 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Machine learning approach for rapid disaster response based on multi-modal data. The case of housing & shelter needs
Jul 29, 2021




Along with climate change, more frequent extreme events, such as flooding and tropical cyclones, threaten the livelihoods and wellbeing of poor and vulnerable populations. One of the most immediate needs of people affected by a disaster is finding shelter. While the proliferation of data on disasters is already helping to save lives, identifying damages in buildings, assessing shelter needs, and finding appropriate places to establish emergency shelters or settlements require a wide range of data to be combined rapidly. To address this gap and make a headway in comprehensive assessments, this paper proposes a machine learning workflow that aims to fuse and rapidly analyse multimodal data. This workflow is built around open and online data to ensure scalability and broad accessibility. Based on a database of 19 characteristics for more than 200 disasters worldwide, a fusion approach at the decision level was used. This technique allows the collected multimodal data to share a common semantic space that facilitates the prediction of individual variables. Each fused numerical vector was fed into an unsupervised clustering algorithm called Self-Organizing-Maps (SOM). The trained SOM serves as a predictor for future cases, allowing predicting consequences such as total deaths, total people affected, and total damage, and provides specific recommendations for assessments in the shelter and housing sector. To achieve such prediction, a satellite image from before the disaster and the geographic and demographic conditions are shown to the trained model, which achieved a prediction accuracy of 62 %
Increasing the robustness of DNNs against image corruptions by playing the Game of Noise
Feb 26, 2020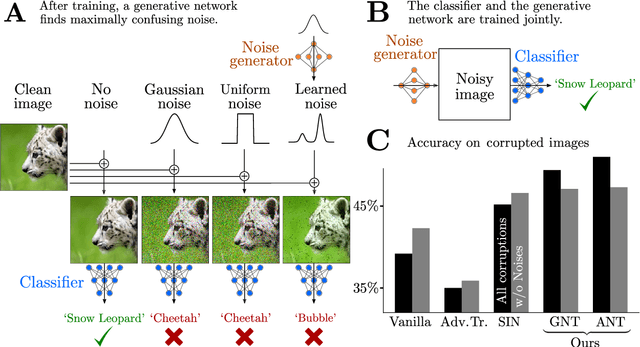
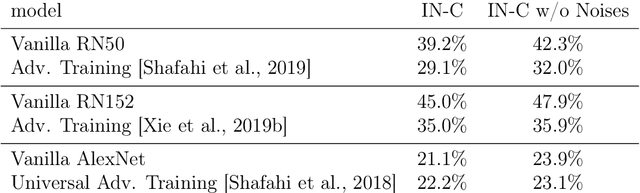
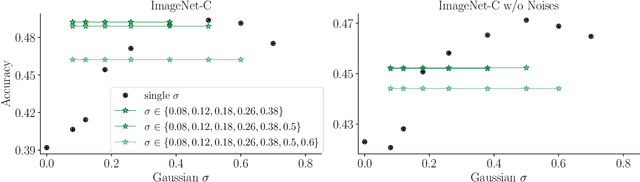
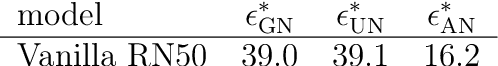
The human visual system is remarkably robust against a wide range of naturally occurring variations and corruptions like rain or snow. In contrast, the performance of modern image recognition models strongly degrades when evaluated on previously unseen corruptions. Here, we demonstrate that a simple but properly tuned training with additive Gaussian and Speckle noise generalizes surprisingly well to unseen corruptions, easily reaching the previous state of the art on the corruption benchmark ImageNet-C (with ResNet50) and on MNIST-C. We build on top of these strong baseline results and show that an adversarial training of the recognition model against uncorrelated worst-case noise distributions leads to an additional increase in performance. This regularization can be combined with previously proposed defense methods for further improvement.
Adaptive image-feature learning for disease classification using inductive graph networks
May 08, 2019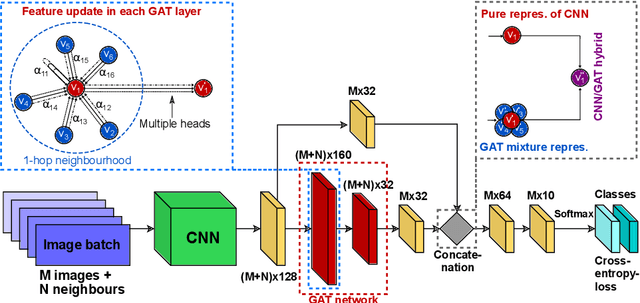
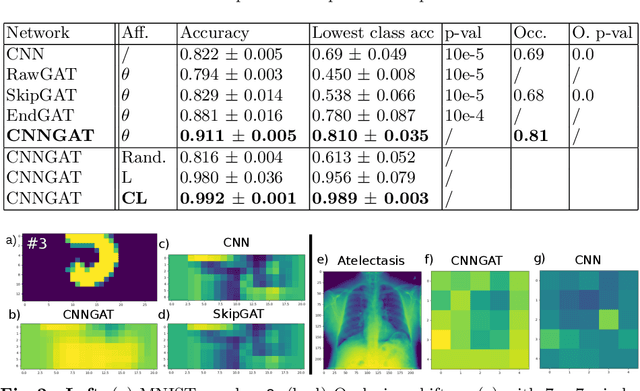

Recently, Geometric Deep Learning (GDL) has been introduced as a novel and versatile framework for computer-aided disease classification. GDL uses patient meta-information such as age and gender to model patient cohort relations in a graph structure. Concepts from graph signal processing are leveraged to learn the optimal mapping of multi-modal features, e.g. from images to disease classes. Related studies so far have considered image features that are extracted in a pre-processing step. We hypothesize that such an approach prevents the network from optimizing feature representations towards achieving the best performance in the graph network. We propose a new network architecture that exploits an inductive end-to-end learning approach for disease classification, where filters from both the CNN and the graph are trained jointly. We validate this architecture against state-of-the-art inductive graph networks and demonstrate significantly improved classification scores on a modified MNIST toy dataset, as well as comparable classification results with higher stability on a chest X-ray image dataset. Additionally, we explain how the structural information of the graph affects both the image filters and the feature learning.
Learning with Noisy Labels for Robust Point Cloud Segmentation
Jul 29, 2021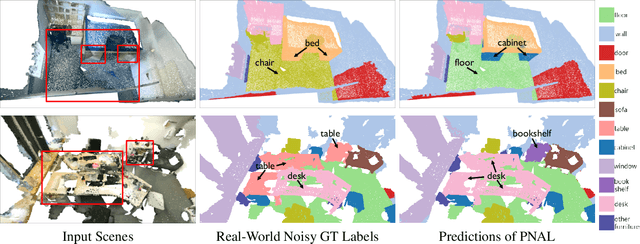
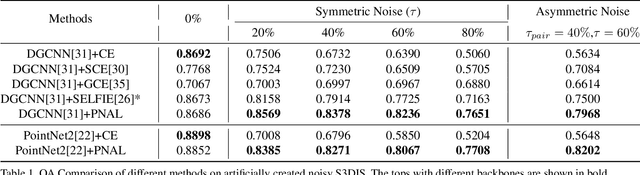
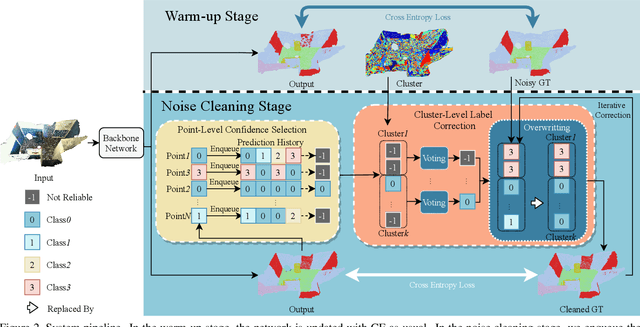
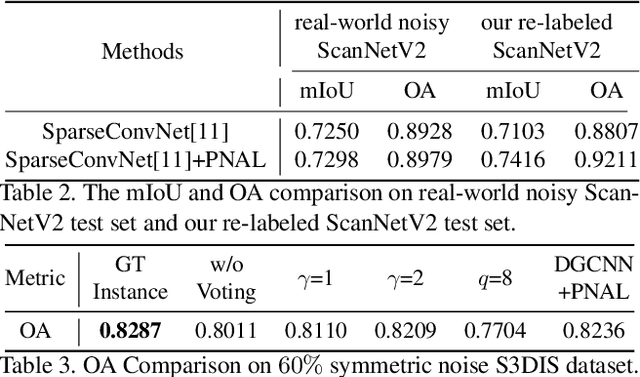
Point cloud segmentation is a fundamental task in 3D. Despite recent progress on point cloud segmentation with the power of deep networks, current deep learning methods based on the clean label assumptions may fail with noisy labels. Yet, object class labels are often mislabeled in real-world point cloud datasets. In this work, we take the lead in solving this issue by proposing a novel Point Noise-Adaptive Learning (PNAL) framework. Compared to existing noise-robust methods on image tasks, our PNAL is noise-rate blind, to cope with the spatially variant noise rate problem specific to point clouds. Specifically, we propose a novel point-wise confidence selection to obtain reliable labels based on the historical predictions of each point. A novel cluster-wise label correction is proposed with a voting strategy to generate the best possible label taking the neighbor point correlations into consideration. We conduct extensive experiments to demonstrate the effectiveness of PNAL on both synthetic and real-world noisy datasets. In particular, even with $60\%$ symmetric noisy labels, our proposed method produces much better results than its baseline counterpart without PNAL and is comparable to the ideal upper bound trained on a completely clean dataset. Moreover, we fully re-labeled the test set of a popular but noisy real-world scene dataset ScanNetV2 to make it clean, for rigorous experiment and future research. Our code and data will be available at \url{https://shuquanye.com/PNAL_website/}.
Doc2Im: document to image conversion through self-attentive embedding
Nov 08, 2018
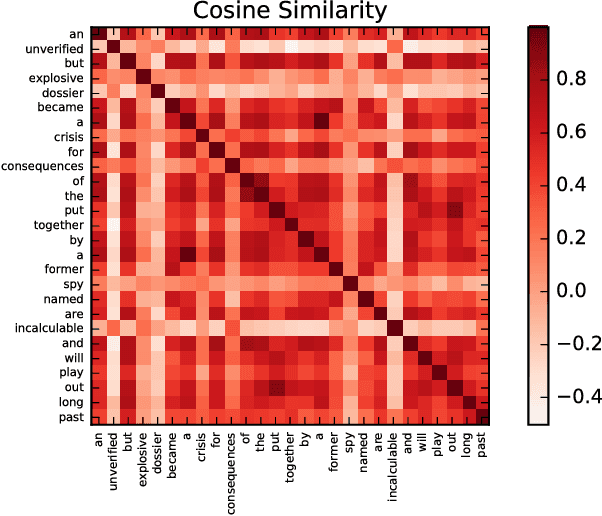
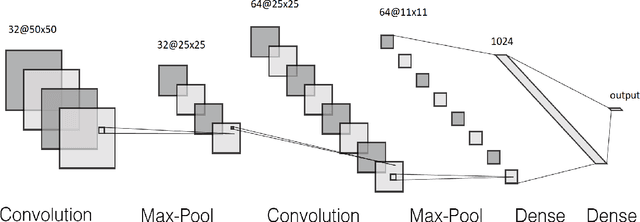
Text classification is a fundamental task in NLP applications. Latest research in this field has largely been divided into two major sub-fields. Learning representations is one sub-field and learning deeper models, both sequential and convolutional, which again connects back to the representation is the other side. We posit the idea that the stronger the representation is, the simpler classifier models are needed to achieve higher performance. In this paper we propose a completely novel direction to text classification research, wherein we convert text to a representation very similar to images, such that any deep network able to handle images is equally able to handle text. We take a deeper look at the representation of documents as an image and subsequently utilize very simple convolution based models taken as is from computer vision domain. This image can be cropped, re-scaled, re-sampled and augmented just like any other image to work with most of the state-of-the-art large convolution based models which have been designed to handle large image datasets. We show impressive results with some of the latest benchmarks in the related fields. We perform transfer learning experiments, both from text to text domain and also from image to text domain. We believe this is a paradigm shift from the way document understanding and text classification has been traditionally done, and will drive numerous novel research ideas in the community.
CLDA: Contrastive Learning for Semi-Supervised Domain Adaptation
Jun 30, 2021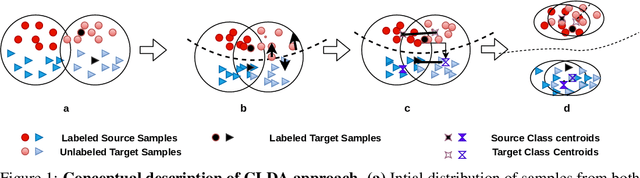
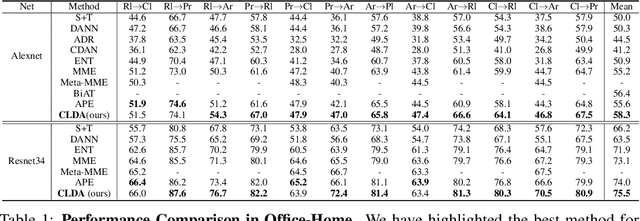
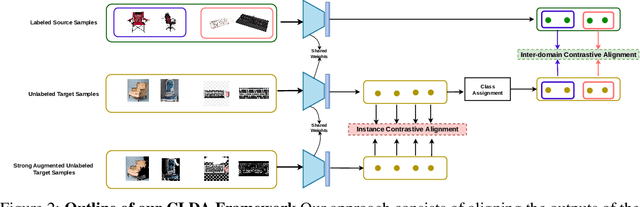
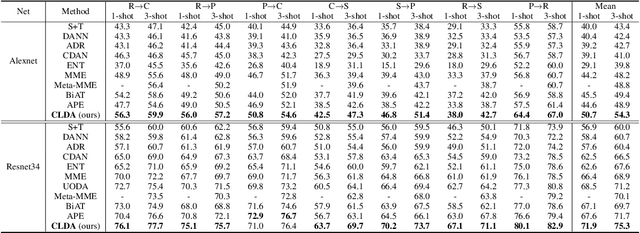
Unsupervised Domain Adaptation (UDA) aims to align the labeled source distribution with the unlabeled target distribution to obtain domain invariant predictive models. However, the application of well-known UDA approaches does not generalize well in Semi-Supervised Domain Adaptation (SSDA) scenarios where few labeled samples from the target domain are available. In this paper, we propose a simple Contrastive Learning framework for semi-supervised Domain Adaptation (CLDA) that attempts to bridge the intra-domain gap between the labeled and unlabeled target distributions and inter-domain gap between source and unlabeled target distribution in SSDA. We suggest employing class-wise contrastive learning to reduce the inter-domain gap and instance-level contrastive alignment between the original (input image) and strongly augmented unlabeled target images to minimize the intra-domain discrepancy. We have shown empirically that both of these modules complement each other to achieve superior performance. Experiments on three well-known domain adaptation benchmark datasets namely DomainNet, Office-Home, and Office31 demonstrate the effectiveness of our approach. CLDA achieves state-of-the-art results on all the above datasets.
Efficient automated U-Net based tree crown delineation using UAV multi-spectral imagery on embedded devices
Jul 16, 2021



Delineation approaches provide significant benefits to various domains, including agriculture, environmental and natural disasters monitoring. Most of the work in the literature utilize traditional segmentation methods that require a large amount of computational and storage resources. Deep learning has transformed computer vision and dramatically improved machine translation, though it requires massive dataset for training and significant resources for inference. More importantly, energy-efficient embedded vision hardware delivering real-time and robust performance is crucial in the aforementioned application. In this work, we propose a U-Net based tree delineation method, which is effectively trained using multi-spectral imagery but can then delineate single-spectrum images. The deep architecture that also performs localization, i.e., a class label corresponds to each pixel, has been successfully used to allow training with a small set of segmented images. The ground truth data were generated using traditional image denoising and segmentation approaches. To be able to execute the proposed DNN efficiently in embedded platforms designed for deep learning approaches, we employ traditional model compression and acceleration methods. Extensive evaluation studies using data collected from UAVs equipped with multi-spectral cameras demonstrate the effectiveness of the proposed methods in terms of delineation accuracy and execution efficiency.
No-Reference Color Image Quality Assessment: From Entropy to Perceptual Quality
Dec 27, 2018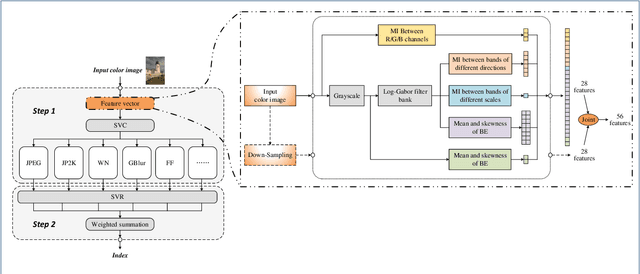

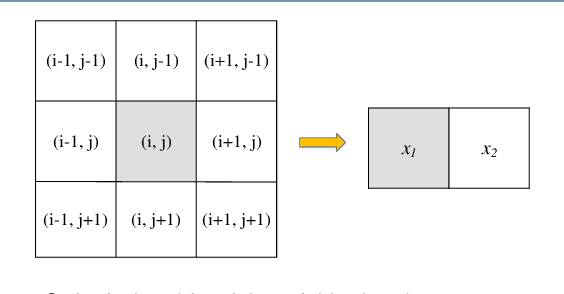
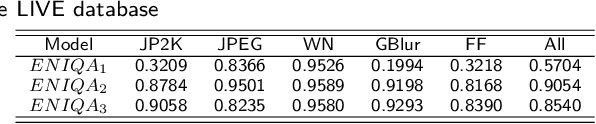
This paper presents a high-performance general-purpose no-reference (NR) image quality assessment (IQA) method based on image entropy. The image features are extracted from two domains. In the spatial domain, the mutual information between the color channels and the two-dimensional entropy are calculated. In the frequency domain, the two-dimensional entropy and the mutual information of the filtered sub-band images are computed as the feature set of the input color image. Then, with all the extracted features, the support vector classifier (SVC) for distortion classification and support vector regression (SVR) are utilized for the quality prediction, to obtain the final quality assessment score. The proposed method, which we call entropy-based no-reference image quality assessment (ENIQA), can assess the quality of different categories of distorted images, and has a low complexity. The proposed ENIQA method was assessed on the LIVE and TID2013 databases and showed a superior performance. The experimental results confirmed that the proposed ENIQA method has a high consistency of objective and subjective assessment on color images, which indicates the good overall performance and generalization ability of ENIQA. The source code is available on github https://github.com/jacob6/ENIQA.
Speeding up scaled gradient projection methods using deep neural networks for inverse problems in image processing
Feb 07, 2019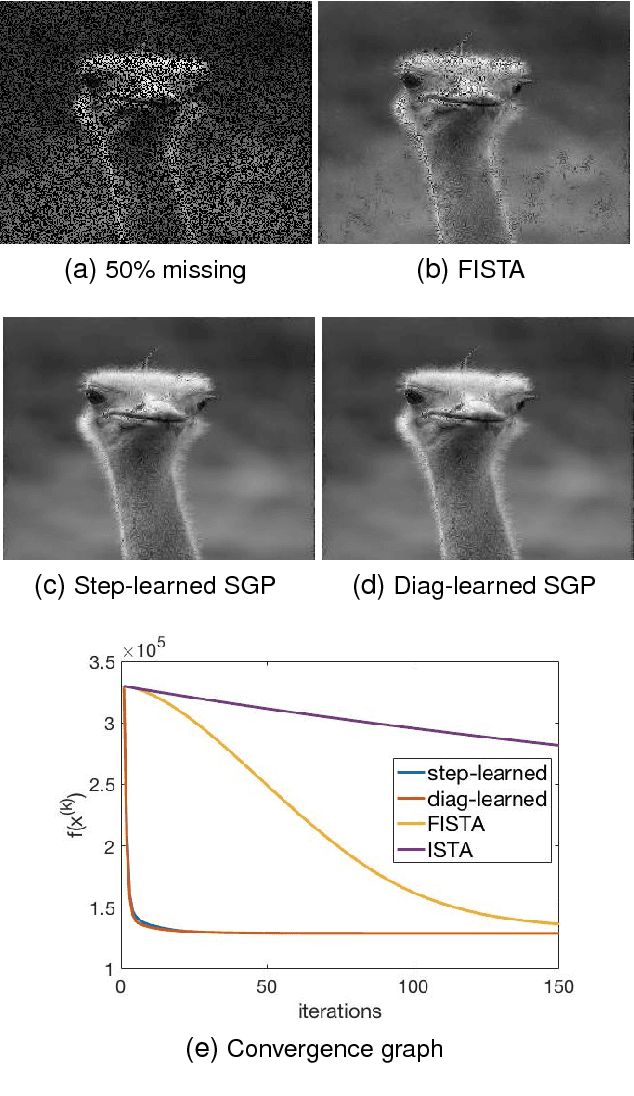
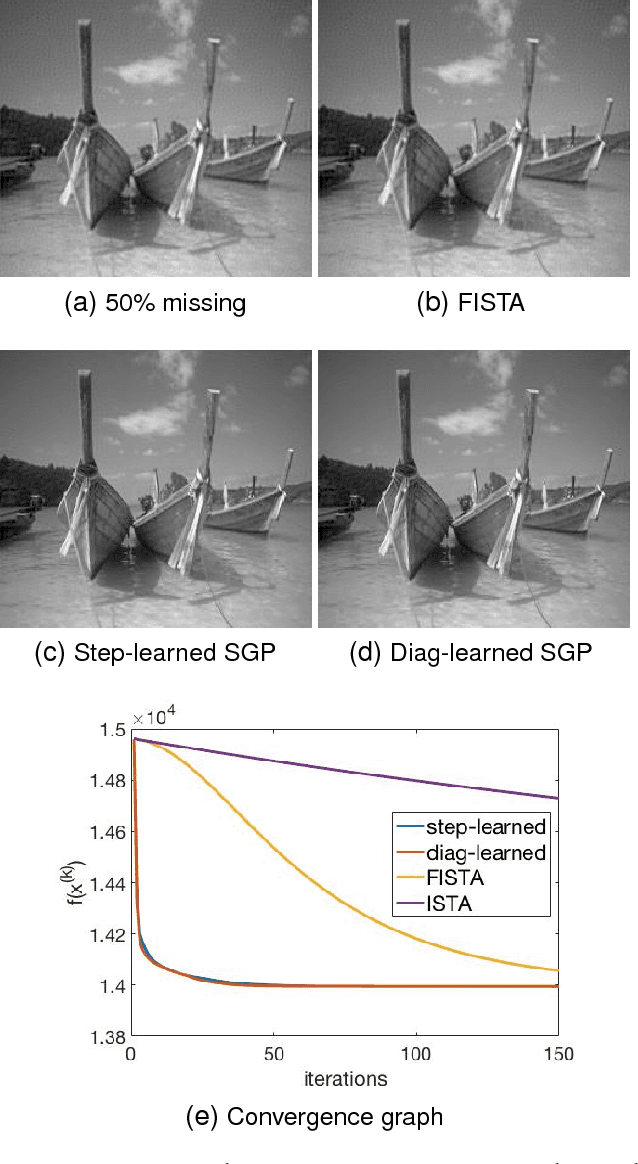
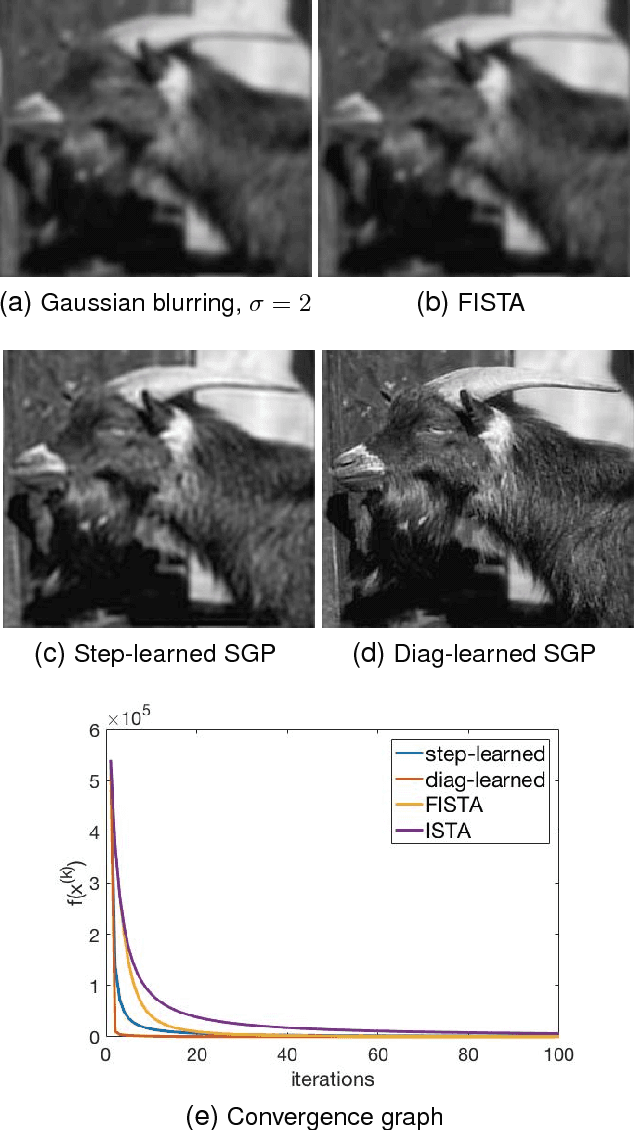
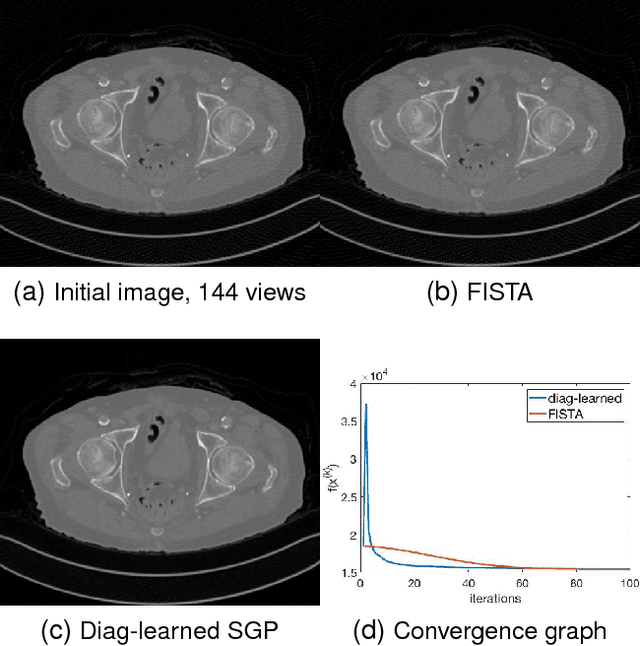
Conventional optimization based methods have utilized forward models with image priors to solve inverse problems in image processing. Recently, deep neural networks (DNN) have been investigated to significantly improve the image quality of the solution for inverse problems. Most DNN based inverse problems have focused on using data-driven image priors with massive amount of data. However, these methods often do not inherit nice properties of conventional approaches using theoretically well-grounded optimization algorithms such as monotone, global convergence. Here we investigate another possibility of using DNN for inverse problems in image processing. We propose methods to use DNNs to seamlessly speed up convergence rates of conventional optimization based methods. Our DNN-incorporated scaled gradient projection methods, without breaking theoretical properties, significantly improved convergence speed over state-of-the-art conventional optimization methods such as ISTA or FISTA in practice for inverse problems such as image inpainting, compressive image recovery with partial Fourier samples, image deblurring, and medical image reconstruction with sparse-view projections.
Probabilistic and Geometric Depth: Detecting Objects in Perspective
Jul 29, 2021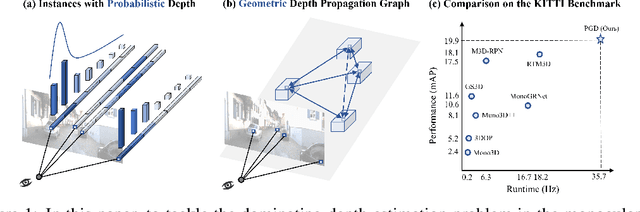
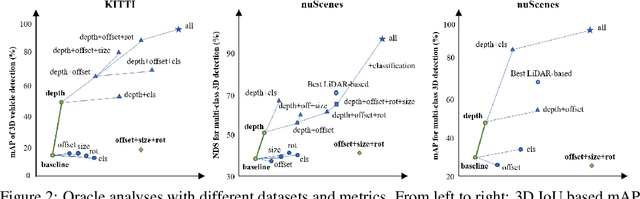
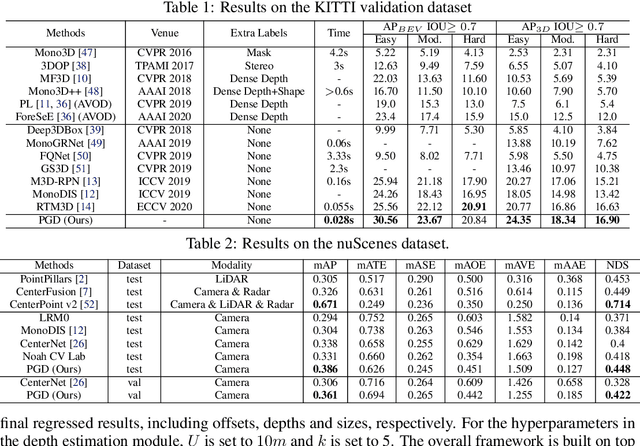
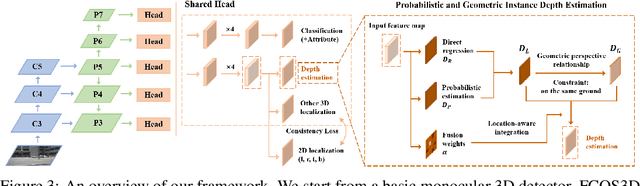
3D object detection is an important capability needed in various practical applications such as driver assistance systems. Monocular 3D detection, as an economical solution compared to conventional settings relying on binocular vision or LiDAR, has drawn increasing attention recently but still yields unsatisfactory results. This paper first presents a systematic study on this problem and observes that the current monocular 3D detection problem can be simplified as an instance depth estimation problem: The inaccurate instance depth blocks all the other 3D attribute predictions from improving the overall detection performance. However, recent methods directly estimate the depth based on isolated instances or pixels while ignoring the geometric relations across different objects, which can be valuable constraints as the key information about depth is not directly manifest in the monocular image. Therefore, we construct geometric relation graphs across predicted objects and use the graph to facilitate depth estimation. As the preliminary depth estimation of each instance is usually inaccurate in this ill-posed setting, we incorporate a probabilistic representation to capture the uncertainty. It provides an important indicator to identify confident predictions and further guide the depth propagation. Despite the simplicity of the basic idea, our method obtains significant improvements on KITTI and nuScenes benchmarks, achieving the 1st place out of all monocular vision-only methods while still maintaining real-time efficiency. Code and models will be released at https://github.com/open-mmlab/mmdetection3d.