 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigation of moving objects through atmospheric turbulence from a non-stationary platform
Oct 29, 2024In this work, we extract the optical flow field corresponding to moving objects from an image sequence of a scene impacted by atmospheric turbulence \emph{and} captured from a moving camera. Our procedure first computes the optical flow field and creates a motion model to compensate for the flow field induced by camera motion. After subtracting the motion model from the optical flow, we proceed with our previous work, Gilles et al~\cite{gilles2018detection}, where a spatial-temporal cartoon+texture inspired decomposition is performed on the motion-compensated flow field in order to separate flows corresponding to atmospheric turbulence and object motion. Finally, the geometric component is processed with the detection and tracking method and is compared against a ground truth. All of the sequences and code used in this work are open source and are available by contacting the authors.
Out-of-Distribution Learning with Human Feedback
Aug 14, 2024



Out-of-distribution (OOD) learning often relies heavily on statistical approaches or predefined assumptions about OOD data distributions, hindering their efficacy in addressing multifaceted challenges of OOD generalization and OOD detection in real-world deployment environments. This paper presents a novel framework for OOD learning with human feedback, which can provide invaluable insights into the nature of OOD shifts and guide effective model adaptation. Our framework capitalizes on the freely available unlabeled data in the wild that captures the environmental test-time OOD distributions under both covariate and semantic shifts. To harness such data, our key idea is to selectively provide human feedback and label a small number of informative samples from the wild data distribution, which are then used to train a multi-class classifier and an OOD detector. By exploiting human feedback, we enhance the robustness and reliability of machine learning models, equipping them with the capability to handle OOD scenarios with greater precision. We provide theoretical insights on the generalization error bounds to justify our algorithm. Extensive experiments show the superiority of our method, outperforming the current state-of-the-art by a significant margin.
Real-Time Event-Based Tracking and Detection for Maritime Environments
Feb 09, 2022
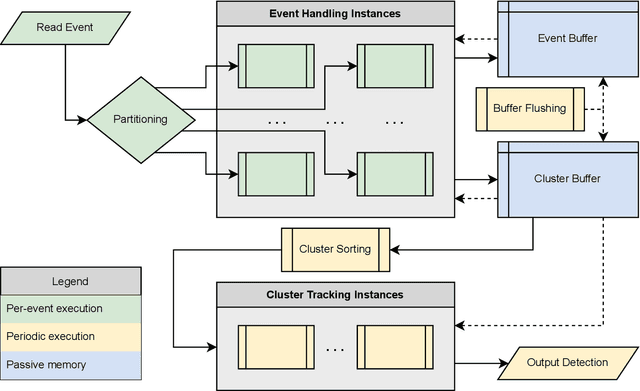

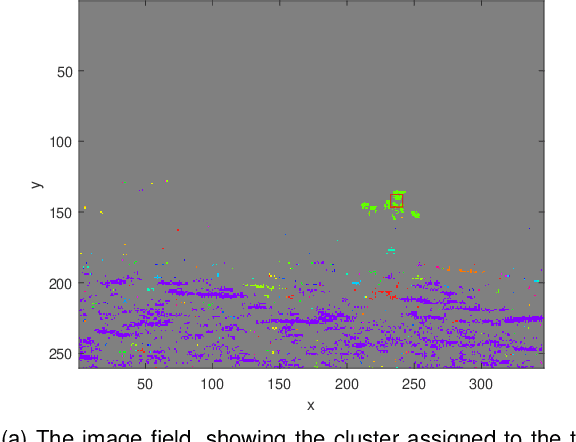
Event cameras are ideal for object tracking applications due to their ability to capture fast-moving objects while mitigating latency and data redundancy. Existing event-based clustering and feature tracking approaches for surveillance and object detection work well in the majority of cases, but fall short in a maritime environment. Our application of maritime vessel detection and tracking requires a process that can identify features and output a confidence score representing the likelihood that the feature was produced by a vessel, which may trigger a subsequent alert or activate a classification system. However, the maritime environment presents unique challenges such as the tendency of waves to produce the majority of events, demanding the majority of computational processing and producing false positive detections. By filtering redundant events and analyzing the movement of each event cluster, we can identify and track vessels while ignoring shorter lived and erratic features such as those produced by waves.
Image quality assessment for determining efficacy and limitations of Super-Resolution Convolutional Neural Network (SRCNN)
May 14, 2019Traditional metrics for evaluating the efficacy of image processing techniques do not lend themselves to understanding the capabilities and limitations of modern image processing methods - particularly those enabled by deep learning. When applying image processing in engineering solutions, a scientist or engineer has a need to justify their design decisions with clear metrics. By applying blind/referenceless image spatial quality (BRISQUE), Structural SIMilarity (SSIM) index scores, and Peak signal-to-noise ratio (PSNR) to images before and after image processing, we can quantify quality improvements in a meaningful way and determine the lowest recoverable image quality for a given method.
Image denoising with generalized Gaussian mixture model patch priors
Jun 11, 2018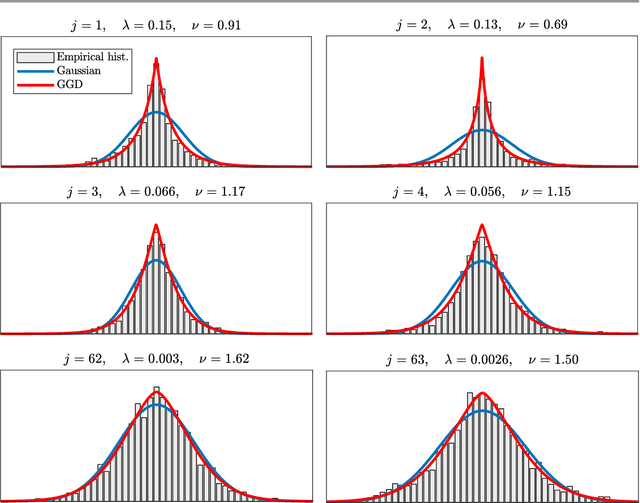

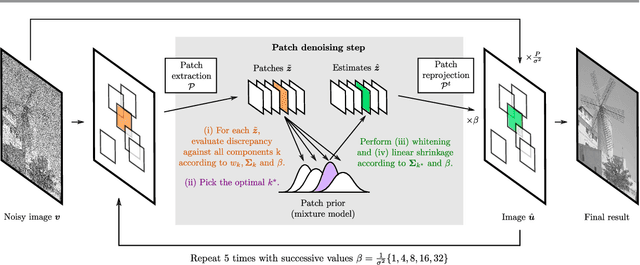
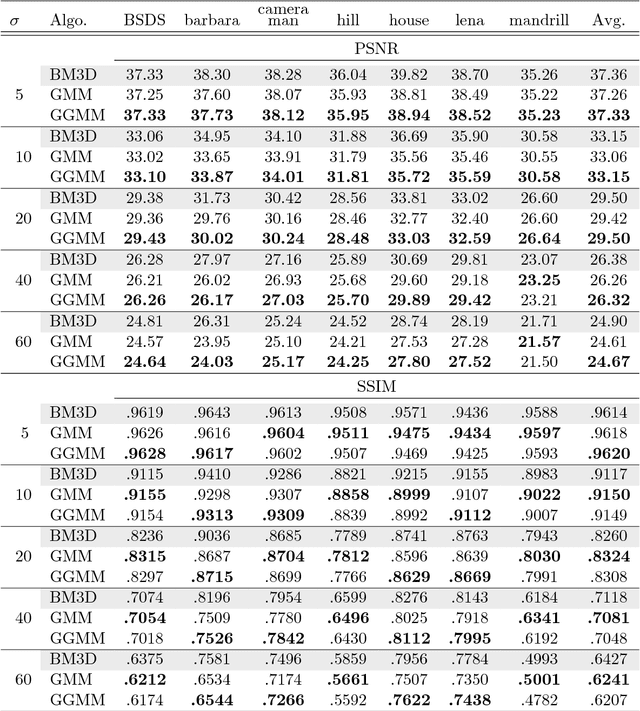
Patch priors have become an important component of image restoration. A powerful approach in this category of restoration algorithms is the popular Expected Patch Log-Likelihood (EPLL) algorithm. EPLL uses a Gaussian mixture model (GMM) prior learned on clean image patches as a way to regularize degraded patches. In this paper, we show that a generalized Gaussian mixture model (GGMM) captures the underlying distribution of patches better than a GMM. Even though GGMM is a powerful prior to combine with EPLL, the non-Gaussianity of its components presents major challenges to be applied to a computationally intensive process of image restoration. Specifically, each patch has to undergo a patch classification step and a shrinkage step. These two steps can be efficiently solved with a GMM prior but are computationally impractical when using a GGMM prior. In this paper, we provide approximations and computational recipes for fast evaluation of these two steps, so that EPLL can embed a GGMM prior on an image with more than tens of thousands of patches. Our main contribution is to analyze the accuracy of our approximations based on thorough theoretical analysis. Our evaluations indicate that the GGMM prior is consistently a better fit formodeling image patch distribution and performs better on average in image denoising task.
Accelerating GMM-based patch priors for image restoration: Three ingredients for a 100$\times$ speed-up
Oct 23, 2017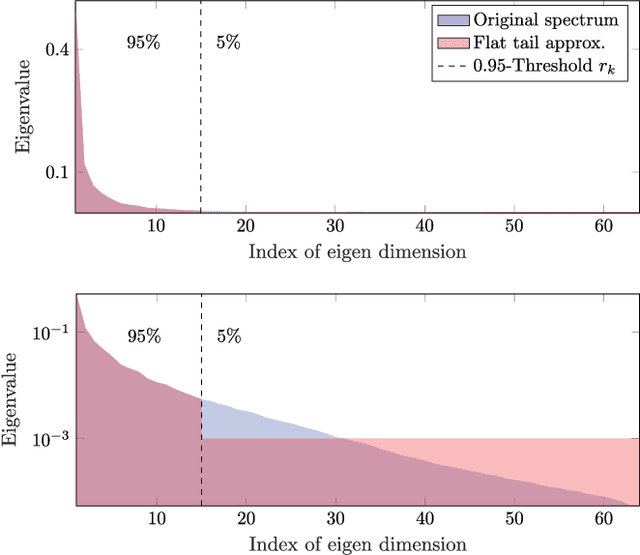
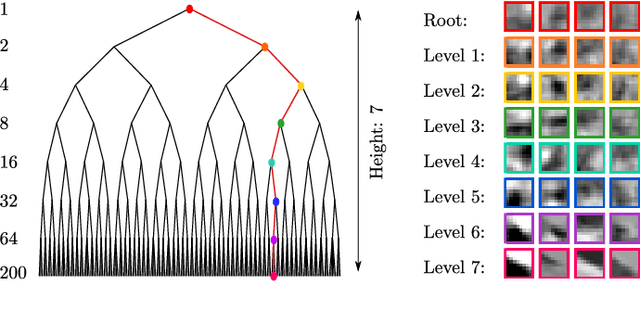
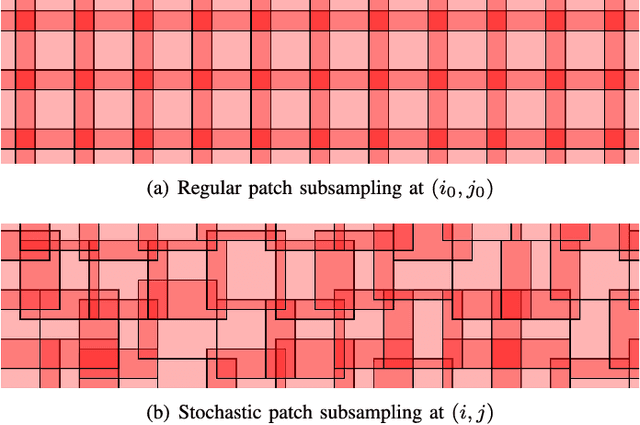
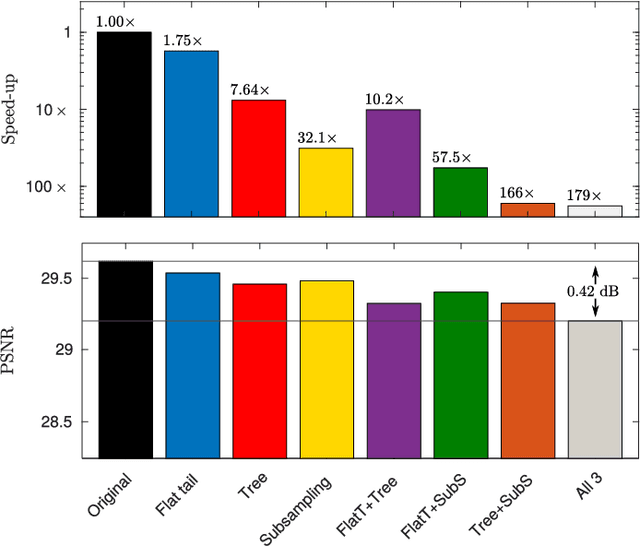
Image restoration methods aim to recover the underlying clean image from corrupted observations. The Expected Patch Log-likelihood (EPLL) algorithm is a powerful image restoration method that uses a Gaussian mixture model (GMM) prior on the patches of natural images. Although it is very effective for restoring images, its high runtime complexity makes EPLL ill-suited for most practical applications. In this paper, we propose three approximations to the original EPLL algorithm. The resulting algorithm, which we call the fast-EPLL (FEPLL), attains a dramatic speed-up of two orders of magnitude over EPLL while incurring a negligible drop in the restored image quality (less than 0.5 dB). We demonstrate the efficacy and versatility of our algorithm on a number of inverse problems such as denoising, deblurring, super-resolution, inpainting and devignetting. To the best of our knowledge, FEPLL is the first algorithm that can competitively restore a 512x512 pixel image in under 0.5s for all the degradations mentioned above without specialized code optimizations such as CPU parallelization or GPU implementation.