 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVPBench: A Multi-Video Perception Evaluation Benchmark for Multi-Modal Video Understanding
Mar 24, 2026The rapid progress of Large Language Models (LLMs) has spurred growing interest in Multi-modal LLMs (MLLMs) and motivated the development of benchmarks to evaluate their perceptual and comprehension abilities. Existing benchmarks, however, are limited to static images or single videos, overlooking the complex interactions across multiple videos. To address this gap, we introduce the Multi-Video Perception Evaluation Benchmark (MVPBench), a new benchmark featuring 14 subtasks across diverse visual domains designed to evaluate models on extracting relevant information from video sequences to make informed decisions. MVPBench includes 5K question-answering tests involving 2.7K video clips sourced from existing datasets and manually annotated clips. Extensive evaluations reveal that current models struggle to process multi-video inputs effectively, underscoring substantial limitations in their multi-video comprehension. We anticipate MVPBench will drive advancements in multi-video perception.
Semantically Aware UAV Landing Site Assessment from Remote Sensing Imagery via Multimodal Large Language Models
Feb 01, 2026Safe UAV emergency landing requires more than just identifying flat terrain; it demands understanding complex semantic risks (e.g., crowds, temporary structures) invisible to traditional geometric sensors. In this paper, we propose a novel framework leveraging Remote Sensing (RS) imagery and Multimodal Large Language Models (MLLMs) for global context-aware landing site assessment. Unlike local geometric methods, our approach employs a coarse-to-fine pipeline: first, a lightweight semantic segmentation module efficiently pre-screens candidate areas; second, a vision-language reasoning agent fuses visual features with Point-of-Interest (POI) data to detect subtle hazards. To validate this approach, we construct and release the Emergency Landing Site Selection (ELSS) benchmark. Experiments demonstrate that our framework significantly outperforms geometric baselines in risk identification accuracy. Furthermore, qualitative results confirm its ability to generate human-like, interpretable justifications, enhancing trust in automated decision-making. The benchmark dataset is publicly accessible at https://anonymous.4open.science/r/ELSS-dataset-43D7.
AI based signage classification for linguistic landscape studies
Oct 27, 2025Linguistic Landscape (LL) research traditionally relies on manual photography and annotation of public signages to examine distribution of languages in urban space. While such methods yield valuable findings, the process is time-consuming and difficult for large study areas. This study explores the use of AI powered language detection method to automate LL analysis. Using Honolulu Chinatown as a case study, we constructed a georeferenced photo dataset of 1,449 images collected by researchers and applied AI for optical character recognition (OCR) and language classification. We also conducted manual validations for accuracy checking. This model achieved an overall accuracy of 79%. Five recurring types of mislabeling were identified, including distortion, reflection, degraded surface, graffiti, and hallucination. The analysis also reveals that the AI model treats all regions of an image equally, detecting peripheral or background texts that human interpreters typically ignore. Despite these limitations, the results demonstrate the potential of integrating AI-assisted workflows into LL research to reduce such time-consuming processes. However, due to all the limitations and mis-labels, we recognize that AI cannot be fully trusted during this process. This paper encourages a hybrid approach combining AI automation with human validation for a more reliable and efficient workflow.
The Maximum Coverage Model and Recommendation System for UAV Vertiports Location Planning
Aug 18, 2025As urban aerial mobility (UAM) infrastructure development accelerates globally, cities like Shenzhen are planning large-scale vertiport networks (e.g., 1,200+ facilities by 2026). Existing planning frameworks remain inadequate for this complexity due to historical limitations in data granularity and real-world applicability. This paper addresses these gaps by first proposing the Capacitated Dynamic Maximum Covering Location Problem (CDMCLP), a novel optimization framework that simultaneously models urban-scale spatial-temporal demand, heterogeneous user behaviors, and infrastructure capacity constraints. Building on this foundation, we introduce an Integrated Planning Recommendation System that combines CDMCLP with socio-economic factors and dynamic clustering initialization. This system leverages adaptive parameter tuning based on empirical user behavior to generate practical planning solutions. Validation in a Chinese center city demonstrates the effectiveness of the new optimization framework and recommendation system. Under the evaluation and optimization of CDMCLP, the quantitative performance of traditional location methods are exposed and can be improved by 38\%--52\%, while the recommendation system shows user-friendliness and the effective integration of complex elements. By integrating mathematical rigor with practical implementation considerations, this hybrid approach bridges the gap between theoretical location modeling and real-world UAM infrastructure planning, offering municipalities a pragmatic tool for vertiport network design.
Subsampling Winner Algorithm for Feature Selection in Large Regression Data
Feb 07, 2020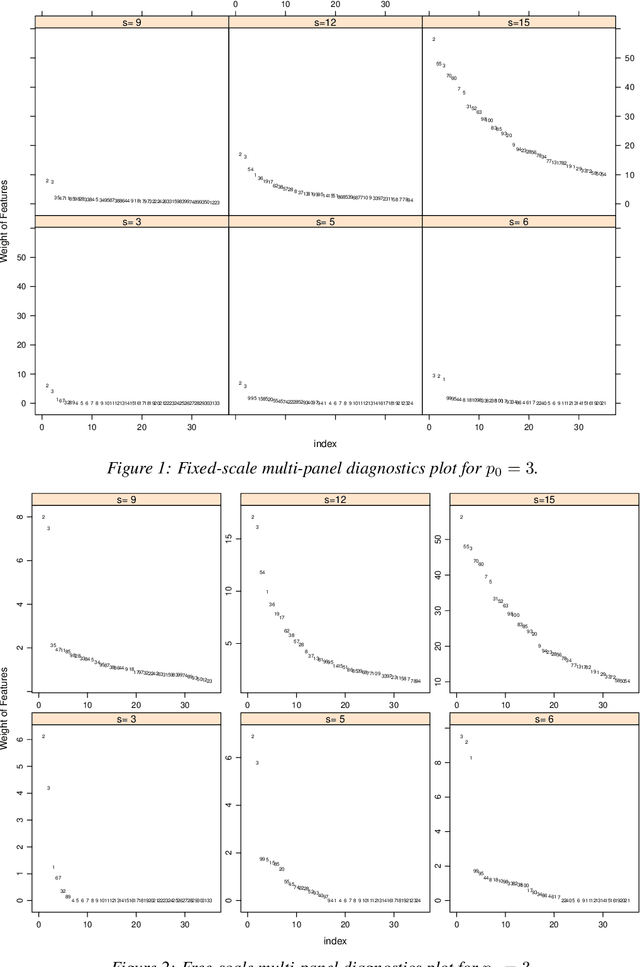
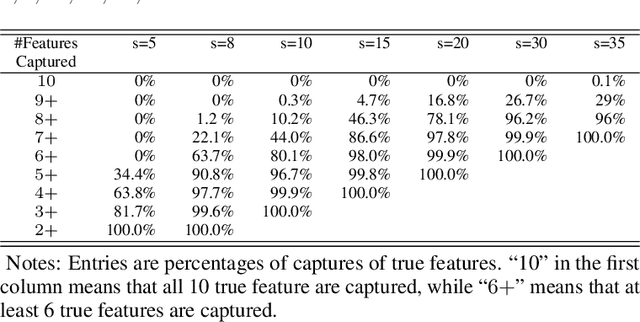

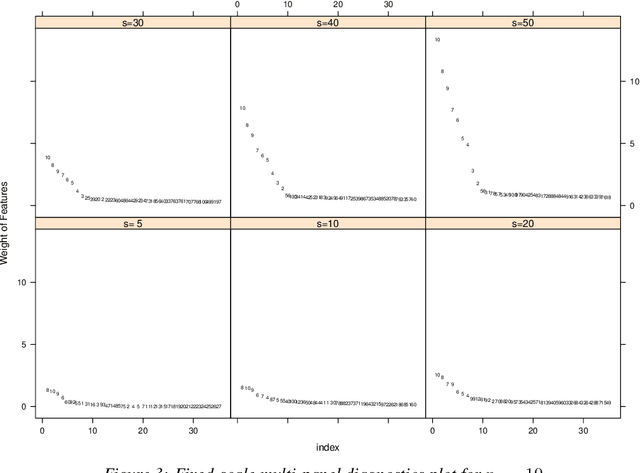
Feature selection from a large number of covariates (aka features) in a regression analysis remains a challenge in data science, especially in terms of its potential of scaling to ever-enlarging data and finding a group of scientifically meaningful features. For example, to develop new, responsive drug targets for ovarian cancer, the actual false discovery rate (FDR) of a practical feature selection procedure must also match the target FDR. The popular approach to feature selection, when true features are sparse, is to use a penalized likelihood or a shrinkage estimation, such as a LASSO, SCAD, Elastic Net, or MCP procedure (call them benchmark procedures). We present a different approach using a new subsampling method, called the Subsampling Winner algorithm (SWA). The central idea of SWA is analogous to that used for the selection of US national merit scholars. SWA uses a "base procedure" to analyze each of the subsamples, computes the scores of all features according to the performance of each feature from all subsample analyses, obtains the "semifinalist" based on the resulting scores, and then determines the "finalists," i.e., the most important features. Due to its subsampling nature, SWA can scale to data of any dimension in principle. The SWA also has the best-controlled actual FDR in comparison with the benchmark procedures and the randomForest, while having a competitive true-feature discovery rate. We also suggest practical add-on strategies to SWA with or without a penalized benchmark procedure to further assure the chance of "true" discovery. Our application of SWA to the ovarian serous cystadenocarcinoma specimens from the Broad Institute revealed functionally important genes and pathways, which we verified by additional genomics tools. This second-stage investigation is essential in the current discussion of the proper use of P-values.
LISA: a MATLAB package for Longitudinal Image Sequence Analysis
Feb 16, 2019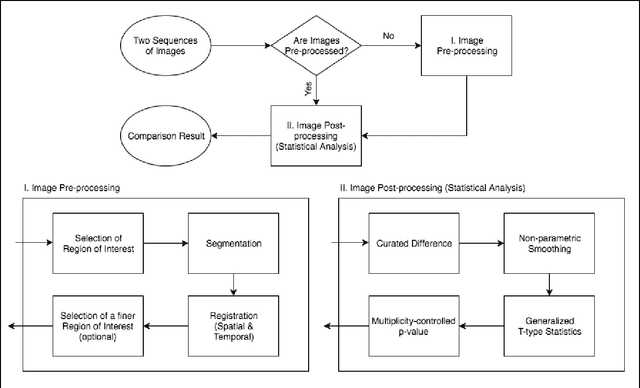

Large sequences of images (or movies) can now be obtained on an unprecedented scale, which poses fundamental challenges to the existing image analysis techniques. The challenges include heterogeneity, (automatic) alignment, multiple comparisons, potential artifacts, and hidden noises. This paper introduces our MATLAB package, Longitudinal Image Sequence Analysis (LISA), as a one-stop ensemble of image processing and analysis tool for comparing a general class of images from either different times, sessions, or subjects. Given two contrasting sequences of images, the image processing in LISA starts with selecting a region of interest in two representative images, followed by automatic or manual segmentation and registration. Automatic segmentation de-noises an image using a mixture of Gaussian distributions of the pixel intensity values, while manual segmentation applies a user-chosen intensity cut-off value to filter out noises. Automatic registration aligns the contrasting images based on a mid-line regression whereas manual registration lines up the images along a reference line formed by two user-selected points. The processed images are then rendered for simultaneous statistical comparisons to generate D, S, T, and P-maps. The D map represents a curated difference of contrasting images, the S map is the non-parametrically smoothed differences, the T map presents the variance-adjusted, smoothed differences, and the P-map provides multiplicity-controlled p-values. These maps reveal the regions with significant differences due to either longitudinal, subject-specific, or treatment changes. A user can skip the image processing step to dive directly into the statistical analysis step if the images have already been processed. Hence, LISA offers flexibility in applying other image pre-processing tools. LISA also has a parallel computing option for high definition images.