 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Lightweight Pyramid Networks for Image Deraining
May 16, 2018

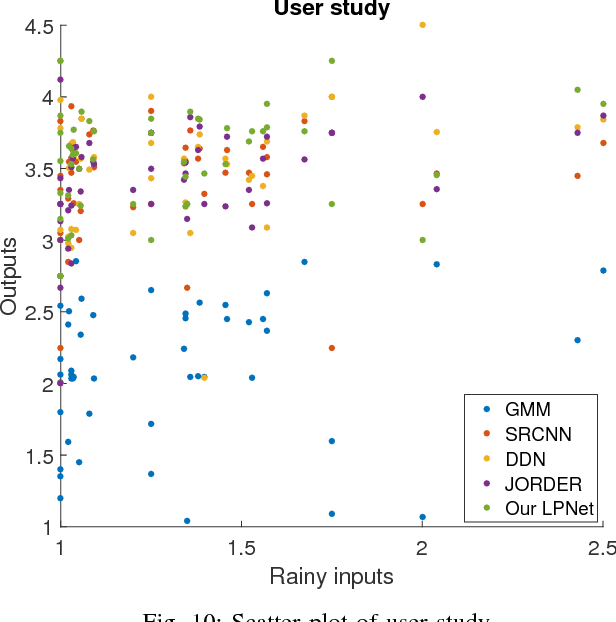

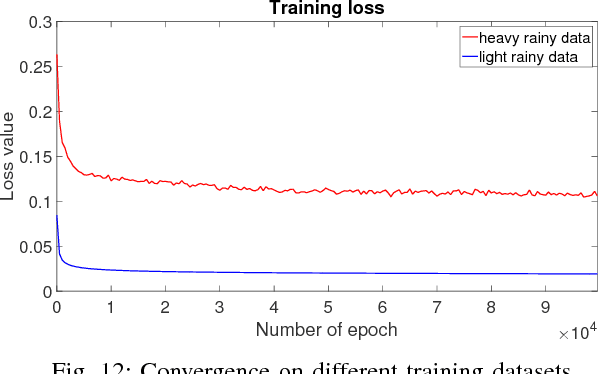
Existing deep convolutional neural networks have found major success in image deraining, but at the expense of an enormous number of parameters. This limits their potential application, for example in mobile devices. In this paper, we propose a lightweight pyramid of networks (LPNet) for single image deraining. Instead of designing a complex network structures, we use domain-specific knowledge to simplify the learning process. Specifically, we find that by introducing the mature Gaussian-Laplacian image pyramid decomposition technology to the neural network, the learning problem at each pyramid level is greatly simplified and can be handled by a relatively shallow network with few parameters. We adopt recursive and residual network structures to build the proposed LPNet, which has less than 8K parameters while still achieving state-of-the-art performance on rain removal. We also discuss the potential value of LPNet for other low- and high-level vision tasks.
Modulating Image Restoration with Continual Levels via Adaptive Feature Modification Layers
Apr 19, 2019
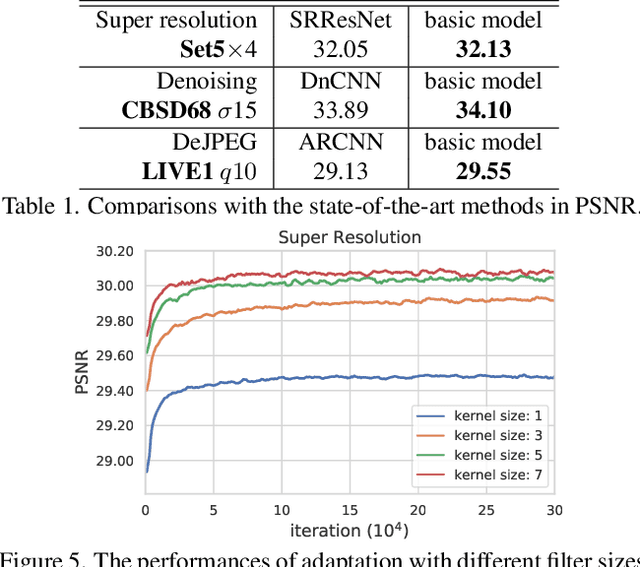

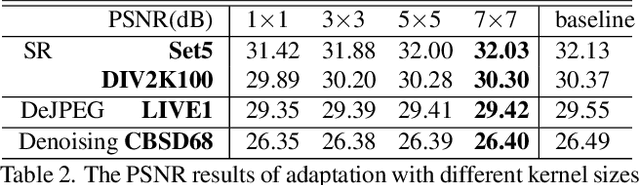
In image restoration tasks, like denoising and super resolution, continual modulation of restoration levels is of great importance for real-world applications, but has failed most of existing deep learning based image restoration methods. Learning from discrete and fixed restoration levels, deep models cannot be easily generalized to data of continuous and unseen levels. This topic is rarely touched in literature, due to the difficulty of modulating well-trained models with certain hyper-parameters. We make a step forward by proposing a unified CNN framework that consists of few additional parameters than a single-level model yet could handle arbitrary restoration levels between a start and an end level. The additional module, namely AdaFM layer, performs channel-wise feature modification, and can adapt a model to another restoration level with high accuracy. By simply tweaking an interpolation coefficient, the intermediate model - AdaFM-Net could generate smooth and continuous restoration effects without artifacts. Extensive experiments on three image restoration tasks demonstrate the effectiveness of both model training and modulation testing. Besides, we carefully investigate the properties of AdaFM layers, providing a detailed guidance on the usage of the proposed method.
Local Relation Networks for Image Recognition
Apr 25, 2019
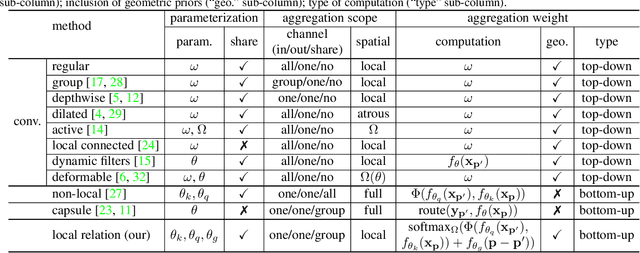
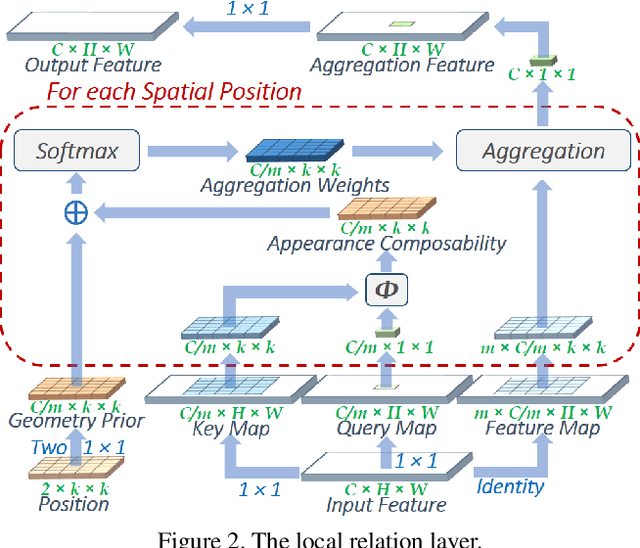
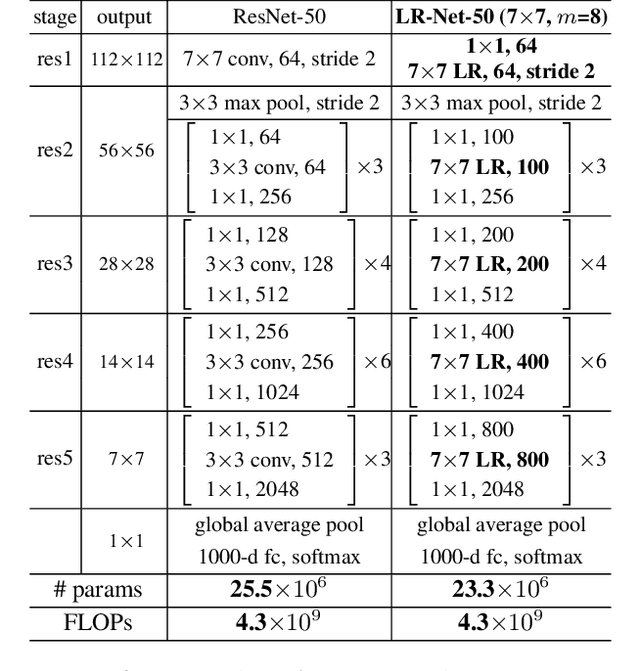
The convolution layer has been the dominant feature extractor in computer vision for years. However, the spatial aggregation in convolution is basically a pattern matching process that applies fixed filters which are inefficient at modeling visual elements with varying spatial distributions. This paper presents a new image feature extractor, called the local relation layer, that adaptively determines aggregation weights based on the compositional relationship of local pixel pairs. With this relational approach, it can composite visual elements into higher-level entities in a more efficient manner that benefits semantic inference. A network built with local relation layers, called the Local Relation Network (LR-Net), is found to provide greater modeling capacity than its counterpart built with regular convolution on large-scale recognition tasks such as ImageNet classification.
Single-pixel diffuser camera
May 06, 2021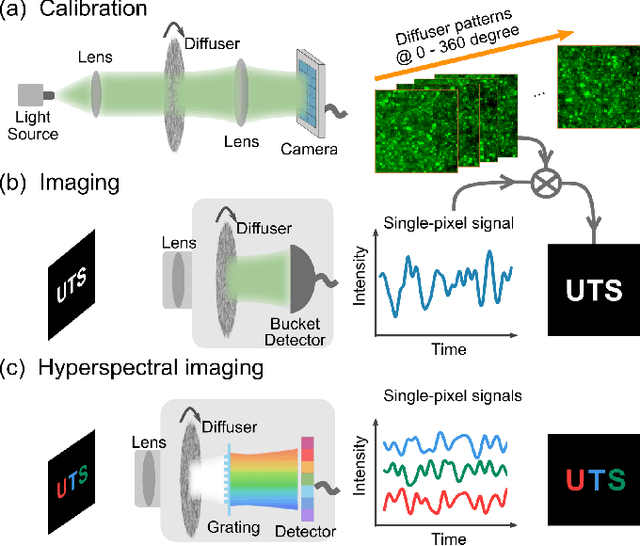
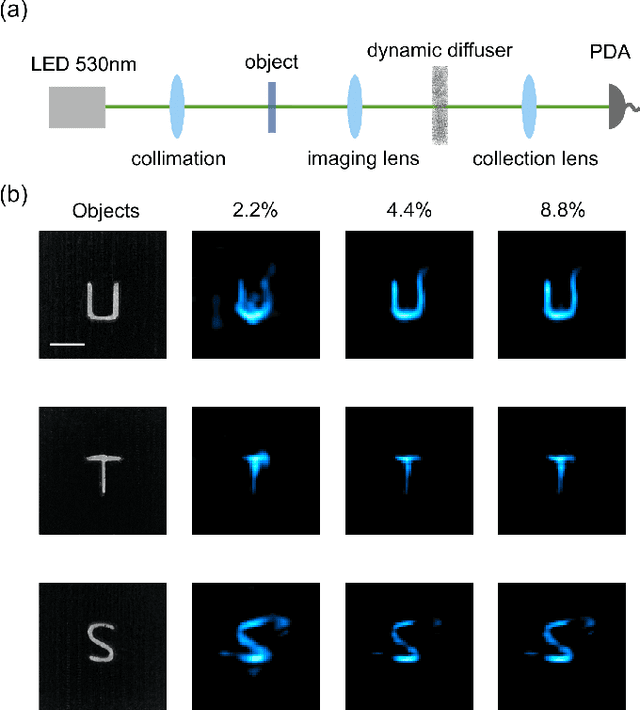
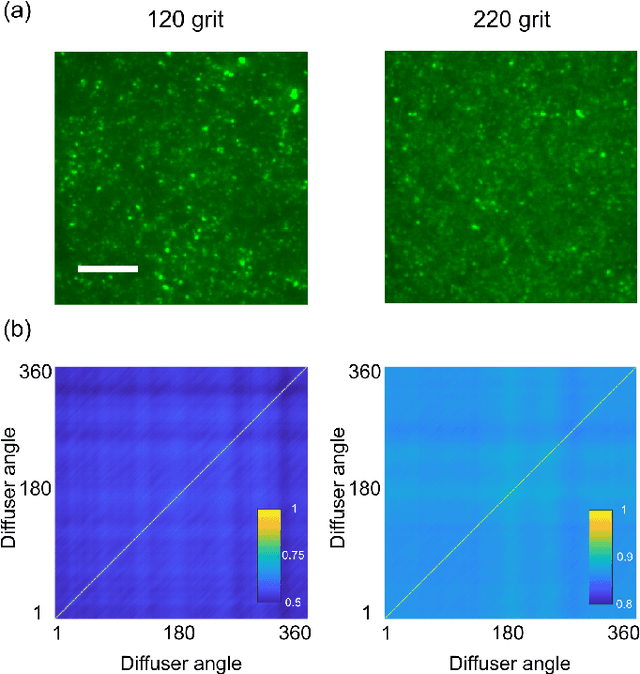
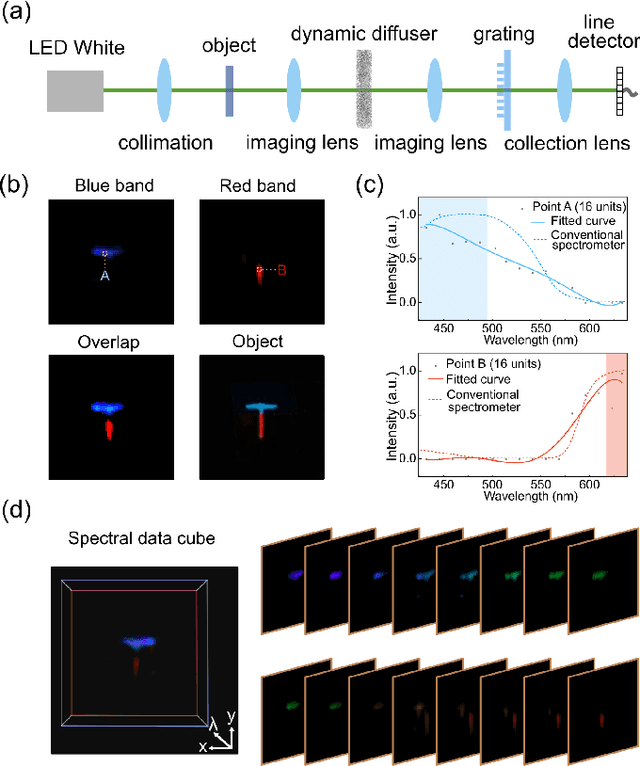
We present a compact, diffuser-assisted, single-pixel computational camera. A rotating ground glass diffuser is adopted, in preference to a commonly used digital micro-mirror device (DMD), to encode a two-dimensional (2D) image into single-pixel signals. We retrieve images with an 8.8% sampling ratio after the calibration of the pseudo-random pattern of the diffuser under incoherent illumination. Furthermore, we demonstrate hyperspectral imaging with line array detection by adding a diffraction grating. The implementation results in a cost-effective single-pixel camera for high-dimensional imaging, with potential for imaging in non-visible wavebands.
All unconstrained strongly convex problems are weakly simplicial
Jun 24, 2021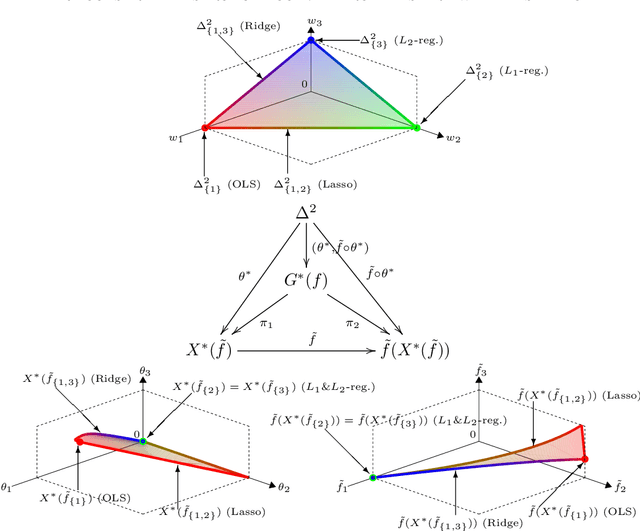
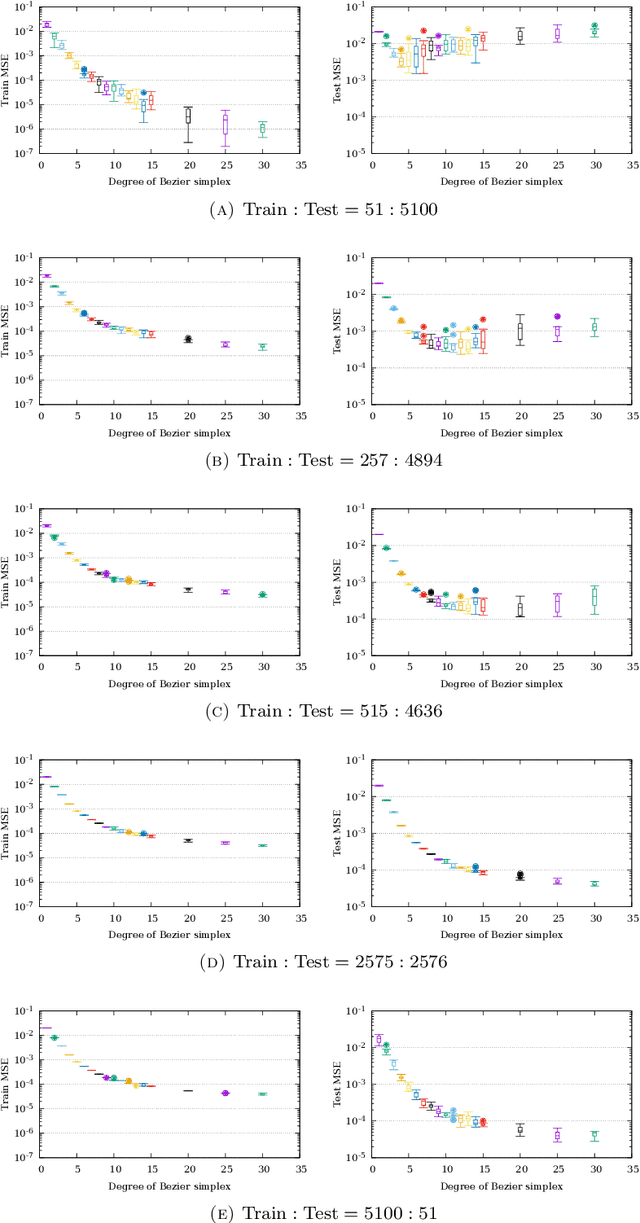
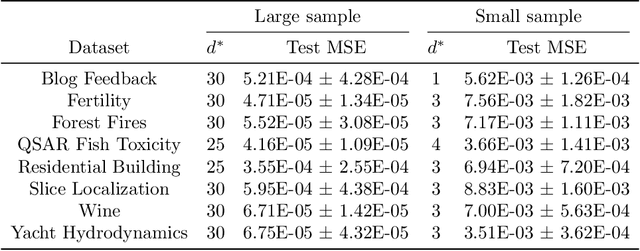
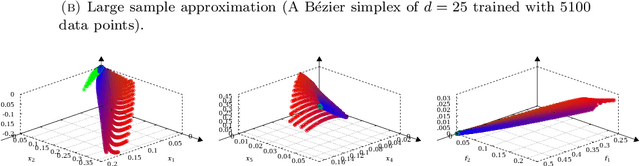
A multi-objective optimization problem is $C^r$ weakly simplicial if there exists a $C^r$ surjection from a simplex onto the Pareto set/front such that the image of each subsimplex is the Pareto set/front of a subproblem, where $0\leq r\leq \infty$. This property is helpful to compute a parametric-surface approximation of the entire Pareto set and Pareto front. It is known that all unconstrained strongly convex $C^r$ problems are $C^{r-1}$ weakly simplicial for $1\leq r \leq \infty$. In this paper, we show that all unconstrained strongly convex problems are $C^0$ weakly simplicial. The usefulness of this theorem is demonstrated in a sparse modeling application: we reformulate the elastic net as a non-differentiable multi-objective strongly convex problem and approximate its Pareto set (the set of all trained models with different hyper-parameters) and Pareto front (the set of performance metrics of the trained models) by using a B\'ezier simplex fitting method, which accelerates hyper-parameter search.
DFM: A Performance Baseline for Deep Feature Matching
Jun 14, 2021
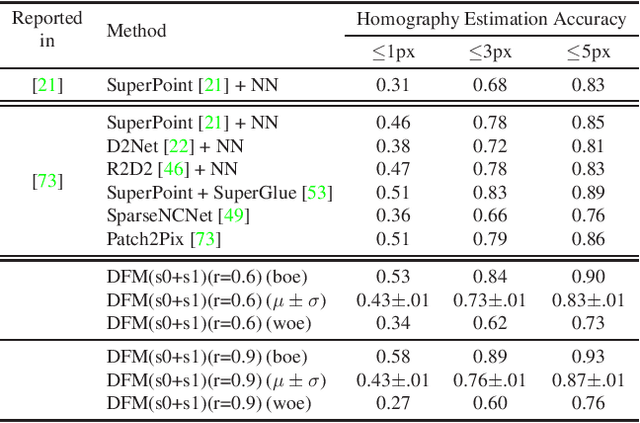
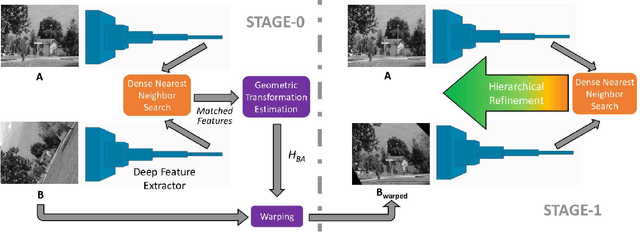

A novel image matching method is proposed that utilizes learned features extracted by an off-the-shelf deep neural network to obtain a promising performance. The proposed method uses pre-trained VGG architecture as a feature extractor and does not require any additional training specific to improve matching. Inspired by well-established concepts in the psychology area, such as the Mental Rotation paradigm, an initial warping is performed as a result of a preliminary geometric transformation estimate. These estimates are simply based on dense matching of nearest neighbors at the terminal layer of VGG network outputs of the images to be matched. After this initial alignment, the same approach is repeated again between reference and aligned images in a hierarchical manner to reach a good localization and matching performance. Our algorithm achieves 0.57 and 0.80 overall scores in terms of Mean Matching Accuracy (MMA) for 1 pixel and 2 pixels thresholds respectively on Hpatches dataset, which indicates a better performance than the state-of-the-art.
SegVisRL: Visuomotor Development for a Lunar Rover for Hazard Avoidance using Camera Images
Mar 26, 2021
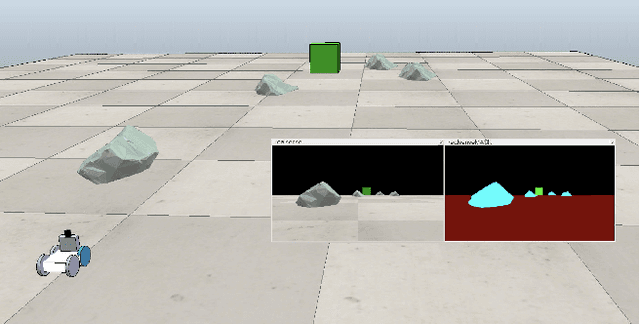
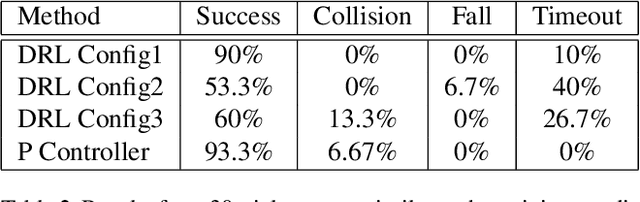
The visuomotor system of any animal is critical for its survival, and the development of a complex one within humans is large factor in our success as a species on Earth. This system is an essential part of our ability to adapt to our environment. We use this system continuously throughout the day, when picking something up, or walking around while avoiding bumping into objects. Equipping robots with such capabilities will help produce more intelligent locomotion with the ability to more easily understand their surroundings and to move safely. In particular, such capabilities are desirable for traversing the lunar surface, as it is full of hazardous obstacles, such as rocks. These obstacles need to be identified and avoided in real time. This paper seeks to demonstrate the development of a visuomotor system within a robot for navigation and obstacle avoidance, with complex rock shaped objects representing hazards. Our approach uses deep reinforcement learning with only image data. In this paper, we compare the results from several neural network architectures and a preprocessing methodology which includes producing a segmented image and downsampling.
RECON: Rapid Exploration for Open-World Navigation with Latent Goal Models
Apr 12, 2021
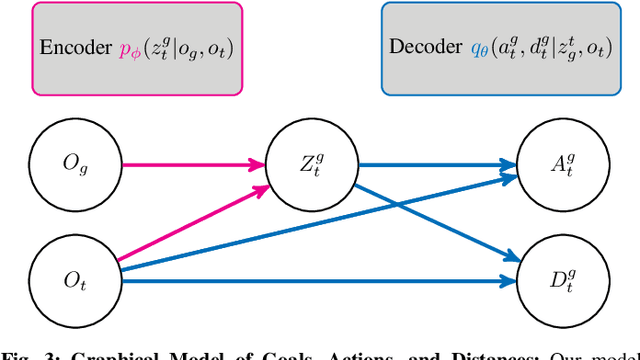
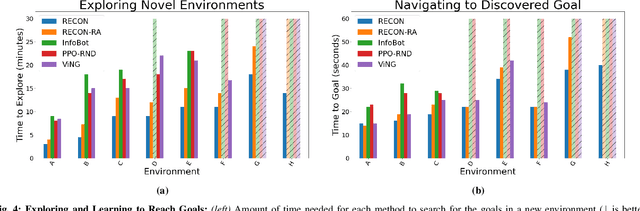
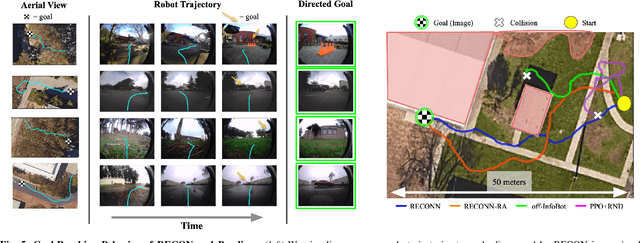
We describe a robotic learning system for autonomous navigation in diverse environments. At the core of our method are two components: (i) a non-parametric map that reflects the connectivity of the environment but does not require geometric reconstruction or localization, and (ii) a latent variable model of distances and actions that enables efficiently constructing and traversing this map. The model is trained on a large dataset of prior experience to predict the expected amount of time and next action needed to transit between the current image and a goal image. Training the model in this way enables it to develop a representation of goals robust to distracting information in the input images, which aids in deploying the system to quickly explore new environments. We demonstrate our method on a mobile ground robot in a range of outdoor navigation scenarios. Our method can learn to reach new goals, specified as images, in a radius of up to 80 meters in just 20 minutes, and reliably revisit these goals in changing environments. We also demonstrate our method's robustness to previously-unseen obstacles and variable weather conditions. We encourage the reader to visit the project website for videos of our experiments and demonstrations https://sites.google.com/view/recon-robot
Medical Transformer: Universal Brain Encoder for 3D MRI Analysis
Apr 28, 2021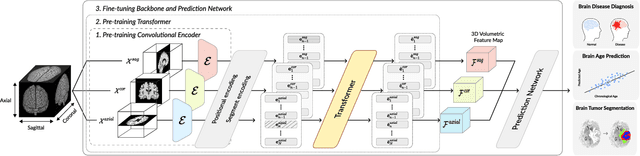
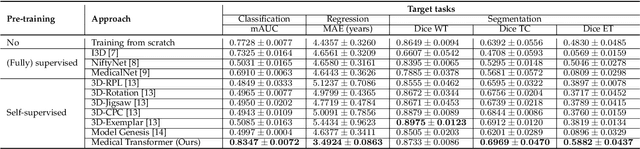
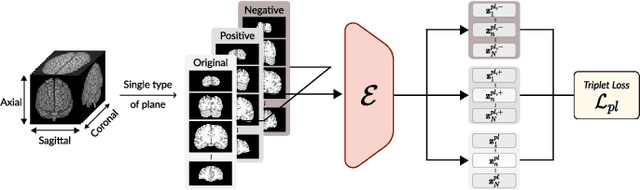
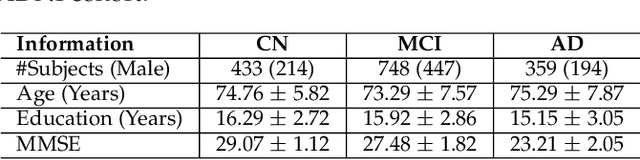
Transfer learning has gained attention in medical image analysis due to limited annotated 3D medical datasets for training data-driven deep learning models in the real world. Existing 3D-based methods have transferred the pre-trained models to downstream tasks, which achieved promising results with only a small number of training samples. However, they demand a massive amount of parameters to train the model for 3D medical imaging. In this work, we propose a novel transfer learning framework, called Medical Transformer, that effectively models 3D volumetric images in the form of a sequence of 2D image slices. To make a high-level representation in 3D-form empowering spatial relations better, we take a multi-view approach that leverages plenty of information from the three planes of 3D volume, while providing parameter-efficient training. For building a source model generally applicable to various tasks, we pre-train the model in a self-supervised learning manner for masked encoding vector prediction as a proxy task, using a large-scale normal, healthy brain magnetic resonance imaging (MRI) dataset. Our pre-trained model is evaluated on three downstream tasks: (i) brain disease diagnosis, (ii) brain age prediction, and (iii) brain tumor segmentation, which are actively studied in brain MRI research. The experimental results show that our Medical Transformer outperforms the state-of-the-art transfer learning methods, efficiently reducing the number of parameters up to about 92% for classification and
GNSS-denied geolocalization of UAVs by visual matching of onboard camera images with orthophotos
Mar 26, 2021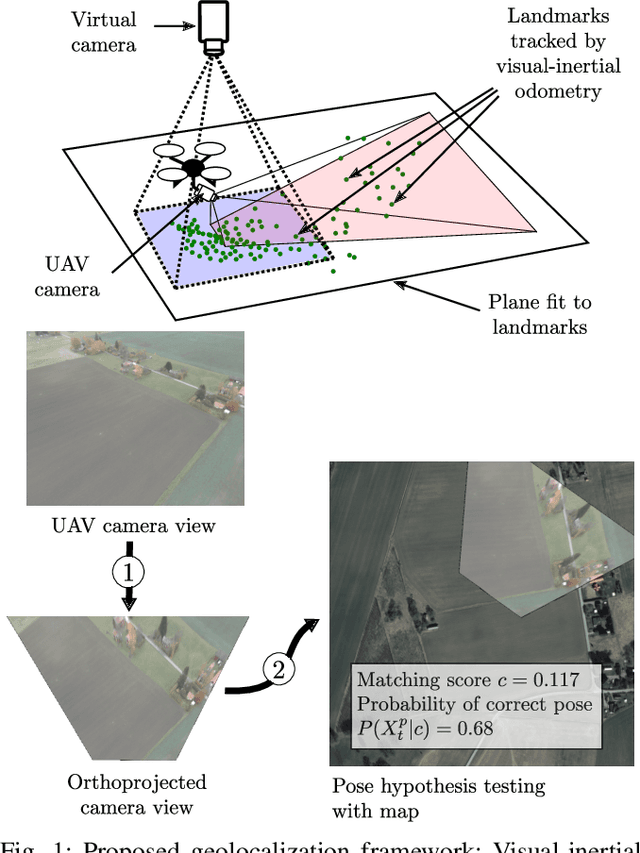
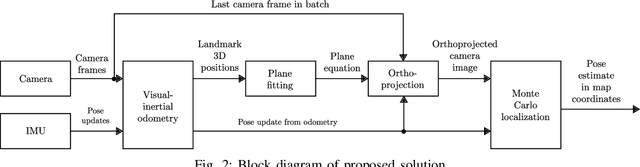
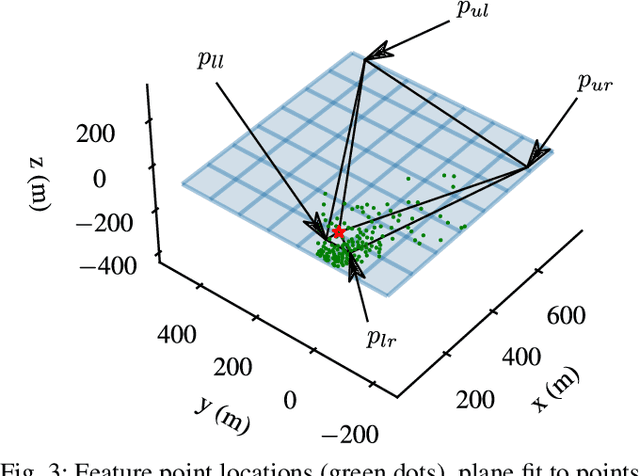

Localization of low-cost unmanned aerial vehicles(UAVs) often relies on Global Navigation Satellite Systems (GNSS). GNSS are susceptible to both natural disruptions to radio signal and intentional jamming and spoofing by an adversary. A typical way to provide georeferenced localization without GNSS for small UAVs is to have a downward-facing camera and match camera images to a map. The downward-facing camera adds cost, size, and weight to the UAV platform and the orientation limits its usability for other purposes. In this work, we propose a Monte-Carlo localization method for georeferenced localization of an UAV requiring no infrastructure using only inertial measurements, a camera facing an arbitrary direction, and an orthoimage map. We perform orthorectification of the UAV image, relying on a local planarity assumption of the environment, relaxing the requirement of downward-pointing camera. We propose a measure of goodness for the matching score of an orthorectified UAV image and a map. We demonstrate that the system is able to localize globally an UAV with modest requirements for initialization and map resolution.