 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A New Pairwise Deep Learning Feature For Environmental Microorganism Image Analysis
Feb 24, 2021
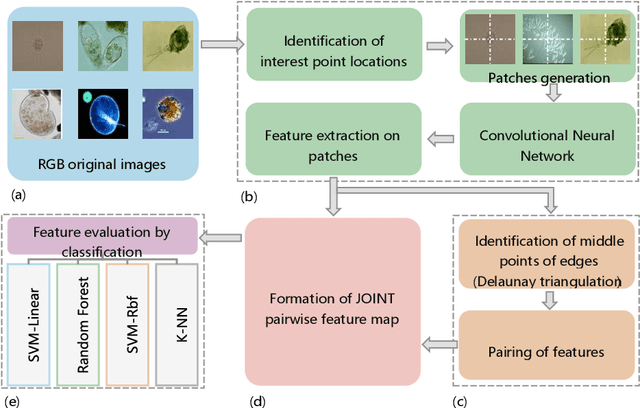


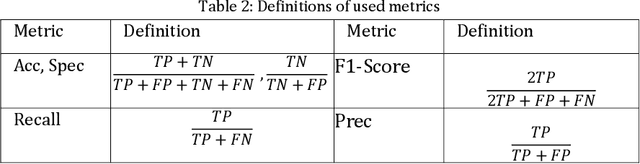
Environmental microorganism (EM) offers a high-efficient, harmless, and low-cost solution to environmental pollution. They are used in sanitation, monitoring, and decomposition of environmental pollutants. However, this depends on the proper identification of suitable microorganisms. In order to fasten, low the cost, increase consistency and accuracy of identification, we propose the novel pairwise deep learning features to analyze microorganisms. The pairwise deep learning features technique combines the capability of handcrafted and deep learning features. In this technique we, leverage the Shi and Tomasi interest points by extracting deep learning features from patches which are centered at interest points locations. Then, to increase the number of potential features that have intermediate spatial characteristics between nearby interest points, we use Delaunay triangulation theorem and straight-line geometric theorem to pair the nearby deep learning features. The potential of pairwise features is justified on the classification of EMs using SVMs, k-NN, and Random Forest classifier. The pairwise features obtain outstanding results of 99.17%, 91.34%, 91.32%, 91.48%, and 99.56%, which are the increase of about 5.95%, 62.40%, 62.37%, 61.84%, and 3.23% in accuracy, F1-score, recall, precision, and specificity respectively, compared to non-paired deep learning features.
System Matrix based Reconstruction for Pulsed Sequences in Magnetic Particle Imaging
Aug 23, 2021
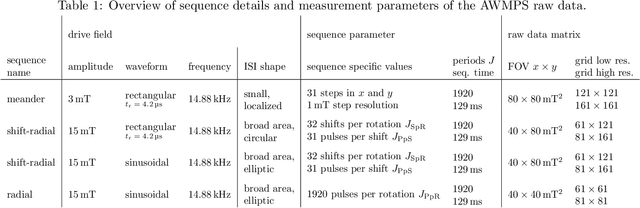
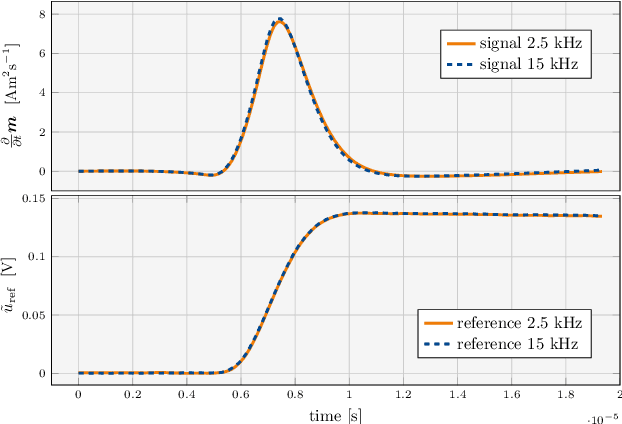
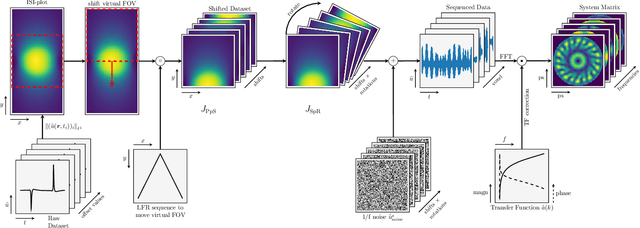
Improving resolution and sensitivity will widen possible medical applications of magnetic particle imaging in its clinical application. Pulsed excitation promises such benefits, at the cost of more complex hardware solutions and restrictions on drive field amplitude and frequency. In this work, a sequence is proposed, that combines high drive-field amplitudes and high frequency rectangular excitation. State of the art systems utilize a sinusoidal excitation to drive superparamagnetic nanoparticles into the non-linear part of their magnetization curve, which creates a spectrum with a clear separation of direct feed-through and higher harmonics caused by the particles response. One challenge for rectangular excitation is the discrimination of particle and excitation signals, both broad-band. Another is the drive-field sequence itself, as particles that are not placed at the same spatial position, may react simultaneously and are not separable by their signals phase or signal shape. This loss of information in spatial encoding is overcome in this work by utilizing a superposition of shifting fields and drive-field rotations. The software framework developed for this work processes measured data from an Arbitrary Waveform Magnetic Particle Spectrometer, which is calibrated to guarantee device independence. Multiple sequence types and waveforms are compared, based on frequency space image reconstruction from emulated signals, that are derived from these measured particle responses. A resolution of 1.0 mT (0.8 mm for a gradient of (-1.25,-1.25,2.5) T/m) in x- and y-direction was achieved and a superior sensitivity was detected on the basis of reference phantoms for the proposed sequence in this work.
DiaRet: A browser-based application for the grading of Diabetic Retinopathy with Integrated Gradients
Mar 15, 2021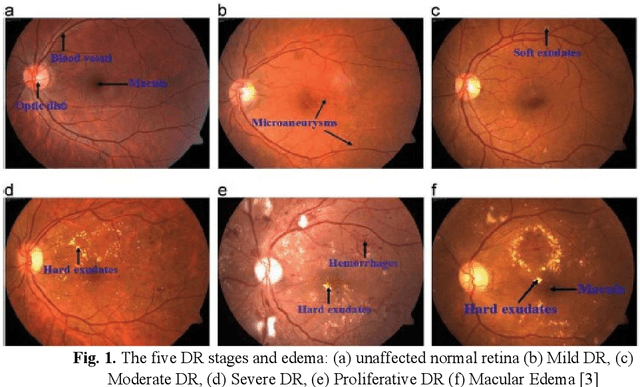



Diabetes is a metabolic disorder that results from defects in autoimmune beta-cell destruction in Type 1, peripheral resistance to insulin action in Type 2 or, most commonly, both. Patients with long-standing diabetes often fall prey to Diabetic Retinopathy (DR) resulting in changes in the retina of the human eye, which may lead to loss of vision in extreme cases. The aim of this study is two-fold: (a) create deep learning models that were trained to grade degraded retinal fundus images and (b) to create a browser-based application that will aid in diagnostic procedures by highlighting the key features of the fundus image. Deep learning has proven to be a success for computer-aided DR diagnosis resulting in early-detection and prevention of blindness. In this research work, we have emulated the images plagued by distortions by degrading the images based on multiple different combinations of Light Transmission Disturbance, Image Blurring and insertion of Retinal Artifacts. These degraded images were used for the training of multiple Deep Learning based Convolutional Neural Networks. We have trained InceptionV3, ResNet-50 and InceptionResNetV2 on multiple datasets. These models were used to classify the fundus images in terms of DR severity level. The models were further used in the creation of a browser-based application, which demonstrates the models prediction and the probability associated with each class. It will also show the Integration Gradient (IG) Attribution Mask superimposed onto the input image. The creation of the browser-based application would aid in the diagnostic procedures performed by ophthalmologists by highlighting the key features of the fundus image based on an educated prediction made by the model.
AdaAttN: Revisit Attention Mechanism in Arbitrary Neural Style Transfer
Aug 11, 2021
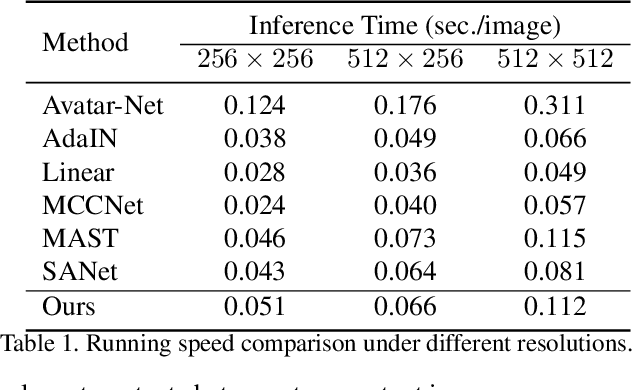
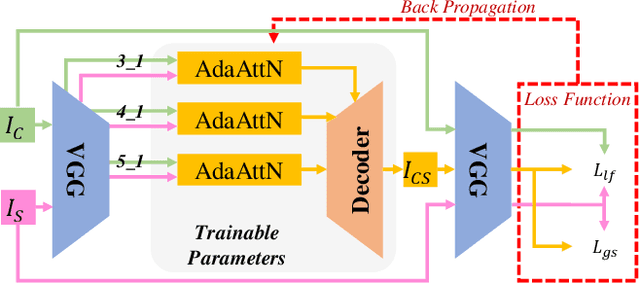

Fast arbitrary neural style transfer has attracted widespread attention from academic, industrial and art communities due to its flexibility in enabling various applications. Existing solutions either attentively fuse deep style feature into deep content feature without considering feature distributions, or adaptively normalize deep content feature according to the style such that their global statistics are matched. Although effective, leaving shallow feature unexplored and without locally considering feature statistics, they are prone to unnatural output with unpleasing local distortions. To alleviate this problem, in this paper, we propose a novel attention and normalization module, named Adaptive Attention Normalization (AdaAttN), to adaptively perform attentive normalization on per-point basis. Specifically, spatial attention score is learnt from both shallow and deep features of content and style images. Then per-point weighted statistics are calculated by regarding a style feature point as a distribution of attention-weighted output of all style feature points. Finally, the content feature is normalized so that they demonstrate the same local feature statistics as the calculated per-point weighted style feature statistics. Besides, a novel local feature loss is derived based on AdaAttN to enhance local visual quality. We also extend AdaAttN to be ready for video style transfer with slight modifications. Experiments demonstrate that our method achieves state-of-the-art arbitrary image/video style transfer. Codes and models are available.
ACCL: Adversarial constrained-CNN loss for weakly supervised medical image segmentation
May 01, 2020
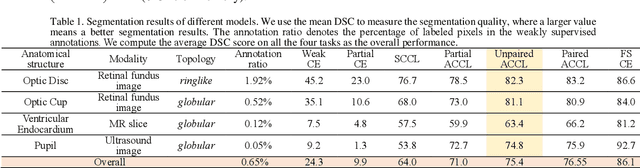
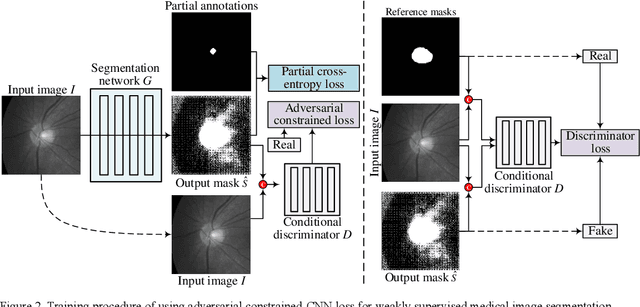
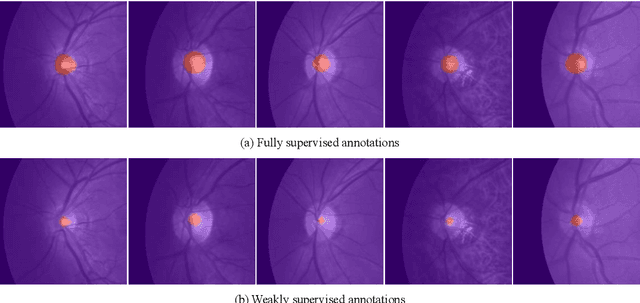
We propose adversarial constrained-CNN loss, a new paradigm of constrained-CNN loss methods, for weakly supervised medical image segmentation. In the new paradigm, prior knowledge is encoded and depicted by reference masks, and is further employed to impose constraints on segmentation outputs through adversarial learning with reference masks. Unlike pseudo label methods for weakly supervised segmentation, such reference masks are used to train a discriminator rather than a segmentation network, and thus are not required to be paired with specific images. Our new paradigm not only greatly facilitates imposing prior knowledge on network's outputs, but also provides stronger and higher-order constraints, i.e., distribution approximation, through adversarial learning. Extensive experiments involving different medical modalities, different anatomical structures, different topologies of the object of interest, different levels of prior knowledge and weakly supervised annotations with different annotation ratios is conducted to evaluate our ACCL method. Consistently superior segmentation results over the size constrained-CNN loss method have been achieved, some of which are close to the results of full supervision, thus fully verifying the effectiveness and generalization of our method. Specifically, we report an average Dice score of 75.4% with an average annotation ratio of 0.65%, surpassing the prior art, i.e., the size constrained-CNN loss method, by a large margin of 11.4%. Our codes are made publicly available at https://github.com/PengyiZhang/ACCL.
Scaling Laws for Deep Learning
Aug 17, 2021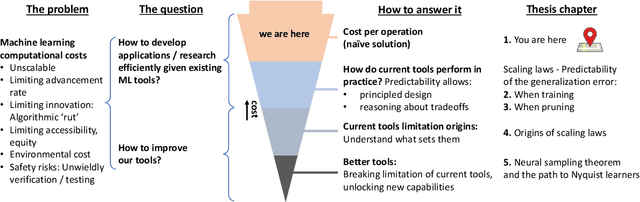
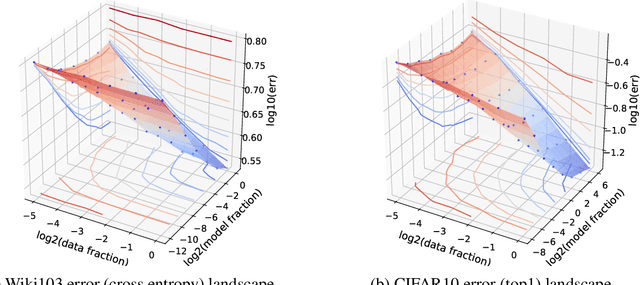
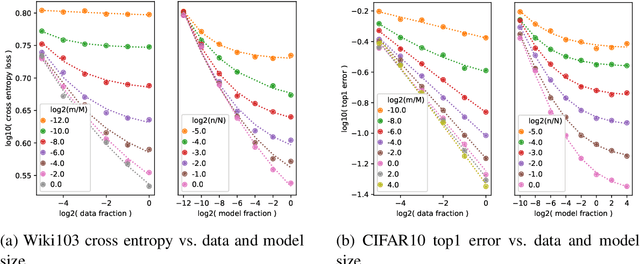
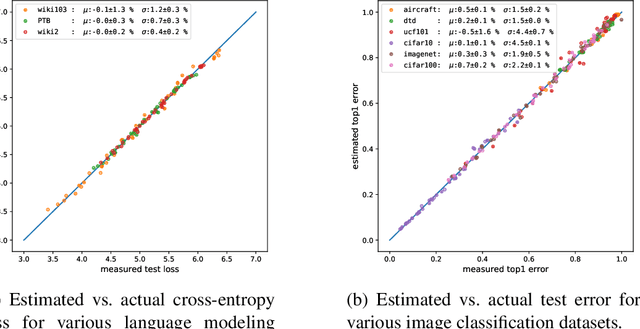
Running faster will only get you so far -- it is generally advisable to first understand where the roads lead, then get a car ... The renaissance of machine learning (ML) and deep learning (DL) over the last decade is accompanied by an unscalable computational cost, limiting its advancement and weighing on the field in practice. In this thesis we take a systematic approach to address the algorithmic and methodological limitations at the root of these costs. We first demonstrate that DL training and pruning are predictable and governed by scaling laws -- for state of the art models and tasks, spanning image classification and language modeling, as well as for state of the art model compression via iterative pruning. Predictability, via the establishment of these scaling laws, provides the path for principled design and trade-off reasoning, currently largely lacking in the field. We then continue to analyze the sources of the scaling laws, offering an approximation-theoretic view and showing through the exploration of a noiseless realizable case that DL is in fact dominated by error sources very far from the lower error limit. We conclude by building on the gained theoretical understanding of the scaling laws' origins. We present a conjectural path to eliminate one of the current dominant error sources -- through a data bandwidth limiting hypothesis and the introduction of Nyquist learners -- which can, in principle, reach the generalization error lower limit (e.g. 0 in the noiseless case), at finite dataset size.
Greedy Offset-Guided Keypoint Grouping for Human Pose Estimation
Jul 07, 2021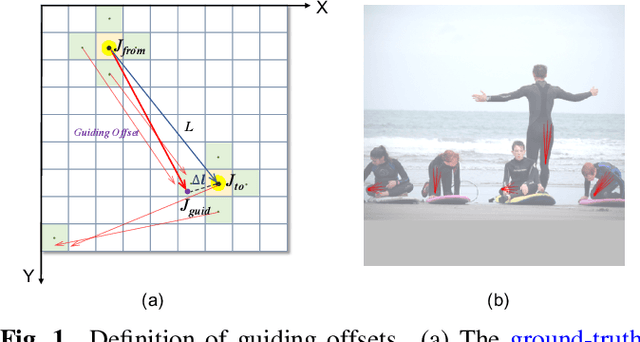
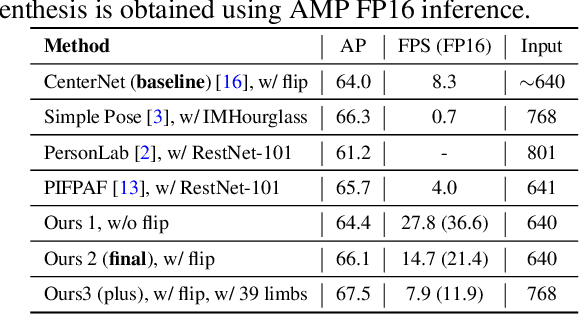
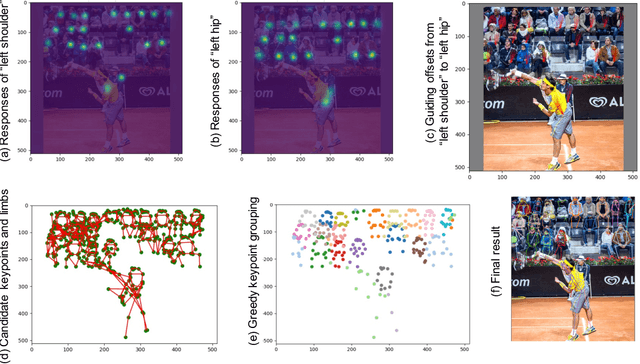

We propose a simple yet reliable bottom-up approach with a good trade-off between accuracy and efficiency for the problem of multi-person pose estimation. Given an image, we employ an Hourglass Network to infer all the keypoints from different persons indiscriminately as well as the guiding offsets connecting the adjacent keypoints belonging to the same persons. Then, we greedily group the candidate keypoints into multiple human poses (if any), utilizing the predicted guiding offsets. And we refer to this process as greedy offset-guided keypoint grouping (GOG). Moreover, we revisit the encoding-decoding method for the multi-person keypoint coordinates and reveal some important facts affecting accuracy. Experiments have demonstrated the obvious performance improvements brought by the introduced components. Our approach is comparable to the state of the art on the challenging COCO dataset under fair conditions. The source code and our pre-trained model are publicly available online.
Dual Adversarial Learning with Attention Mechanism for Fine-grained Medical Image Synthesis
Jul 07, 2019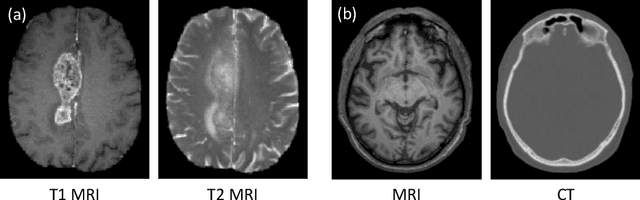
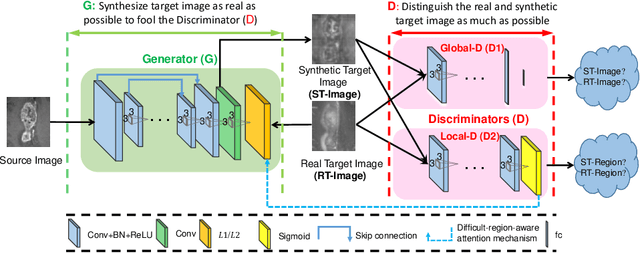

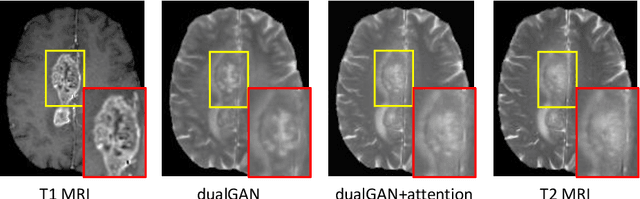
Medical imaging plays a critical role in various clinical applications. However, due to multiple considerations such as cost and risk, the acquisition of certain image modalities could be limited. To address this issue, many cross-modality medical image synthesis methods have been proposed. However, the current methods cannot well model the hard-to-synthesis regions (e.g., tumor or lesion regions). To address this issue, we propose a simple but effective strategy, that is, we propose a dual-discriminator (dual-D) adversarial learning system, in which, a global-D is used to make an overall evaluation for the synthetic image, and a local-D is proposed to densely evaluate the local regions of the synthetic image. More importantly, we build an adversarial attention mechanism which targets at better modeling hard-to-synthesize regions (e.g., tumor or lesion regions) based on the local-D. Experimental results show the robustness and accuracy of our method in synthesizing fine-grained target images from the corresponding source images. In particular, we evaluate our method on two datasets, i.e., to address the tasks of generating T2 MRI from T1 MRI for the brain tumor images and generating MRI from CT. Our method outperforms the state-of-the-art methods under comparison in all datasets and tasks. And the proposed difficult-region-aware attention mechanism is also proved to be able to help generate more realistic images, especially for the hard-to-synthesize regions.
An End-to-End Neural Network for Image Cropping by Learning Composition from Aesthetic Photos
Aug 07, 2019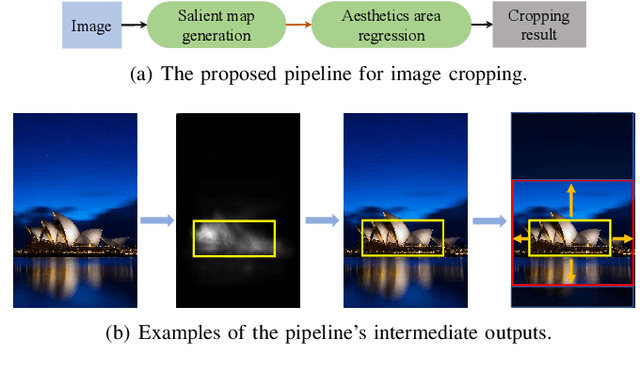
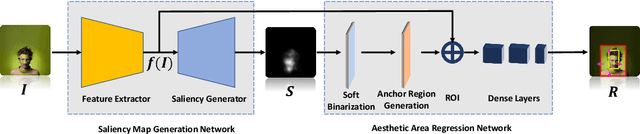
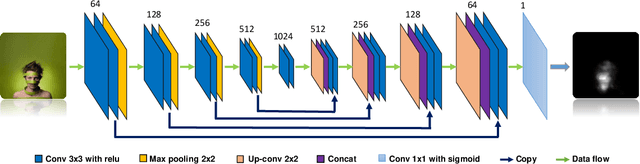

As one of the fundamental techniques for image editing, image cropping discards unrelevant contents and remains the pleasing portions of the image to enhance the overall composition and achieve better visual/aesthetic perception. In this paper, we primarily focus on improving the accuracy of automatic image cropping, and on further exploring its potential in public datasets with high efficiency. From this respect, we propose a deep learning based framework to learn the objects composition from photos with high aesthetic qualities, where an anchor region is detected through a convolutional neural network (CNN) with the Gaussian kernel to maintain the interested objects' integrity. This initial detected anchor area is then fed into a light weighted regression network to obtain the final cropping result. Unlike the conventional methods that multiple candidates are proposed and evaluated iteratively, only a single anchor region is produced in our model, which is mapped to the final output directly. Thus, low computational resources are required for the proposed approach. The experimental results on the public datasets show that both cropping accuracy and efficiency achieve the state-ofthe-art performances.
RankSRGAN: Super Resolution Generative Adversarial Networks with Learning to Rank
Jul 20, 2021
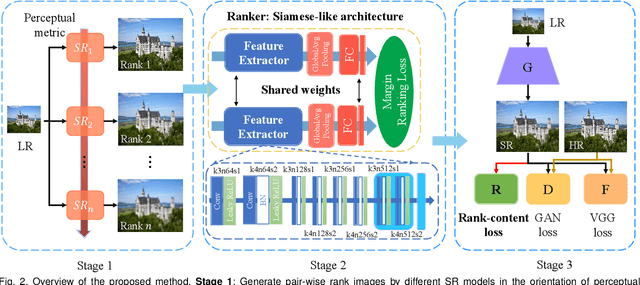

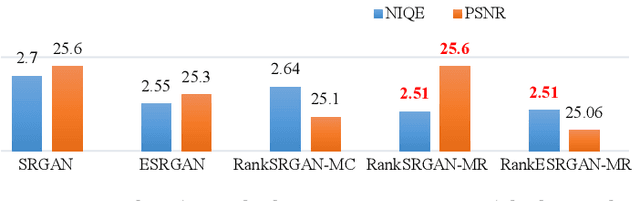
Generative Adversarial Networks (GAN) have demonstrated the potential to recover realistic details for single image super-resolution (SISR). To further improve the visual quality of super-resolved results, PIRM2018-SR Challenge employed perceptual metrics to assess the perceptual quality, such as PI, NIQE, and Ma. However, existing methods cannot directly optimize these indifferentiable perceptual metrics, which are shown to be highly correlated with human ratings. To address the problem, we propose Super-Resolution Generative Adversarial Networks with Ranker (RankSRGAN) to optimize generator in the direction of different perceptual metrics. Specifically, we first train a Ranker which can learn the behaviour of perceptual metrics and then introduce a novel rank-content loss to optimize the perceptual quality. The most appealing part is that the proposed method can combine the strengths of different SR methods to generate better results. Furthermore, we extend our method to multiple Rankers to provide multi-dimension constraints for the generator. Extensive experiments show that RankSRGAN achieves visually pleasing results and reaches state-of-the-art performance in perceptual metrics and quality. Project page: https://wenlongzhang0517.github.io/Projects/RankSRGAN