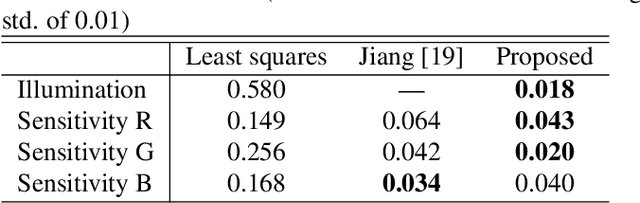
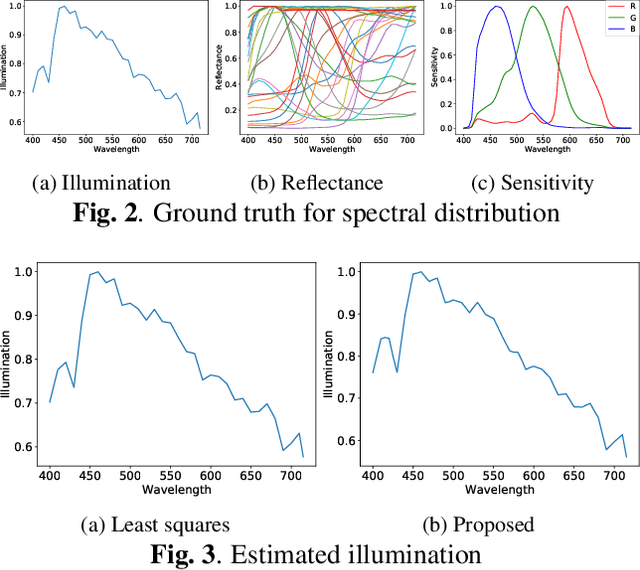
In this paper, we propose a novel method for separately estimating spectral distributions from images captured by a typical RGB camera. The proposed method allows us to separately estimate a spectral distribution of illumination, reflectance, or camera sensitivity, while recent hyperspectral cameras are limited to capturing a joint spectral distribution from a scene. In addition, the use of Bayesian inference makes it possible to take into account prior information of both spectral distributions and image noise as probability distributions. As a result, the proposed method can estimate spectral distributions in a unified way, and it can enhance the robustness of the estimation against noise, which conventional spectral-distribution estimation methods cannot. The use of Bayesian inference also enables us to obtain the confidence of estimation results. In an experiment, the proposed method is shown not only to outperform conventional estimation methods in terms of RMSE but also to be robust against noise.
Dual Recovery Network with Online Compensation for Image Super-Resolution
Jun 18, 2018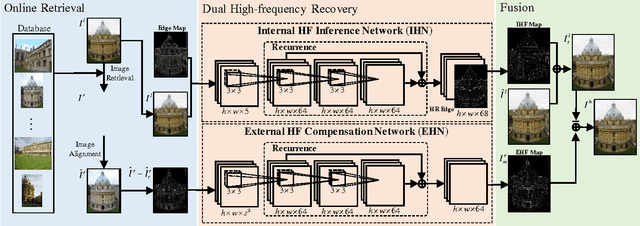
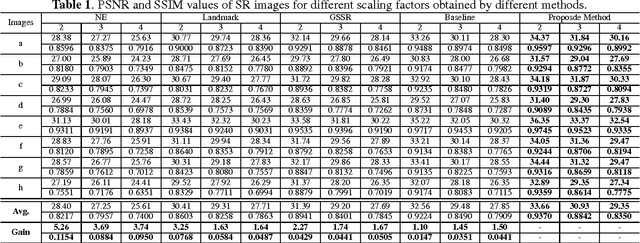

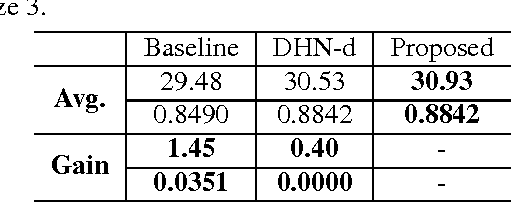
Image super-resolution (SR) methods essentially lead to a loss of some high-frequency (HF) information when predicting high-resolution (HR) images from low-resolution (LR) images without using external references. To address this issue, we additionally utilize online retrieved data to facilitate image SR in a unified deep framework. A novel dual high-frequency recovery network (DHN) is proposed to predict an HR image with three parts: an LR image, an internal inferred HF (IHF) map (HF missing part inferred solely from the LR image) and an external extracted HF (EHF) map. In particular, we infer the HF information based on both the LR image and similar HR references which are retrieved online. For the EHF map, we align the references with affine transformation and then in the aligned references, part of HF signals are extracted by the proposed DHN to compensate for the HF loss. Extensive experimental results demonstrate that our DHN achieves notably better performance than state-of-the-art SR methods.
Scene Retrieval for Contextual Visual Mapping
Feb 25, 2021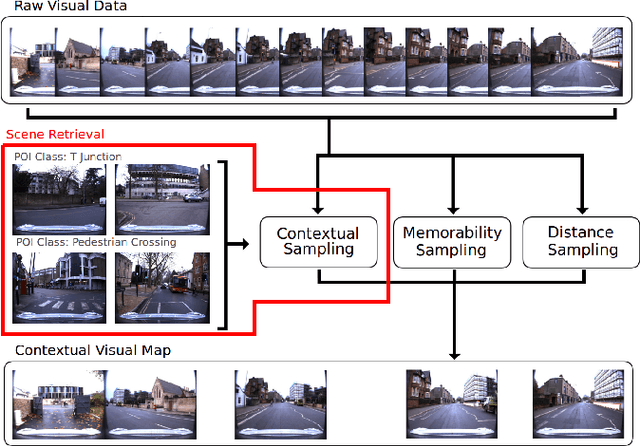

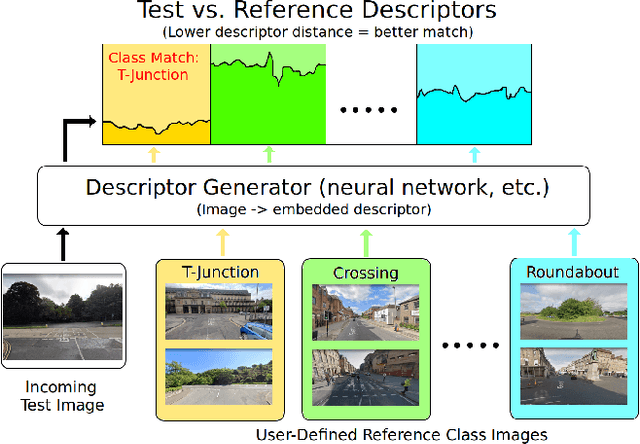
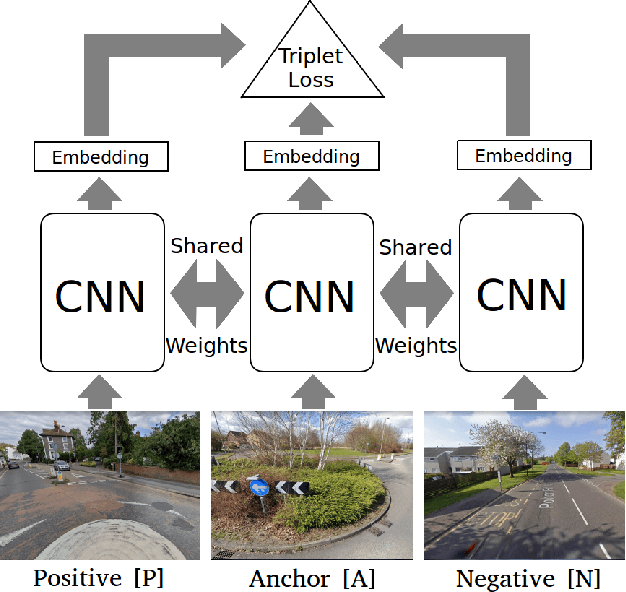
Visual navigation localizes a query place image against a reference database of place images, also known as a `visual map'. Localization accuracy requirements for specific areas of the visual map, `scene classes', vary according to the context of the environment and task. State-of-the-art visual mapping is unable to reflect these requirements by explicitly targetting scene classes for inclusion in the map. Four different scene classes, including pedestrian crossings and stations, are identified in each of the Nordland and St. Lucia datasets. Instead of re-training separate scene classifiers which struggle with these overlapping scene classes we make our first contribution: defining the problem of `scene retrieval'. Scene retrieval extends image retrieval to classification of scenes defined at test time by associating a single query image to reference images of scene classes. Our second contribution is a triplet-trained convolutional neural network (CNN) to address this problem which increases scene classification accuracy by up to 7% against state-of-the-art networks pre-trained for scene recognition. The second contribution is an algorithm `DMC' that combines our scene classification with distance and memorability for visual mapping. Our analysis shows that DMC includes 64% more images of our chosen scene classes in a visual map than just using distance interval mapping. State-of-the-art visual place descriptors AMOS-Net, Hybrid-Net and NetVLAD are finally used to show that DMC improves scene class localization accuracy by a mean of 3% and localization accuracy of the remaining map images by a mean of 10% across both datasets.
H-FL: A Hierarchical Communication-Efficient and Privacy-Protected Architecture for Federated Learning
Jun 01, 2021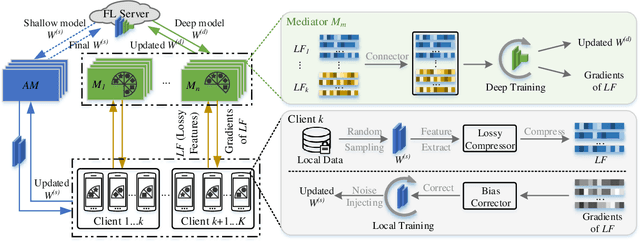

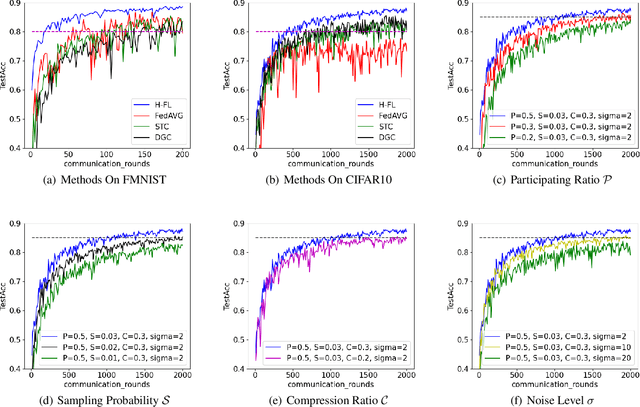

The longstanding goals of federated learning (FL) require rigorous privacy guarantees and low communication overhead while holding a relatively high model accuracy. However, simultaneously achieving all the goals is extremely challenging. In this paper, we propose a novel framework called hierarchical federated learning (H-FL) to tackle this challenge. Considering the degradation of the model performance due to the statistic heterogeneity of the training data, we devise a runtime distribution reconstruction strategy, which reallocates the clients appropriately and utilizes mediators to rearrange the local training of the clients. In addition, we design a compression-correction mechanism incorporated into H-FL to reduce the communication overhead while not sacrificing the model performance. To further provide privacy guarantees, we introduce differential privacy while performing local training, which injects moderate amount of noise into only part of the complete model. Experimental results show that our H-FL framework achieves the state-of-art performance on different datasets for the real-world image recognition tasks.
Regional Registration of Whole Slide Image Stacks Containing Highly Deformed Artefacts
Feb 28, 2020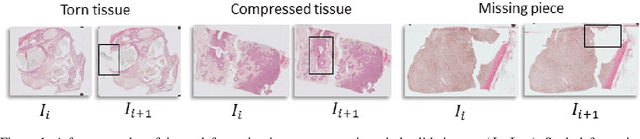

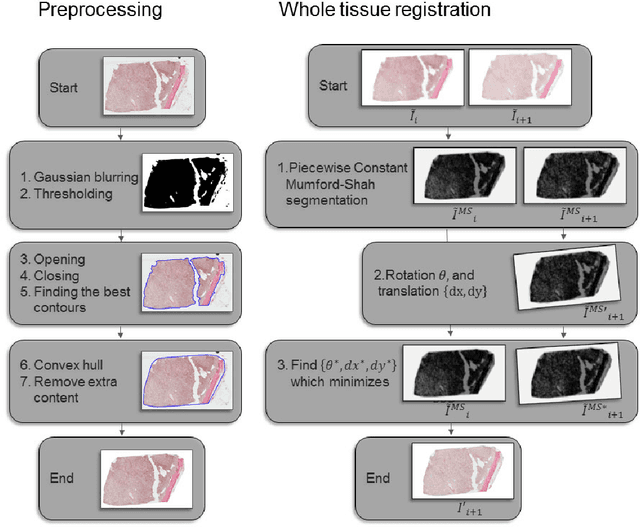
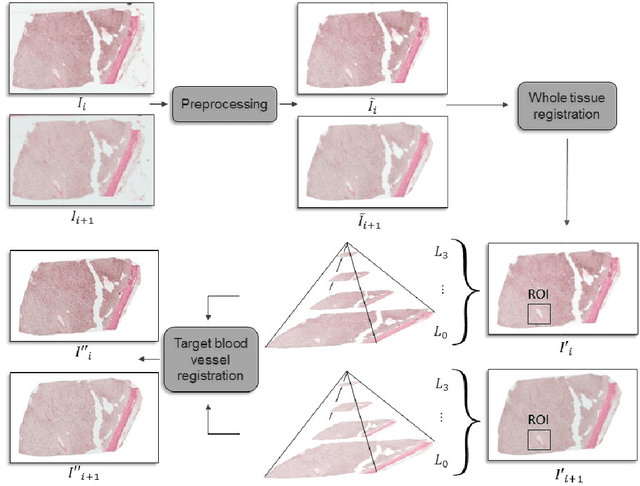
Motivation: High resolution 2D whole slide imaging provides rich information about the tissue structure. This information can be a lot richer if these 2D images can be stacked into a 3D tissue volume. A 3D analysis, however, requires accurate reconstruction of the tissue volume from the 2D image stack. This task is not trivial due to the distortions that each individual tissue slice experiences while cutting and mounting the tissue on the glass slide. Performing registration for the whole tissue slices may be adversely affected by the deformed tissue regions. Consequently, regional registration is found to be more effective. In this paper, we propose an accurate and robust regional registration algorithm for whole slide images which incrementally focuses registration on the area around the region of interest. Results: Using mean similarity index as the metric, the proposed algorithm (mean $\pm$ std: $0.84 \pm 0.11$) followed by a fine registration algorithm ($0.86 \pm 0.08$) outperformed the state-of-the-art linear whole tissue registration algorithm ($0.74 \pm 0.19$) and the regional version of this algorithm ($0.81 \pm 0.15$). The proposed algorithm also outperforms the state-of-the-art nonlinear registration algorithm (original : $0.82 \pm 0.12$, regional : $0.77 \pm 0.22$) for whole slide images and a recently proposed patch-based registration algorithm (patch size 256: $0.79 \pm 0.16$ , patch size 512: $0.77 \pm 0.16$) for medical images. Availability: The C++ implementation code is available online at the github repository: https://github.com/MahsaPaknezhad/WSIRegistration
Non-linear aggregation of filters to improve image denoising
Apr 01, 2019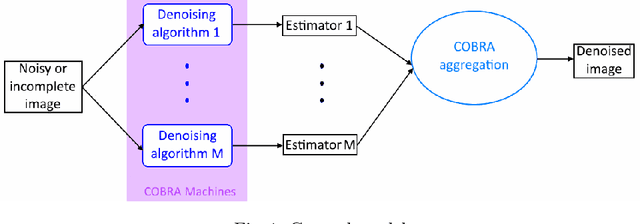

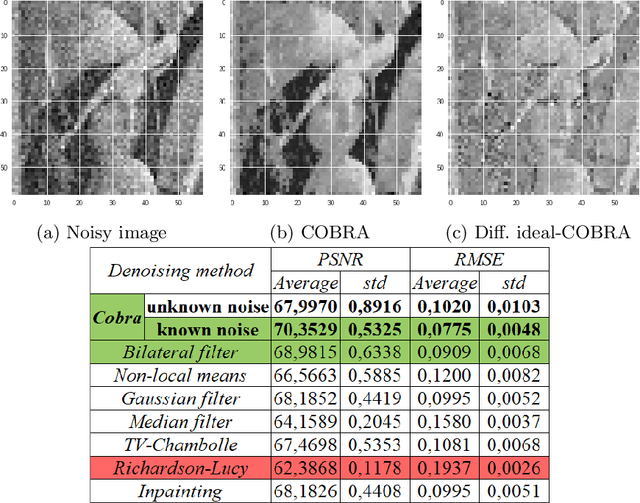
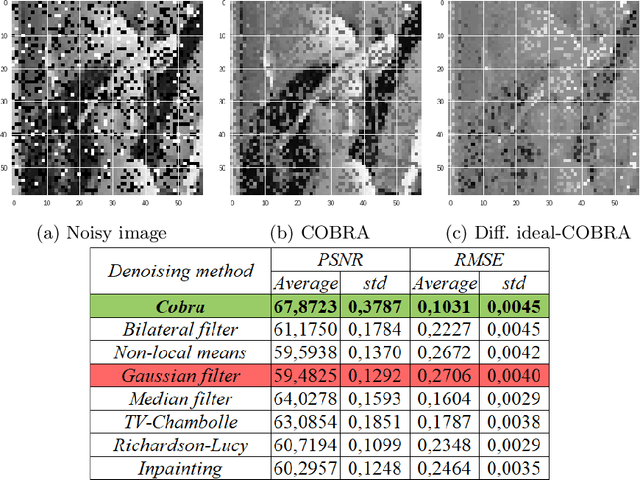
We introduce a novel aggregation method to efficiently perform image denoising. Preliminary filters are aggregated in a non-linear fashion, using a new metric of pixel proximity based on how the pool of filters reaches a consensus. The numerical performance of the method is illustrated and we show that the aggregate significantly outperforms each of the preliminary filters.
The Pursuit of Knowledge: Discovering and Localizing Novel Categories using Dual Memory
May 04, 2021
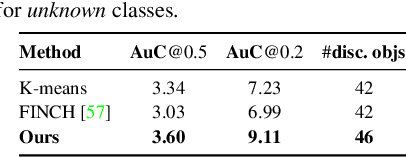
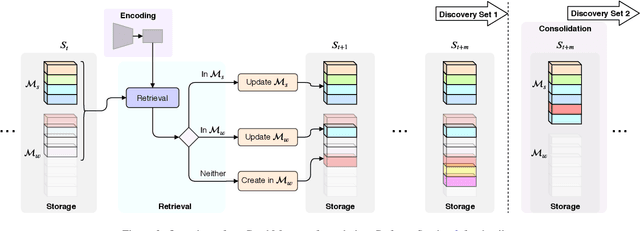

We tackle object category discovery, which is the problem of discovering and localizing novel objects in a large unlabeled dataset. While existing methods show results on datasets with less cluttered scenes and fewer object instances per image, we present our results on the challenging COCO dataset. Moreover, we argue that, rather than discovering new categories from scratch, discovery algorithms can benefit from identifying what is already known and focusing their attention on the unknown. We propose a method to use prior knowledge about certain object categories to discover new categories by leveraging two memory modules, namely Working and Semantic memory. We show the performance of our detector on the COCO minival dataset to demonstrate its in-the-wild capabilities.