 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Region Domain Adaptation for Class-level Alignment
Paper and Code
Sep 14, 2021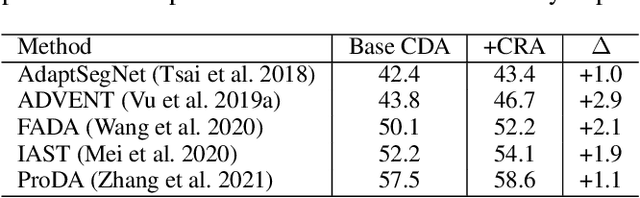
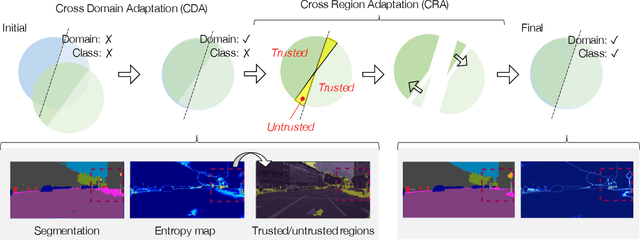
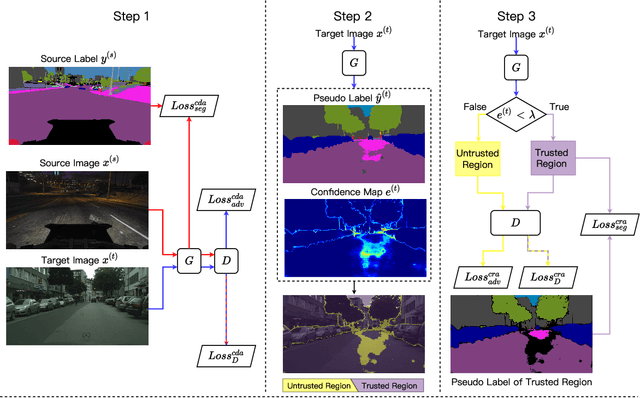
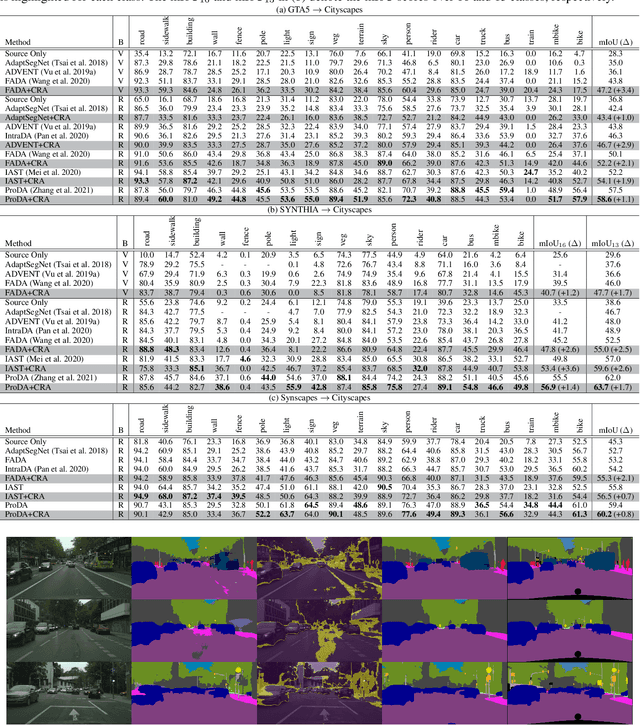
Semantic segmentation requires a lot of training data, which necessitates costly annotation. There have been many studies on unsupervised domain adaptation (UDA) from one domain to another, e.g., from computer graphics to real images. However, there is still a gap in accuracy between UDA and supervised training on native domain data. It is arguably attributable to class-level misalignment between the source and target domain data. To cope with this, we propose a method that applies adversarial training to align two feature distributions in the target domain. It uses a self-training framework to split the image into two regions (i.e., trusted and untrusted), which form two distributions to align in the feature space. We term this approach cross-region adaptation (CRA) to distinguish from the previous methods of aligning different domain distributions, which we call cross-domain adaptation (CDA). CRA can be applied after any CDA method. Experimental results show that this always improves the accuracy of the combined CDA method, having updated the state-of-the-art.