 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Mix & Match: training convnets with mixed image sizes for improved accuracy, speed and scale resiliency
Aug 12, 2019
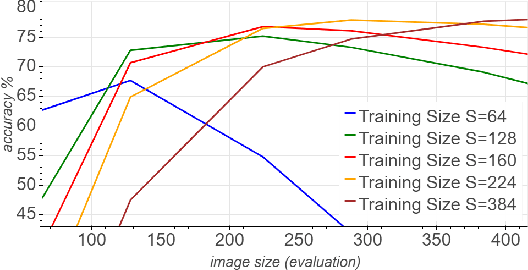
Convolutional neural networks (CNNs) are commonly trained using a fixed spatial image size predetermined for a given model. Although trained on images of aspecific size, it is well established that CNNs can be used to evaluate a wide range of image sizes at test time, by adjusting the size of intermediate feature maps. In this work, we describe and evaluate a novel mixed-size training regime that mixes several image sizes at training time. We demonstrate that models trained using our method are more resilient to image size changes and generalize well even on small images. This allows faster inference by using smaller images attest time. For instance, we receive a 76.43% top-1 accuracy using ResNet50 with an image size of 160, which matches the accuracy of the baseline model with 2x fewer computations. Furthermore, for a given image size used at test time, we show this method can be exploited either to accelerate training or the final test accuracy. For example, we are able to reach a 79.27% accuracy with a model evaluated at a 288 spatial size for a relative improvement of 14% over the baseline.
Ground Encoding: Learned Factor Graph-based Models for Localizing Ground Penetrating Radar
Mar 29, 2021

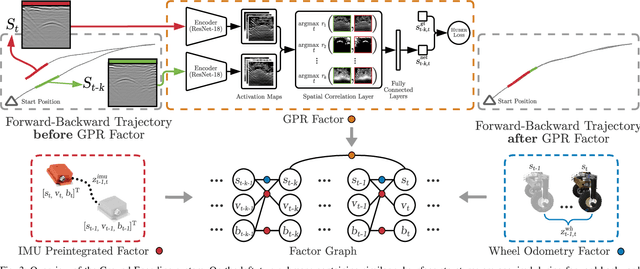

We address the problem of robot localization using ground penetrating radar (GPR) sensors. Current approaches for localization with GPR sensors require a priori maps of the system's environment as well as access to approximate global positioning (GPS) during operation. In this paper, we propose a novel, real-time GPR-based localization system for unknown and GPS-denied environments. We model the localization problem as an inference over a factor graph. Our approach combines 1D single-channel GPR measurements to form 2D image submaps. To use these GPR images in the graph, we need sensor models that can map noisy, high-dimensional image measurements into the state space. These are challenging to obtain a priori since image generation has a complex dependency on subsurface composition and radar physics, which itself varies with sensors and variations in subsurface electromagnetic properties. Our key idea is to instead learn relative sensor models directly from GPR data that map non-sequential GPR image pairs to relative robot motion. These models are incorporated as factors within the factor graph with relative motion predictions correcting for accumulated drift in the position estimates. We demonstrate our approach over datasets collected across multiple locations using a custom designed experimental rig. We show reliable, real-time localization using only GPR and odometry measurements for varying trajectories in three distinct GPS-denied environments. For our supplementary video, see https://youtu.be/HXXgdTJzqyw.
LISA: a MATLAB package for Longitudinal Image Sequence Analysis
Feb 16, 2019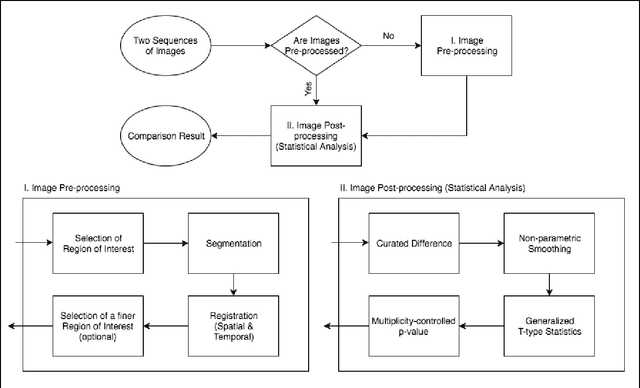

Large sequences of images (or movies) can now be obtained on an unprecedented scale, which poses fundamental challenges to the existing image analysis techniques. The challenges include heterogeneity, (automatic) alignment, multiple comparisons, potential artifacts, and hidden noises. This paper introduces our MATLAB package, Longitudinal Image Sequence Analysis (LISA), as a one-stop ensemble of image processing and analysis tool for comparing a general class of images from either different times, sessions, or subjects. Given two contrasting sequences of images, the image processing in LISA starts with selecting a region of interest in two representative images, followed by automatic or manual segmentation and registration. Automatic segmentation de-noises an image using a mixture of Gaussian distributions of the pixel intensity values, while manual segmentation applies a user-chosen intensity cut-off value to filter out noises. Automatic registration aligns the contrasting images based on a mid-line regression whereas manual registration lines up the images along a reference line formed by two user-selected points. The processed images are then rendered for simultaneous statistical comparisons to generate D, S, T, and P-maps. The D map represents a curated difference of contrasting images, the S map is the non-parametrically smoothed differences, the T map presents the variance-adjusted, smoothed differences, and the P-map provides multiplicity-controlled p-values. These maps reveal the regions with significant differences due to either longitudinal, subject-specific, or treatment changes. A user can skip the image processing step to dive directly into the statistical analysis step if the images have already been processed. Hence, LISA offers flexibility in applying other image pre-processing tools. LISA also has a parallel computing option for high definition images.
Variational Capsules for Image Analysis and Synthesis
Jul 11, 2018


A capsule is a group of neurons whose activity vector models different properties of the same entity. This paper extends the capsule to a generative version, named variational capsules (VCs). Each VC produces a latent variable for a specific entity, making it possible to integrate image analysis and image synthesis into a unified framework. Variational capsules model an image as a composition of entities in a probabilistic model. Different capsules' divergence with a specific prior distribution represents the presence of different entities, which can be applied in image analysis tasks such as classification. In addition, variational capsules encode multiple entities in a semantically-disentangling way. Diverse instantiations of capsules are related to various properties of the same entity, making it easy to generate diverse samples with fine-grained semantic attributes. Extensive experiments demonstrate that deep networks designed with variational capsules can not only achieve promising performance on image analysis tasks (including image classification and attribute prediction) but can also improve the diversity and controllability of image synthesis.
Challenges for machine learning in clinical translation of big data imaging studies
Jul 07, 2021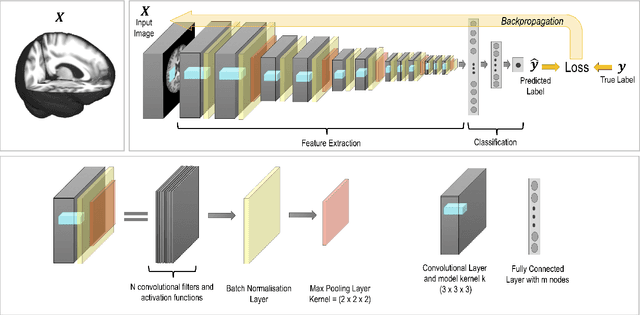

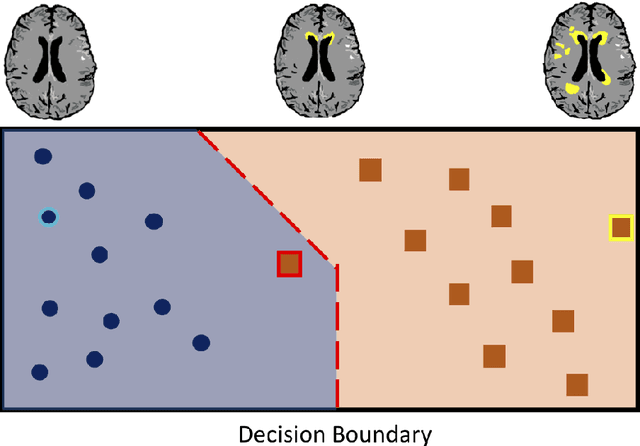
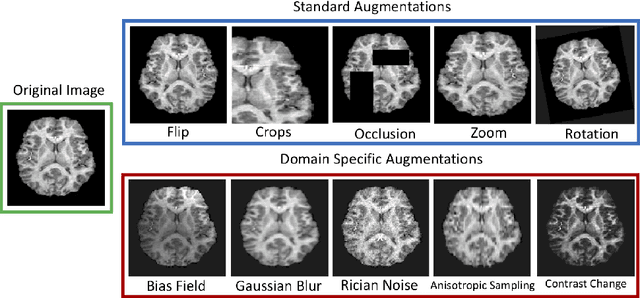
The combination of deep learning image analysis methods and large-scale imaging datasets offers many opportunities to imaging neuroscience and epidemiology. However, despite the success of deep learning when applied to many neuroimaging tasks, there remain barriers to the clinical translation of large-scale datasets and processing tools. Here, we explore the main challenges and the approaches that have been explored to overcome them. We focus on issues relating to data availability, interpretability, evaluation and logistical challenges, and discuss the challenges we believe are still to be overcome to enable the full success of big data deep learning approaches to be experienced outside of the research field.
Partial 3D Object Retrieval using Local Binary QUICCI Descriptors and Dissimilarity Tree Indexing
Jul 07, 2021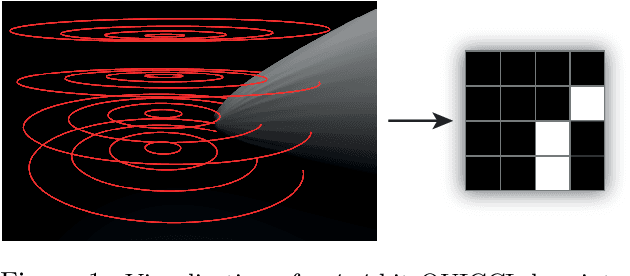

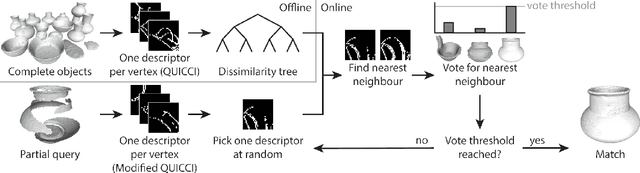
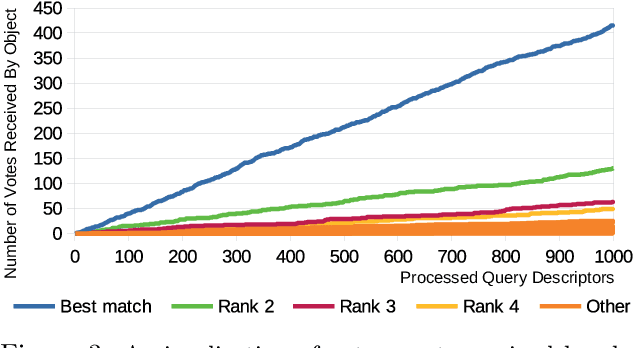
A complete pipeline is presented for accurate and efficient partial 3D object retrieval based on Quick Intersection Count Change Image (QUICCI) binary local descriptors and a novel indexing tree. It is shown how a modification to the QUICCI query descriptor makes it ideal for partial retrieval. An indexing structure called Dissimilarity Tree is proposed which can significantly accelerate searching the large space of local descriptors; this is applicable to QUICCI and other binary descriptors. The index exploits the distribution of bits within descriptors for efficient retrieval. The retrieval pipeline is tested on the artificial part of SHREC'16 dataset with near-ideal retrieval results.
CRNet: Image Super-Resolution Using A Convolutional Sparse Coding Inspired Network
Aug 03, 2019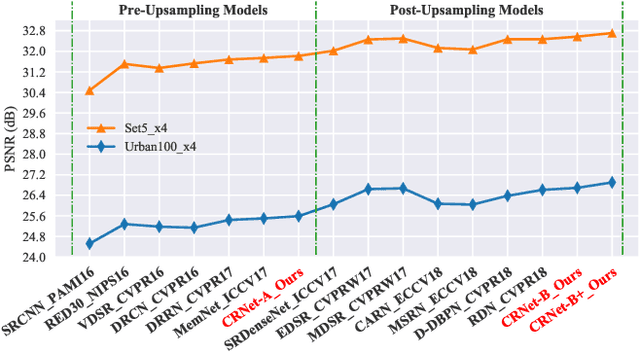
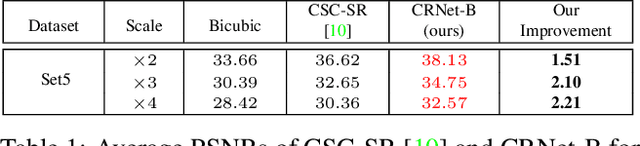

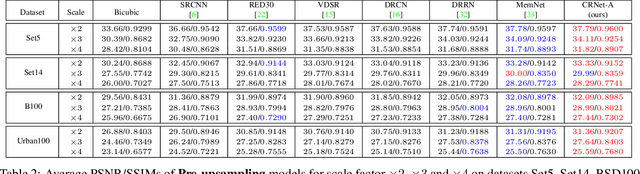
Convolutional Sparse Coding (CSC) has been attracting more and more attention in recent years, for making full use of image global correlation to improve performance on various computer vision applications. However, very few studies focus on solving CSC based image Super-Resolution (SR) problem. As a consequence, there is no significant progress in this area over a period of time. In this paper, we exploit the natural connection between CSC and Convolutional Neural Networks (CNN) to address CSC based image SR. Specifically, Convolutional Iterative Soft Thresholding Algorithm (CISTA) is introduced to solve CSC problem and it can be implemented using CNN architectures. Then we develop a novel CSC based SR framework analogy to the traditional SC based SR methods. Two models inspired by this framework are proposed for pre-/post-upsampling SR, respectively. Compared with recent state-of-the-art SR methods, both of our proposed models show superior performance in terms of both quantitative and qualitative measurements.
Stroke-Based Scene Text Erasing Using Synthetic Data
Apr 23, 2021


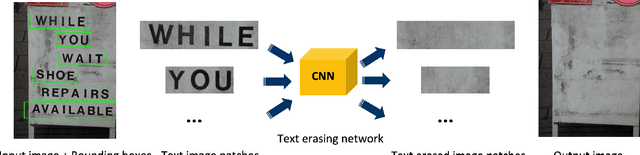
Scene text erasing, which replaces text regions with reasonable content in natural images, has drawn attention in the computer vision community in recent years. There are two potential subtasks in scene text erasing: text detection and image inpainting. Either sub-task requires considerable data to achieve better performance; however, the lack of a large-scale real-world scene-text removal dataset allows the existing methods to not work in full strength. To avoid the limitation of the lack of pairwise real-world data, we enhance and make full use of the synthetic text and consequently train our model only on the dataset generated by the improved synthetic text engine. Our proposed network contains a stroke mask prediction module and background inpainting module that can extract the text stroke as a relatively small hole from the text image patch to maintain more background content for better inpainting results. This model can partially erase text instances in a scene image with a bounding box provided or work with an existing scene text detector for automatic scene text erasing. The experimental results of qualitative evaluation and quantitative evaluation on the SCUT-Syn, ICDAR2013, and SCUT-EnsText datasets demonstrate that our method significantly outperforms existing state-of-the-art methods even when trained on real-world data.
BezierSeg: Parametric Shape Representation for Fast Object Segmentation in Medical Images
Aug 02, 2021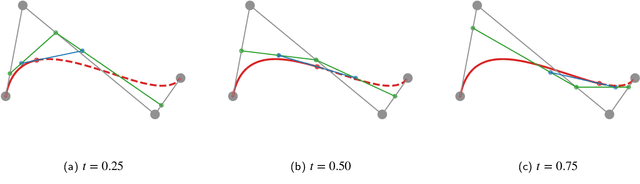
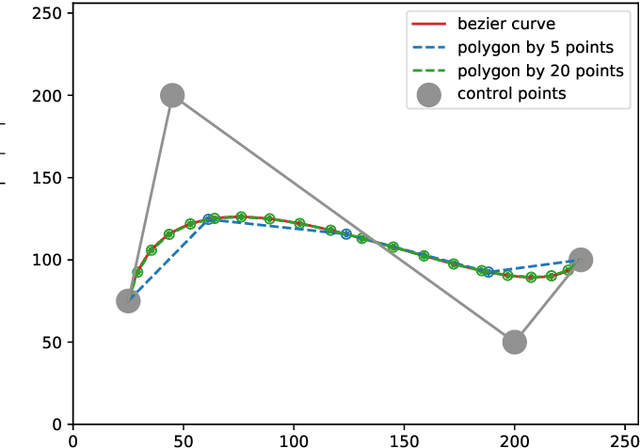
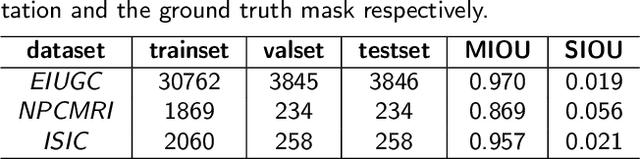
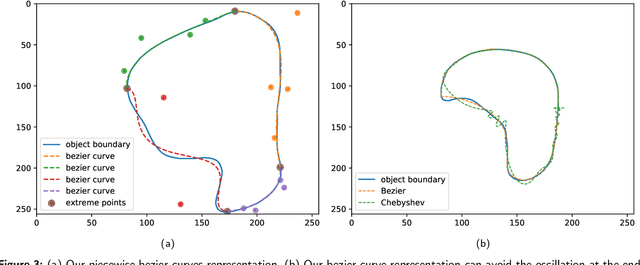
Delineating the lesion area is an important task in image-based diagnosis. Pixel-wise classification is a popular approach to segmenting the region of interest. However, at fuzzy boundaries such methods usually result in glitches, discontinuity, or disconnection, inconsistent with the fact that lesions are solid and smooth. To overcome these undesirable artifacts, we propose the BezierSeg model which outputs bezier curves encompassing the region of interest. Directly modelling the contour with analytic equations ensures that the segmentation is connected, continuous, and the boundary is smooth. In addition, it offers sub-pixel accuracy. Without loss of accuracy, the bezier contour can be resampled and overlaid with images of any resolution. Moreover, a doctor can conveniently adjust the curve's control points to refine the result. Our experiments show that the proposed method runs in real time and achieves accuracy competitive with pixel-wise segmentation models.
Offline and Online Deep Learning for Image Recognition
Mar 18, 2019
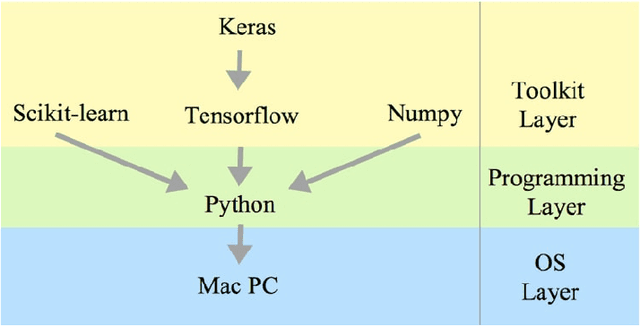
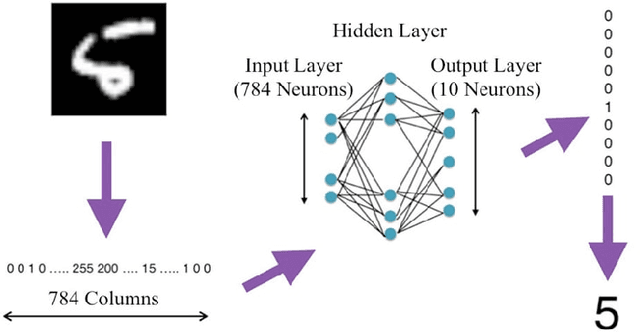
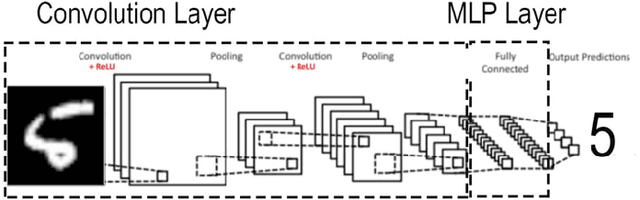
Image recognition using Deep Learning has been evolved for decades though advances in the field through different settings is still a challenge. In this paper, we present our findings in searching for better image classifiers in offline and online environments. We resort to Convolutional Neural Network and its variations of fully connected Multi-layer Perceptron. Though still preliminary, these results are encouraging and may provide a better understanding about the field and directions toward future works.
* 5 pages