 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
EGGS: Eigen-Gap Guided Search Making Subspace Clustering Easy
Jul 27, 2021
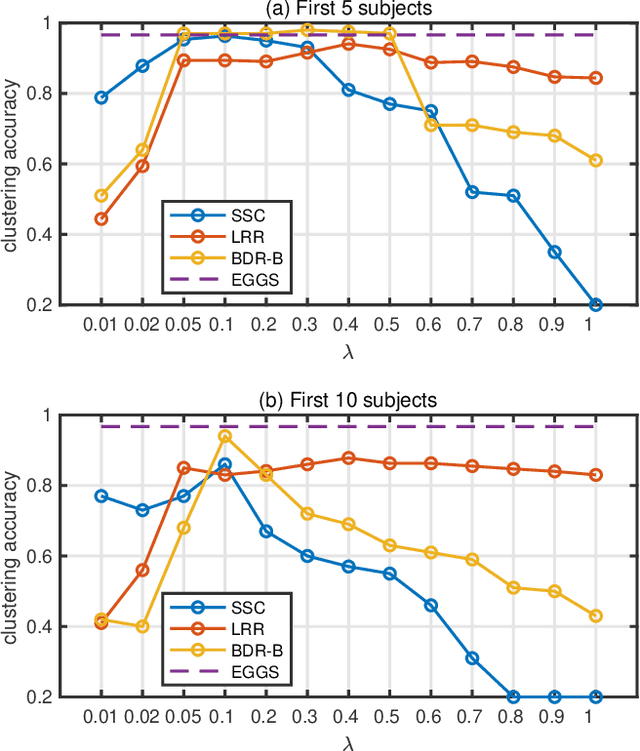
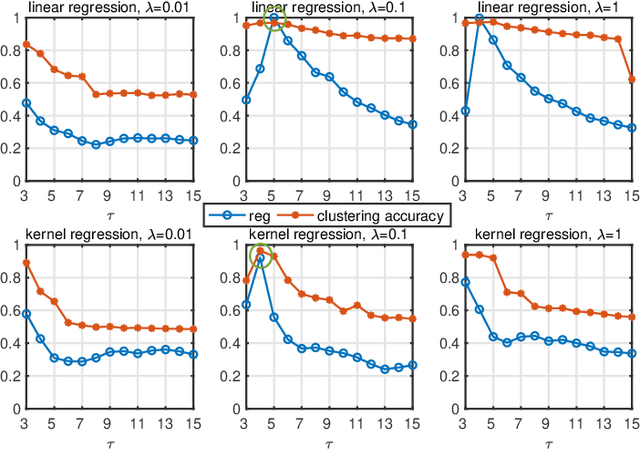
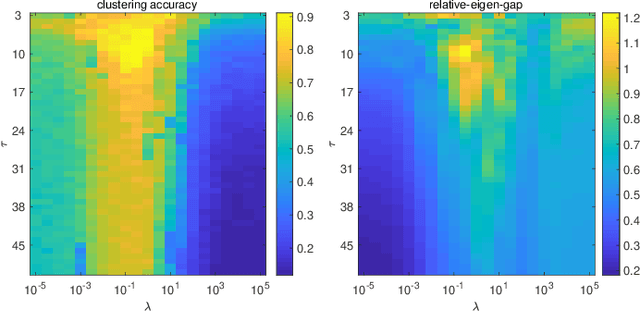
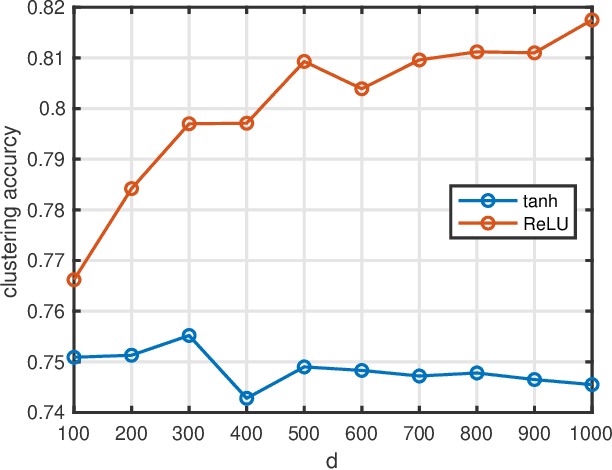
The performance of spectral clustering heavily relies on the quality of affinity matrix. A variety of affinity-matrix-construction methods have been proposed but they have hyper-parameters to determine beforehand, which requires strong experience and lead to difficulty in real applications especially when the inter-cluster similarity is high or/and the dataset is large. On the other hand, we often have to determine to use a linear model or a nonlinear model, which still depends on experience. To solve these two problems, in this paper, we present an eigen-gap guided search method for subspace clustering. The main idea is to find the most reliable affinity matrix among a set of candidates constructed by linear and kernel regressions, where the reliability is quantified by the \textit{relative-eigen-gap} of graph Laplacian defined in this paper. We show, theoretically and numerically, that the Laplacian matrix with a larger relative-eigen-gap often yields a higher clustering accuracy and stability. Our method is able to automatically search the best model and hyper-parameters in a pre-defined space. The search space is very easy to determine and can be arbitrarily large, though a relatively compact search space can reduce the highly unnecessary computation. Our method has high flexibility and convenience in real applications, and also has low computational cost because the affinity matrix is not computed by iterative optimization. We extend the method to large-scale datasets such as MNIST, on which the time cost is less than 90s and the clustering accuracy is state-of-the-art. Extensive experiments of natural image clustering show that our method is more stable, accurate, and efficient than baseline methods.
Deep Denoising of Flash and No-Flash Pairs for Photography in Low-Light Environments
Dec 09, 2020
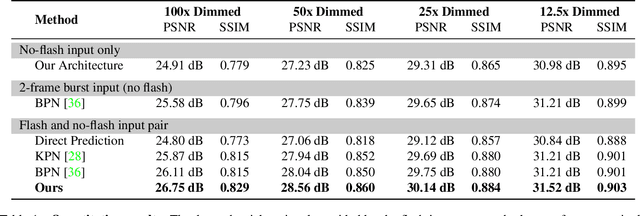
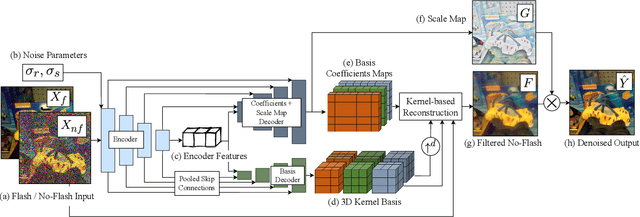
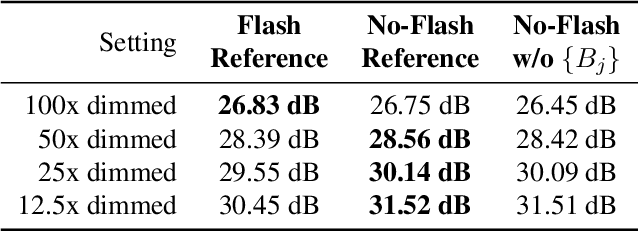
We introduce a neural network-based method to denoise pairs of images taken in quick succession in low-light environments, with and without a flash. Our goal is to produce a high-quality rendering of the scene that preserves the color and mood from the ambient illumination of the noisy no-flash image, while recovering surface texture and detail revealed by the flash. Our network outputs a gain map and a field of kernels, the latter obtained by linearly mixing elements of a per-image low-rank kernel basis. We first apply the kernel field to the no-flash image, and then multiply the result with the gain map to create the final output. We show our network effectively learns to produce high-quality images by combining a smoothed out estimate of the scene's ambient appearance from the no-flash image, with high-frequency albedo details extracted from the flash input. Our experiments show significant improvements over alternative captures without a flash, and baseline denoisers that use flash no-flash pairs. In particular, our method produces images that are both noise-free and contain accurate ambient colors without the sharp shadows or strong specular highlights visible in the flash image.
Semi-Supervised Domain Adaptation with Prototypical Alignment and Consistency Learning
Apr 19, 2021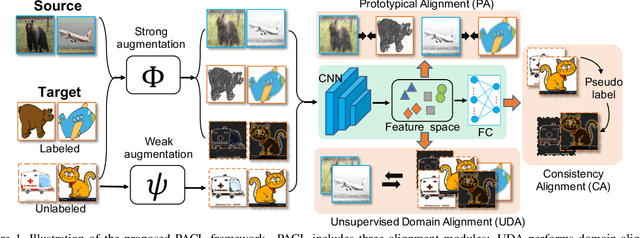
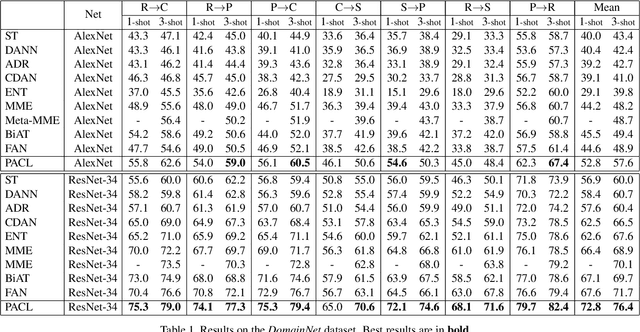
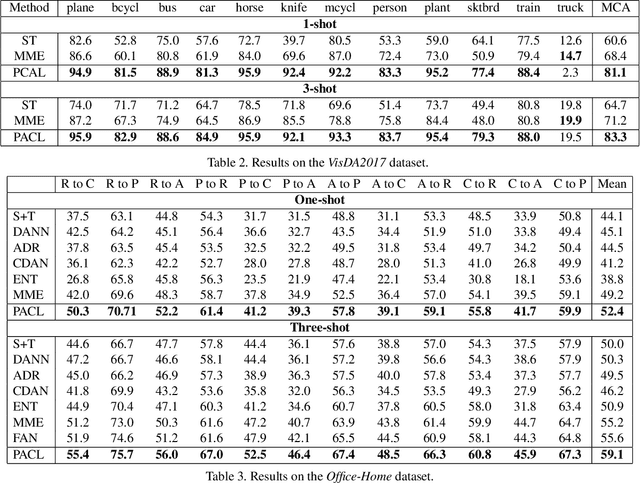
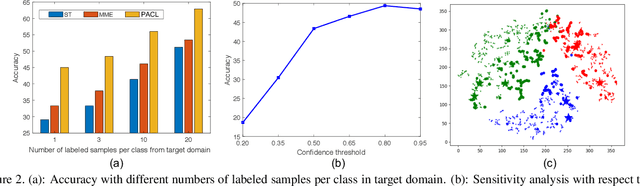
Domain adaptation enhances generalizability of a model across domains with domain shifts. Most research effort has been spent on Unsupervised Domain Adaption (UDA) which trains a model jointly with labeled source data and unlabeled target data. This paper studies how much it can help address domain shifts if we further have a few target samples (e.g., one sample per class) labeled. This is the so-called semi-supervised domain adaptation (SSDA) problem and the few labeled target samples are termed as ``landmarks''. To explore the full potential of landmarks, we incorporate a prototypical alignment (PA) module which calculates a target prototype for each class from the landmarks; source samples are then aligned with the target prototype from the same class. To further alleviate label scarcity, we propose a data augmentation based solution. Specifically, we severely perturb the labeled images, making PA non-trivial to achieve and thus promoting model generalizability. Moreover, we apply consistency learning on unlabeled target images, by perturbing each image with light transformations and strong transformations. Then, the strongly perturbed image can enjoy ``supervised-like'' training using the pseudo label inferred from the lightly perturbed one. Experiments show that the proposed method, though simple, reaches significant performance gains over state-of-the-art methods, and enjoys the flexibility of being able to serve as a plug-and-play component to various existing UDA methods and improve adaptation performance with landmarks provided. Our code is available at \url{https://github.com/kailigo/pacl}.
An Efficient and Small Convolutional Neural Network for Pest Recognition -- ExquisiteNet
Jul 15, 2021
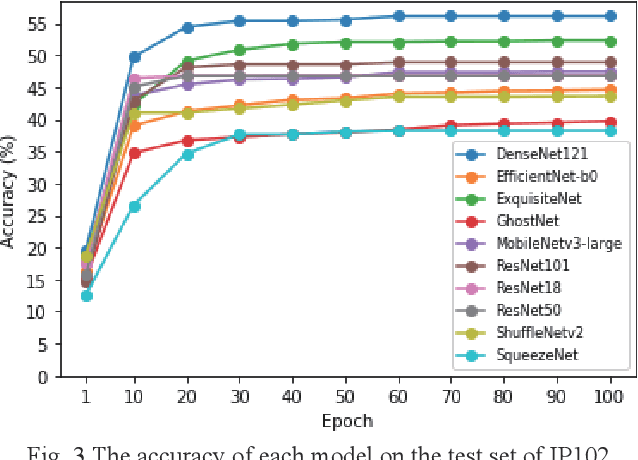

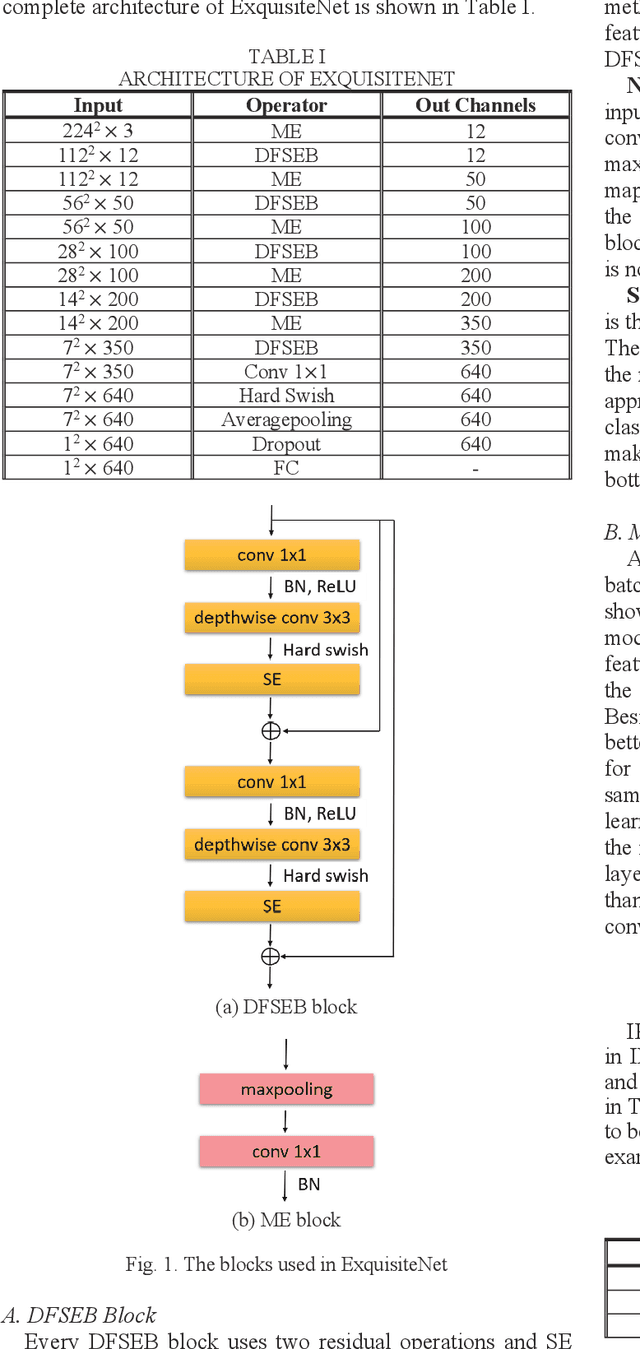
Nowadays, due to the rapid population expansion, food shortage has become a critical issue. In order to stabilizing the food source production, preventing crops from being attacked by pests is very important. In generally, farmers use pesticides to kill pests, however, improperly using pesticides will also kill some insects which is beneficial to crops, such as bees. If the number of bees is too few, the supplement of food in the world will be in short. Besides, excessive pesticides will seriously pollute the environment. Accordingly, farmers need a machine which can automatically recognize the pests. Recently, deep learning is popular because its effectiveness in the field of image classification. In this paper, we propose a small and efficient model called ExquisiteNet to complete the task of recognizing the pests and we expect to apply our model on mobile devices. ExquisiteNet mainly consists of two blocks. One is double fusion with squeeze-and-excitation-bottleneck block (DFSEB block), and the other is max feature expansion block (ME block). ExquisiteNet only has 0.98M parameters and its computing speed is very fast almost the same as SqueezeNet. In order to evaluate our model's performance, we test our model on a benchmark pest dataset called IP102. Compared to many state-of-the-art models, such as ResNet101, ShuffleNetV2, MobileNetV3-large and EfficientNet etc., our model achieves higher accuracy, that is, 52.32% on the test set of IP102 without any data augmentation.
Direct Image to Point Cloud Descriptors Matching for 6-DOF Camera Localization in Dense 3D Point Cloud
Jun 14, 2019
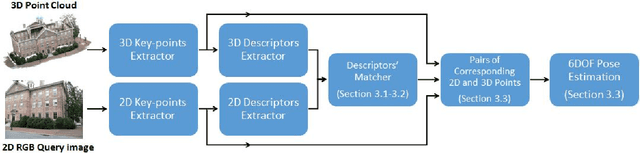
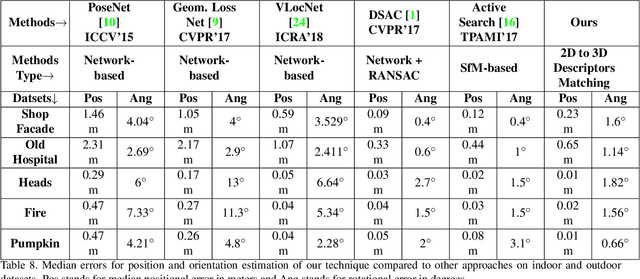
We propose a novel concept to directly match feature descriptors extracted from RGB images, with feature descriptors extracted from 3D point clouds. We use this concept to localize the position and orientation (pose) of the camera of a query image in dense point clouds. We generate a dataset of matching 2D and 3D descriptors, and use it to train a proposed Descriptor-Matcher algorithm. To localize a query image in a point cloud, we extract 2D keypoints and descriptors from the query image. Then the Descriptor-Matcher is used to find the corresponding pairs 2D and 3D keypoints by matching the 2D descriptors with the pre-extracted 3D descriptors of the point cloud. This information is used in a robust pose estimation algorithm to localize the query image in the 3D point cloud. Experiments demonstrate that directly matching 2D and 3D descriptors is not only a viable idea but also achieves competitive accuracy compared to other state-of-the-art approaches for camera pose localization.
Enhancing Remote Sensing Image Retrieval with Triplet Deep Metric Learning Network
Feb 15, 2019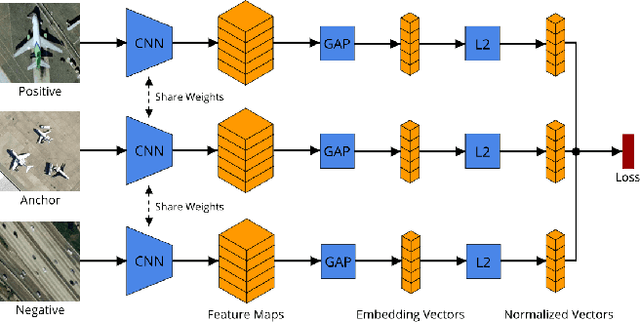

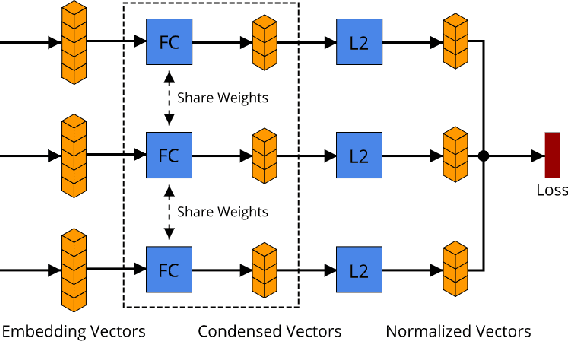
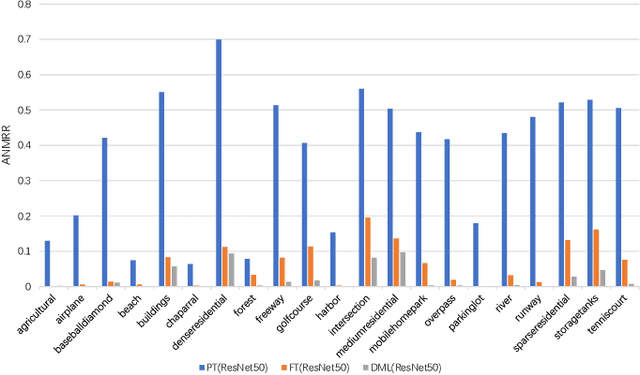
With the rapid growing of remotely sensed imagery data, there is a high demand for effective and efficient image retrieval tools to manage and exploit such data. In this letter, we present a novel content-based remote sensing image retrieval method based on Triplet deep metric learning convolutional neural network (CNN). By constructing a Triplet network with metric learning objective function, we extract the representative features of the images in a semantic space in which images from the same class are close to each other while those from different classes are far apart. In such a semantic space, simple metric measures such as Euclidean distance can be used directly to compare the similarity of images and effectively retrieve images of the same class. We also investigate a supervised and an unsupervised learning methods for reducing the dimensionality of the learned semantic features. We present comprehensive experimental results on two publicly available remote sensing image retrieval datasets and show that our method significantly outperforms state-of-the-art.
A new approach to extracting coronary arteries and detecting stenosis in invasive coronary angiograms
Jan 25, 2021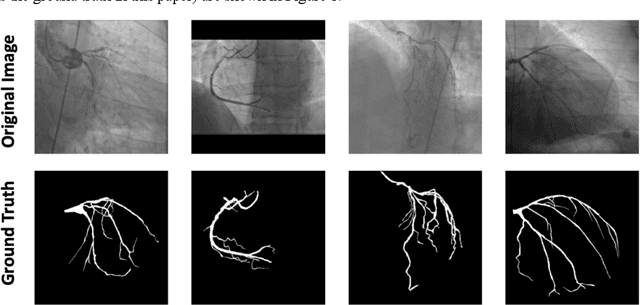

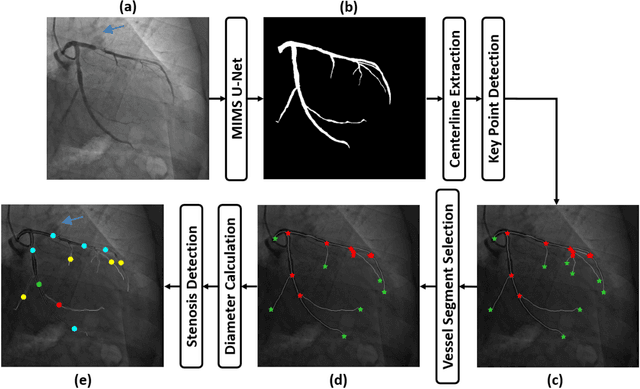
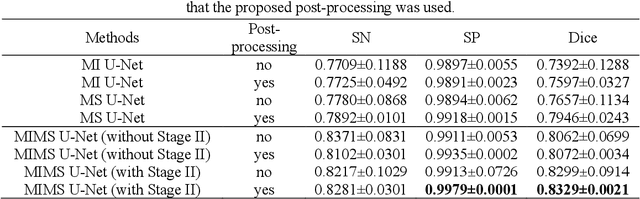
In stable coronary artery disease (CAD), reduction in mortality and/or myocardial infarction with revascularization over medical therapy has not been reliably achieved. Coronary arteries are usually extracted to perform stenosis detection. We aim to develop an automatic algorithm by deep learning to extract coronary arteries from ICAs.In this study, a multi-input and multi-scale (MIMS) U-Net with a two-stage recurrent training strategy was proposed for the automatic vessel segmentation. Incorporating features such as the Inception residual module with depth-wise separable convolutional layers, the proposed model generated a refined prediction map with the following two training stages: (i) Stage I coarsely segmented the major coronary arteries from pre-processed single-channel ICAs and generated the probability map of vessels; (ii) during the Stage II, a three-channel image consisting of the original preprocessed image, a generated probability map, and an edge-enhanced image generated from the preprocessed image was fed to the proposed MIMS U-Net to produce the final segmentation probability map. During the training stage, the probability maps were iteratively and recurrently updated by feeding into the neural network. After segmentation, an arterial stenosis detection algorithm was developed to extract vascular centerlines and calculate arterial diameters to evaluate stenotic level. Experimental results demonstrated that the proposed method achieved an average Dice score of 0.8329, an average sensitivity of 0.8281, and an average specificity of 0.9979 in our dataset with 294 ICAs obtained from 73 patient. Moreover, our stenosis detection algorithm achieved a true positive rate of 0.6668 and a positive predictive value of 0.7043.
Image Fusion via Sparse Regularization with Non-Convex Penalties
May 23, 2019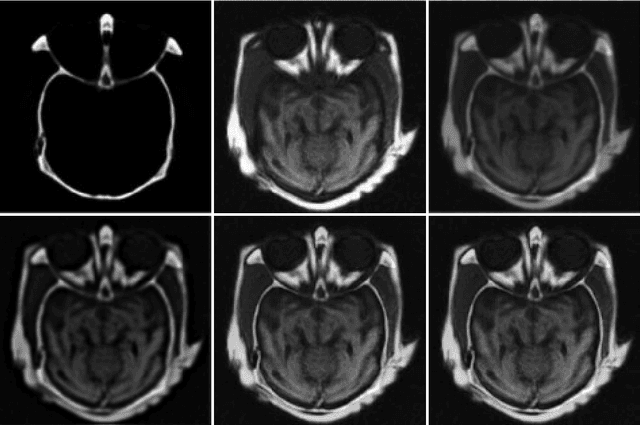
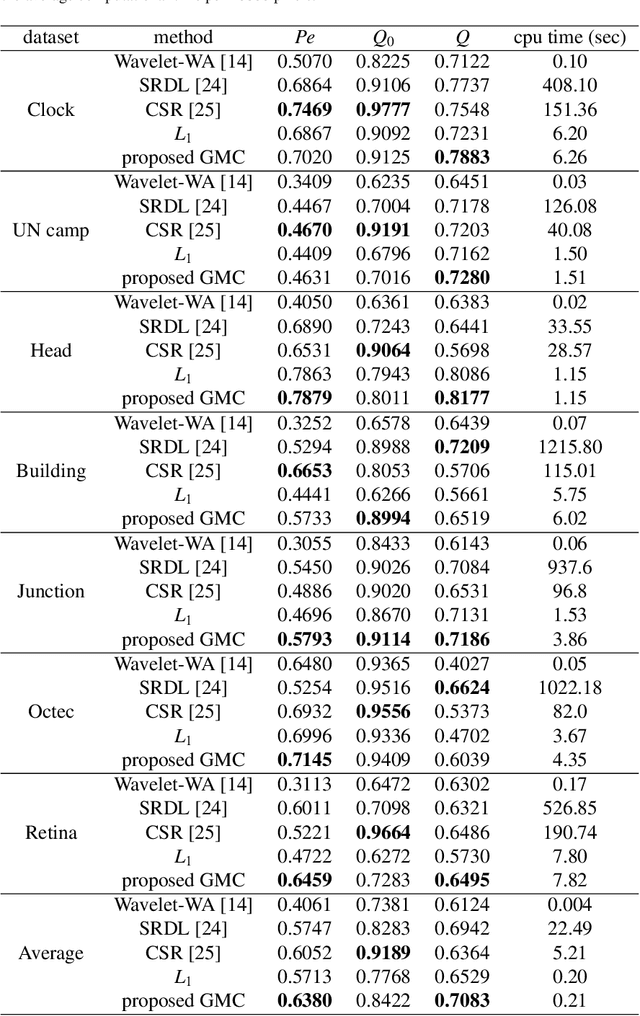

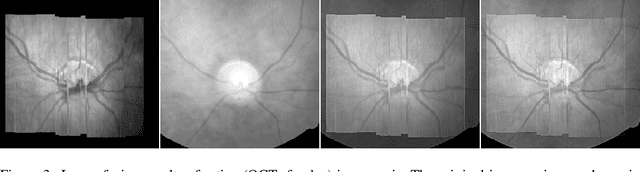
The L1 norm regularized least squares method is often used for finding sparse approximate solutions and is widely used in 1-D signal restoration. Basis pursuit denoising (BPD) performs noise reduction in this way. However, the shortcoming of using L1 norm regularization is the underestimation of the true solution. Recently, a class of non-convex penalties have been proposed to improve this situation. This kind of penalty function is non-convex itself, but preserves the convexity property of the whole cost function. This approach has been confirmed to offer good performance in 1-D signal denoising. This paper demonstrates the aforementioned method to 2-D signals (images) and applies it to multisensor image fusion. The problem is posed as an inverse one and a corresponding cost function is judiciously designed to include two data attachment terms. The whole cost function is proved to be convex upon suitably choosing the non-convex penalty, so that the cost function minimization can be tackled by convex optimization approaches, which comprise simple computations. The performance of the proposed method is benchmarked against a number of state-of-the-art image fusion techniques and superior performance is demonstrated both visually and in terms of various assessment measures.
What makes visual place recognition easy or hard?
Jun 23, 2021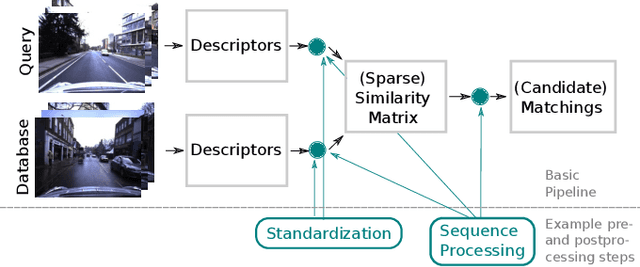

Visual place recognition is a fundamental capability for the localization of mobile robots. It places image retrieval in the practical context of physical agents operating in a physical world. It is an active field of research and many different approaches have been proposed and evaluated in many different experiments. In the following, we argue that due to variations of this practical context and individual design decisions, place recognition experiments are barely comparable across different papers and that there is a variety of properties that can change from one experiment to another. We provide an extensive list of such properties and give examples how they can be used to setup a place recognition experiment easier or harder. This might be interesting for different involved parties: (1) people who just want to select a place recognition approach that is suitable for the properties of their particular task at hand, (2) researchers that look for open research questions and are interested in particularly difficult instances, (3) authors that want to create reproducible papers on this topic, and (4) also reviewers that have the task to identify potential problems in papers under review.
Information-Theoretic Segmentation by Inpainting Error Maximization
Dec 14, 2020
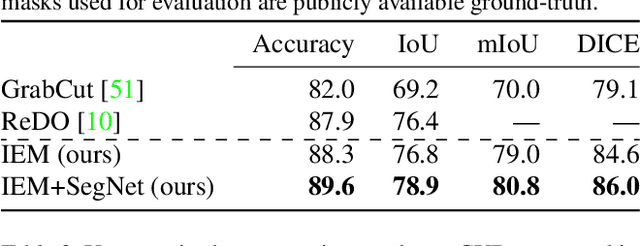
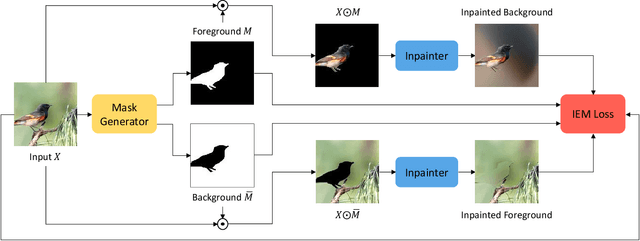
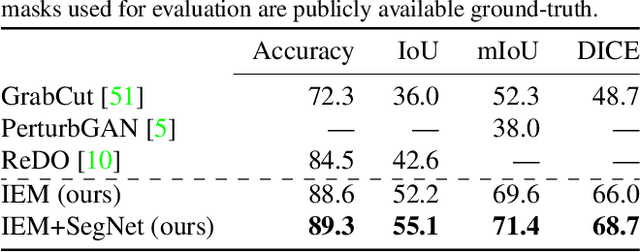
We study image segmentation from an information-theoretic perspective, proposing a novel adversarial method that performs unsupervised segmentation by partitioning images into maximally independent sets. More specifically, we group image pixels into foreground and background, with the goal of minimizing predictability of one set from the other. An easily computed loss drives a greedy search process to maximize inpainting error over these partitions. Our method does not involve training deep networks, is computationally cheap, class-agnostic, and even applicable in isolation to a single unlabeled image. Experiments demonstrate that it achieves a new state-of-the-art in unsupervised segmentation quality, while being substantially faster and more general than competing approaches.