 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Language Models Understand Honorific Systems in Javanese?
Feb 28, 2025



The Javanese language features a complex system of honorifics that vary according to the social status of the speaker, listener, and referent. Despite its cultural and linguistic significance, there has been limited progress in developing a comprehensive corpus to capture these variations for natural language processing (NLP) tasks. In this paper, we present Unggah-Ungguh, a carefully curated dataset designed to encapsulate the nuances of Unggah-Ungguh Basa, the Javanese speech etiquette framework that dictates the choice of words and phrases based on social hierarchy and context. Using Unggah-Ungguh, we assess the ability of language models (LMs) to process various levels of Javanese honorifics through classification and machine translation tasks. To further evaluate cross-lingual LMs, we conduct machine translation experiments between Javanese (at specific honorific levels) and Indonesian. Additionally, we explore whether LMs can generate contextually appropriate Javanese honorifics in conversation tasks, where the honorific usage should align with the social role and contextual cues. Our findings indicate that current LMs struggle with most honorific levels, exhibitinga bias toward certain honorific tiers.
DriveThru: a Document Extraction Platform and Benchmark Datasets for Indonesian Local Language Archives
Nov 14, 2024



Indonesia is one of the most diverse countries linguistically. However, despite this linguistic diversity, Indonesian languages remain underrepresented in Natural Language Processing (NLP) research and technologies. In the past two years, several efforts have been conducted to construct NLP resources for Indonesian languages. However, most of these efforts have been focused on creating manual resources thus difficult to scale to more languages. Although many Indonesian languages do not have a web presence, locally there are resources that document these languages well in printed forms such as books, magazines, and newspapers. Digitizing these existing resources will enable scaling of Indonesian language resource construction to many more languages. In this paper, we propose an alternative method of creating datasets by digitizing documents, which have not previously been used to build digital language resources in Indonesia. DriveThru is a platform for extracting document content utilizing Optical Character Recognition (OCR) techniques in its system to provide language resource building with less manual effort and cost. This paper also studies the utility of current state-of-the-art LLM for post-OCR correction to show the capability of increasing the character accuracy rate (CAR) and word accuracy rate (WAR) compared to off-the-shelf OCR.
MetaMetrics-MT: Tuning Meta-Metrics for Machine Translation via Human Preference Calibration
Nov 01, 2024We present MetaMetrics-MT, an innovative metric designed to evaluate machine translation (MT) tasks by aligning closely with human preferences through Bayesian optimization with Gaussian Processes. MetaMetrics-MT enhances existing MT metrics by optimizing their correlation with human judgments. Our experiments on the WMT24 metric shared task dataset demonstrate that MetaMetrics-MT outperforms all existing baselines, setting a new benchmark for state-of-the-art performance in the reference-based setting. Furthermore, it achieves comparable results to leading metrics in the reference-free setting, offering greater efficiency.
Linguistics Theory Meets LLM: Code-Switched Text Generation via Equivalence Constrained Large Language Models
Oct 30, 2024Code-switching, the phenomenon of alternating between two or more languages in a single conversation, presents unique challenges for Natural Language Processing (NLP). Most existing research focuses on either syntactic constraints or neural generation, with few efforts to integrate linguistic theory with large language models (LLMs) for generating natural code-switched text. In this paper, we introduce EZSwitch, a novel framework that combines Equivalence Constraint Theory (ECT) with LLMs to produce linguistically valid and fluent code-switched text. We evaluate our method using both human judgments and automatic metrics, demonstrating a significant improvement in the quality of generated code-switching sentences compared to baseline LLMs. To address the lack of suitable evaluation metrics, we conduct a comprehensive correlation study of various automatic metrics against human scores, revealing that current metrics often fail to capture the nuanced fluency of code-switched text. Additionally, we create CSPref, a human preference dataset based on human ratings and analyze model performance across ``hard`` and ``easy`` examples. Our findings indicate that incorporating linguistic constraints into LLMs leads to more robust and human-aligned generation, paving the way for scalable code-switching text generation across diverse language pairs.
WorldCuisines: A Massive-Scale Benchmark for Multilingual and Multicultural Visual Question Answering on Global Cuisines
Oct 16, 2024



Vision Language Models (VLMs) often struggle with culture-specific knowledge, particularly in languages other than English and in underrepresented cultural contexts. To evaluate their understanding of such knowledge, we introduce WorldCuisines, a massive-scale benchmark for multilingual and multicultural, visually grounded language understanding. This benchmark includes a visual question answering (VQA) dataset with text-image pairs across 30 languages and dialects, spanning 9 language families and featuring over 1 million data points, making it the largest multicultural VQA benchmark to date. It includes tasks for identifying dish names and their origins. We provide evaluation datasets in two sizes (12k and 60k instances) alongside a training dataset (1 million instances). Our findings show that while VLMs perform better with correct location context, they struggle with adversarial contexts and predicting specific regional cuisines and languages. To support future research, we release a knowledge base with annotated food entries and images along with the VQA data.
MetaMetrics: Calibrating Metrics For Generation Tasks Using Human Preferences
Oct 03, 2024Understanding the quality of a performance evaluation metric is crucial for ensuring that model outputs align with human preferences. However, it remains unclear how well each metric captures the diverse aspects of these preferences, as metrics often excel in one particular area but not across all dimensions. To address this, it is essential to systematically calibrate metrics to specific aspects of human preference, catering to the unique characteristics of each aspect. We introduce MetaMetrics, a calibrated meta-metric designed to evaluate generation tasks across different modalities in a supervised manner. MetaMetrics optimizes the combination of existing metrics to enhance their alignment with human preferences. Our metric demonstrates flexibility and effectiveness in both language and vision downstream tasks, showing significant benefits across various multilingual and multi-domain scenarios. MetaMetrics aligns closely with human preferences and is highly extendable and easily integrable into any application. This makes MetaMetrics a powerful tool for improving the evaluation of generation tasks, ensuring that metrics are more representative of human judgment across diverse contexts.
Generating Faithful and Salient Text from Multimodal Data
Sep 06, 2024



While large multimodal models (LMMs) have obtained strong performance on many multimodal tasks, they may still hallucinate while generating text. Their performance on detecting salient features from visual data is also unclear. In this paper, we develop a framework to generate faithful and salient text from mixed-modal data, which includes images and structured data ( represented in knowledge graphs or tables). Specifically, we train a small vision critic model to identify hallucinated and non-salient features from the image modality. The critic model also generates a list of salient image features. This information is used in the post editing step to improve the generation quality. Experiments on two datasets show that our framework improves LMMs' generation quality on both faithfulness and saliency, outperforming recent techniques aimed at reducing hallucination.
Enhancing Emotion Prediction in News Headlines: Insights from ChatGPT and Seq2Seq Models for Free-Text Generation
Jul 14, 2024

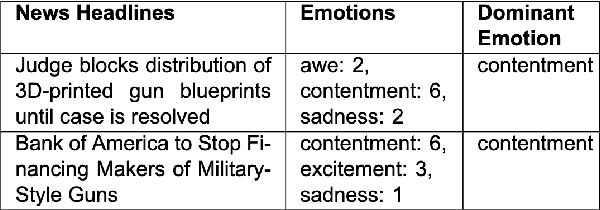

Predicting emotions elicited by news headlines can be challenging as the task is largely influenced by the varying nature of people's interpretations and backgrounds. Previous works have explored classifying discrete emotions directly from news headlines. We provide a different approach to tackling this problem by utilizing people's explanations of their emotion, written in free-text, on how they feel after reading a news headline. Using the dataset BU-NEmo+ (Gao et al., 2022), we found that for emotion classification, the free-text explanations have a strong correlation with the dominant emotion elicited by the headlines. The free-text explanations also contain more sentimental context than the news headlines alone and can serve as a better input to emotion classification models. Therefore, in this work we explored generating emotion explanations from headlines by training a sequence-to-sequence transformer model and by using pretrained large language model, ChatGPT (GPT-4). We then used the generated emotion explanations for emotion classification. In addition, we also experimented with training the pretrained T5 model for the intermediate task of explanation generation before fine-tuning it for emotion classification. Using McNemar's significance test, methods that incorporate GPT-generated free-text emotion explanations demonstrated significant improvement (P-value < 0.05) in emotion classification from headlines, compared to methods that only use headlines. This underscores the value of using intermediate free-text explanations for emotion prediction tasks with headlines.
* published at LREC-COLING 2024
Mitigating Translationese in Low-resource Languages: The Storyboard Approach
Jul 14, 2024Low-resource languages often face challenges in acquiring high-quality language data due to the reliance on translation-based methods, which can introduce the translationese effect. This phenomenon results in translated sentences that lack fluency and naturalness in the target language. In this paper, we propose a novel approach for data collection by leveraging storyboards to elicit more fluent and natural sentences. Our method involves presenting native speakers with visual stimuli in the form of storyboards and collecting their descriptions without direct exposure to the source text. We conducted a comprehensive evaluation comparing our storyboard-based approach with traditional text translation-based methods in terms of accuracy and fluency. Human annotators and quantitative metrics were used to assess translation quality. The results indicate a preference for text translation in terms of accuracy, while our method demonstrates worse accuracy but better fluency in the language focused.
* published at LREC-COLING 2024
Detecting Frames in News Headlines and Lead Images in U.S. Gun Violence Coverage
Jun 25, 2024



News media structure their reporting of events or issues using certain perspectives. When describing an incident involving gun violence, for example, some journalists may focus on mental health or gun regulation, while others may emphasize the discussion of gun rights. Such perspectives are called \say{frames} in communication research. We study, for the first time, the value of combining lead images and their contextual information with text to identify the frame of a given news article. We observe that using multiple modes of information(article- and image-derived features) improves prediction of news frames over any single mode of information when the images are relevant to the frames of the headlines. We also observe that frame image relevance is related to the ease of conveying frames via images, which we call frame concreteness. Additionally, we release the first multimodal news framing dataset related to gun violence in the U.S., curated and annotated by communication researchers. The dataset will allow researchers to further examine the use of multiple information modalities for studying media framing.