 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMARF: The Medial Atom Ray Field Object Representation
Jun 30, 2023



We propose Medial Atom Ray Fields (MARFs), a novel neural object representation that enables accurate differentiable surface rendering with a single network evaluation per camera ray. Existing neural ray fields struggle with multi-view consistency and representing surface discontinuities. MARFs address both using a medial shape representation, a dual representation of solid geometry that yields cheap geometrically grounded surface normals, in turn enabling computing analytical curvature despite the network having no second derivative. MARFs map a camera ray to multiple medial intersection candidates, subject to ray-sphere intersection testing. We illustrate how the learned medial shape quantities applies to sub-surface scattering, part segmentation, and aid representing a space of articulated shapes. Able to learn a space of shape priors, MARFs may prove useful for tasks like shape retrieval and shape completion, among others. Code and data can be found at https://github.com/pbsds/MARF.
Partial 3D Object Retrieval using Local Binary QUICCI Descriptors and Dissimilarity Tree Indexing
Jul 07, 2021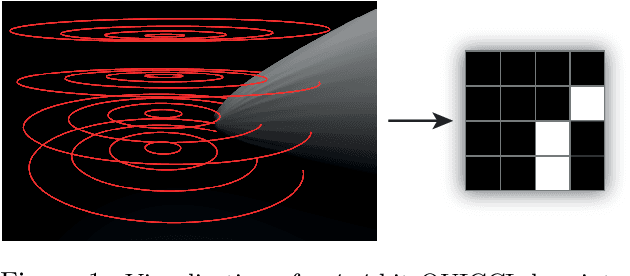

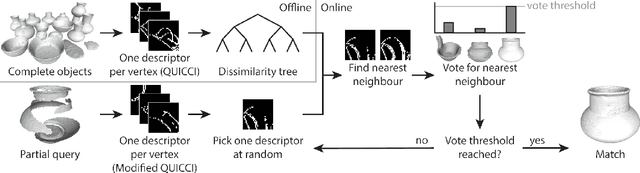
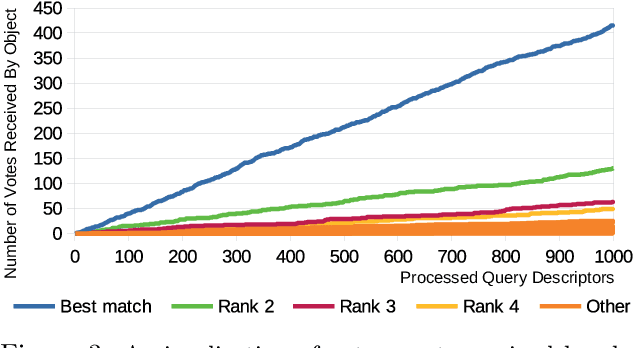
A complete pipeline is presented for accurate and efficient partial 3D object retrieval based on Quick Intersection Count Change Image (QUICCI) binary local descriptors and a novel indexing tree. It is shown how a modification to the QUICCI query descriptor makes it ideal for partial retrieval. An indexing structure called Dissimilarity Tree is proposed which can significantly accelerate searching the large space of local descriptors; this is applicable to QUICCI and other binary descriptors. The index exploits the distribution of bits within descriptors for efficient retrieval. The retrieval pipeline is tested on the artificial part of SHREC'16 dataset with near-ideal retrieval results.
An Indexing Scheme and Descriptor for 3D Object Retrieval Based on Local Shape Querying
Aug 07, 2020
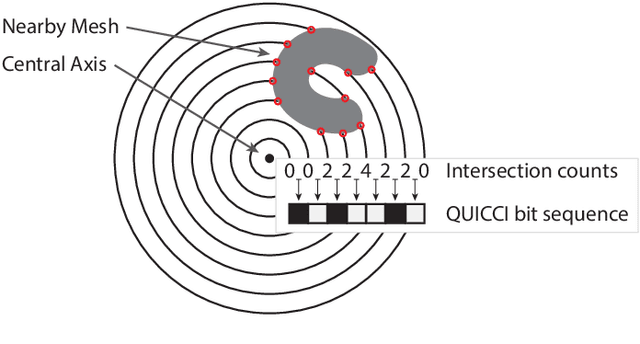
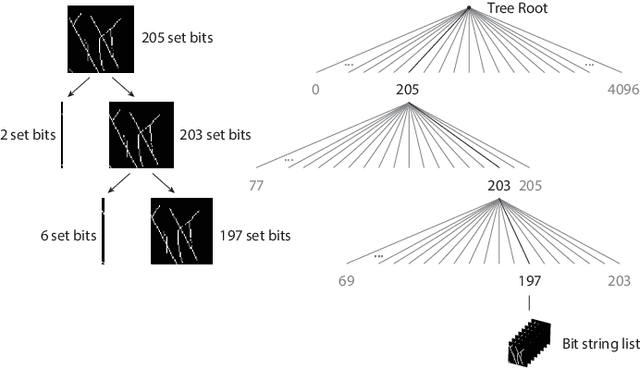
A binary descriptor indexing scheme based on Hamming distance called the Hamming tree for local shape queries is presented. A new binary clutter resistant descriptor named Quick Intersection Count Change Image (QUICCI) is also introduced. This local shape descriptor is extremely small and fast to compare. Additionally, a novel distance function called Weighted Hamming applicable to QUICCI images is proposed for retrieval applications. The effectiveness of the indexing scheme and QUICCI is demonstrated on 828 million QUICCI images derived from the SHREC2017 dataset, while the clutter resistance of QUICCI is shown using the clutterbox experiment.
Radial Intersection Count Image: a Clutter Resistant 3D Shape Descriptor
Jul 05, 2020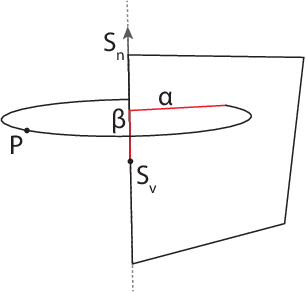

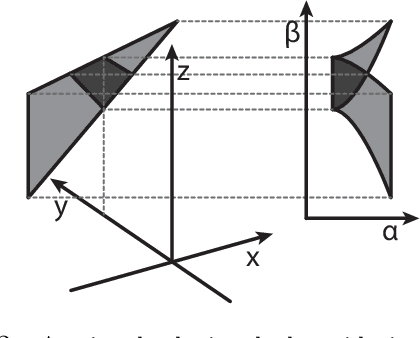
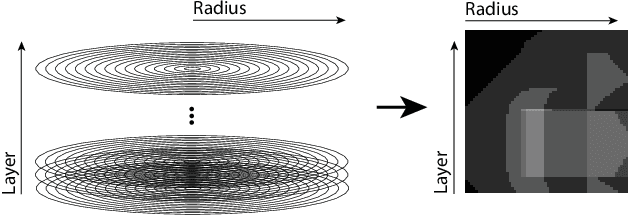
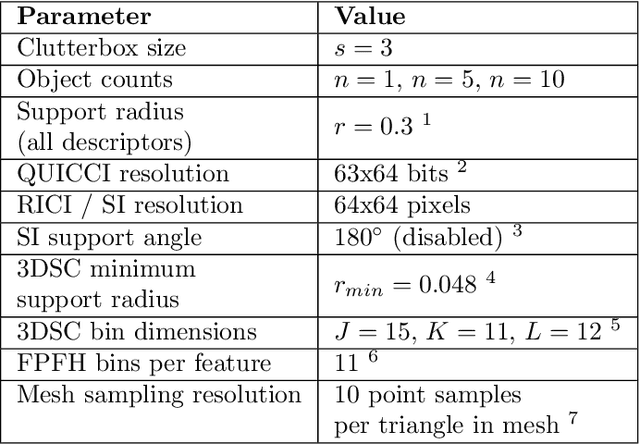
A novel shape descriptor for cluttered scenes is presented, the Radial Intersection Count Image (RICI), and is shown to significantly outperform the classic Spin Image (SI) and 3D Shape Context (3DSC) in both uncluttered and, more significantly, cluttered scenes. It is also faster to compute and compare. The clutter resistance of the RICI is mainly due to the design of a novel distance function, capable of disregarding clutter to a great extent. As opposed to the SI and 3DSC, which both count point samples, the RICI uses intersection counts with the mesh surface, and is therefore noise-free. For efficient RICI construction, novel algorithms of general interest were developed. These include an efficient circle-triangle intersection algorithm and an algorithm for projecting a point into SI-like ($\alpha$, $\beta$) coordinates. The 'clutterbox experiment' is also introduced as a better way of evaluating descriptors' response to clutter. The SI, 3DSC, and RICI are evaluated in this framework and the advantage of the RICI is clearly demonstrated.
Looking Beyond Appearances: Synthetic Training Data for Deep CNNs in Re-identification
Jan 11, 2017
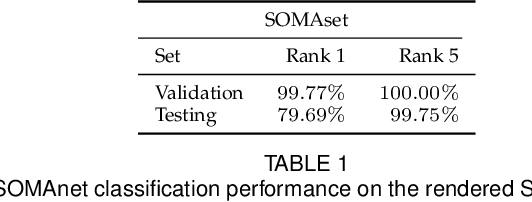
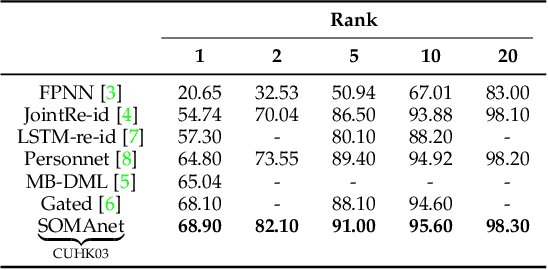
Re-identification is generally carried out by encoding the appearance of a subject in terms of outfit, suggesting scenarios where people do not change their attire. In this paper we overcome this restriction, by proposing a framework based on a deep convolutional neural network, SOMAnet, that additionally models other discriminative aspects, namely, structural attributes of the human figure (e.g. height, obesity, gender). Our method is unique in many respects. First, SOMAnet is based on the Inception architecture, departing from the usual siamese framework. This spares expensive data preparation (pairing images across cameras) and allows the understanding of what the network learned. Second, and most notably, the training data consists of a synthetic 100K instance dataset, SOMAset, created by photorealistic human body generation software. Synthetic data represents a good compromise between realistic imagery, usually not required in re-identification since surveillance cameras capture low-resolution silhouettes, and complete control of the samples, which is useful in order to customize the data w.r.t. the surveillance scenario at-hand, e.g. ethnicity. SOMAnet, trained on SOMAset and fine-tuned on recent re-identification benchmarks, outperforms all competitors, matching subjects even with different apparel. The combination of synthetic data with Inception architectures opens up new research avenues in re-identification.