 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscover, Hallucinate, and Adapt: Open Compound Domain Adaptation for Semantic Segmentation
Oct 08, 2021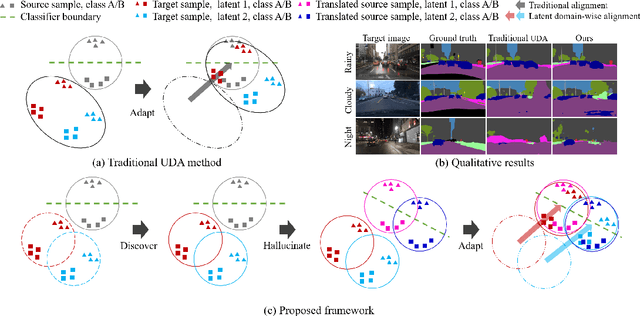
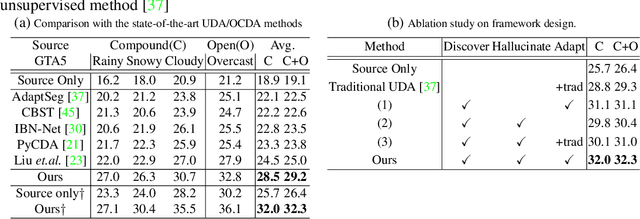
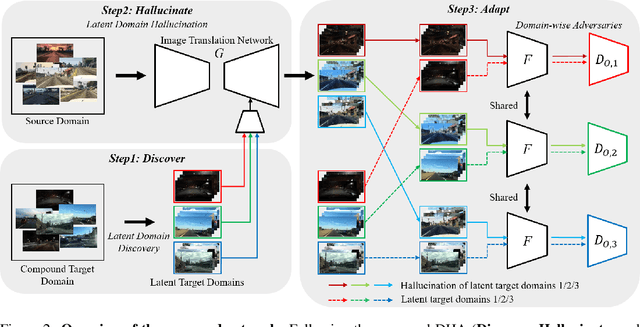
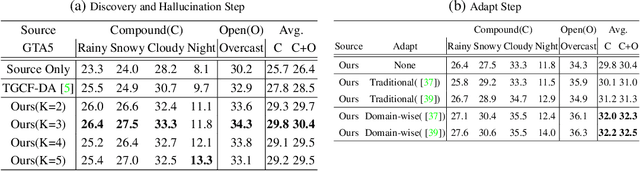
Unsupervised domain adaptation (UDA) for semantic segmentation has been attracting attention recently, as it could be beneficial for various label-scarce real-world scenarios (e.g., robot control, autonomous driving, medical imaging, etc.). Despite the significant progress in this field, current works mainly focus on a single-source single-target setting, which cannot handle more practical settings of multiple targets or even unseen targets. In this paper, we investigate open compound domain adaptation (OCDA), which deals with mixed and novel situations at the same time, for semantic segmentation. We present a novel framework based on three main design principles: discover, hallucinate, and adapt. The scheme first clusters compound target data based on style, discovering multiple latent domains (discover). Then, it hallucinates multiple latent target domains in source by using image-translation (hallucinate). This step ensures the latent domains in the source and the target to be paired. Finally, target-to-source alignment is learned separately between domains (adapt). In high-level, our solution replaces a hard OCDA problem with much easier multiple UDA problems. We evaluate our solution on standard benchmark GTA to C-driving, and achieved new state-of-the-art results.
Align-and-Attend Network for Globally and Locally Coherent Video Inpainting
May 30, 2019
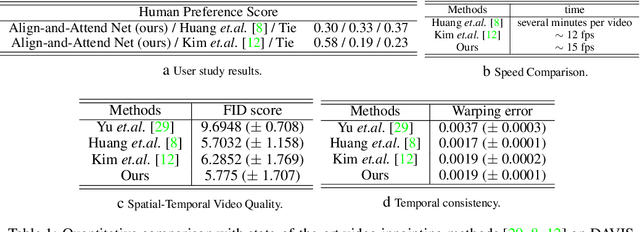
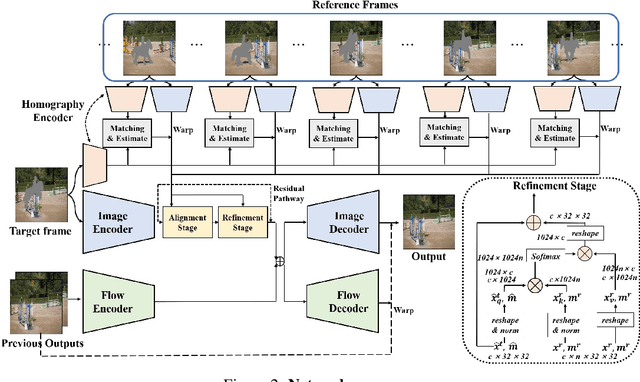

We propose a novel feed-forward network for video inpainting. We use a set of sampled video frames as the reference to take visible contents to fill the hole of a target frame. Our video inpainting network consists of two stages. The first stage is an alignment module that uses computed homographies between the reference frames and the target frame. The visible patches are then aggregated based on the frame similarity to fill in the target holes roughly. The second stage is a non-local attention module that matches the generated patches with known reference patches (in space and time) to refine the previous global alignment stage. Both stages consist of large spatial-temporal window size for the reference and thus enable modeling long-range correlations between distant information and the hole regions. Therefore, even challenging scenes with large or slowly moving holes can be handled, which have been hardly modeled by existing flow-based approach. Our network is also designed with a recurrent propagation stream to encourage temporal consistency in video results. Experiments on video object removal demonstrate that our method inpaints the holes with globally and locally coherent contents.