 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Consensus Learning
Mar 15, 2021
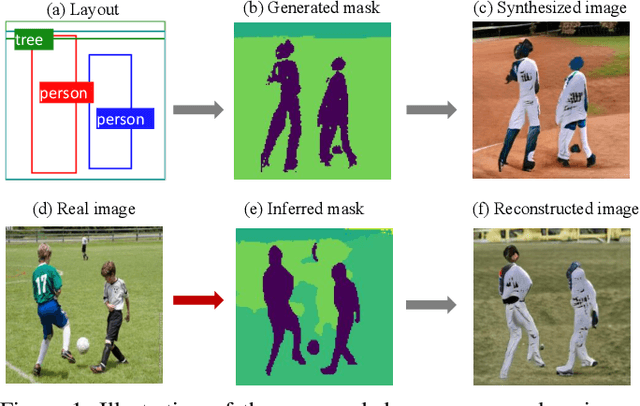
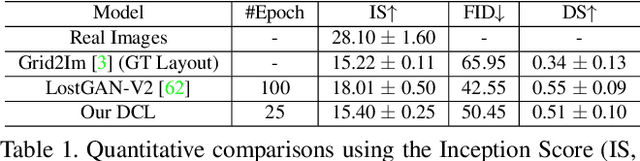
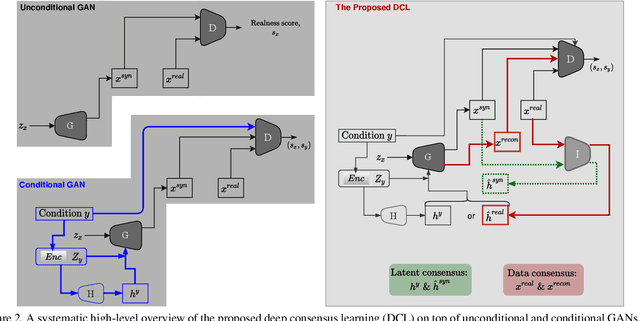
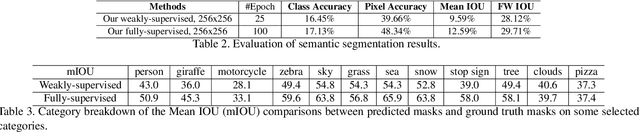
Both generative learning and discriminative learning have recently witnessed remarkable progress using Deep Neural Networks (DNNs). For structured input synthesis and structured output prediction problems (e.g., layout-to-image synthesis and image semantic segmentation respectively), they often are studied separately. This paper proposes deep consensus learning (DCL) for joint layout-to-image synthesis and weakly-supervised image semantic segmentation. The former is realized by a recently proposed LostGAN approach, and the latter by introducing an inference network as the third player joining the two-player game of LostGAN. Two deep consensus mappings are exploited to facilitate training the three networks end-to-end: Given an input layout (a list of object bounding boxes), the generator generates a mask (label map) and then use it to help synthesize an image. The inference network infers the mask for the synthesized image. Then, the latent consensus is measured between the mask generated by the generator and the one inferred by the inference network. For the real image corresponding to the input layout, its mask also is computed by the inference network, and then used by the generator to reconstruct the real image. Then, the data consensus is measured between the real image and its reconstructed image. The discriminator still plays the role of an adversary by computing the realness scores for a real image, its reconstructed image and a synthesized image. In experiments, our DCL is tested in the COCO-Stuff dataset. It obtains compelling layout-to-image synthesis results and weakly-supervised image semantic segmentation results.
Sequential Voting with Relational Box Fields for Active Object Detection
Nov 21, 2021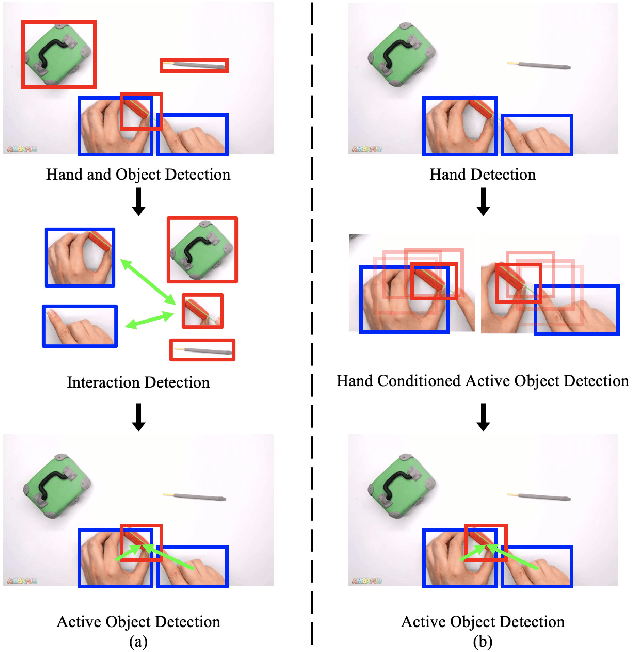

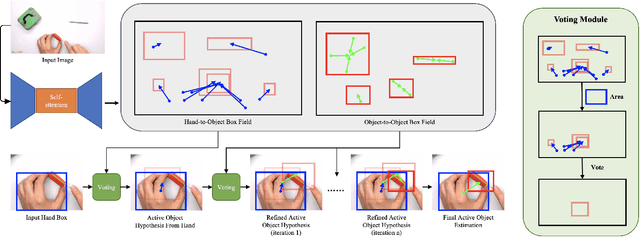

A key component of understanding hand-object interactions is the ability to identify the active object -- the object that is being manipulated by the human hand. In order to accurately localize the active object, any method must reason using information encoded by each image pixel, such as whether it belongs to the hand, the object, or the background. To leverage each pixel as evidence to determine the bounding box of the active object, we propose a pixel-wise voting function. Our pixel-wise voting function takes an initial bounding box as input and produces an improved bounding box of the active object as output. The voting function is designed so that each pixel inside of the input bounding box votes for an improved bounding box, and the box with the majority vote is selected as the output. We call the collection of bounding boxes generated inside of the voting function, the Relational Box Field, as it characterizes a field of bounding boxes defined in relationship to the current bounding box. While our voting function is able to improve the bounding box of the active object, one round of voting is typically not enough to accurately localize the active object. Therefore, we repeatedly apply the voting function to sequentially improve the location of the bounding box. However, since it is known that repeatedly applying a one-step predictor (i.e., auto-regressive processing with our voting function) can cause a data distribution shift, we mitigate this issue using reinforcement learning (RL). We adopt standard RL to learn the voting function parameters and show that it provides a meaningful improvement over a standard supervised learning approach. We perform experiments on two large-scale datasets: 100DOH and MECCANO, improving AP50 performance by 8% and 30%, respectively, over the state of the art.
Tomographic phase and attenuation extraction for a sample composed of unknown materials using X-ray propagation-based phase-contrast imaging
Oct 14, 2021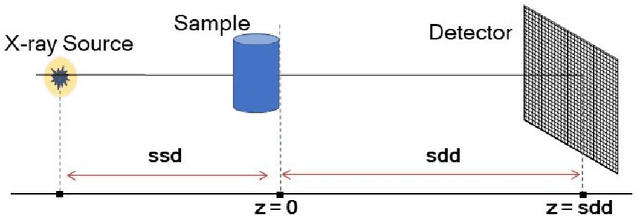
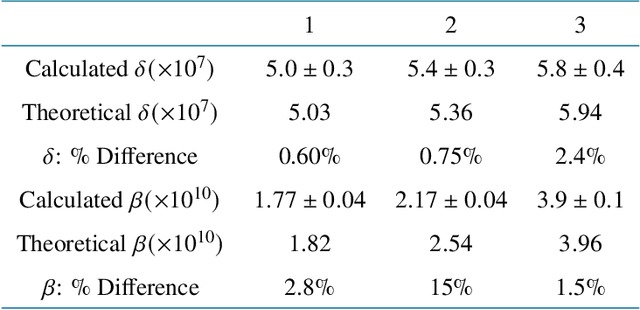
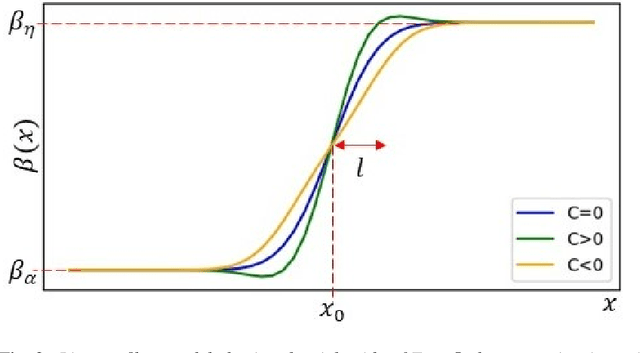
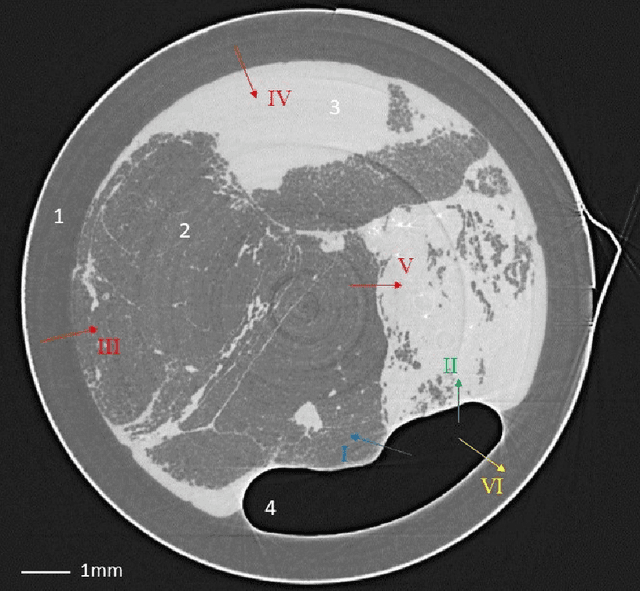
Propagation-based phase-contrast X-ray imaging (PB-PCXI) generates image contrast by utilizing sample-imposed phase-shifts. This has proven useful when imaging weakly-attenuating samples, as conventional attenuation-based imaging does not always provide adequate contrast. We present a PB-PCXI algorithm capable of extracting the X-ray attenuation, $\beta$, and refraction, $\delta$, components of the complex refractive index of distinct materials within an unknown sample. The method involves curve-fitting an error-function-based model to a phase-retrieved interface in a PB-PCXI tomographic reconstruction, which is obtained when Paganin-type phase-retrieval is applied with incorrect values of $\delta$ and $\beta$. The fit parameters can then be used to calculate true $\delta$ and $\beta$ values for composite materials. This approach requires no a priori sample information, making it broadly applicable. Our PB-PCXI reconstruction is single distance, requiring only one exposure per tomographic angle, which is important for radiosensitive samples. We apply this approach to a breast-tissue sample, recovering the refraction component, $\delta$, with 0.6 - 2.4\% accuracy compared to theoretical values.
Semi-supervised classification of radiology images with NoTeacher: A Teacher that is not Mean
Aug 10, 2021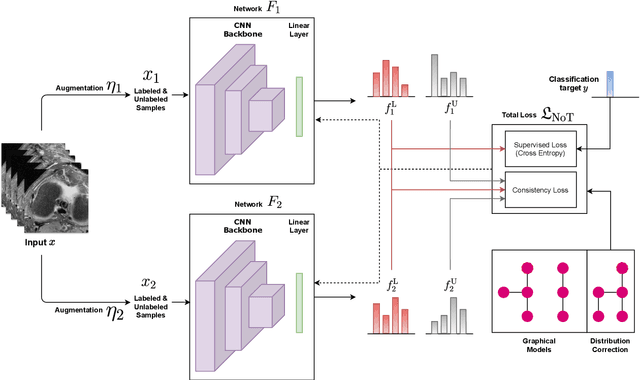
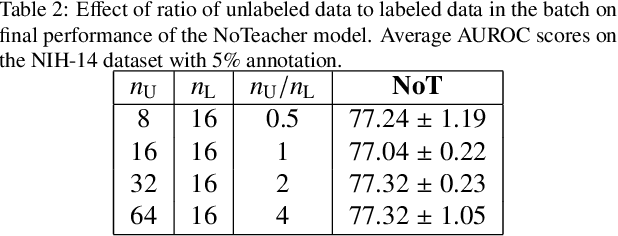
Deep learning models achieve strong performance for radiology image classification, but their practical application is bottlenecked by the need for large labeled training datasets. Semi-supervised learning (SSL) approaches leverage small labeled datasets alongside larger unlabeled datasets and offer potential for reducing labeling cost. In this work, we introduce NoTeacher, a novel consistency-based SSL framework which incorporates probabilistic graphical models. Unlike Mean Teacher which maintains a teacher network updated via a temporal ensemble, NoTeacher employs two independent networks, thereby eliminating the need for a teacher network. We demonstrate how NoTeacher can be customized to handle a range of challenges in radiology image classification. Specifically, we describe adaptations for scenarios with 2D and 3D inputs, uni and multi-label classification, and class distribution mismatch between labeled and unlabeled portions of the training data. In realistic empirical evaluations on three public benchmark datasets spanning the workhorse modalities of radiology (X-Ray, CT, MRI), we show that NoTeacher achieves over 90-95% of the fully supervised AUROC with less than 5-15% labeling budget. Further, NoTeacher outperforms established SSL methods with minimal hyperparameter tuning, and has implications as a principled and practical option for semisupervised learning in radiology applications.
RePOSE: Real-Time Iterative Rendering and Refinement for 6D Object Pose Estimation
Apr 01, 2021
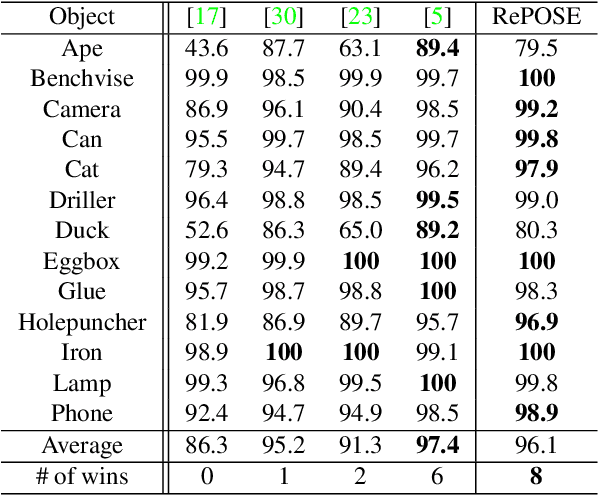
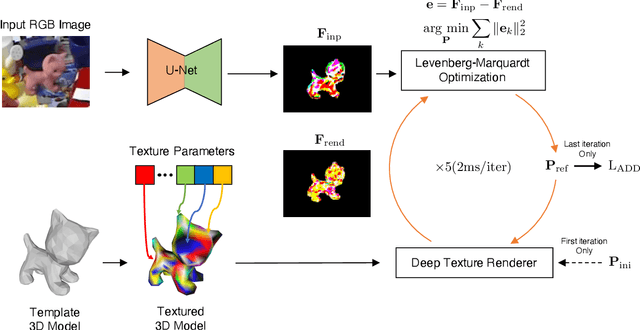
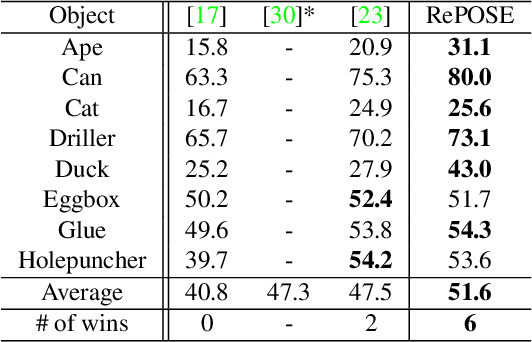
The use of iterative pose refinement is a critical processing step for 6D object pose estimation, and its performance depends greatly on one's choice of image representation. Image representations learned via deep convolutional neural networks (CNN) are currently the method of choice as they are able to robustly encode object keypoint locations. However, CNN-based image representations are computational expensive to use for iterative pose refinement, as they require that image features are extracted using a deep network, once for the input image and multiple times for rendered images during the refinement process. Instead of using a CNN to extract image features from a rendered RGB image, we propose to directly render a deep feature image. We call this deep texture rendering, where a shallow multi-layer perceptron is used to directly regress a view invariant image representation of an object. Using an estimate of the pose and deep texture rendering, our system can render an image representation in under 1ms. This image representation is optimized such that it makes it easier to perform nonlinear 6D pose estimation by adding a differentiable Levenberg-Marquardt optimization network and back-propagating the 6D pose alignment error. We call our method, RePOSE, a Real-time Iterative Rendering and Refinement algorithm for 6D POSE estimation. RePOSE runs at 71 FPS and achieves state-of-the-art accuracy of 51.6% on the Occlusion LineMOD dataset - a 4.1% absolute improvement over the prior art, and comparable performance on the YCB-Video dataset with a much faster runtime than the other pose refinement methods.
Neural Image Decompression: Learning to Render Better Image Previews
Dec 06, 2018
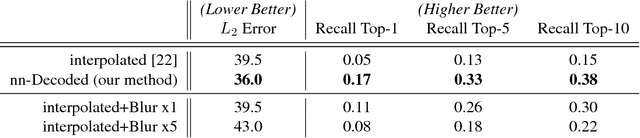


A rapidly increasing portion of Internet traffic is dominated by requests from mobile devices with limited- and metered-bandwidth constraints. To satisfy these requests, it has become standard practice for websites to transmit small and extremely compressed image previews as part of the initial page-load process. Recent work, based on an adaptive triangulation of the target image, has shown the ability to generate thumbnails of full images at extreme compression rates: 200 bytes or less with impressive gains (in terms of PSNR and SSIM) over both JPEG and WebP standards. However, qualitative assessments and preservation of semantic content can be less favorable. We present a novel method to significantly improve the reconstruction quality of the original image with no changes to the encoded information. Our neural-based decoding not only achieves higher PSNR and SSIM scores than the original methods, but also yields a substantial increase in semantic-level content preservation. In addition, by keeping the same encoding stream, our solution is completely inter-operable with the original decoder. The end result is suitable for a range of small-device deployments, as it involves only a single forward-pass through a small, scalable network.
Talk-to-Edit: Fine-Grained Facial Editing via Dialog
Sep 09, 2021


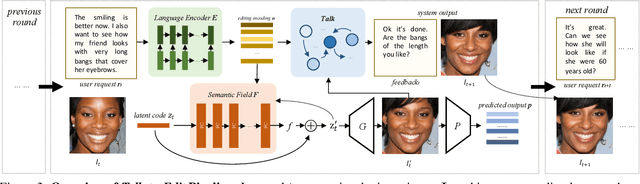
Facial editing is an important task in vision and graphics with numerous applications. However, existing works are incapable to deliver a continuous and fine-grained editing mode (e.g., editing a slightly smiling face to a big laughing one) with natural interactions with users. In this work, we propose Talk-to-Edit, an interactive facial editing framework that performs fine-grained attribute manipulation through dialog between the user and the system. Our key insight is to model a continual "semantic field" in the GAN latent space. 1) Unlike previous works that regard the editing as traversing straight lines in the latent space, here the fine-grained editing is formulated as finding a curving trajectory that respects fine-grained attribute landscape on the semantic field. 2) The curvature at each step is location-specific and determined by the input image as well as the users' language requests. 3) To engage the users in a meaningful dialog, our system generates language feedback by considering both the user request and the current state of the semantic field. We also contribute CelebA-Dialog, a visual-language facial editing dataset to facilitate large-scale study. Specifically, each image has manually annotated fine-grained attribute annotations as well as template-based textual descriptions in natural language. Extensive quantitative and qualitative experiments demonstrate the superiority of our framework in terms of 1) the smoothness of fine-grained editing, 2) the identity/attribute preservation, and 3) the visual photorealism and dialog fluency. Notably, user study validates that our overall system is consistently favored by around 80% of the participants. Our project page is https://www.mmlab-ntu.com/project/talkedit/.
Algorithmic encoding of protected characteristics and its implications on disparities across subgroups
Oct 27, 2021
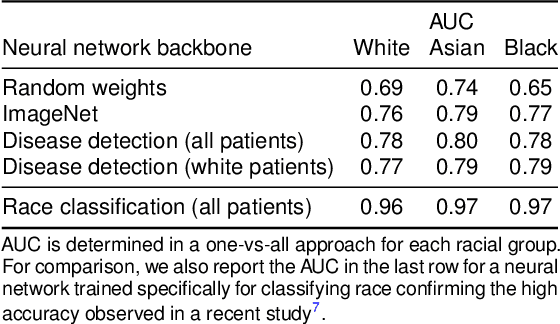
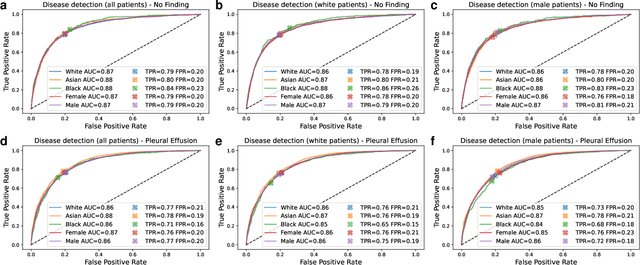
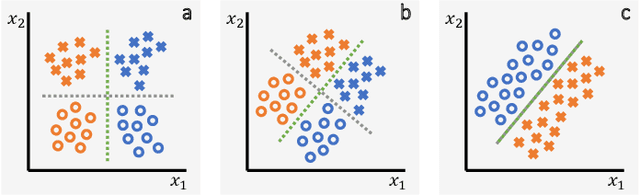
It has been rightfully emphasized that the use of AI for clinical decision making could amplify health disparities. A machine learning model may pick up undesirable correlations, for example, between a patient's racial identity and clinical outcome. Such correlations are often present in (historical) data used for model development. There has been an increase in studies reporting biases in disease detection models across patient subgroups. Besides the scarcity of data from underserved populations, very little is known about how these biases are encoded and how one may reduce or even remove disparate performance. There is some speculation whether algorithms may recognize patient characteristics such as biological sex or racial identity, and then directly or indirectly use this information when making predictions. But it remains unclear how we can establish whether such information is actually used. This article aims to shed some light on these issues by exploring new methodology allowing intuitive inspections of the inner working of machine learning models for image-based detection of disease. We also evaluate an effective yet debatable technique for addressing disparities leveraging the automatic prediction of patient characteristics, resulting in models with comparable true and false positive rates across subgroups. Our findings may stimulate the discussion about safe and ethical use of AI.
Detect and Locate: A Face Anti-Manipulation Approach with Semantic and Noise-level Supervision
Jul 13, 2021
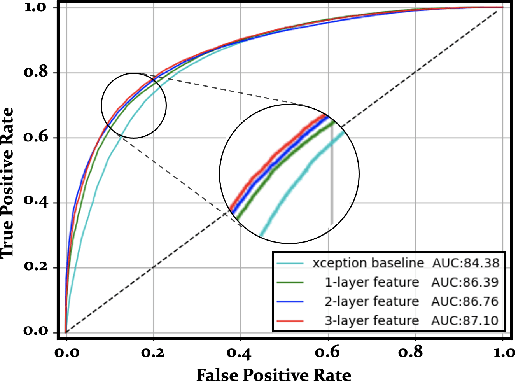
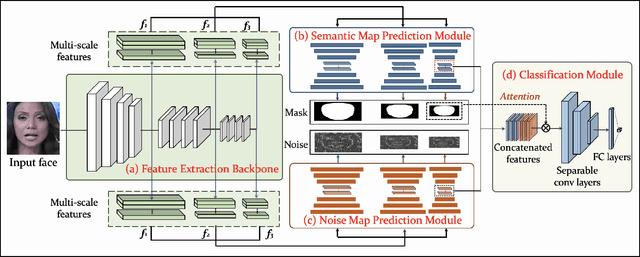
The technological advancements of deep learning have enabled sophisticated face manipulation schemes, raising severe trust issues and security concerns in modern society. Generally speaking, detecting manipulated faces and locating the potentially altered regions are challenging tasks. Herein, we propose a conceptually simple but effective method to efficiently detect forged faces in an image while simultaneously locating the manipulated regions. The proposed scheme relies on a segmentation map that delivers meaningful high-level semantic information clues about the image. Furthermore, a noise map is estimated, playing a complementary role in capturing low-level clues and subsequently empowering decision-making. Finally, the features from these two modules are combined to distinguish fake faces. Extensive experiments show that the proposed model achieves state-of-the-art detection accuracy and remarkable localization performance.
Disentangling Generative Factors in Natural Language with Discrete Variational Autoencoders
Sep 15, 2021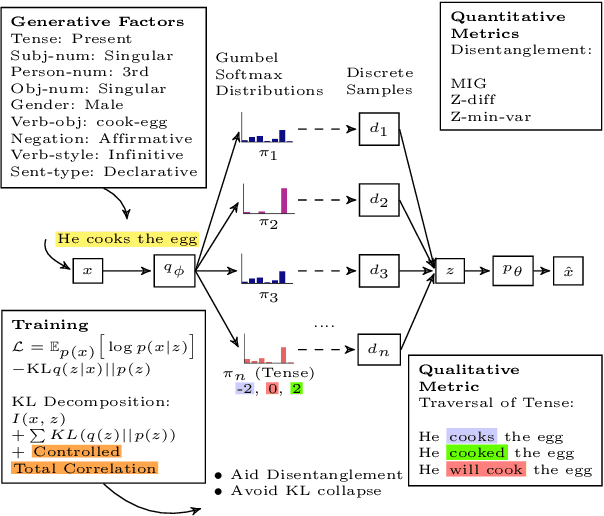
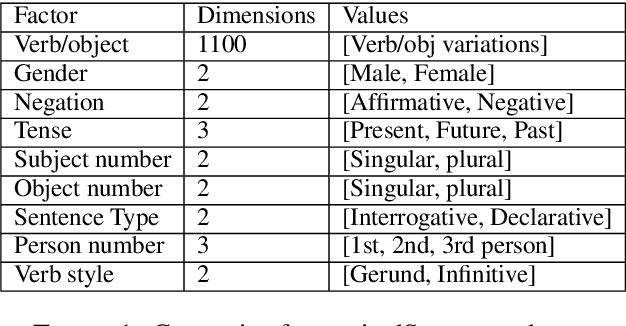
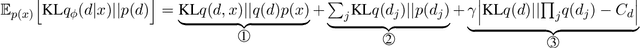
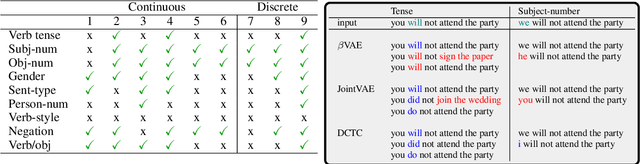
The ability of learning disentangled representations represents a major step for interpretable NLP systems as it allows latent linguistic features to be controlled. Most approaches to disentanglement rely on continuous variables, both for images and text. We argue that despite being suitable for image datasets, continuous variables may not be ideal to model features of textual data, due to the fact that most generative factors in text are discrete. We propose a Variational Autoencoder based method which models language features as discrete variables and encourages independence between variables for learning disentangled representations. The proposed model outperforms continuous and discrete baselines on several qualitative and quantitative benchmarks for disentanglement as well as on a text style transfer downstream application.