 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Large image datasets: A pyrrhic win for computer vision?
Jun 24, 2020
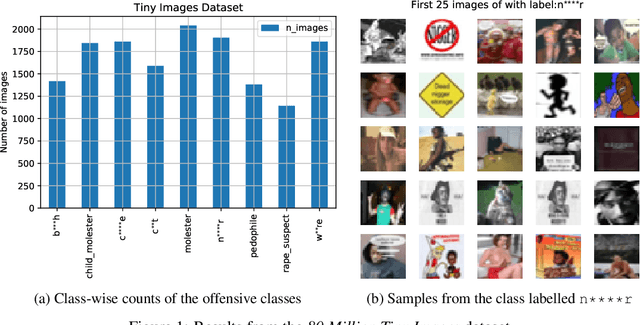

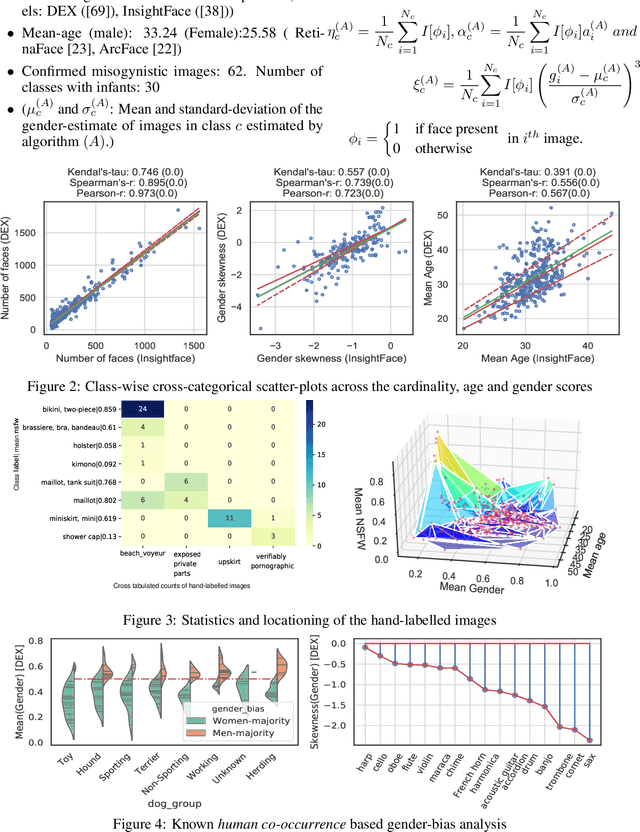
In this paper we investigate problematic practices and consequences of large scale vision datasets. We examine broad issues such as the question of consent and justice as well as specific concerns such as the inclusion of verifiably pornographic images in datasets. Taking the ImageNet-ILSVRC-2012 dataset as an example, we perform a cross-sectional model-based quantitative census covering factors such as age, gender, NSFW content scoring, class-wise accuracy, human-cardinality-analysis, and the semanticity of the image class information in order to statistically investigate the extent and subtleties of ethical transgressions. We then use the census to help hand-curate a look-up-table of images in the ImageNet-ILSVRC-2012 dataset that fall into the categories of verifiably pornographic: shot in a non-consensual setting (up-skirt), beach voyeuristic, and exposed private parts. We survey the landscape of harm and threats both society broadly and individuals face due to uncritical and ill-considered dataset curation practices. We then propose possible courses of correction and critique the pros and cons of these. We have duly open-sourced all of the code and the census meta-datasets generated in this endeavor for the computer vision community to build on. By unveiling the severity of the threats, our hope is to motivate the constitution of mandatory Institutional Review Boards (IRB) for large scale dataset curation processes.
Identifying High Accuracy Regions in Traffic Camera Images to Enhance the Estimation of Road Traffic Metrics: A Quadtree Based Method
Jun 29, 2021
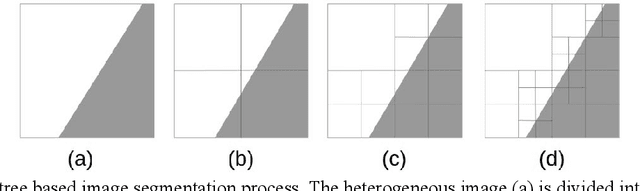

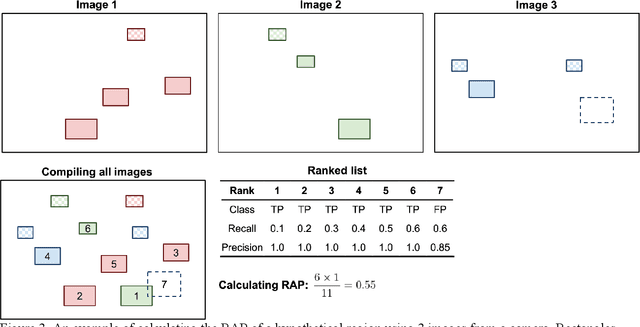
The growing number of real-time camera feeds in urban areas has made it possible to provide high-quality traffic data for effective transportation planning, operations, and management. However, deriving reliable traffic metrics from these camera feeds has been a challenge due to the limitations of current vehicle detection techniques, as well as the various camera conditions such as height and resolution. In this work, a quadtree based algorithm is developed to continuously partition the image extent until only regions with high detection accuracy are remained. These regions are referred to as the high-accuracy identification regions (HAIR) in this paper. We demonstrate how the use of the HAIR can improve the accuracy of traffic density estimates using images from traffic cameras at different heights and resolutions in Central Ohio. Our experiments show that the proposed algorithm can be used to derive robust HAIR where vehicle detection accuracy is 41 percent higher than that in the original image extent. The use of the HAIR also significantly improves the traffic density estimation with an overall decrease of 49 percent in root mean squared error.
Unsupervised Real-world Image Super Resolution via Domain-distance Aware Training
Apr 02, 2020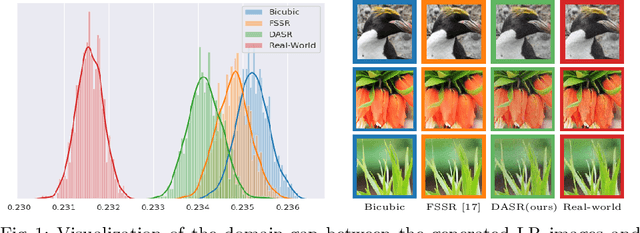
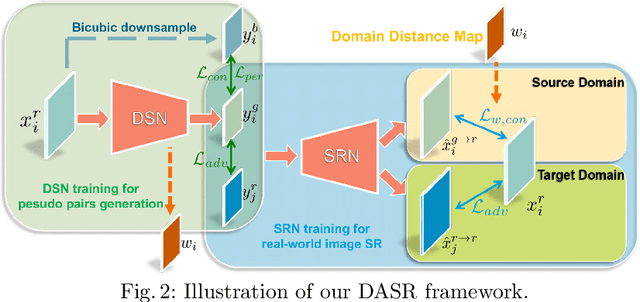
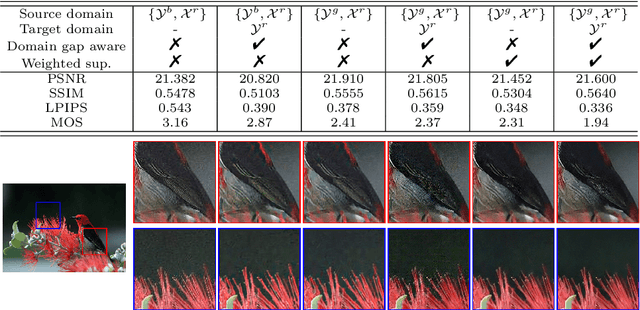
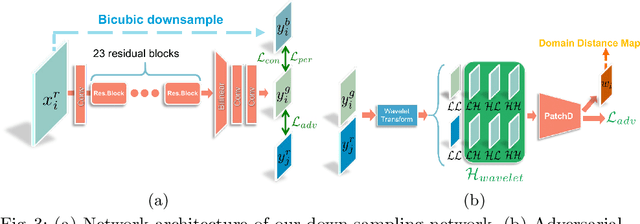
These days, unsupervised super-resolution (SR) has been soaring due to its practical and promising potential in real scenarios. The philosophy of off-the-shelf approaches lies in the augmentation of unpaired data, i.e. first generating synthetic low-resolution (LR) images $\mathcal{Y}^g$ corresponding to real-world high-resolution (HR) images $\mathcal{X}^r$ in the real-world LR domain $\mathcal{Y}^r$, and then utilizing the pseudo pairs $\{\mathcal{Y}^g, \mathcal{X}^r\}$ for training in a supervised manner. Unfortunately, since image translation itself is an extremely challenging task, the SR performance of these approaches are severely limited by the domain gap between generated synthetic LR images and real LR images. In this paper, we propose a novel domain-distance aware super-resolution (DASR) approach for unsupervised real-world image SR. The domain gap between training data (e.g. $\mathcal{Y}^g$) and testing data (e.g. $\mathcal{Y}^r$) is addressed with our \textbf{domain-gap aware training} and \textbf{domain-distance weighted supervision} strategies. Domain-gap aware training takes additional benefit from real data in the target domain while domain-distance weighted supervision brings forward the more rational use of labeled source domain data. The proposed method is validated on synthetic and real datasets and the experimental results show that DASR consistently outperforms state-of-the-art unsupervised SR approaches in generating SR outputs with more realistic and natural textures.
Semantic sentence similarity: size does not always matter
Jun 16, 2021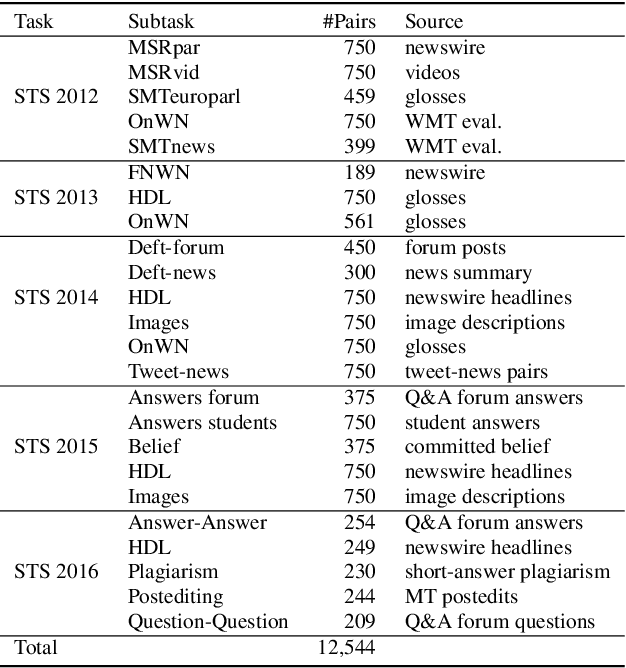
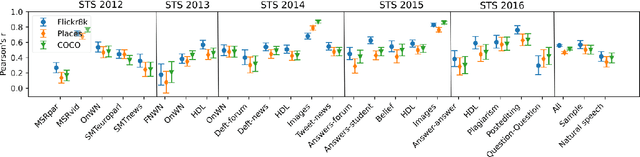
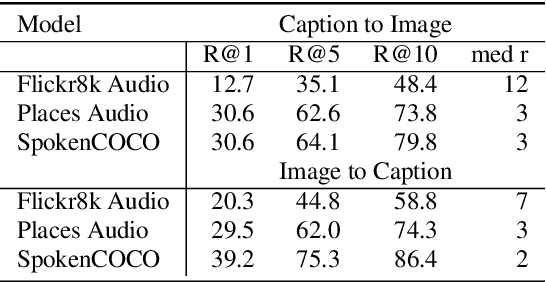
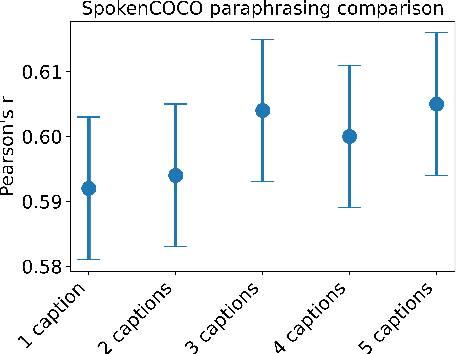
This study addresses the question whether visually grounded speech recognition (VGS) models learn to capture sentence semantics without access to any prior linguistic knowledge. We produce synthetic and natural spoken versions of a well known semantic textual similarity database and show that our VGS model produces embeddings that correlate well with human semantic similarity judgements. Our results show that a model trained on a small image-caption database outperforms two models trained on much larger databases, indicating that database size is not all that matters. We also investigate the importance of having multiple captions per image and find that this is indeed helpful even if the total number of images is lower, suggesting that paraphrasing is a valuable learning signal. While the general trend in the field is to create ever larger datasets to train models on, our findings indicate other characteristics of the database can just as important important.
Task Decomposition and Synchronization for Semantic Biomedical Image Segmentation
May 21, 2019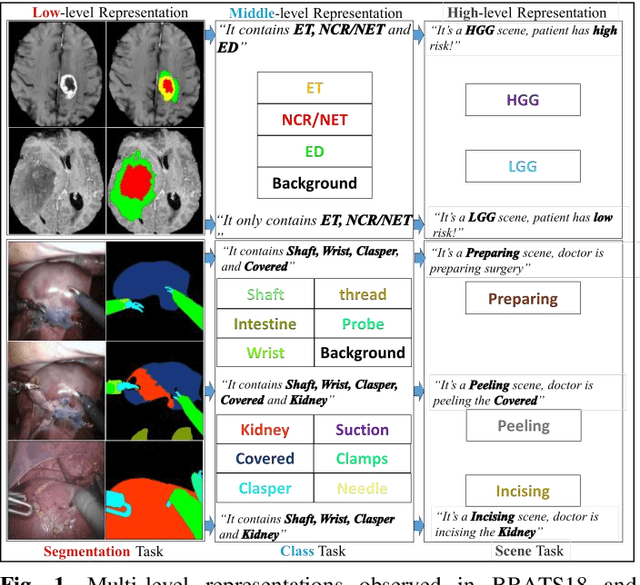

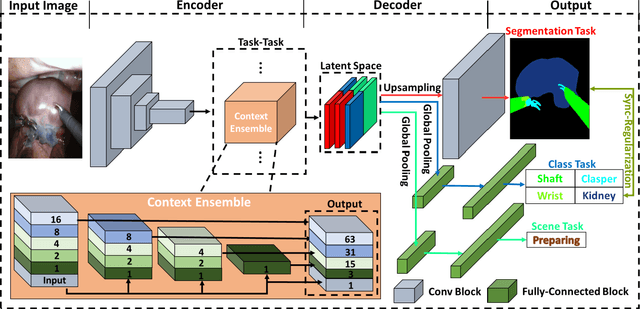
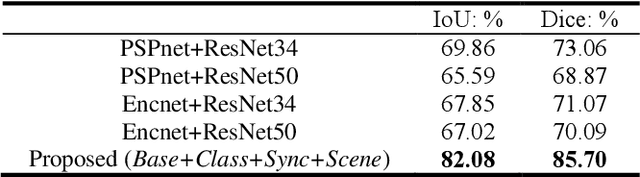
Semantic segmentation is essentially important to biomedical image analysis. Many recent works mainly focus on integrating the Fully Convolutional Network (FCN) architecture with sophisticated convolution implementation and deep supervision. In this paper, we propose to decompose the single segmentation task into three subsequent sub-tasks, including (1) pixel-wise image segmentation, (2) prediction of the class labels of the objects within the image, and (3) classification of the scene the image belonging to. While these three sub-tasks are trained to optimize their individual loss functions of different perceptual levels, we propose to let them interact by the task-task context ensemble. Moreover, we propose a novel sync-regularization to penalize the deviation between the outputs of the pixel-wise segmentation and the class prediction tasks. These effective regularizations help FCN utilize context information comprehensively and attain accurate semantic segmentation, even though the number of the images for training may be limited in many biomedical applications. We have successfully applied our framework to three diverse 2D/3D medical image datasets, including Robotic Scene Segmentation Challenge 18 (ROBOT18), Brain Tumor Segmentation Challenge 18 (BRATS18), and Retinal Fundus Glaucoma Challenge (REFUGE18). We have achieved top-tier performance in all three challenges.
Deep Long-Tailed Learning: A Survey
Oct 09, 2021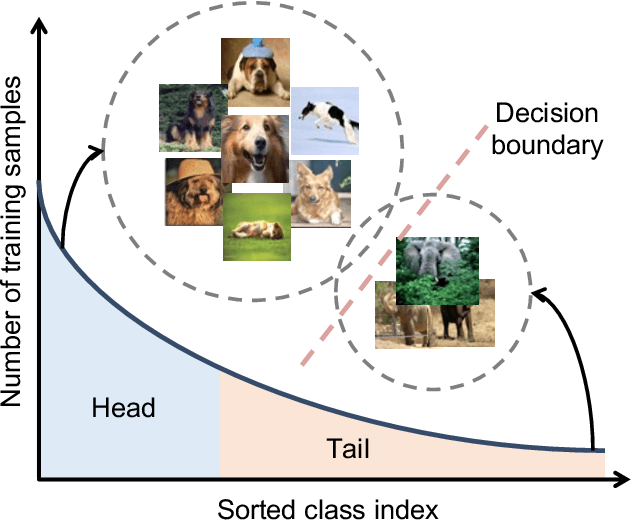
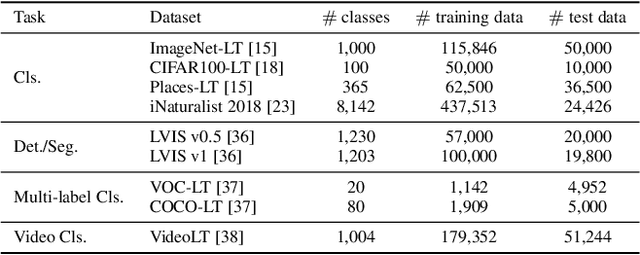
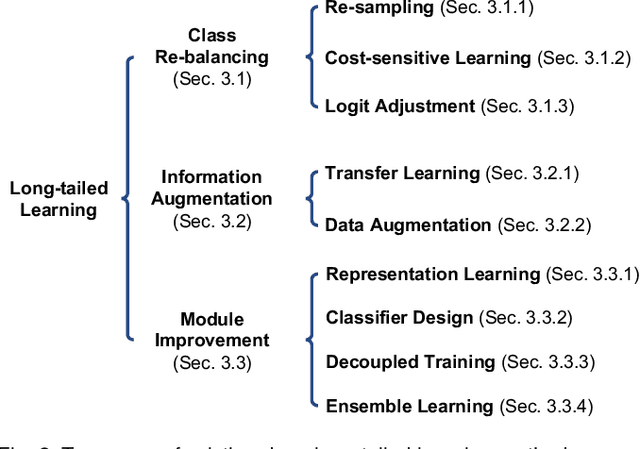
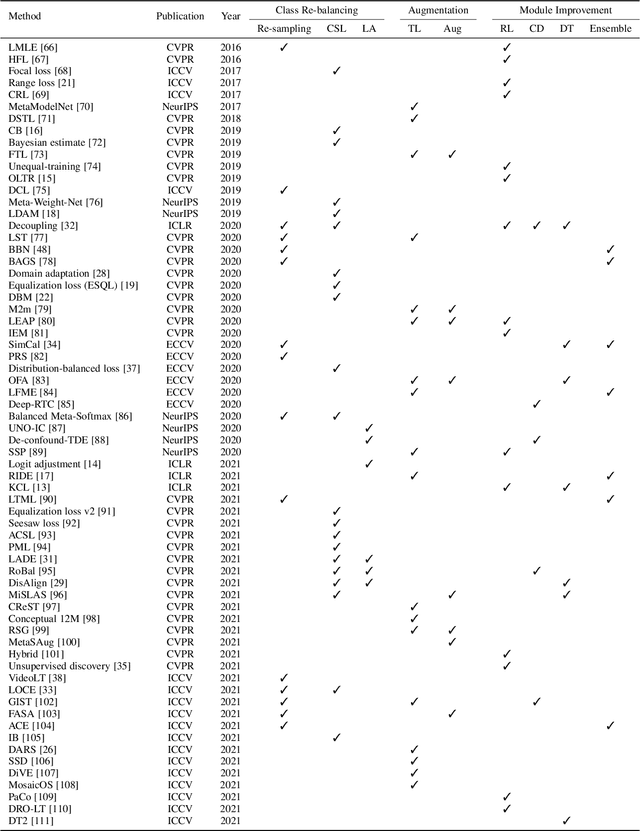
Deep long-tailed learning, one of the most challenging problems in visual recognition, aims to train well-performing deep models from a large number of images that follow a long-tailed class distribution. In the last decade, deep learning has emerged as a powerful recognition model for learning high-quality image representations and has led to remarkable breakthroughs in generic visual recognition. However, long-tailed class imbalance, a common problem in practical visual recognition tasks, often limits the practicality of deep network based recognition models in real-world applications, since they can be easily biased towards dominant classes and perform poorly on tail classes. To address this problem, a large number of studies have been conducted in recent years, making promising progress in the field of deep long-tailed learning. Considering the rapid evolution of this field, this paper aims to provide a comprehensive survey on recent advances in deep long-tailed learning. To be specific, we group existing deep long-tailed learning studies into three main categories (i.e., class re-balancing, information augmentation and module improvement), and review these methods following this taxonomy in detail. Afterward, we empirically analyze several state-of-the-art methods by evaluating to what extent they address the issue of class imbalance via a newly proposed evaluation metric, i.e., relative accuracy. We conclude the survey by highlighting important applications of deep long-tailed learning and identifying several promising directions for future research.
Image Reconstruction with Predictive Filter Flow
Nov 28, 2018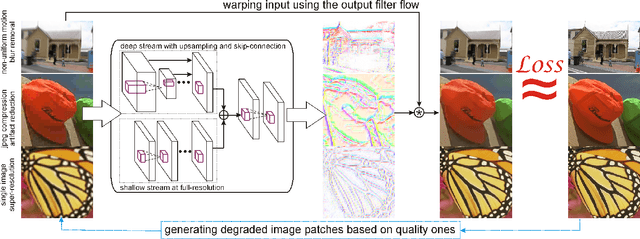
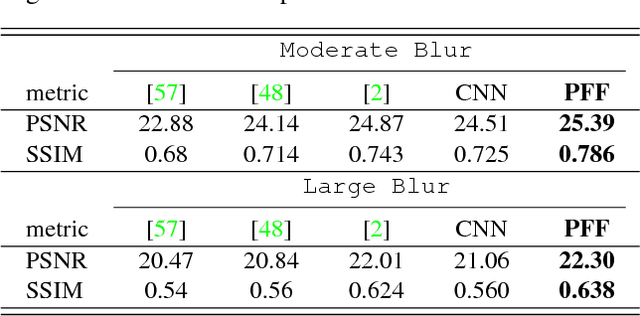

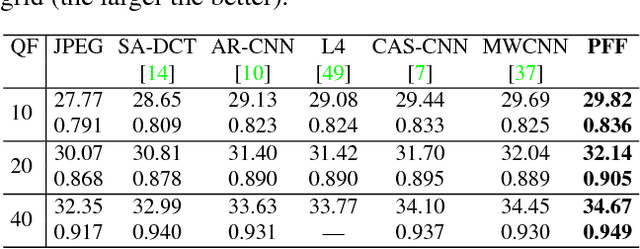
We propose a simple, interpretable framework for solving a wide range of image reconstruction problems such as denoising and deconvolution. Given a corrupted input image, the model synthesizes a spatially varying linear filter which, when applied to the input image, reconstructs the desired output. The model parameters are learned using supervised or self-supervised training. We test this model on three tasks: non-uniform motion blur removal, lossy-compression artifact reduction and single image super resolution. We demonstrate that our model substantially outperforms state-of-the-art methods on all these tasks and is significantly faster than optimization-based approaches to deconvolution. Unlike models that directly predict output pixel values, the predicted filter flow is controllable and interpretable, which we demonstrate by visualizing the space of predicted filters for different tasks.
Cross-Region Domain Adaptation for Class-level Alignment
Sep 14, 2021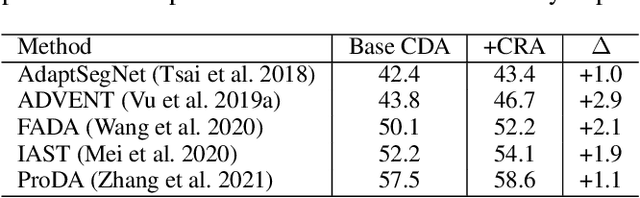
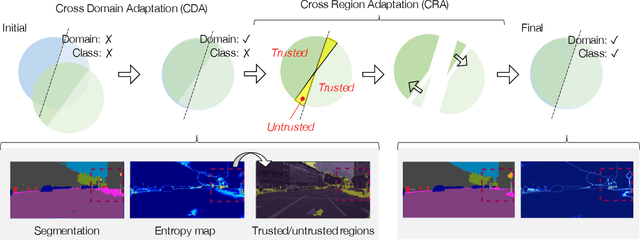
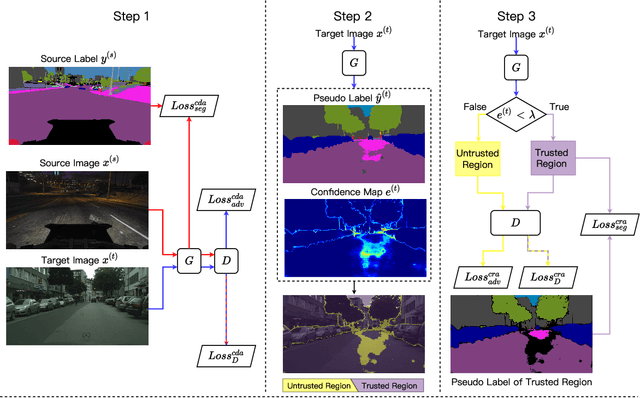
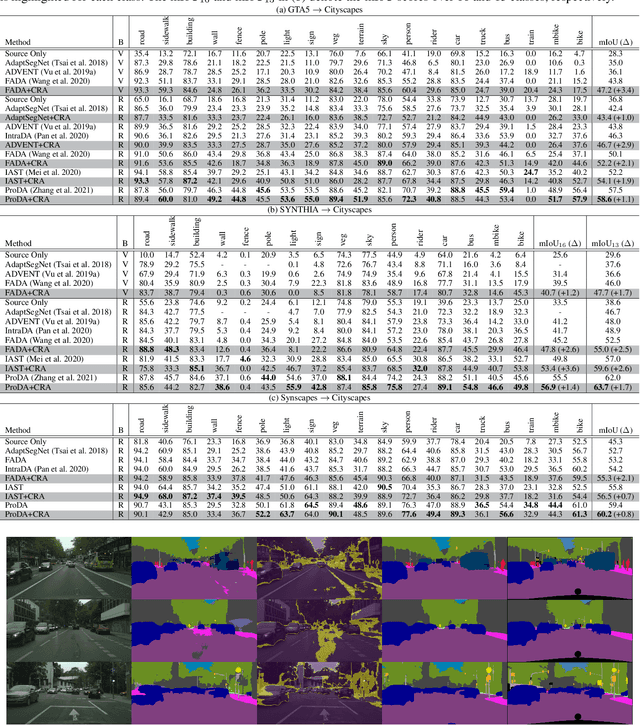
Semantic segmentation requires a lot of training data, which necessitates costly annotation. There have been many studies on unsupervised domain adaptation (UDA) from one domain to another, e.g., from computer graphics to real images. However, there is still a gap in accuracy between UDA and supervised training on native domain data. It is arguably attributable to class-level misalignment between the source and target domain data. To cope with this, we propose a method that applies adversarial training to align two feature distributions in the target domain. It uses a self-training framework to split the image into two regions (i.e., trusted and untrusted), which form two distributions to align in the feature space. We term this approach cross-region adaptation (CRA) to distinguish from the previous methods of aligning different domain distributions, which we call cross-domain adaptation (CDA). CRA can be applied after any CDA method. Experimental results show that this always improves the accuracy of the combined CDA method, having updated the state-of-the-art.
Interpreting and improving deep-learning models with reality checks
Aug 19, 2021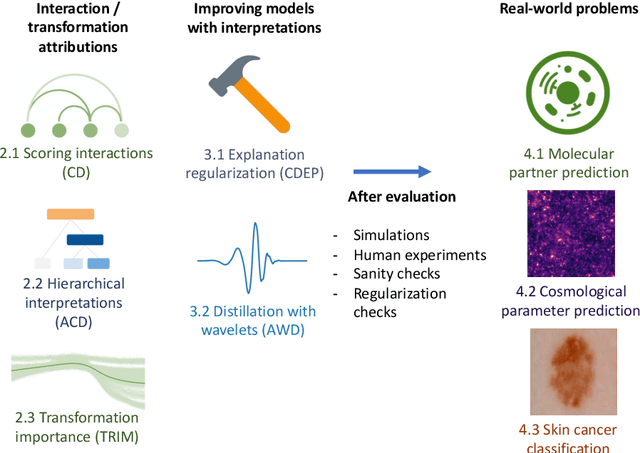

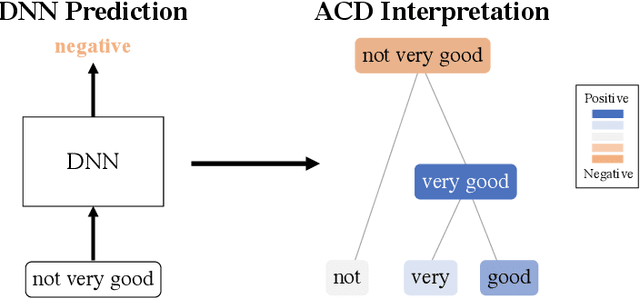
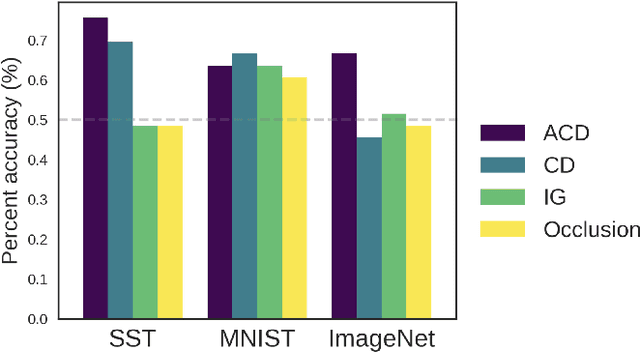
Recent deep-learning models have achieved impressive predictive performance by learning complex functions of many variables, often at the cost of interpretability. This chapter covers recent work aiming to interpret models by attributing importance to features and feature groups for a single prediction. Importantly, the proposed attributions assign importance to interactions between features, in addition to features in isolation. These attributions are shown to yield insights across real-world domains, including bio-imaging, cosmology image and natural-language processing. We then show how these attributions can be used to directly improve the generalization of a neural network or to distill it into a simple model. Throughout the chapter, we emphasize the use of reality checks to scrutinize the proposed interpretation techniques.
Classification of Diabetic Retinopathy Severity in Fundus Images with DenseNet121 and ResNet50
Aug 19, 2021
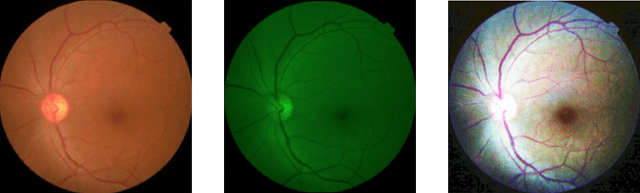
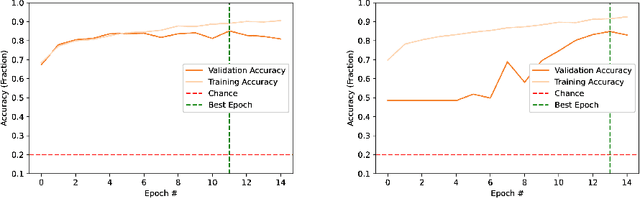

In this work, deep learning algorithms are used to classify fundus images in terms of diabetic retinopathy severity. Six different combinations of two model architectures, the Dense Convolutional Network-121 and the Residual Neural Network-50 and three image types, RGB, Green, and High Contrast, were tested to find the highest performing combination. We achieved an average validation loss of 0.17 and a max validation accuracy of 85 percent. By testing out multiple combinations, certain combinations of parameters performed better than others, though minimal variance was found overall. Green filtration was shown to perform the poorest, while amplified contrast appeared to have a negligible effect in comparison to RGB analysis. ResNet50 proved to be less of a robust model as opposed to DenseNet121.