 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Discover, Hallucinate, and Adapt: Open Compound Domain Adaptation for Semantic Segmentation
Oct 08, 2021
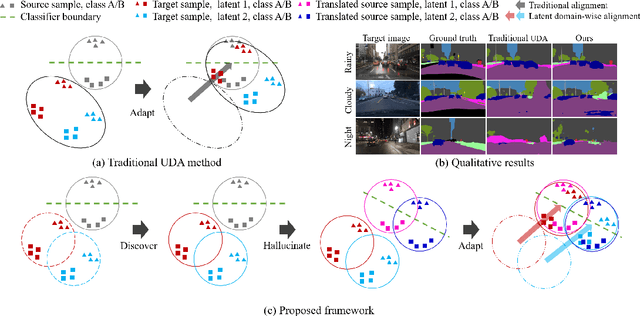
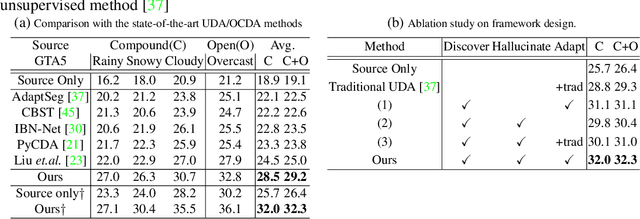
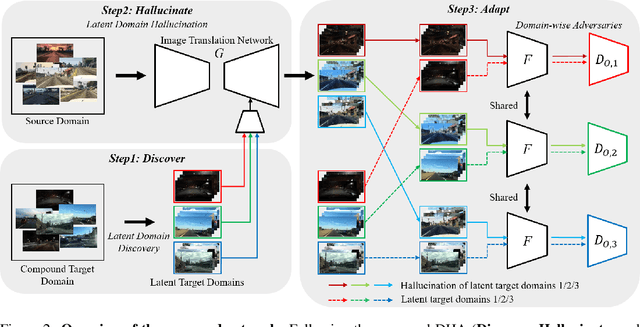
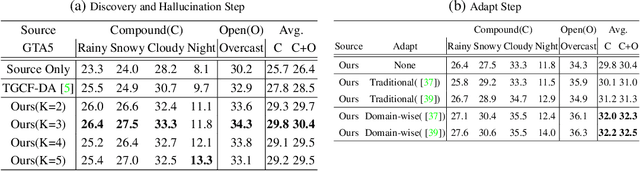
Unsupervised domain adaptation (UDA) for semantic segmentation has been attracting attention recently, as it could be beneficial for various label-scarce real-world scenarios (e.g., robot control, autonomous driving, medical imaging, etc.). Despite the significant progress in this field, current works mainly focus on a single-source single-target setting, which cannot handle more practical settings of multiple targets or even unseen targets. In this paper, we investigate open compound domain adaptation (OCDA), which deals with mixed and novel situations at the same time, for semantic segmentation. We present a novel framework based on three main design principles: discover, hallucinate, and adapt. The scheme first clusters compound target data based on style, discovering multiple latent domains (discover). Then, it hallucinates multiple latent target domains in source by using image-translation (hallucinate). This step ensures the latent domains in the source and the target to be paired. Finally, target-to-source alignment is learned separately between domains (adapt). In high-level, our solution replaces a hard OCDA problem with much easier multiple UDA problems. We evaluate our solution on standard benchmark GTA to C-driving, and achieved new state-of-the-art results.
Full-color photon-counting single-pixel imaging
Sep 06, 2021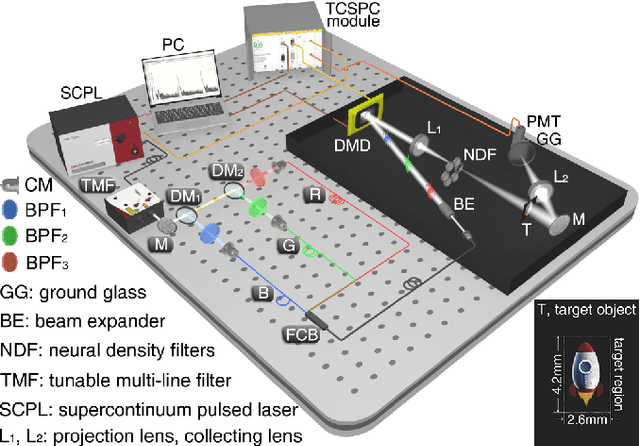
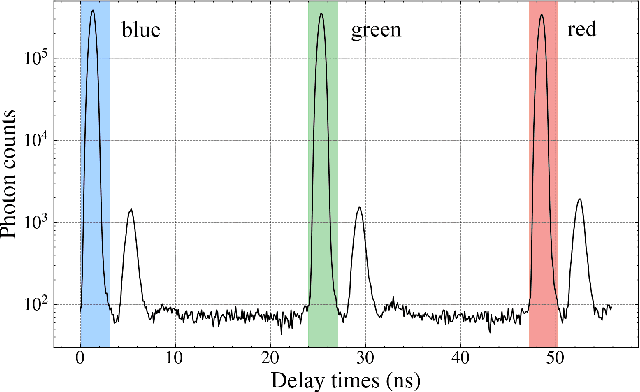

We propose and experimentally demonstrate a high-efficiency single-pixel imaging (SPI) scheme by integrating time-correlated single-photon counting (TCSPC) with time-division multiplexing to acquire full-color images at extremely low light level. This SPI scheme uses a digital micromirror device to modulate a sequence of laser pulses with preset delays to achieve three-color structured illumination, then employs a photomultiplier tube into the TCSPC module to achieve photon-counting detection. By exploiting the time-resolved capabilities of TCSPC, we demodulate the spectrum-image-encoded signals, and then reconstruct high-quality full-color images in a single-round of measurement. Based on this scheme, the strategies such as single-step measurement, high-speed projection, and undersampling can further improve the imaging efficiency.
Subjective and Objective De-raining Quality Assessment Towards Authentic Rain Image
Oct 06, 2019
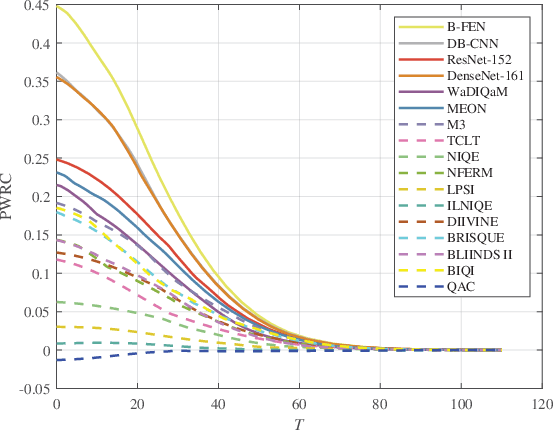

Images acquired by outdoor vision systems easily suffer poor visibility and annoying interference due to the rainy weather, which brings great challenge for accurately understanding and describing the visual contents. Recent researches have devoted great efforts on the task of rain removal for improving the image visibility. However, there is very few exploration about the quality assessment of de-rained image, even it is crucial for accurately measuring the performance of various de-raining algorithms. In this paper, we first create a de-raining quality assessment (DQA) database that collects 206 authentic rain images and their de-rained versions produced by 6 representative single image rain removal algorithms. Then, a subjective study is conducted on our DQA database, which collects the subject-rated scores of all de-rained images. To quantitatively measure the quality of de-rained image with non-uniform artifacts, we propose a bi-directional feature embedding network (B-FEN) which integrates the features of global perception and local difference together. Experiments confirm that the proposed method significantly outperforms many existing universal blind image quality assessment models. To help the research towards perceptually preferred de-raining algorithm, we will publicly release our DQA database and B-FEN source code on https://github.com/wqb-uestc.
Learning with Privileged Information for Efficient Image Super-Resolution
Jul 15, 2020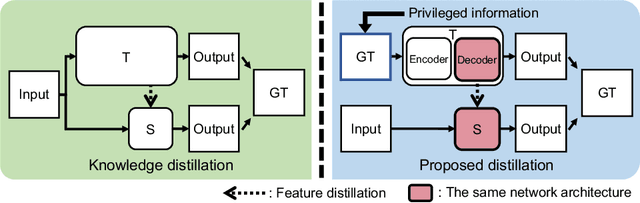
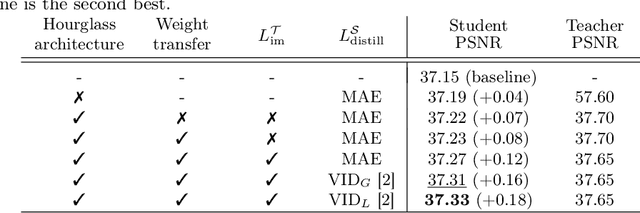
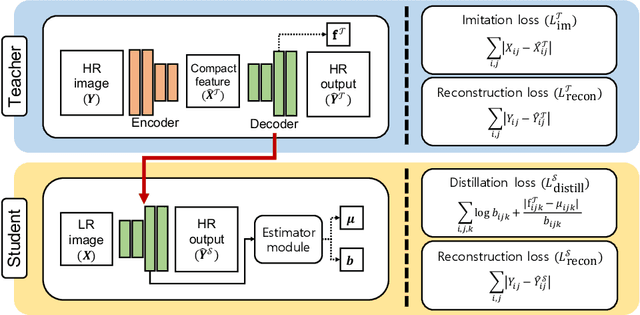
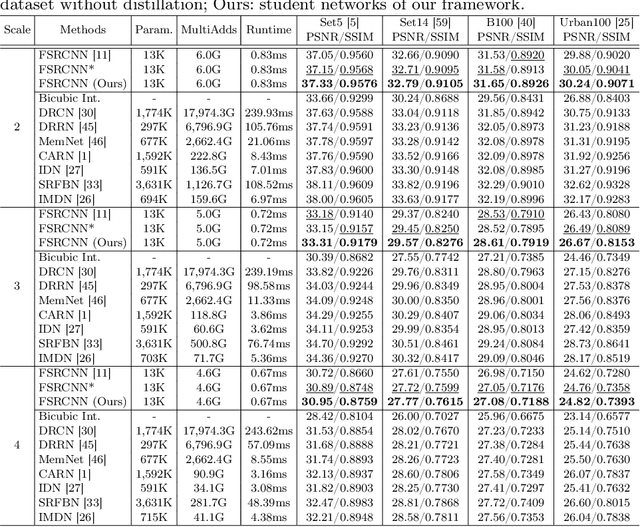
Convolutional neural networks (CNNs) have allowed remarkable advances in single image super-resolution (SISR) over the last decade. Most SR methods based on CNNs have focused on achieving performance gains in terms of quality metrics, such as PSNR and SSIM, over classical approaches. They typically require a large amount of memory and computational units. FSRCNN, consisting of few numbers of convolutional layers, has shown promising results, while using an extremely small number of network parameters. We introduce in this paper a novel distillation framework, consisting of teacher and student networks, that allows to boost the performance of FSRCNN drastically. To this end, we propose to use ground-truth high-resolution (HR) images as privileged information. The encoder in the teacher learns the degradation process, subsampling of HR images, using an imitation loss. The student and the decoder in the teacher, having the same network architecture as FSRCNN, try to reconstruct HR images. Intermediate features in the decoder, affordable for the student to learn, are transferred to the student through feature distillation. Experimental results on standard benchmarks demonstrate the effectiveness and the generalization ability of our framework, which significantly boosts the performance of FSRCNN as well as other SR methods. Our code and model are available online: https://cvlab.yonsei.ac.kr/projects/PISR.
Single Image Reflection Removal through Cascaded Refinement
Nov 15, 2019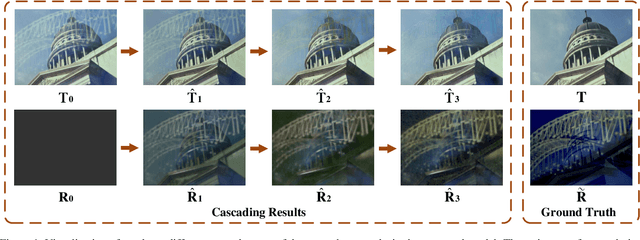
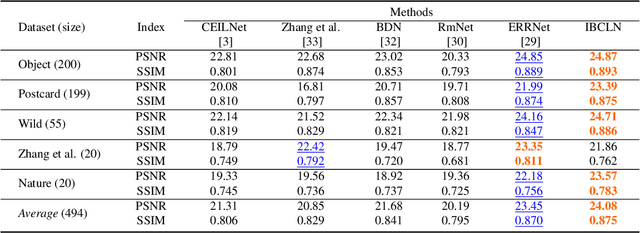
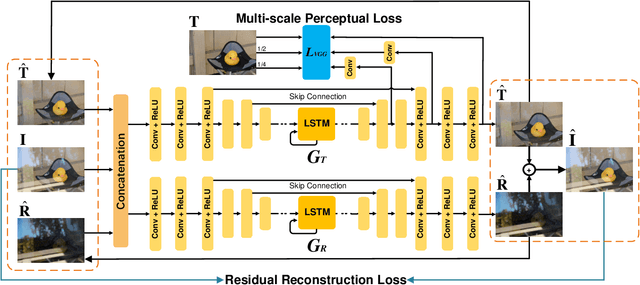
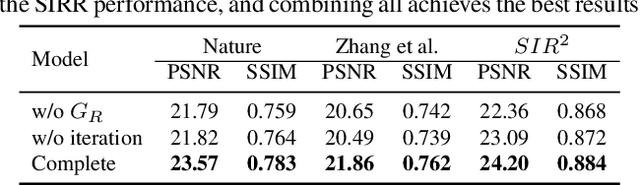
We address the problem of removing undesirable reflections from a single image captured through a glass surface, which is an ill-posed, challenging but practically important problem for photo enhancement. Inspired by iterative structure reduction for hidden community detection in social networks, we propose an Iterative Boost Convolutional LSTM Network (IBCLN) that enables cascaded prediction for reflection removal. IBCLN iteratively refines estimates of the transmission and reflection layers at each step in a manner that they can boost the prediction quality for each other. The intuition is that progressive refinement of the transmission or reflection layer is aided by increasingly better estimates of these quantities as input, and that transmission and reflection are complementary to each other in a single image and thus provide helpful auxiliary information for each other's prediction. To facilitate training over multiple cascade steps, we employ LSTM to address the vanishing gradient problem, and incorporate a reconstruction loss as further training guidance at each step. In addition, we create a dataset of real-world images with reflection and ground-truth transmission layers to mitigate the problem of insufficient data. Through comprehensive experiments, IBCLN demonstrates performance that surpasses state-of-the-art reflection removal methods.
Exploring the Diversity and Invariance in Yourself for Visual Pre-Training Task
Jun 01, 2021
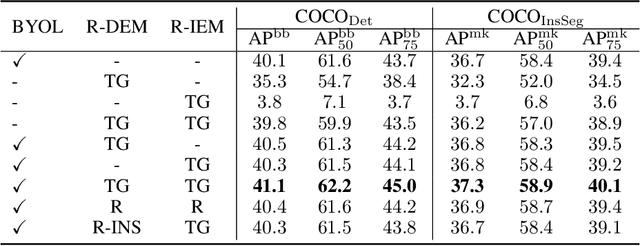
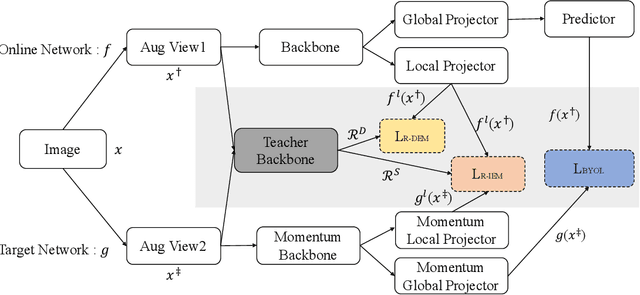
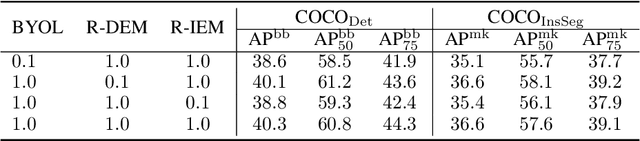
Recently, self-supervised learning methods have achieved remarkable success in visual pre-training task. By simply pulling the different augmented views of each image together or other novel mechanisms, they can learn much unsupervised knowledge and significantly improve the transfer performance of pre-training models. However, these works still cannot avoid the representation collapse problem, i.e., they only focus on limited regions or the extracted features on totally different regions inside each image are nearly the same. Generally, this problem makes the pre-training models cannot sufficiently describe the multi-grained information inside images, which further limits the upper bound of their transfer performance. To alleviate this issue, this paper introduces a simple but effective mechanism, called Exploring the Diversity and Invariance in Yourself E-DIY. By simply pushing the most different regions inside each augmented view away, E-DIY can preserve the diversity of extracted region-level features. By pulling the most similar regions from different augmented views of the same image together, E-DIY can ensure the robustness of region-level features. Benefited from the above diversity and invariance exploring mechanism, E-DIY maximally extracts the multi-grained visual information inside each image. Extensive experiments on downstream tasks demonstrate the superiority of our proposed approach, e.g., there are 2.1% improvements compared with the strong baseline BYOL on COCO while fine-tuning Mask R-CNN with the R50-C4 backbone and 1X learning schedule.
A Regularized Convolutional Neural Network for Semantic Image Segmentation
Jun 28, 2019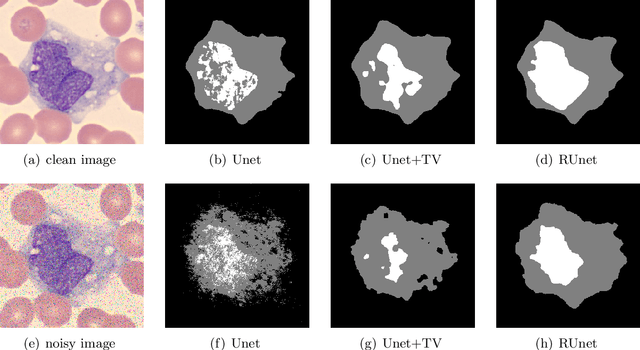
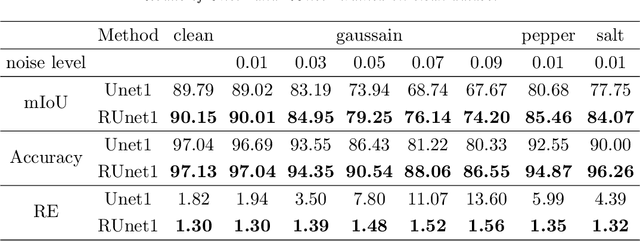
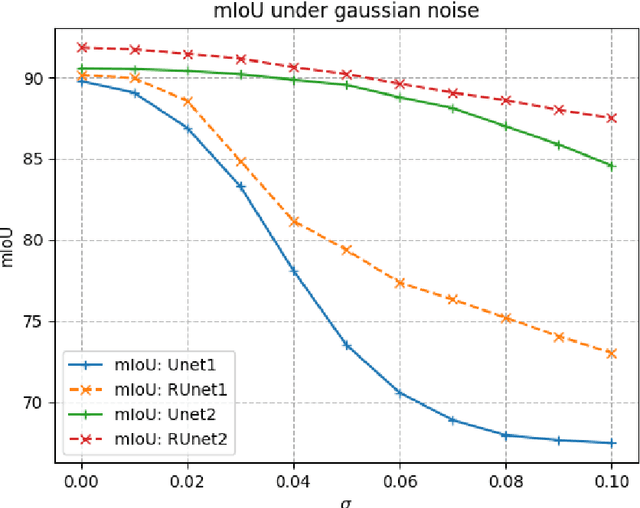
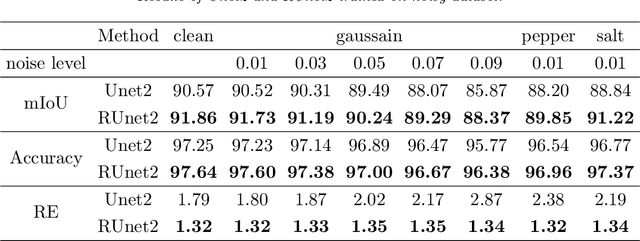
Convolutional neural networks (CNNs) show outstanding performance in many image processing problems, such as image recognition, object detection and image segmentation. Semantic segmentation is a very challenging task that requires recognizing, understanding what's in the image in pixel level. Though the state of the art has been greatly improved by CNNs, there is no explicit connections between prediction of neighbouring pixels. That is, spatial regularity of the segmented objects is still a problem for CNNs. In this paper, we propose a method to add spatial regularization to the segmented objects. In our method, the spatial regularization such as total variation (TV) can be easily integrated into CNN network. It can help CNN find a better local optimum and make the segmentation results more robust to noise. We apply our proposed method to Unet and Segnet, which are well established CNNs for image segmentation, and test them on WBC, CamVid and SUN-RGBD datasets, respectively. The results show that the regularized networks not only could provide better segmentation results with regularization effect than the original ones but also have certain robustness to noise.
Predicting Tau Accumulation in Cerebral Cortex with Multivariate MRI Morphometry Measurements, Sparse Coding, and Correntropy
Oct 20, 2021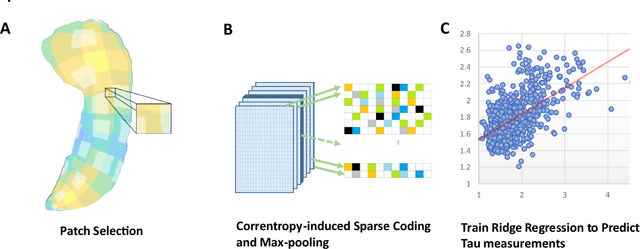
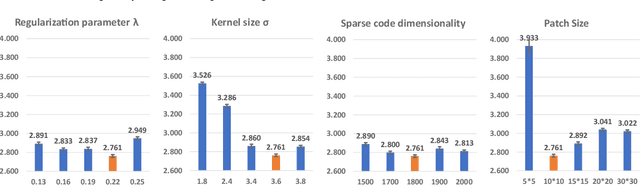
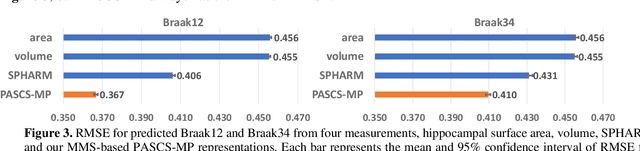
Biomarker-assisted diagnosis and intervention in Alzheimer's disease (AD) may be the key to prevention breakthroughs. One of the hallmarks of AD is the accumulation of tau plaques in the human brain. However, current methods to detect tau pathology are either invasive (lumbar puncture) or quite costly and not widely available (Tau PET). In our previous work, structural MRI-based hippocampal multivariate morphometry statistics (MMS) showed superior performance as an effective neurodegenerative biomarker for preclinical AD and Patch Analysis-based Surface Correntropy-induced Sparse coding and max-pooling (PASCS-MP) has excellent ability to generate low-dimensional representations with strong statistical power for brain amyloid prediction. In this work, we apply this framework together with ridge regression models to predict Tau deposition in Braak12 and Braak34 brain regions separately. We evaluate our framework on 925 subjects from the Alzheimer's Disease Neuroimaging Initiative (ADNI). Each subject has one pair consisting of a PET image and MRI scan which were collected at about the same times. Experimental results suggest that the representations from our MMS and PASCS-MP have stronger predictive power and their predicted Braak12 and Braak34 are closer to the real values compared to the measures derived from other approaches such as hippocampal surface area and volume, and shape morphometry features based on spherical harmonics (SPHARM).
ASK: Adaptively Selecting Key Local Features for RGB-D Scene Recognition
Oct 14, 2021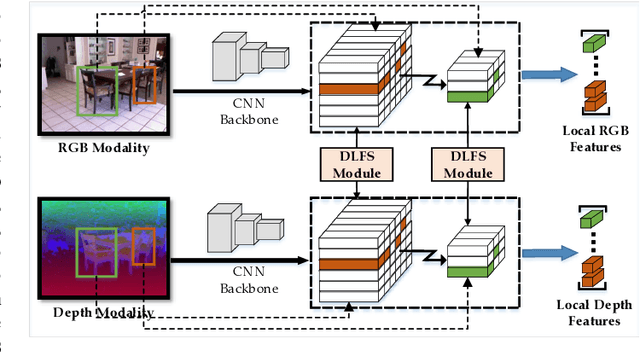

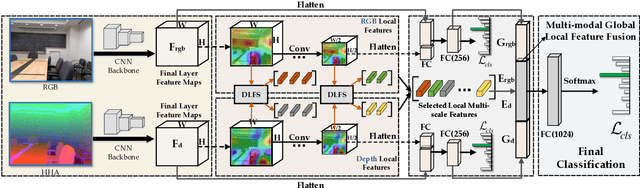
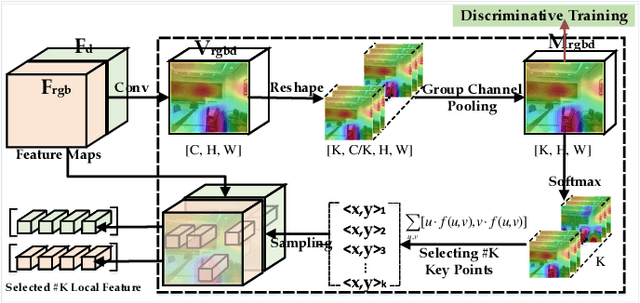
Indoor scene images usually contain scattered objects and various scene layouts, which make RGB-D scene classification a challenging task. Existing methods still have limitations for classifying scene images with great spatial variability. Thus, how to extract local patch-level features effectively using only image labels is still an open problem for RGB-D scene recognition. In this paper, we propose an efficient framework for RGB-D scene recognition, which adaptively selects important local features to capture the great spatial variability of scene images. Specifically, we design a differentiable local feature selection (DLFS) module, which can extract the appropriate number of key local scenerelated features. Discriminative local theme-level and object-level representations can be selected with the DLFS module from the spatially-correlated multi-modal RGB-D features. We take advantage of the correlation between RGB and depth modalities to provide more cues for selecting local features. To ensure that discriminative local features are selected, the variational mutual information maximization loss is proposed. Additionally, the DLFS module can be easily extended to select local features of different scales. By concatenating the local-orderless and global structured multi-modal features, the proposed framework can achieve state-of-the-art performance on public RGB-D scene recognition datasets.
Hybrid graph convolutional neural networks for landmark-based anatomical segmentation
Jun 17, 2021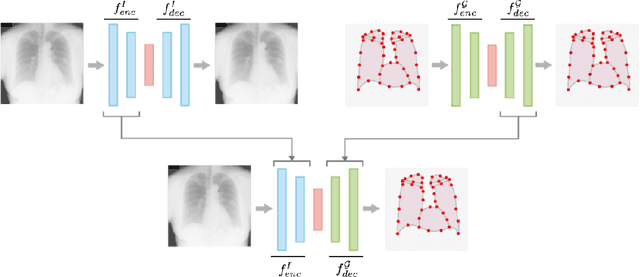
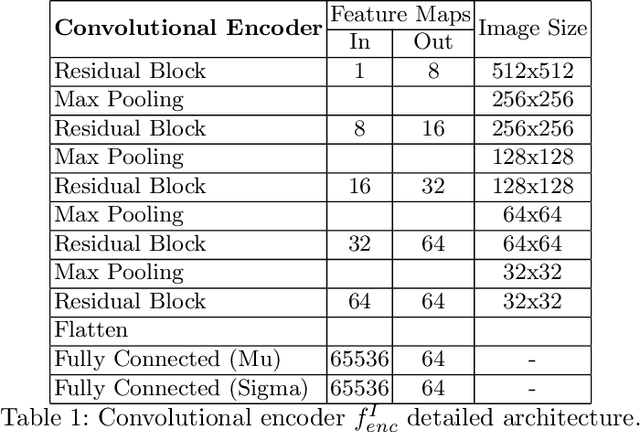
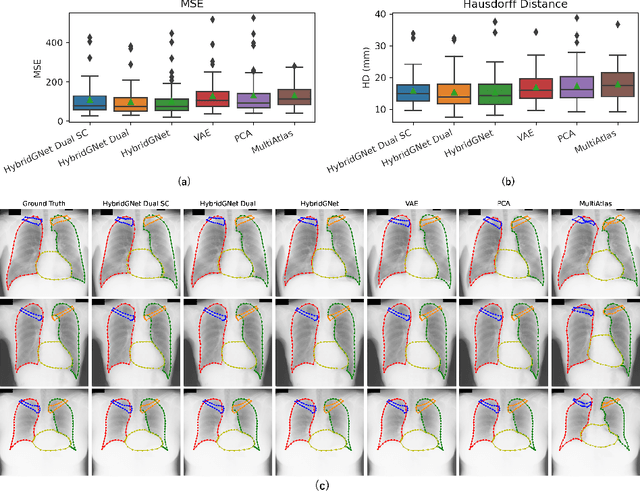
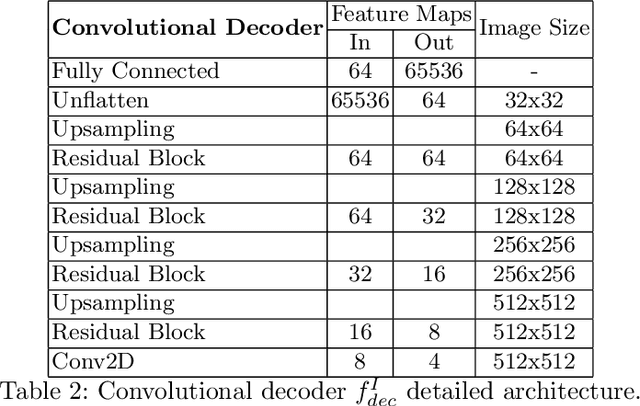
In this work we address the problem of landmark-based segmentation for anatomical structures. We propose HybridGNet, an encoder-decoder neural architecture which combines standard convolutions for image feature encoding, with graph convolutional neural networks to decode plausible representations of anatomical structures. We benchmark the proposed architecture considering other standard landmark and pixel-based models for anatomical segmentation in chest x-ray images, and found that HybridGNet is more robust to image occlusions. We also show that it can be used to construct landmark-based segmentations from pixel level annotations. Our experimental results suggest that HybridGNet produces accurate and anatomically plausible landmark-based segmentations, by naturally incorporating shape constraints within the decoding process via spectral convolutions.