 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Method to Generate Synthetically Warped Document Image
Oct 15, 2019
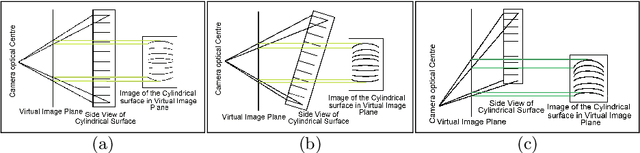

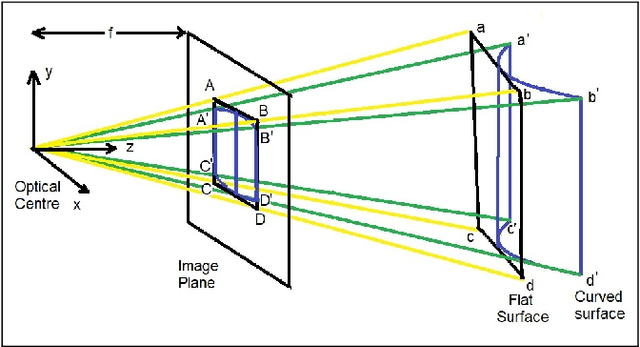

The digital camera captured document images may often be warped and distorted due to different camera angles or document surfaces. A robust technique is needed to solve this kind of distortion. The research on dewarping of the document suffers due to the limited availability of benchmark public dataset. In recent times, deep learning based approaches are used to solve the problems accurately. To train most of the deep neural networks a large number of document images is required and generating such a large volume of document images manually is difficult. In this paper, we propose a technique to generate a synthetic warped image from a flat-bedded scanned document image. It is done by calculating warping factors for each pixel position using two warping position parameters (WPP) and eight warping control parameters (WCP). These parameters can be specified as needed depending upon the desired warping. The results are compared with similar real captured images both qualitative and quantitative way.
Exploring the Common Principal Subspace of Deep Features in Neural Networks
Oct 06, 2021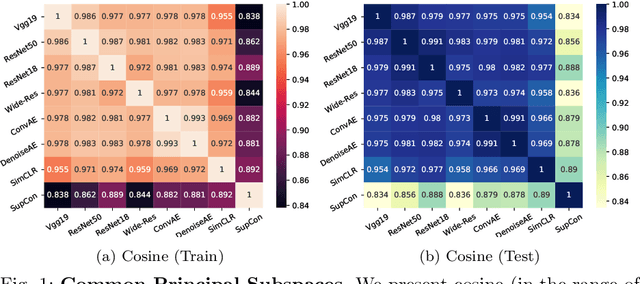

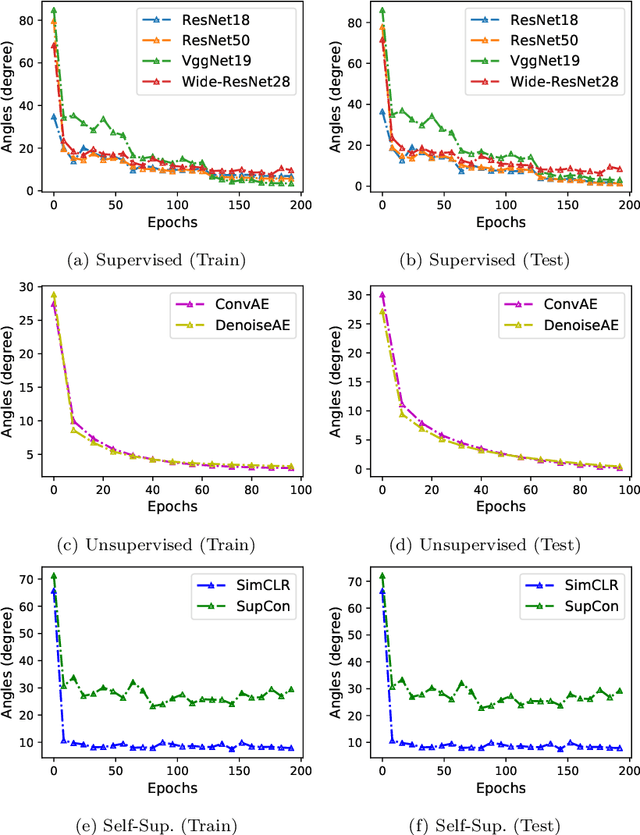
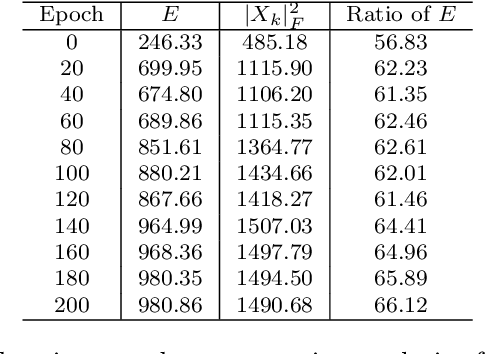
We find that different Deep Neural Networks (DNNs) trained with the same dataset share a common principal subspace in latent spaces, no matter in which architectures (e.g., Convolutional Neural Networks (CNNs), Multi-Layer Preceptors (MLPs) and Autoencoders (AEs)) the DNNs were built or even whether labels have been used in training (e.g., supervised, unsupervised, and self-supervised learning). Specifically, we design a new metric $\mathcal{P}$-vector to represent the principal subspace of deep features learned in a DNN, and propose to measure angles between the principal subspaces using $\mathcal{P}$-vectors. Small angles (with cosine close to $1.0$) have been found in the comparisons between any two DNNs trained with different algorithms/architectures. Furthermore, during the training procedure from random scratch, the angle decrease from a larger one ($70^\circ-80^\circ$ usually) to the small one, which coincides the progress of feature space learning from scratch to convergence. Then, we carry out case studies to measure the angle between the $\mathcal{P}$-vector and the principal subspace of training dataset, and connect such angle with generalization performance. Extensive experiments with practically-used Multi-Layer Perceptron (MLPs), AEs and CNNs for classification, image reconstruction, and self-supervised learning tasks on MNIST, CIFAR-10 and CIFAR-100 datasets have been done to support our claims with solid evidences. Interpretability of Deep Learning, Feature Learning, and Subspaces of Deep Features
LAMP: Large Deep Nets with Automated Model Parallelism for Image Segmentation
Jun 26, 2020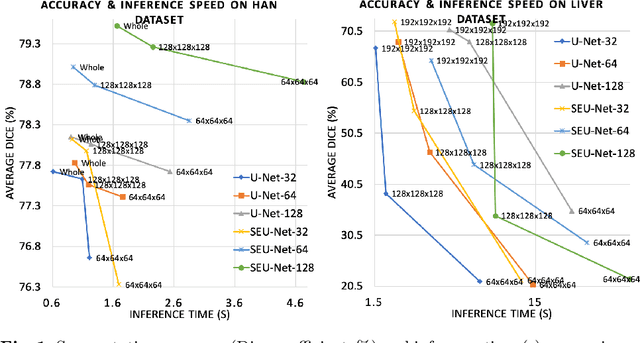
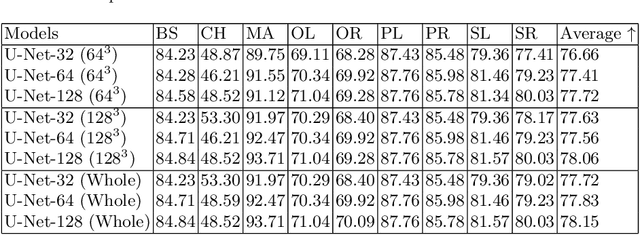
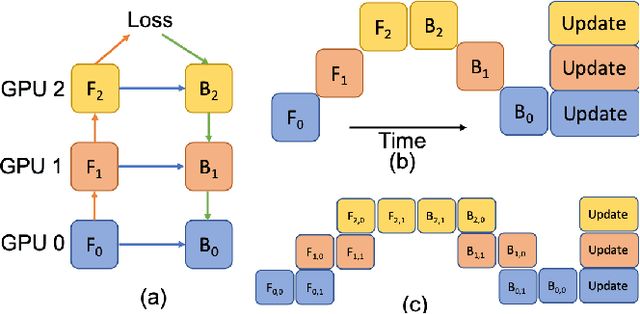
Deep Learning (DL) models are becoming larger, because the increase in model size might offer significant accuracy gain. To enable the training of large deep networks, data parallelism and model parallelism are two well-known approaches for parallel training. However, data parallelism does not help reduce memory footprint per device. In this work, we introduce Large deep 3D ConvNets with Automated Model Parallelism (LAMP) and investigate the impact of both input's and deep 3D ConvNets' size on segmentation accuracy. Through automated model parallelism, it is feasible to train large deep 3D ConvNets with a large input patch, even the whole image. Extensive experiments demonstrate that, facilitated by the automated model parallelism, the segmentation accuracy can be improved through increasing model size and input context size, and large input yields significant inference speedup compared with sliding window of small patches in the inference. Code is available\footnote{https://monai.io/research/lamp-automated-model-parallelism}.
Integrating Knowledge and Reasoning in Image Understanding
Jun 24, 2019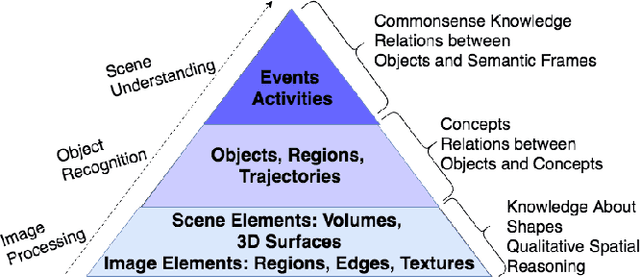

Deep learning based data-driven approaches have been successfully applied in various image understanding applications ranging from object recognition, semantic segmentation to visual question answering. However, the lack of knowledge integration as well as higher-level reasoning capabilities with the methods still pose a hindrance. In this work, we present a brief survey of a few representative reasoning mechanisms, knowledge integration methods and their corresponding image understanding applications developed by various groups of researchers, approaching the problem from a variety of angles. Furthermore, we discuss upon key efforts on integrating external knowledge with neural networks. Taking cues from these efforts, we conclude by discussing potential pathways to improve reasoning capabilities.
* 8 pages, 2 figures
ACAE-REMIND for Online Continual Learning with Compressed Feature Replay
May 18, 2021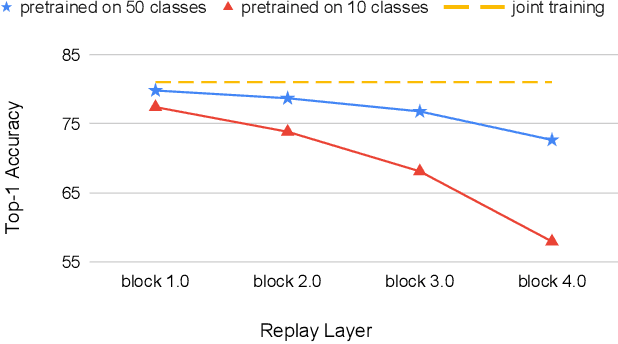

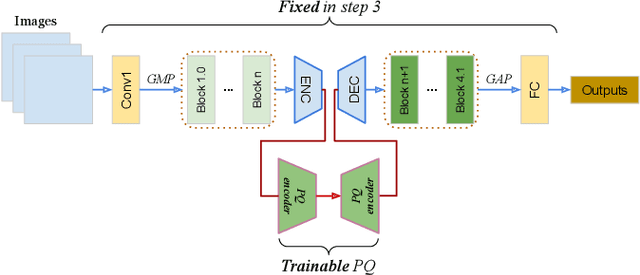
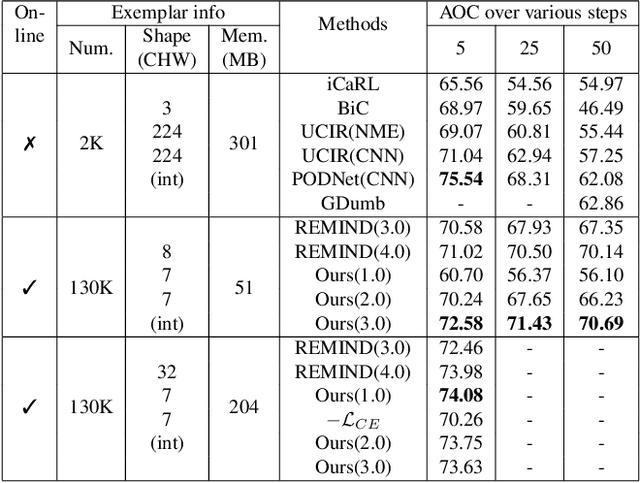
Online continual learning aims to learn from a non-IID stream of data from a number of different tasks, where the learner is only allowed to consider data once. Methods are typically allowed to use a limited buffer to store some of the images in the stream. Recently, it was found that feature replay, where an intermediate layer representation of the image is stored (or generated) leads to superior results than image replay, while requiring less memory. Quantized exemplars can further reduce the memory usage. However, a drawback of these methods is that they use a fixed (or very intransigent) backbone network. This significantly limits the learning of representations that can discriminate between all tasks. To address this problem, we propose an auxiliary classifier auto-encoder (ACAE) module for feature replay at intermediate layers with high compression rates. The reduced memory footprint per image allows us to save more exemplars for replay. In our experiments, we conduct task-agnostic evaluation under online continual learning setting and get state-of-the-art performance on ImageNet-Subset, CIFAR100 and CIFAR10 dataset.
Motion-aware Self-supervised Video Representation Learning via Foreground-background Merging
Sep 30, 2021



In light of the success of contrastive learning in the image domain, current self-supervised video representation learning methods usually employ contrastive loss to facilitate video representation learning. When naively pulling two augmented views of a video closer, the model however tends to learn the common static background as a shortcut but fails to capture the motion information, a phenomenon dubbed as background bias. This bias makes the model suffer from weak generalization ability, leading to worse performance on downstream tasks such as action recognition. To alleviate such bias, we propose Foreground-background Merging (FAME) to deliberately compose the foreground region of the selected video onto the background of others. Specifically, without any off-the-shelf detector, we extract the foreground and background regions via the frame difference and color statistics, and shuffle the background regions among the videos. By leveraging the semantic consistency between the original clips and the fused ones, the model focuses more on the foreground motion pattern and is thus more robust to the background context. Extensive experiments demonstrate that FAME can significantly boost the performance in different downstream tasks with various backbones. When integrated with MoCo, FAME reaches 84.8% and 53.5% accuracy on UCF101 and HMDB51, respectively, achieving the state-of-the-art performance.
"Wikily" Neural Machine Translation Tailored to Cross-Lingual Tasks
Apr 16, 2021
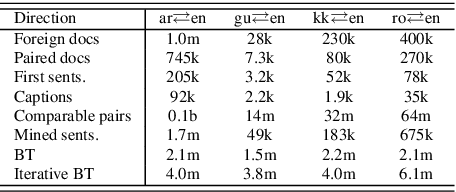
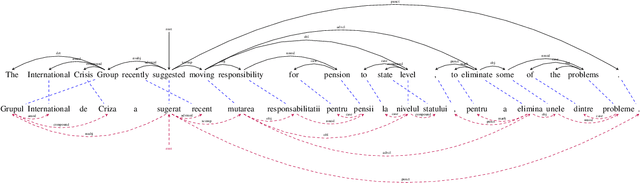
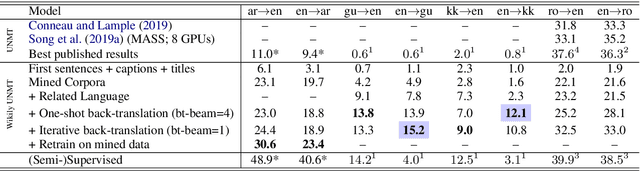
We present a simple but effective approach for leveraging Wikipedia for neural machine translation as well as cross-lingual tasks of image captioning and dependency parsing without using any direct supervision from external parallel data or supervised models in the target language. We show that first sentences and titles of linked Wikipedia pages, as well as cross-lingual image captions, are strong signals for a seed parallel data to extract bilingual dictionaries and cross-lingual word embeddings for mining parallel text from Wikipedia. Our final model achieves high BLEU scores that are close to or sometimes higher than strong supervised baselines in low-resource languages; e.g. supervised BLEU of 4.0 versus 12.1 from our model in English-to-Kazakh. Moreover, we tailor our wikily translation models to unsupervised image captioning and cross-lingual dependency parser transfer. In image captioning, we train a multi-tasking machine translation and image captioning pipeline for Arabic and English from which the Arabic training data is a wikily translation of the English captioning data. Our captioning results in Arabic are slightly better than that of its supervised model. In dependency parsing, we translate a large amount of monolingual text, and use it as an artificial training data in an annotation projection framework. We show that our model outperforms recent work on cross-lingual transfer of dependency parsers.
AnonySIGN: Novel Human Appearance Synthesis for Sign Language Video Anonymisation
Jul 23, 2021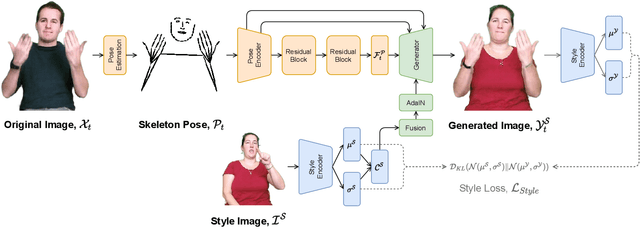
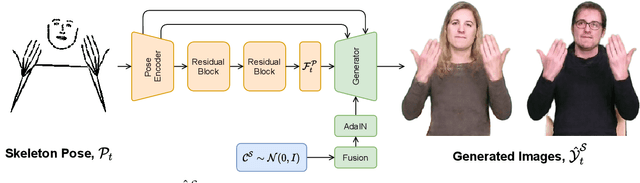


The visual anonymisation of sign language data is an essential task to address privacy concerns raised by large-scale dataset collection. Previous anonymisation techniques have either significantly affected sign comprehension or required manual, labour-intensive work. In this paper, we formally introduce the task of Sign Language Video Anonymisation (SLVA) as an automatic method to anonymise the visual appearance of a sign language video whilst retaining the meaning of the original sign language sequence. To tackle SLVA, we propose AnonySign, a novel automatic approach for visual anonymisation of sign language data. We first extract pose information from the source video to remove the original signer appearance. We next generate a photo-realistic sign language video of a novel appearance from the pose sequence, using image-to-image translation methods in a conditional variational autoencoder framework. An approximate posterior style distribution is learnt, which can be sampled from to synthesise novel human appearances. In addition, we propose a novel \textit{style loss} that ensures style consistency in the anonymised sign language videos. We evaluate AnonySign for the SLVA task with extensive quantitative and qualitative experiments highlighting both realism and anonymity of our novel human appearance synthesis. In addition, we formalise an anonymity perceptual study as an evaluation criteria for the SLVA task and showcase that video anonymisation using AnonySign retains the original sign language content.
Bilinear discriminant feature line analysis for image feature extraction
May 03, 2019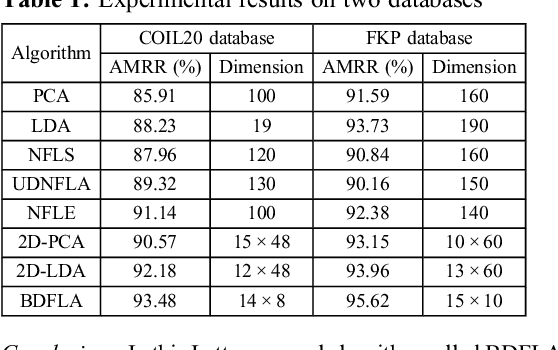
A novel bilinear discriminant feature line analysis (BDFLA) is proposed for image feature extraction. The nearest feature line (NFL) is a powerful classifier. Some NFL-based subspace algorithms were introduced recently. In most of the classical NFL-based subspace learning approaches, the input samples are vectors. For image classification tasks, the image samples should be transformed to vectors first. This process induces a high computational complexity and may also lead to loss of the geometric feature of samples. The proposed BDFLA is a matrix-based algorithm. It aims to minimise the within-class scatter and maximise the between-class scatter based on a two-dimensional (2D) NFL. Experimental results on two-image databases confirm the effectiveness.
NICO: A Dataset Towards Non-I.I.D. Image Classification
Jun 07, 2019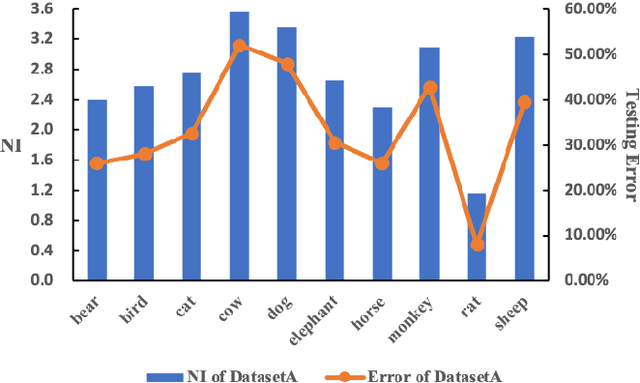
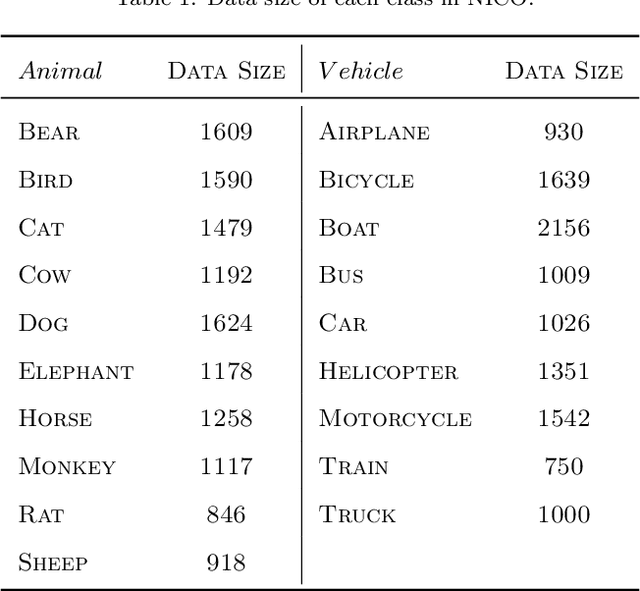
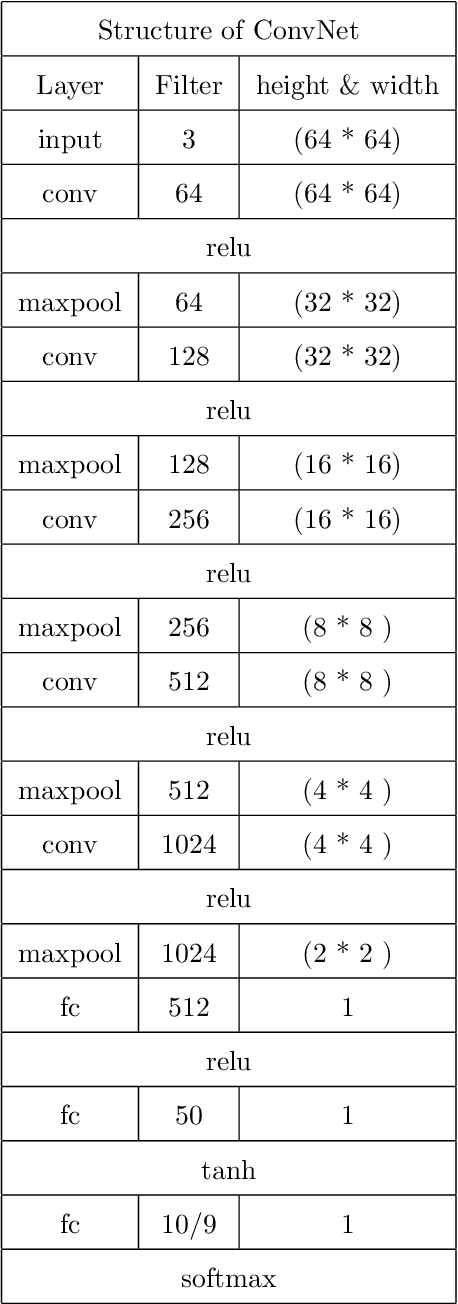
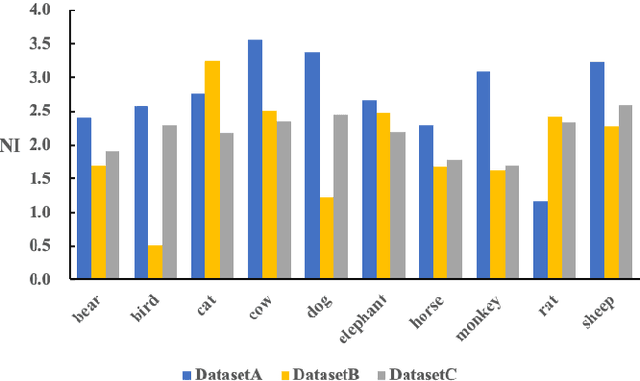
The I.I.D. hypothesis between training data and testing data is the basis of a large number of image classification methods. Such a property can hardly be guaranteed in practical cases where the Non-IIDness is common, leading to instable performances of these models. In literature, however, the Non-I.I.D. image classification problem is largely understudied. A key reason is the lacking of a well-designed dataset to support related research. In this paper, we construct and release a Non-I.I.D. image dataset called NICO, which makes use of contexts to create Non-IIDness consciously. Extended experimental results and anslyses demonstrate that the NICO dataset can well support the training of a ConvNet model from scratch, and NICO can support various Non-I.I.D. situations with sufficient flexibility compared to other datasets.