 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Characterization and recognition of handwritten digits using Julia
Feb 24, 2021
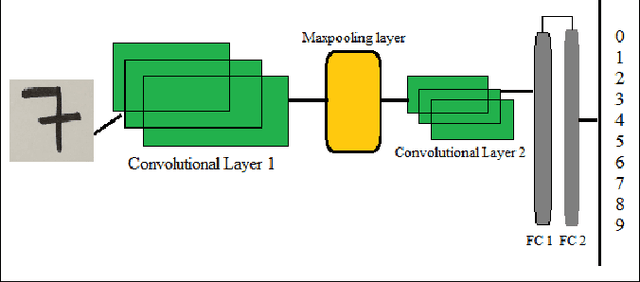
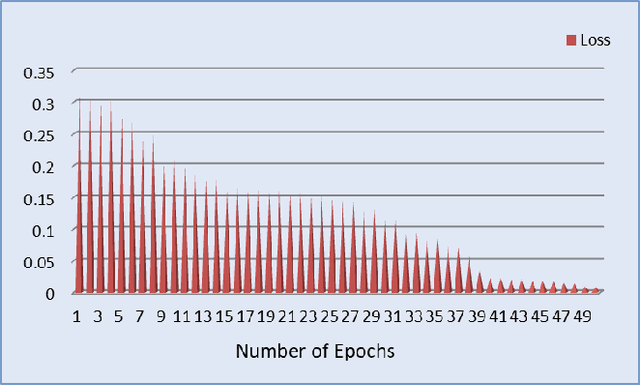
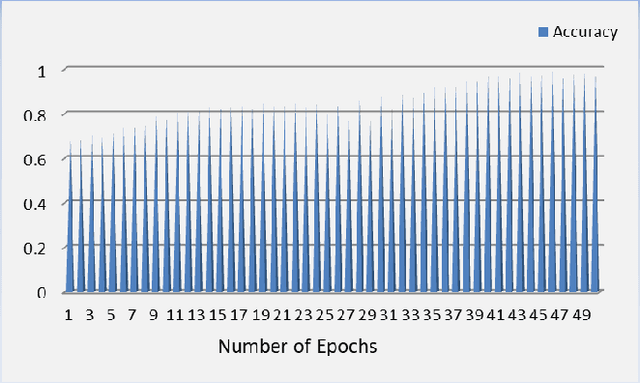
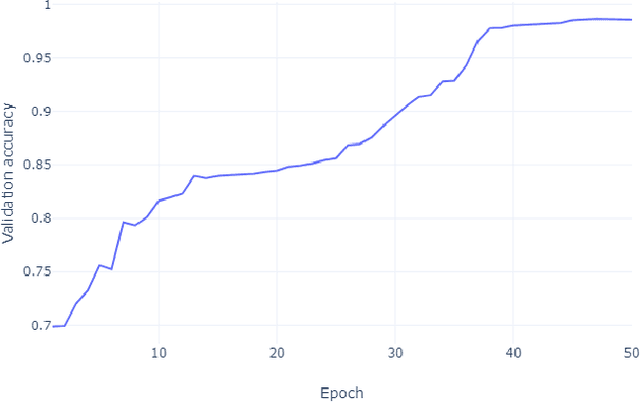
Automatic image and digit recognition is a computationally challenging task for image processing and pattern recognition, requiring an adequate appreciation of the syntactic and semantic importance of the image for the identification ofthe handwritten digits. Image and Pattern Recognition has been identified as one of the driving forces in the research areas because of its shifting of different types of applications, such as safety frameworks, clinical frameworks, diversion, and so on.In this study, for recognition, we implemented a hybrid neural network model that is capable of recognizing the digit of MNISTdataset and achieved a remarkable result. The proposed neural model network can extract features from the image and recognize the features in the layer by layer. To expand, it is so important for the neural network to recognize how the proposed modelcan work in each layer, how it can generate output, and so on. Besides, it also can recognize the auto-encoding system and the variational auto-encoding system of the MNIST dataset. This study will explore those issues that are discussed above, and the explanation for them, and how this phenomenon can be overcome.
Relation Network for Multi-label Aerial Image Classification
Jul 16, 2019
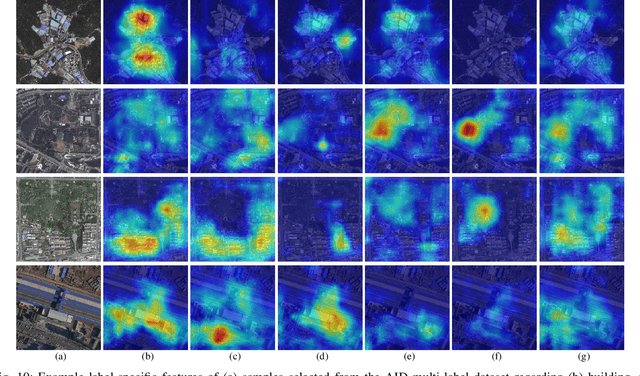
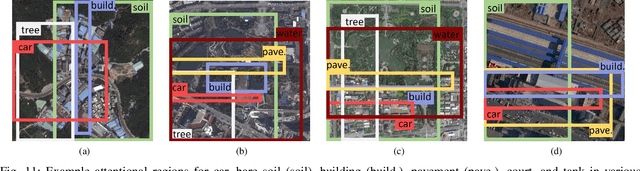
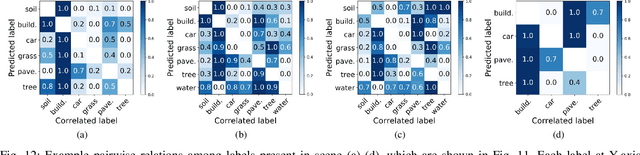
Multi-label classification plays a momentous role in perceiving intricate contents of an aerial image and triggers several related studies over the last years. However, most of them deploy few efforts in exploiting label relations, while such dependencies are crucial for making accurate predictions. Although an LSTM layer can be introduced to modeling such label dependencies in a chain propagation manner, the efficiency might be questioned when certain labels are improperly inferred. To address this, we propose a novel aerial image multi-label classification network, attention-aware label relational reasoning network. Particularly, our network consists of three elemental modules: 1) a label-wise feature parcel learning module, 2) an attentional region extraction module, and 3) a label relational inference module. To be more specific, the label-wise feature parcel learning module is designed for extracting high-level label-specific features. The attentional region extraction module aims at localizing discriminative regions in these features and yielding attentional label-specific features. The label relational inference module finally predicts label existences using label relations reasoned from outputs of the previous module. The proposed network is characterized by its capacities of extracting discriminative label-wise features in a proposal-free way and reasoning about label relations naturally and interpretably. In our experiments, we evaluate the proposed model on the UCM multi-label dataset and a newly produced dataset, AID multi-label dataset. Quantitative and qualitative results on these two datasets demonstrate the effectiveness of our model. To facilitate progress in the multi-label aerial image classification, the AID multi-label dataset will be made publicly available.
Model-Agnostic Explainability for Visual Search
Feb 28, 2021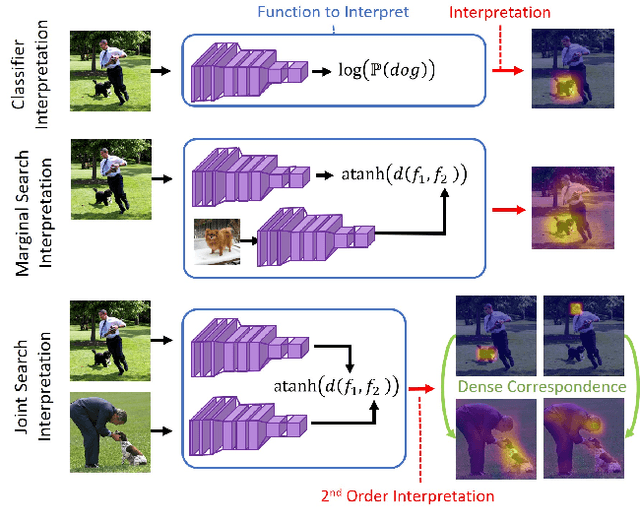
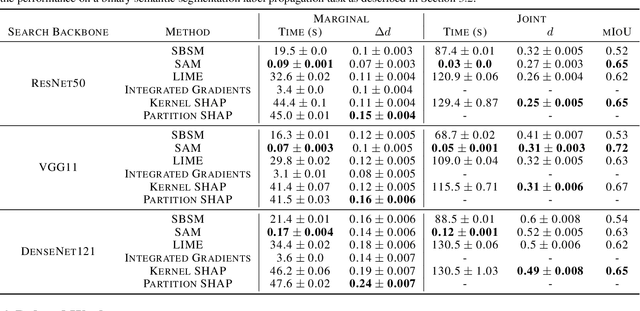


What makes two images similar? We propose new approaches to generate model-agnostic explanations for image similarity, search, and retrieval. In particular, we extend Class Activation Maps (CAMs), Additive Shapley Explanations (SHAP), and Locally Interpretable Model-Agnostic Explanations (LIME) to the domain of image retrieval and search. These approaches enable black and grey-box model introspection and can help diagnose errors and understand the rationale behind a model's similarity judgments. Furthermore, we extend these approaches to extract a full pairwise correspondence between the query and retrieved image pixels, an approach we call "joint interpretations". Formally, we show joint search interpretations arise from projecting Harsanyi dividends, and that this approach generalizes Shapley Values and The Shapley-Taylor indices. We introduce a fast kernel-based method for estimating Shapley-Taylor indices and empirically show that these game-theoretic measures yield more consistent explanations for image similarity architectures.
Event-Based Feature Tracking in Continuous Time with Sliding Window Optimization
Jul 09, 2021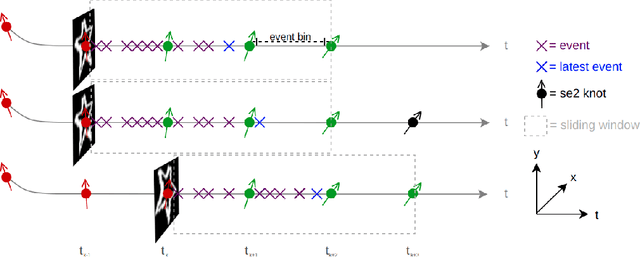
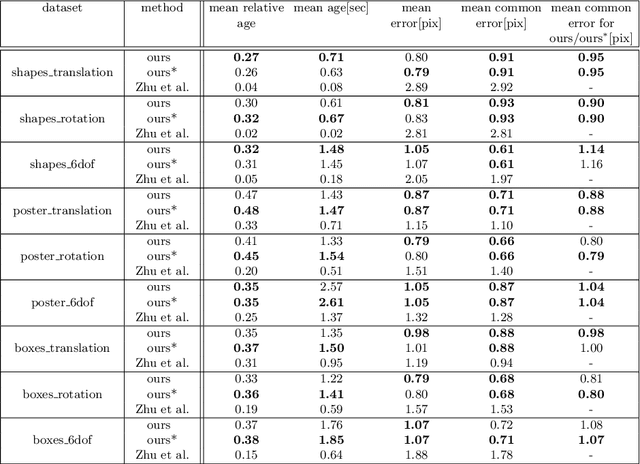
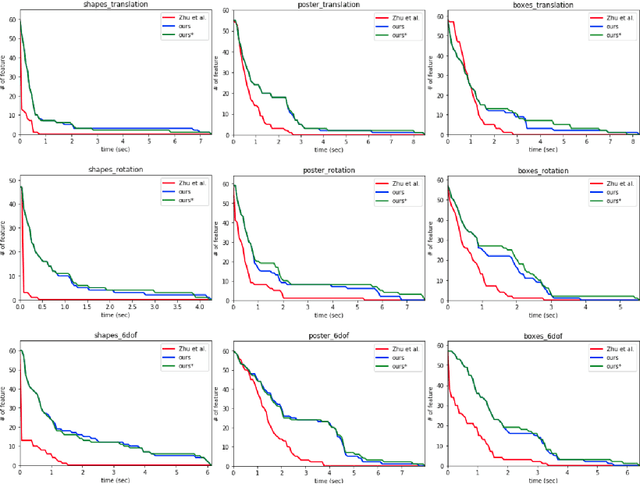

We propose a novel method for continuous-time feature tracking in event cameras. To this end, we track features by aligning events along an estimated trajectory in space-time such that the projection on the image plane results in maximally sharp event patch images. The trajectory is parameterized by $n^{th}$ order B-splines, which are continuous up to $(n-2)^{th}$ derivative. In contrast to previous work, we optimize the curve parameters in a sliding window fashion. On a public dataset we experimentally confirm that the proposed sliding-window B-spline optimization leads to longer and more accurate feature tracks than in previous work.
Cross-Subject Domain Adaptation for Multi-Frame EEG Images
Jun 12, 2021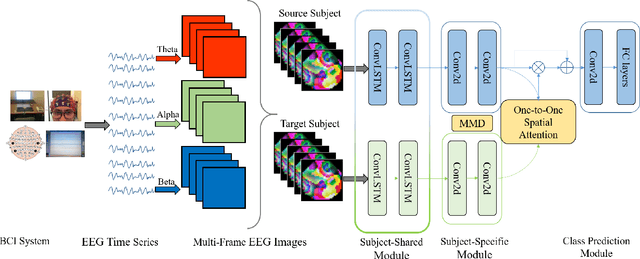

Working memory (WM) is a basic part of human cognition, which plays an important role in the study of human cognitive load. Among various brain imaging techniques, electroencephalography has shown its advantage on easy access and reliability. However, one of the critical challenges is that individual difference may cause the ineffective results, especially when the established model meets an unfamiliar subject. In this work, we propose a cross-subject deep adaptation model with spatial attention (CS-DASA) to generalize the workload classifications across subjects. First, we transform time-series EEG data into multi-frame EEG images incorporating more spatio-temporal information. First, the subject-shared module in CS-DASA receives multi-frame EEG image data from both source and target subjects and learns the common feature representations. Then, in subject-specific module, the maximum mean discrepancy is implemented to measure the domain distribution divergence in a reproducing kernel Hilbert space, which can add an effective penalty loss for domain adaptation. Additionally, the subject-to-subject spatial attention mechanism is employed to focus on the most discriminative spatial feature in EEG image data. Experiments conducted on a public WM EEG dataset containing 13 subjects show that the proposed model is capable of achieve better performance than existing state-of-the art methods.
Contextual Convolutional Neural Networks
Aug 17, 2021
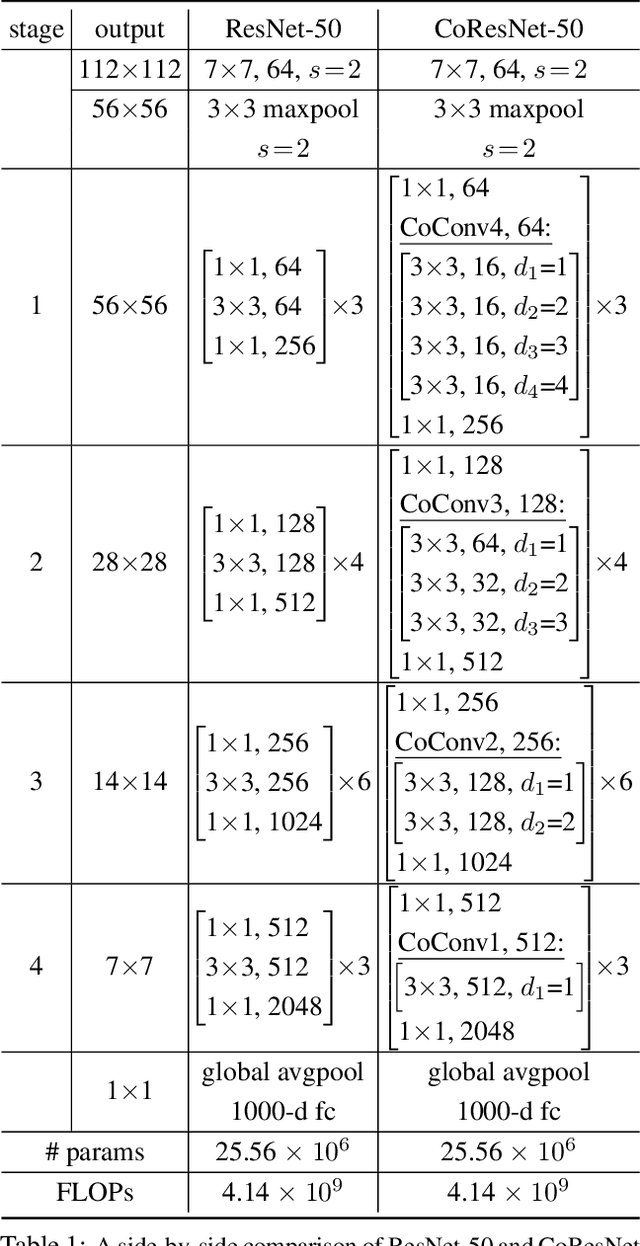
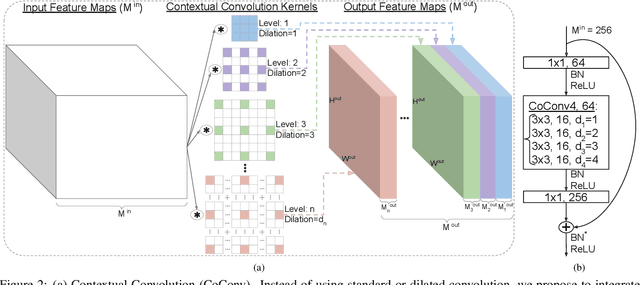

We propose contextual convolution (CoConv) for visual recognition. CoConv is a direct replacement of the standard convolution, which is the core component of convolutional neural networks. CoConv is implicitly equipped with the capability of incorporating contextual information while maintaining a similar number of parameters and computational cost compared to the standard convolution. CoConv is inspired by neuroscience studies indicating that (i) neurons, even from the primary visual cortex (V1 area), are involved in detection of contextual cues and that (ii) the activity of a visual neuron can be influenced by the stimuli placed entirely outside of its theoretical receptive field. On the one hand, we integrate CoConv in the widely-used residual networks and show improved recognition performance over baselines on the core tasks and benchmarks for visual recognition, namely image classification on the ImageNet data set and object detection on the MS COCO data set. On the other hand, we introduce CoConv in the generator of a state-of-the-art Generative Adversarial Network, showing improved generative results on CIFAR-10 and CelebA. Our code is available at https://github.com/iduta/coconv.
The Report on China-Spain Joint Clinical Testing for Rapid COVID-19 Risk Screening by Eye-region Manifestations
Sep 18, 2021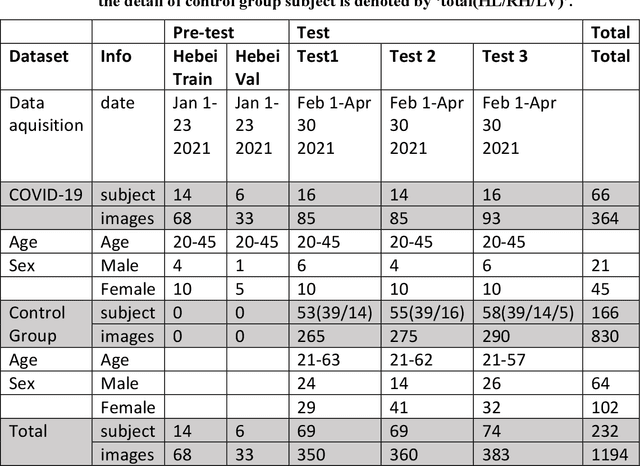

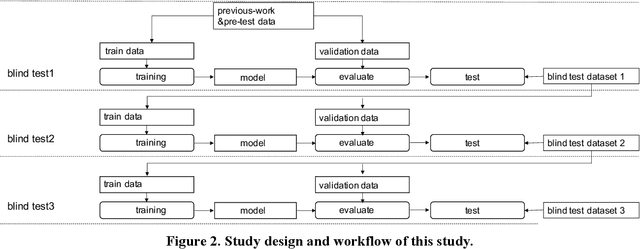
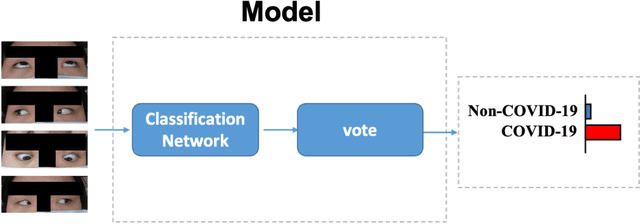
Background: The worldwide surge in coronavirus cases has led to the COVID-19 testing demand surge. Rapid, accurate, and cost-effective COVID-19 screening tests working at a population level are in imperative demand globally. Methods: Based on the eye symptoms of COVID-19, we developed and tested a COVID-19 rapid prescreening model using the eye-region images captured in China and Spain with cellphone cameras. The convolutional neural networks (CNNs)-based model was trained on these eye images to complete binary classification task of identifying the COVID-19 cases. The performance was measured using area under receiver-operating-characteristic curve (AUC), sensitivity, specificity, accuracy, and F1. The application programming interface was open access. Findings: The multicenter study included 2436 pictures corresponding to 657 subjects (155 COVID-19 infection, 23.6%) in development dataset (train and validation) and 2138 pictures corresponding to 478 subjects (64 COVID-19 infections, 13.4%) in test dataset. The image-level performance of COVID-19 prescreening model in the China-Spain multicenter study achieved an AUC of 0.913 (95% CI, 0.898-0.927), with a sensitivity of 0.695 (95% CI, 0.643-0.748), a specificity of 0.904 (95% CI, 0.891 -0.919), an accuracy of 0.875(0.861-0.889), and a F1 of 0.611(0.568-0.655). Interpretation: The CNN-based model for COVID-19 rapid prescreening has reliable specificity and sensitivity. This system provides a low-cost, fully self-performed, non-invasive, real-time feedback solution for continuous surveillance and large-scale rapid prescreening for COVID-19. Funding: This project is supported by Aimomics (Shanghai) Intelligent
LiftPool: Bidirectional ConvNet Pooling
Apr 02, 2021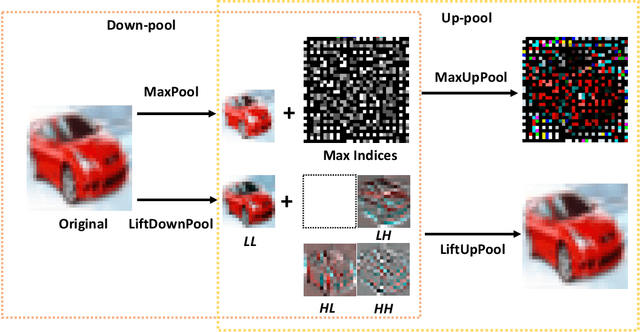
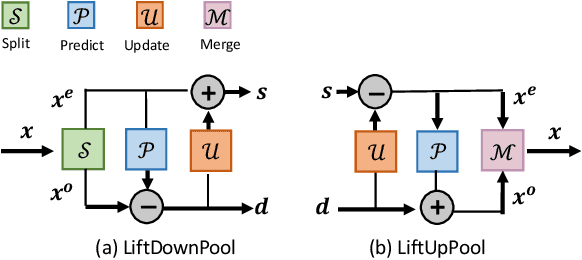
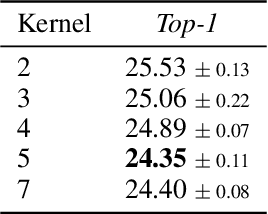
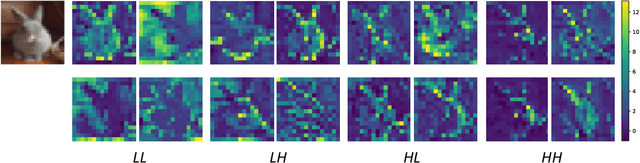
Pooling is a critical operation in convolutional neural networks for increasing receptive fields and improving robustness to input variations. Most existing pooling operations downsample the feature maps, which is a lossy process. Moreover, they are not invertible: upsampling a downscaled feature map can not recover the lost information in the downsampling. By adopting the philosophy of the classical Lifting Scheme from signal processing, we propose LiftPool for bidirectional pooling layers, including LiftDownPool and LiftUpPool. LiftDownPool decomposes a feature map into various downsized sub-bands, each of which contains information with different frequencies. As the pooling function in LiftDownPool is perfectly invertible, by performing LiftDownPool backward, a corresponding up-pooling layer LiftUpPool is able to generate a refined upsampled feature map using the detail sub-bands, which is useful for image-to-image translation challenges. Experiments show the proposed methods achieve better results on image classification and semantic segmentation, using various backbones. Moreover, LiftDownPool offers better robustness to input corruptions and perturbations.
Improving Generalization of Batch Whitening by Convolutional Unit Optimization
Aug 24, 2021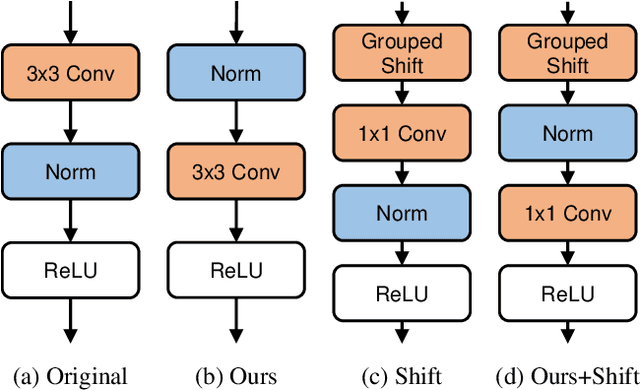
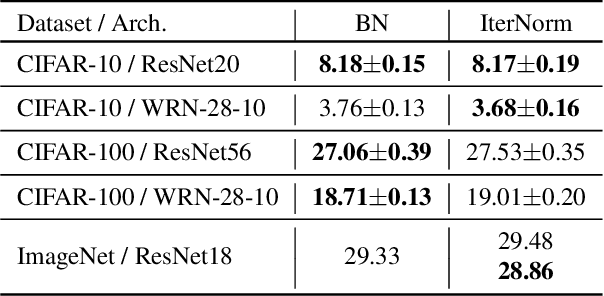
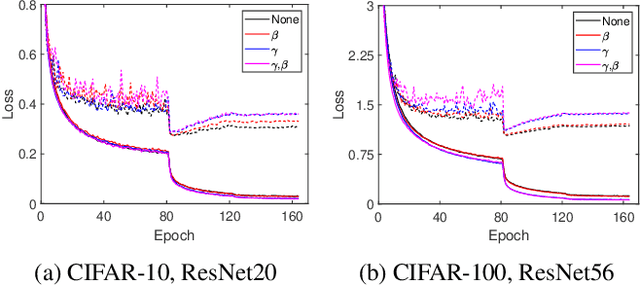
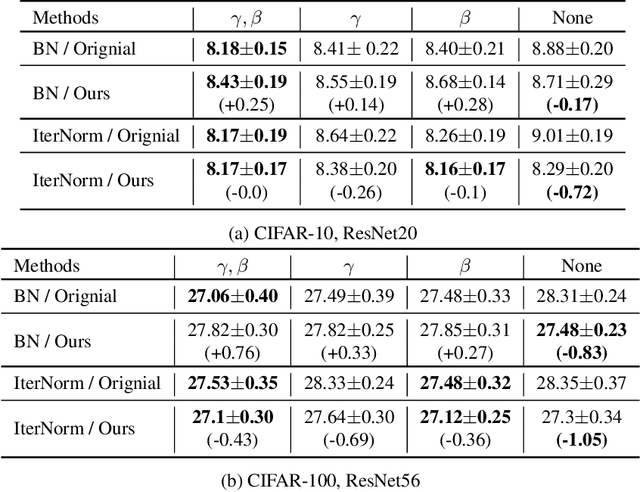
Batch Whitening is a technique that accelerates and stabilizes training by transforming input features to have a zero mean (Centering) and a unit variance (Scaling), and by removing linear correlation between channels (Decorrelation). In commonly used structures, which are empirically optimized with Batch Normalization, the normalization layer appears between convolution and activation function. Following Batch Whitening studies have employed the same structure without further analysis; even Batch Whitening was analyzed on the premise that the input of a linear layer is whitened. To bridge the gap, we propose a new Convolutional Unit that is in line with the theory, and our method generally improves the performance of Batch Whitening. Moreover, we show the inefficacy of the original Convolutional Unit by investigating rank and correlation of features. As our method is employable off-the-shelf whitening modules, we use Iterative Normalization (IterNorm), the state-of-the-art whitening module, and obtain significantly improved performance on five image classification datasets: CIFAR-10, CIFAR-100, CUB-200-2011, Stanford Dogs, and ImageNet. Notably, we verify that our method improves stability and performance of whitening when using large learning rate, group size, and iteration number.
TDLS: A Top-Down Layer Searching Algorithm for Generating Counterfactual Visual Explanation
Aug 08, 2021Explanation of AI, as well as fairness of algorithms' decisions and the transparency of the decision model, are becoming more and more important. And it is crucial to design effective and human-friendly techniques when opening the black-box model. Counterfactual conforms to the human way of thinking and provides a human-friendly explanation, and its corresponding explanation algorithm refers to a strategic alternation of a given data point so that its model output is "counter-facted", i.e. the prediction is reverted. In this paper, we adapt counterfactual explanation over fine-grained image classification problem. We demonstrated an adaptive method that could give a counterfactual explanation by showing the composed counterfactual feature map using top-down layer searching algorithm (TDLS). We have proved that our TDLS algorithm could provide more flexible counterfactual visual explanation in an efficient way using VGG-16 model on Caltech-UCSD Birds 200 dataset. At the end, we discussed several applicable scenarios of counterfactual visual explanations.