 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Kaleido-BERT: Vision-Language Pre-training on Fashion Domain
Apr 06, 2021
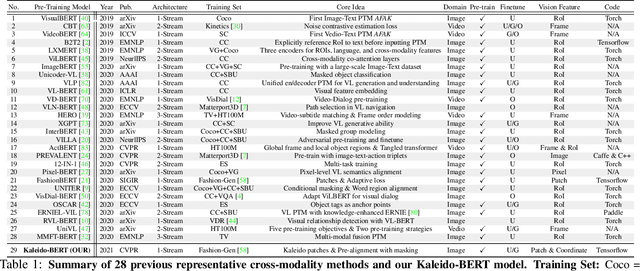
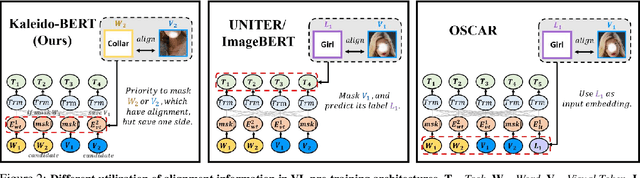
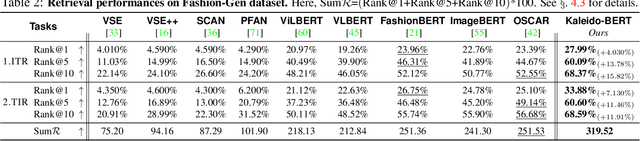
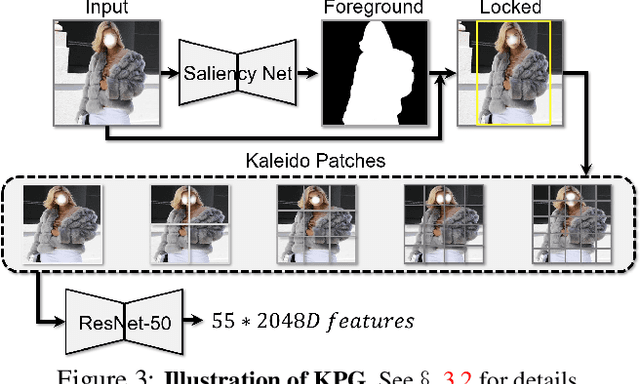
We present a new vision-language (VL) pre-training model dubbed Kaleido-BERT, which introduces a novel kaleido strategy for fashion cross-modality representations from transformers. In contrast to random masking strategy of recent VL models, we design alignment guided masking to jointly focus more on image-text semantic relations. To this end, we carry out five novel tasks, i.e., rotation, jigsaw, camouflage, grey-to-color, and blank-to-color for self-supervised VL pre-training at patches of different scale. Kaleido-BERT is conceptually simple and easy to extend to the existing BERT framework, it attains new state-of-the-art results by large margins on four downstream tasks, including text retrieval (R@1: 4.03% absolute improvement), image retrieval (R@1: 7.13% abs imv.), category recognition (ACC: 3.28% abs imv.), and fashion captioning (Bleu4: 1.2 abs imv.). We validate the efficiency of Kaleido-BERT on a wide range of e-commerical websites, demonstrating its broader potential in real-world applications.
Unsupervised Learning of Fine Structure Generation for 3D Point Clouds by 2D Projection Matching
Aug 08, 2021



Learning to generate 3D point clouds without 3D supervision is an important but challenging problem. Current solutions leverage various differentiable renderers to project the generated 3D point clouds onto a 2D image plane, and train deep neural networks using the per-pixel difference with 2D ground truth images. However, these solutions are still struggling to fully recover fine structures of 3D shapes, such as thin tubes or planes. To resolve this issue, we propose an unsupervised approach for 3D point cloud generation with fine structures. Specifically, we cast 3D point cloud learning as a 2D projection matching problem. Rather than using entire 2D silhouette images as a regular pixel supervision, we introduce structure adaptive sampling to randomly sample 2D points within the silhouettes as an irregular point supervision, which alleviates the consistency issue of sampling from different view angles. Our method pushes the neural network to generate a 3D point cloud whose 2D projections match the irregular point supervision from different view angles. Our 2D projection matching approach enables the neural network to learn more accurate structure information than using the per-pixel difference, especially for fine and thin 3D structures. Our method can recover fine 3D structures from 2D silhouette images at different resolutions, and is robust to different sampling methods and point number in irregular point supervision. Our method outperforms others under widely used benchmarks. Our code, data and models are available at https://github.com/chenchao15/2D\_projection\_matching.
Learning Whole-Slide Segmentation from Inexact and Incomplete Labels using Tissue Graphs
Mar 04, 2021Segmenting histology images into diagnostically relevant regions is imperative to support timely and reliable decisions by pathologists. To this end, computer-aided techniques have been proposed to delineate relevant regions in scanned histology slides. However, the techniques necessitate task-specific large datasets of annotated pixels, which is tedious, time-consuming, expensive, and infeasible to acquire for many histology tasks. Thus, weakly-supervised semantic segmentation techniques are proposed to utilize weak supervision that is cheaper and quicker to acquire. In this paper, we propose SegGini, a weakly supervised segmentation method using graphs, that can utilize weak multiplex annotations, i.e. inexact and incomplete annotations, to segment arbitrary and large images, scaling from tissue microarray (TMA) to whole slide image (WSI). Formally, SegGini constructs a tissue-graph representation for an input histology image, where the graph nodes depict tissue regions. Then, it performs weakly-supervised segmentation via node classification by using inexact image-level labels, incomplete scribbles, or both. We evaluated SegGini on two public prostate cancer datasets containing TMAs and WSIs. Our method achieved state-of-the-art segmentation performance on both datasets for various annotation settings while being comparable to a pathologist baseline.
An Applied Deep Learning Approach for Estimating Soybean Relative Maturity from UAV Imagery to Aid Plant Breeding Decisions
Aug 02, 2021
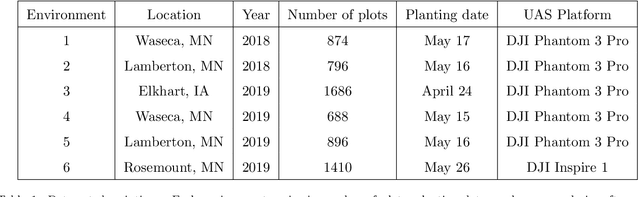
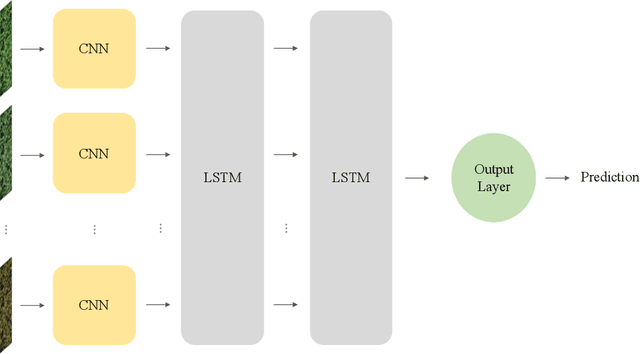
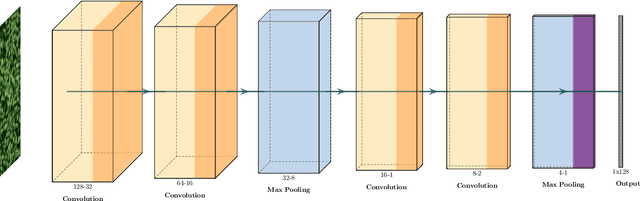
For a global breeding organization, identifying the next generation of superior crops is vital for its success. Recognizing new genetic varieties requires years of in-field testing to gather data about the crop's yield, pest resistance, heat resistance, etc. At the conclusion of the growing season, organizations need to determine which varieties will be advanced to the next growing season (or sold to farmers) and which ones will be discarded from the candidate pool. Specifically for soybeans, identifying their relative maturity is a vital piece of information used for advancement decisions. However, this trait needs to be physically observed, and there are resource limitations (time, money, etc.) that bottleneck the data collection process. To combat this, breeding organizations are moving toward advanced image capturing devices. In this paper, we develop a robust and automatic approach for estimating the relative maturity of soybeans using a time series of UAV images. An end-to-end hybrid model combining Convolutional Neural Networks (CNN) and Long Short-Term Memory (LSTM) is proposed to extract features and capture the sequential behavior of time series data. The proposed deep learning model was tested on six different environments across the United States. Results suggest the effectiveness of our proposed CNN-LSTM model compared to the local regression method. Furthermore, we demonstrate how this newfound information can be used to aid in plant breeding advancement decisions.
Exploring Uncertainty Measures for Image-Caption Embedding-and-Retrieval Task
Apr 09, 2019
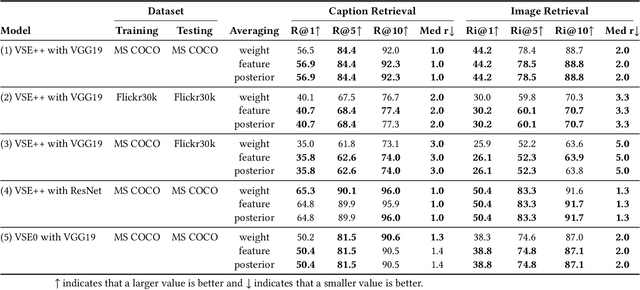
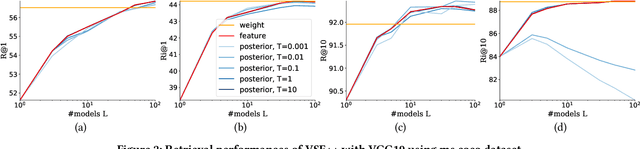
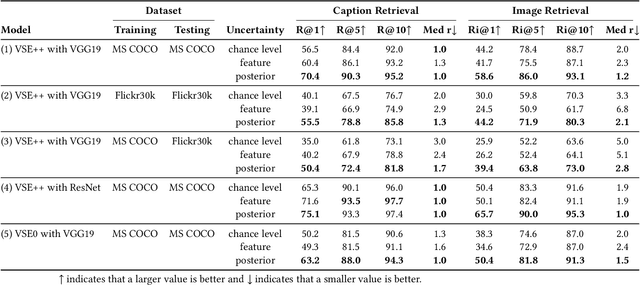
With the wide development of black-box machine learning algorithms, particularly deep neural network (DNN), the practical demand for the reliability assessment is rapidly rising. On the basis of the concept that `Bayesian deep learning knows what it does not know,' the uncertainty of DNN outputs has been investigated as a reliability measure for the classification and regression tasks. However, in the image-caption retrieval task, well-known samples are not always easy-to-retrieve samples. This study investigates two aspects of image-caption embedding-and-retrieval systems. On one hand, we quantify feature uncertainty by considering image-caption embedding as a regression task, and use it for model averaging, which can improve the retrieval performance. On the other hand, we further quantify posterior uncertainty by considering the retrieval as a classification task, and use it as a reliability measure, which can greatly improve the retrieval performance by rejecting uncertain queries. The consistent performance of two uncertainty measures is observed with different datasets (MS COCO and Flickr30k), different deep learning architectures (dropout and batch normalization), and different similarity functions.
Improving Interpretability of Deep Neural Networks in Medical Diagnosis by Investigating the Individual Units
Jul 19, 2021

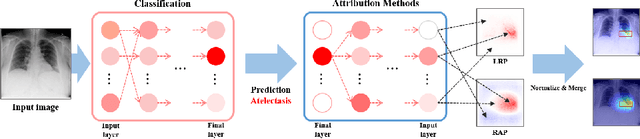
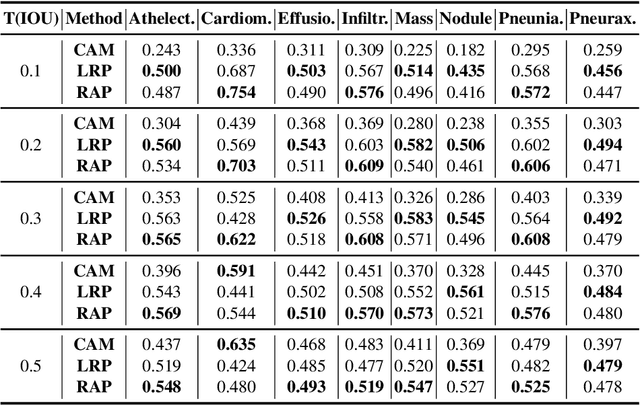
As interpretability has been pointed out as the obstacle to the adoption of Deep Neural Networks (DNNs), there is an increasing interest in solving a transparency issue to guarantee the impressive performance. In this paper, we demonstrate the efficiency of recent attribution techniques to explain the diagnostic decision by visualizing the significant factors in the input image. By utilizing the characteristics of objectness that DNNs have learned, fully decomposing the network prediction visualizes clear localization of target lesion. To verify our work, we conduct our experiments on Chest X-ray diagnosis with publicly accessible datasets. As an intuitive assessment metric for explanations, we report the performance of intersection of Union between visual explanation and bounding box of lesions. Experiment results show that recently proposed attribution methods visualize the more accurate localization for the diagnostic decision compared to the traditionally used CAM. Furthermore, we analyze the inconsistency of intentions between humans and DNNs, which is easily obscured by high performance. By visualizing the relevant factors, it is possible to confirm that the criterion for decision is in line with the learning strategy. Our analysis of unmasking machine intelligence represents the necessity of explainability in the medical diagnostic decision.
MvMM-RegNet: A new image registration framework based on multivariate mixture model and neural network estimation
Jul 14, 2020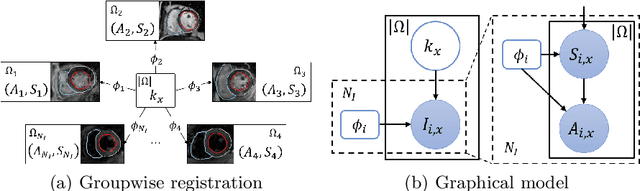
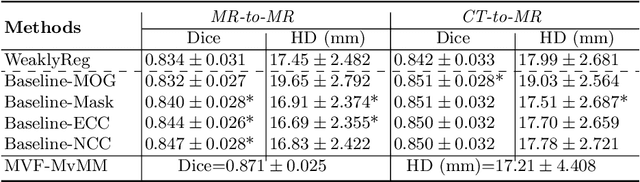
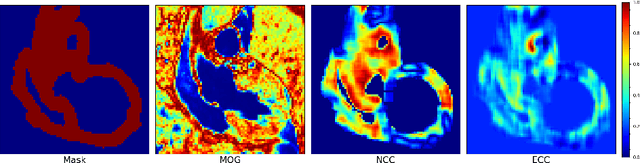
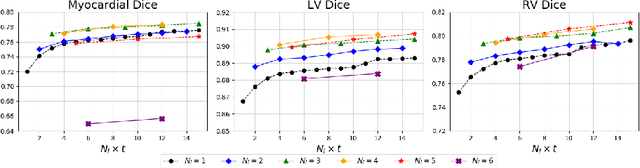
Current deep-learning-based registration algorithms often exploit intensity-based similarity measures as the loss function, where dense correspondence between a pair of moving and fixed images is optimized through backpropagation during training. However, intensity-based metrics can be misleading when the assumption of intensity class correspondence is violated, especially in cross-modality or contrast-enhanced images. Moreover, existing learning-based registration methods are predominantly applicable to pairwise registration and are rarely extended to groupwise registration or simultaneous registration with multiple images. In this paper, we propose a new image registration framework based on multivariate mixture model (MvMM) and neural network estimation. A generative model consolidating both appearance and anatomical information is established to derive a novel loss function capable of implementing groupwise registration. We highlight the versatility of the proposed framework for various applications on multimodal cardiac images, including single-atlas-based segmentation (SAS) via pairwise registration and multi-atlas segmentation (MAS) unified by groupwise registration. We evaluated performance on two publicly available datasets, i.e. MM-WHS-2017 and MS-CMRSeg-2019. The results show that the proposed framework achieved an average Dice score of $0.871\pm 0.025$ for whole-heart segmentation on MR images and $0.783\pm 0.082$ for myocardium segmentation on LGE MR images.
Multi-Temporal High Resolution Aerial Image Registration Using Semantic Features
Aug 30, 2019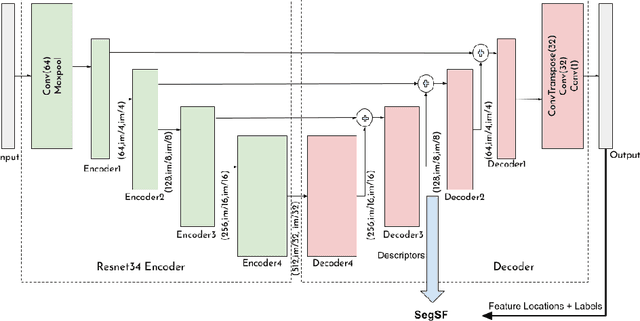


A new type of segmentation-based semantic feature (SegSF) for multi-temporal aerial image registration is proposed in this paper. These features encode information about temporally invariant objects such as roads which help deal with the issues such as changing foliage that classical handcrafted features are unable to address. These features are extracted from a semantic segmentation network and show good accuracy in registering aerial images across years and seasons.
Learning event representations in image sequences by dynamic graph embedding
Oct 08, 2019
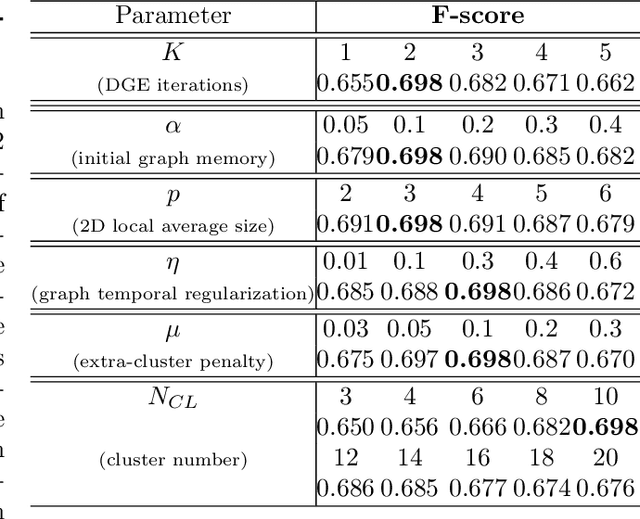
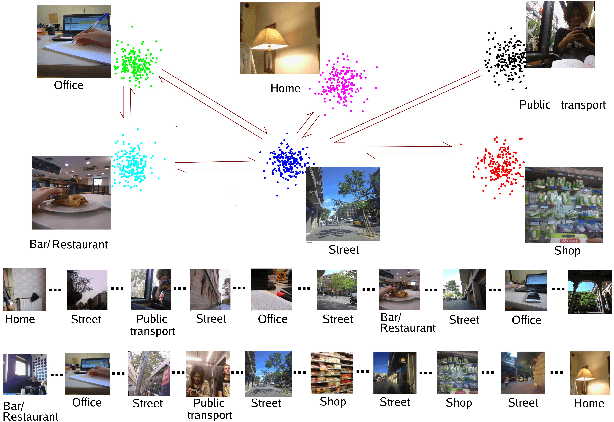
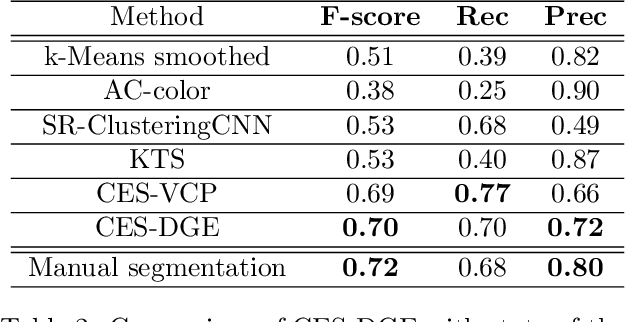
Recently, self-supervised learning has proved to be effective to learn representations of events in image sequences, where events are understood as sets of temporally adjacent images that are semantically perceived as a whole. However, although this approach does not require expensive manual annotations, it is data hungry and suffers from domain adaptation problems. As an alternative, in this work, we propose a novel approach for learning event representations named Dynamic Graph Embedding (DGE). The assumption underlying our model is that a sequence of images can be represented by a graph that encodes both semantic and temporal similarity. The key novelty of DGE is to learn jointly the graph and its graph embedding. At its core, DGE works by iterating over two steps: 1) updating the graph representing the semantic and temporal structure of the data based on the current data representation, and 2) updating the data representation to take into account the current data graph structure. The main advantage of DGE over state-of-the-art self-supervised approaches is that it does not require any training set, but instead learns iteratively from the data itself a low-dimensional embedding that reflects their temporal and semantic structure. Experimental results on two benchmark datasets of real image sequences captured at regular intervals demonstrate that the proposed DGE leads to effective event representations. In particular, it achieves robust temporal segmentation on the EDUBSeg and EDUBSeg-Desc benchmark datasets, outperforming the state of the art.
Joint group and residual sparse coding for image compressive sensing
Jan 23, 2019
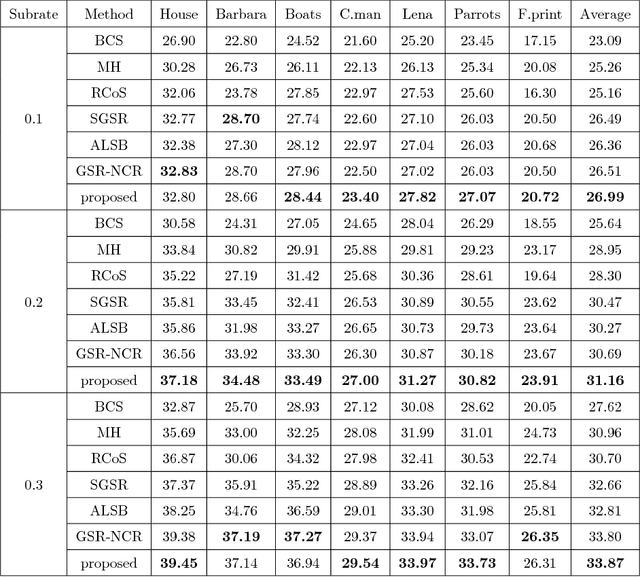
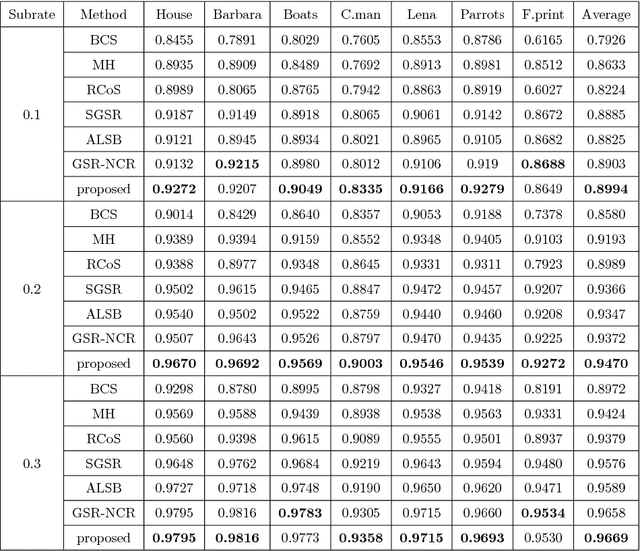

Nonlocal self-similarity and group sparsity have been widely utilized in image compressive sensing (CS). However, when the sampling rate is low, the internal prior information of degraded images may be not enough for accurate restoration, resulting in loss of image edges and details. In this paper, we propose a joint group and residual sparse coding method for CS image recovery (JGRSC-CS). In the proposed JGRSC-CS, patch group is treated as the basic unit of sparse coding and two dictionaries (namely internal and external dictionaries) are applied to exploit the sparse representation of each group simultaneously. The internal self-adaptive dictionary is used to remove artifacts, and an external Gaussian Mixture Model (GMM) dictionary, learned from clean training images, is used to enhance details and texture. To make the proposed method effective and robust, the split Bregman method is adopted to reconstruct the whole image. Experimental results manifest the proposed JGRSC-CS algorithm outperforms existing state-of-the-art methods in both peak signal to noise ratio (PSNR) and visual quality.