 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnnotation-Informed Block-Sparse Bayesian Modeling for cis-Expression Prediction
May 30, 2026Genotype-based cis-expression prediction depends on accurately modeling local regulatory architecture. We present block-sparse Bayesian sparse linear mixed model (bsBSLMM), an extension of Bayesian sparse linear mixed model (BSLMM) that incorporates linkage disequilibrium (LD)-block spike-and-slab sparsity and a transcription start site (TSS)-informed SNP inclusion prior. Across 23,098 genes from GEUVADIS European-ancestry lymphoblastoid cell lines, bsBSLMM retained more predictable genes than BSLMM, LASSO, BLUP, TIGAR elastic net, and TIGAR Dirichlet-process regression under matched evaluation criteria. Compared with BSLMM, bsBSLMM improved held-out prediction performance for most shared genes, with gains driven primarily by LD-block sparsity and further enhanced by the TSS-informed prior. Variants selected by bsBSLMM showed stronger enrichment in GM12878 DNase and H3K27ac regulatory regions than variants selected by BSLMM. In transcriptome-wide association study (TWAS) analysis, bsBSLMM recovered established inflammatory bowel disease signals, including IL23R, and identified additional genome-wide significant genes not detected by BSLMM. Independent validation in the Louisiana Osteoporosis Study reproduced the increased prediction yield across ancestries and recovered biologically relevant bone mineral density pathways in downstream TWAS and gene set enrichment analyses. These results demonstrate that incorporating LD-block structure and biologically informed SNP priors improves cis-expression prediction and enhances downstream TWAS discovery.
Learning-Based Multi-Criteria Decision Making Model for Sawmill Location Problems
Apr 05, 2026Strategically locating a sawmill is vital for enhancing the efficiency, profitability, and sustainability of timber supply chains. Our study proposes a Learning-Based Multi-Criteria Decision-Making (LB-MCDM) framework that integrates machine learning (ML) with GIS-based spatial location analysis via MCDM. The proposed framework provides a data-driven, unbiased, and replicable approach to assessing site suitability. We demonstrate the utility of the proposed model through a case study in Mississippi (MS). We apply five ML algorithms (Random Forest Classifier, Support Vector Classifier, XGBoost Classifier, Logistic Regression, and K-Nearest Neighbors Classifier) to identify the most suitable sawmill locations in Mississippi. Among these models, the Random Forest Classifier achieved the highest performance. We use the SHAP (SHapley Additive exPlanations) technique to determine the relative importance of each criterion, revealing the Supply-Demand Ratio, a composite feature that reflects local market competition dynamics, as the most influential factor, followed by Road, Rail Line and Urban Area Distance. The validation of suitability maps generated by our LB-MCDM model suggests that 10-11% of the MS landscape is highly suitable for sawmill location.
GenoBERT: A Language Model for Accurate Genotype Imputation
Mar 31, 2026Genotype imputation enables dense variant coverage for genome-wide association and risk-prediction studies, yet conventional reference-panel methods remain limited by ancestry bias and reduced rare-variant accuracy. We present Genotype Bidirectional Encoder Representations from Transformers (GenoBERT), a transformer-based, reference-free framework that tokenizes phased genotypes and uses a self-attention mechanism to capture both short- and long-range linkage disequilibrium (LD) dependencies. Benchmarking on two independent datasets including the Louisiana Osteoporosis Study (LOS) and the 1000 Genomes Project (1KGP) across ancestry groups and multiple genotype missingness levels (5-50%) shows that GenoBERT achieves the highest overall accuracy compared to four baseline methods (Beagle5.4, SCDA, BiU-Net, and STICI). At practical sparsity levels (up to 25% missing), GenoBERT attains high overall imputation accuracy ($r^2 approx 0.98$) across datasets, and maintains robust performance ($r^2 > 0.90$) even at 50% missingness. Experimental results across different ancestries confirm consistent gains across datasets, with resilience to small sample sizes and weak LD. A 128-SNP (single-nucleotide polymorphism) context window (approximately 100 Kb) is validated through LD-decay analyses as sufficient to capture local correlation structures. By eliminating reference-panel dependence while preserving high accuracy, GenoBERT provides a scalable and robust solution for genotype imputation and a foundation for downstream genomic modeling.
Project Imaging-X: A Survey of 1000+ Open-Access Medical Imaging Datasets for Foundation Model Development
Mar 29, 2026Foundation models have demonstrated remarkable success across diverse domains and tasks, primarily due to the thrive of large-scale, diverse, and high-quality datasets. However, in the field of medical imaging, the curation and assembling of such medical datasets are highly challenging due to the reliance on clinical expertise and strict ethical and privacy constraints, resulting in a scarcity of large-scale unified medical datasets and hindering the development of powerful medical foundation models. In this work, we present the largest survey to date of medical image datasets, covering over 1,000 open-access datasets with a systematic catalog of their modalities, tasks, anatomies, annotations, limitations, and potential for integration. Our analysis exposes a landscape that is modest in scale, fragmented across narrowly scoped tasks, and unevenly distributed across organs and modalities, which in turn limits the utility of existing medical image datasets for developing versatile and robust medical foundation models. To turn fragmentation into scale, we propose a metadata-driven fusion paradigm (MDFP) that integrates public datasets with shared modalities or tasks, thereby transforming multiple small data silos into larger, more coherent resources. Building on MDFP, we release an interactive discovery portal that enables end-to-end, automated medical image dataset integration, and compile all surveyed datasets into a unified, structured table that clearly summarizes their key characteristics and provides reference links, offering the community an accessible and comprehensive repository. By charting the current terrain and offering a principled path to dataset consolidation, our survey provides a practical roadmap for scaling medical imaging corpora, supporting faster data discovery, more principled dataset creation, and more capable medical foundation models.
FUMO: Prior-Modulated Diffusion for Single Image Reflection Removal
Mar 19, 2026Single image reflection removal (SIRR) is challenging in real scenes, where reflection strength varies spatially and reflection patterns are tightly entangled with transmission structures. This paper presents a diffusion model with prior modulation framework (FUMO) that introduces explicit guidance signals to improve spatial controllability and structural faithfulness. Two priors are extracted directly from the mixed image, an intensity prior that estimates spatial reflection severity and a high-frequency prior that captures detail-sensitive responses via multi-scale residual aggregation. We propose a coarse-to-fine training paradigm. In the first stage, these cues are combined to gate the conditional residual injections, focusing the conditioning on regions that are both reflection-dominant and structure-sensitive. In the second stage, a fine-grained refinement network corrects local misalignment and sharpens fine details in the image space. Experiments conducted on both standard benchmarks and challenging images in the wild demonstrate competitive quantitative results and consistently improved perceptual quality. The code is released at https://github.com/Lucious-Desmon/FUMO.
A Survey of Scientific Large Language Models: From Data Foundations to Agent Frontiers
Aug 28, 2025



Scientific Large Language Models (Sci-LLMs) are transforming how knowledge is represented, integrated, and applied in scientific research, yet their progress is shaped by the complex nature of scientific data. This survey presents a comprehensive, data-centric synthesis that reframes the development of Sci-LLMs as a co-evolution between models and their underlying data substrate. We formulate a unified taxonomy of scientific data and a hierarchical model of scientific knowledge, emphasizing the multimodal, cross-scale, and domain-specific challenges that differentiate scientific corpora from general natural language processing datasets. We systematically review recent Sci-LLMs, from general-purpose foundations to specialized models across diverse scientific disciplines, alongside an extensive analysis of over 270 pre-/post-training datasets, showing why Sci-LLMs pose distinct demands -- heterogeneous, multi-scale, uncertainty-laden corpora that require representations preserving domain invariance and enabling cross-modal reasoning. On evaluation, we examine over 190 benchmark datasets and trace a shift from static exams toward process- and discovery-oriented assessments with advanced evaluation protocols. These data-centric analyses highlight persistent issues in scientific data development and discuss emerging solutions involving semi-automated annotation pipelines and expert validation. Finally, we outline a paradigm shift toward closed-loop systems where autonomous agents based on Sci-LLMs actively experiment, validate, and contribute to a living, evolving knowledge base. Collectively, this work provides a roadmap for building trustworthy, continually evolving artificial intelligence (AI) systems that function as a true partner in accelerating scientific discovery.
Towards Holistic Visual Quality Assessment of AI-Generated Videos: A LLM-Based Multi-Dimensional Evaluation Model
Jun 05, 2025



The development of AI-Generated Video (AIGV) technology has been remarkable in recent years, significantly transforming the paradigm of video content production. However, AIGVs still suffer from noticeable visual quality defects, such as noise, blurriness, frame jitter and low dynamic degree, which severely impact the user's viewing experience. Therefore, an effective automatic visual quality assessment is of great importance for AIGV content regulation and generative model improvement. In this work, we decompose the visual quality of AIGVs into three dimensions: technical quality, motion quality, and video semantics. For each dimension, we design corresponding encoder to achieve effective feature representation. Moreover, considering the outstanding performance of large language models (LLMs) in various vision and language tasks, we introduce a LLM as the quality regression module. To better enable the LLM to establish reasoning associations between multi-dimensional features and visual quality, we propose a specially designed multi-modal prompt engineering framework. Additionally, we incorporate LoRA fine-tuning technology during the training phase, allowing the LLM to better adapt to specific tasks. Our proposed method achieved \textbf{second place} in the NTIRE 2025 Quality Assessment of AI-Generated Content Challenge: Track 2 AI Generated video, demonstrating its effectiveness. Codes can be obtained at https://github.com/QiZelu/AIGVEval.
DAPE: Dual-Stage Parameter-Efficient Fine-Tuning for Consistent Video Editing with Diffusion Models
May 11, 2025



Video generation based on diffusion models presents a challenging multimodal task, with video editing emerging as a pivotal direction in this field. Recent video editing approaches primarily fall into two categories: training-required and training-free methods. While training-based methods incur high computational costs, training-free alternatives often yield suboptimal performance. To address these limitations, we propose DAPE, a high-quality yet cost-effective two-stage parameter-efficient fine-tuning (PEFT) framework for video editing. In the first stage, we design an efficient norm-tuning method to enhance temporal consistency in generated videos. The second stage introduces a vision-friendly adapter to improve visual quality. Additionally, we identify critical shortcomings in existing benchmarks, including limited category diversity, imbalanced object distribution, and inconsistent frame counts. To mitigate these issues, we curate a large dataset benchmark comprising 232 videos with rich annotations and 6 editing prompts, enabling objective and comprehensive evaluation of advanced methods. Extensive experiments on existing datasets (BalanceCC, LOVEU-TGVE, RAVE) and our proposed benchmark demonstrate that DAPE significantly improves temporal coherence and text-video alignment while outperforming previous state-of-the-art approaches.
Learning-Based Multi-Criteria Decision Model for Site Selection Problems
Apr 05, 2025



Strategically locating sawmills is critical for the efficiency, profitability, and sustainability of timber supply chains, yet it involves a series of complex decision-making affected by various factors, such as proximity to resources and markets, proximity to roads and rail lines, distance from the urban area, slope, labor market, and existing sawmill data. Although conventional Multi-Criteria Decision-Making (MCDM) approaches utilize these factors while locating facilities, they are susceptible to bias since they rely heavily on expert opinions to determine the relative factor weights. Machine learning (ML) models provide an objective, data-driven alternative for site selection that derives these weights directly from the patterns in large datasets without requiring subjective weighting. Additionally, ML models autonomously identify critical features, eliminating the need for subjective feature selection. In this study, we propose integrated ML and MCDM methods and showcase the utility of this integrated model to improve sawmill location decisions via a case study in Mississippi. This integrated model is flexible and applicable to site selection problems across various industries.
S2MS: Self-Supervised Learning Driven Multi-Spectral CT Image Enhancement
Jan 26, 2022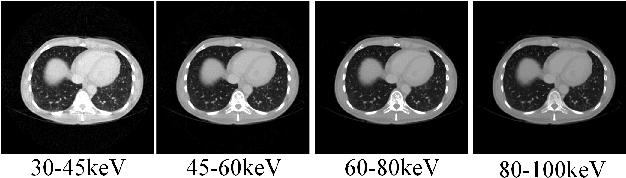
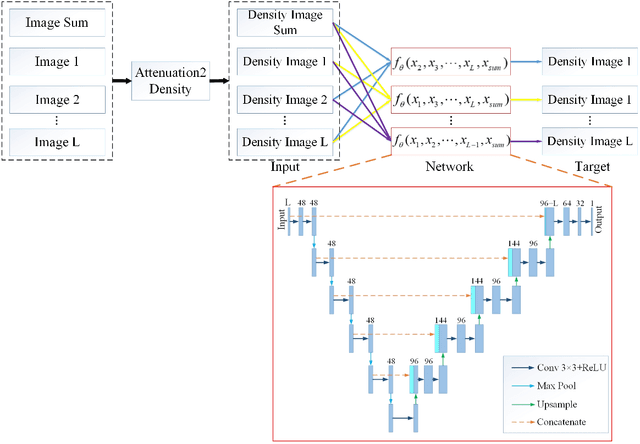
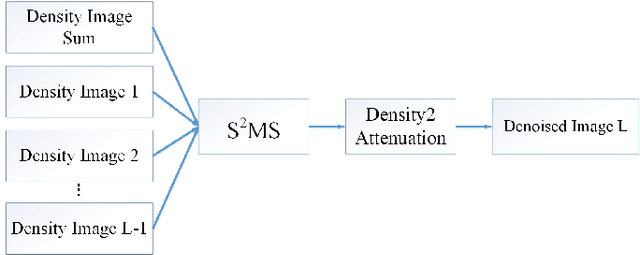
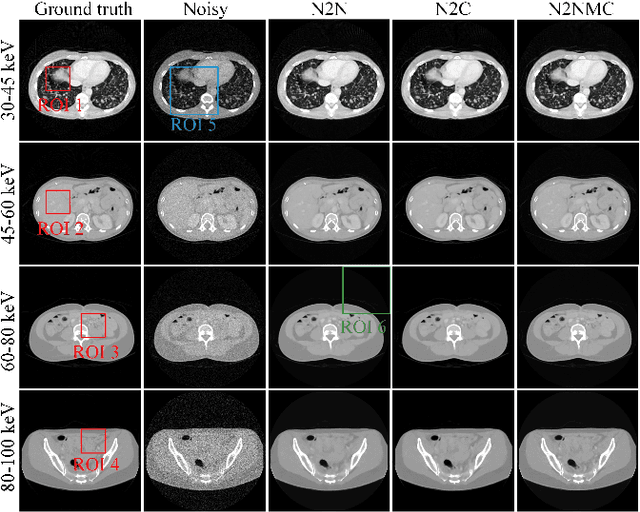
Photon counting spectral CT (PCCT) can produce reconstructed attenuation maps in different energy channels, reflecting energy properties of the scanned object. Due to the limited photon numbers and the non-ideal detector response of each energy channel, the reconstructed images usually contain much noise. With the development of Deep Learning (DL) technique, different kinds of DL-based models have been proposed for noise reduction. However, most of the models require clean data set as the training labels, which are not always available in medical imaging field. Inspiring by the similarities of each channel's reconstructed image, we proposed a self-supervised learning based PCCT image enhancement framework via multi-spectral channels (S2MS). In S2MS framework, both the input and output labels are noisy images. Specifically, one single channel image was used as output while images of other single channels and channel-sum image were used as input to train the network, which can fully use the spectral data information without extra cost. The simulation results based on the AAPM Low-dose CT Challenge database showed that the proposed S2MS model can suppress the noise and preserve details more effectively in comparison with the traditional DL models, which has potential to improve the image quality of PCCT in clinical applications.