 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Offense Detection in Dravidian Languages using Code-Mixing Index based Focal Loss
Nov 12, 2021
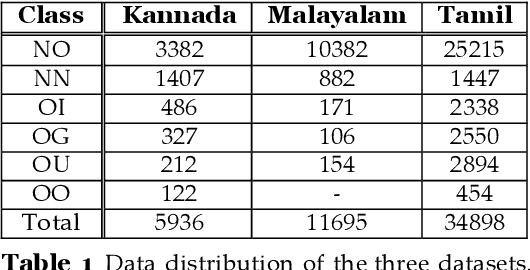

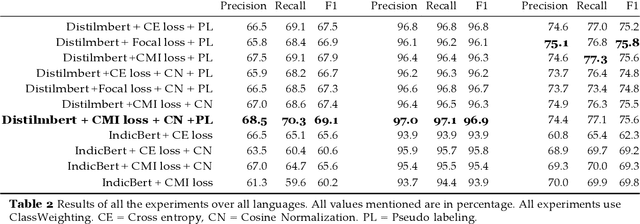
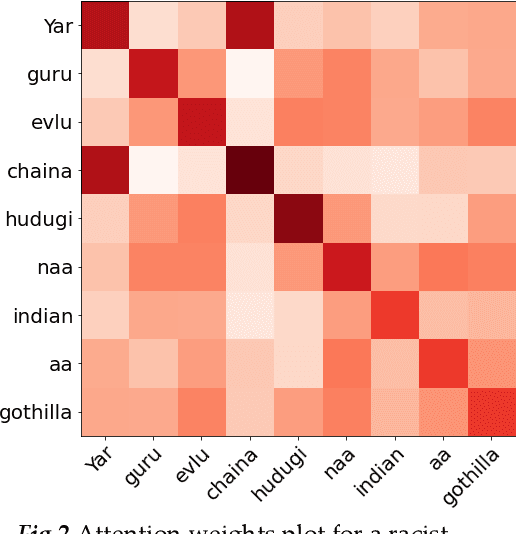
Over the past decade, we have seen exponential growth in online content fueled by social media platforms. Data generation of this scale comes with the caveat of insurmountable offensive content in it. The complexity of identifying offensive content is exacerbated by the usage of multiple modalities (image, language, etc.), code mixed language and more. Moreover, even if we carefully sample and annotate offensive content, there will always exist significant class imbalance in offensive vs non offensive content. In this paper, we introduce a novel Code-Mixing Index (CMI) based focal loss which circumvents two challenges (1) code mixing in languages (2) class imbalance problem for Dravidian language offense detection. We also replace the conventional dot product-based classifier with the cosine-based classifier which results in a boost in performance. Further, we use multilingual models that help transfer characteristics learnt across languages to work effectively with low resourced languages. It is also important to note that our model handles instances of mixed script (say usage of Latin and Dravidian - Tamil script) as well. Our model can handle offensive language detection in a low-resource, class imbalanced, multilingual and code mixed setting.
Shape from Blur: Recovering Textured 3D Shape and Motion of Fast Moving Objects
Jun 16, 2021
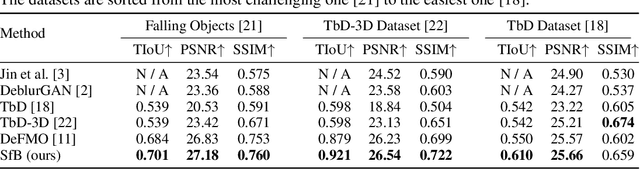
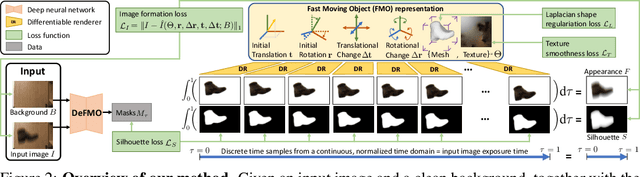
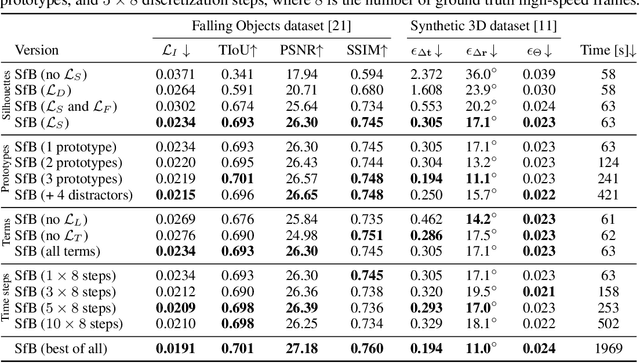
We address the novel task of jointly reconstructing the 3D shape, texture, and motion of an object from a single motion-blurred image. While previous approaches address the deblurring problem only in the 2D image domain, our proposed rigorous modeling of all object properties in the 3D domain enables the correct description of arbitrary object motion. This leads to significantly better image decomposition and sharper deblurring results. We model the observed appearance of a motion-blurred object as a combination of the background and a 3D object with constant translation and rotation. Our method minimizes a loss on reconstructing the input image via differentiable rendering with suitable regularizers. This enables estimating the textured 3D mesh of the blurred object with high fidelity. Our method substantially outperforms competing approaches on several benchmarks for fast moving objects deblurring. Qualitative results show that the reconstructed 3D mesh generates high-quality temporal super-resolution and novel views of the deblurred object.
Towards robust vision by multi-task learning on monkey visual cortex
Jul 29, 2021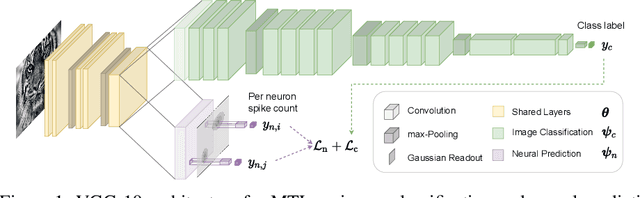
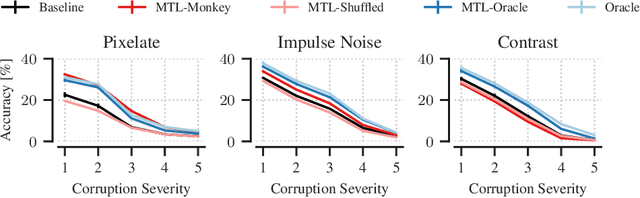
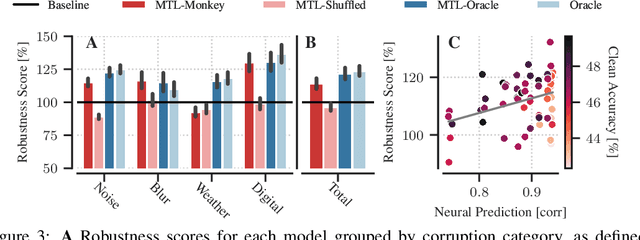
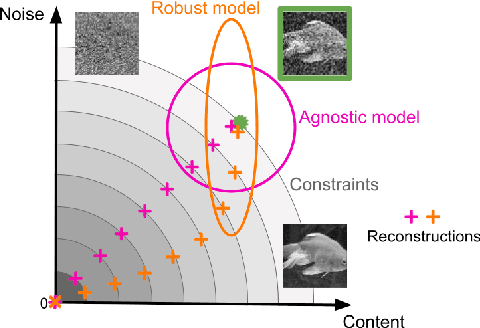
Deep neural networks set the state-of-the-art across many tasks in computer vision, but their generalization ability to image distortions is surprisingly fragile. In contrast, the mammalian visual system is robust to a wide range of perturbations. Recent work suggests that this generalization ability can be explained by useful inductive biases encoded in the representations of visual stimuli throughout the visual cortex. Here, we successfully leveraged these inductive biases with a multi-task learning approach: we jointly trained a deep network to perform image classification and to predict neural activity in macaque primary visual cortex (V1). We measured the out-of-distribution generalization abilities of our network by testing its robustness to image distortions. We found that co-training on monkey V1 data leads to increased robustness despite the absence of those distortions during training. Additionally, we showed that our network's robustness is very close to that of an Oracle network where parts of the architecture are directly trained on noisy images. Our results also demonstrated that the network's representations become more brain-like as their robustness improves. Using a novel constrained reconstruction analysis, we investigated what makes our brain-regularized network more robust. We found that our co-trained network is more sensitive to content than noise when compared to a Baseline network that we trained for image classification alone. Using DeepGaze-predicted saliency maps for ImageNet images, we found that our monkey co-trained network tends to be more sensitive to salient regions in a scene, reminiscent of existing theories on the role of V1 in the detection of object borders and bottom-up saliency. Overall, our work expands the promising research avenue of transferring inductive biases from the brain, and provides a novel analysis of the effects of our transfer.
View Blind-spot as Inpainting: Self-Supervised Denoising with Mask Guided Residual Convolution
Sep 10, 2021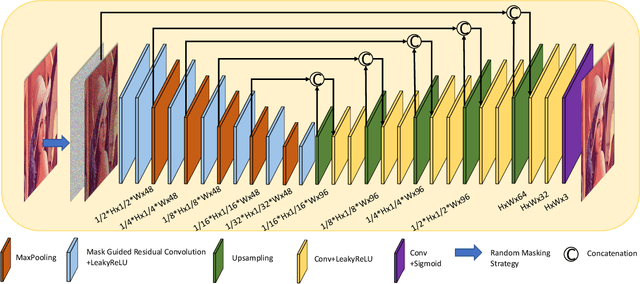
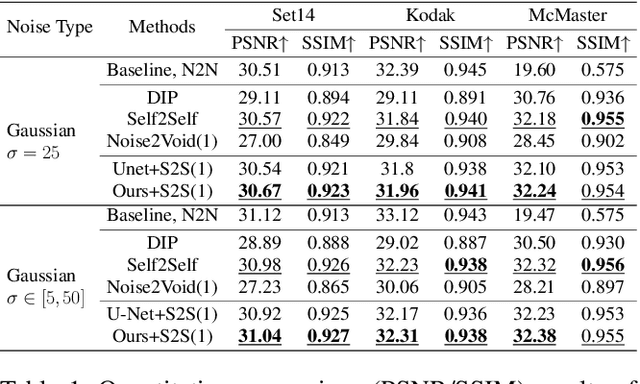
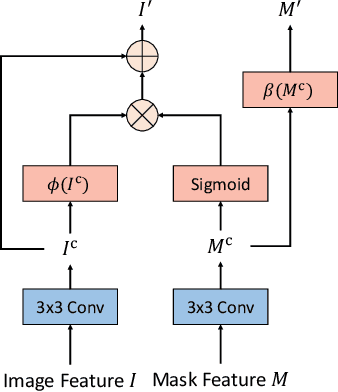
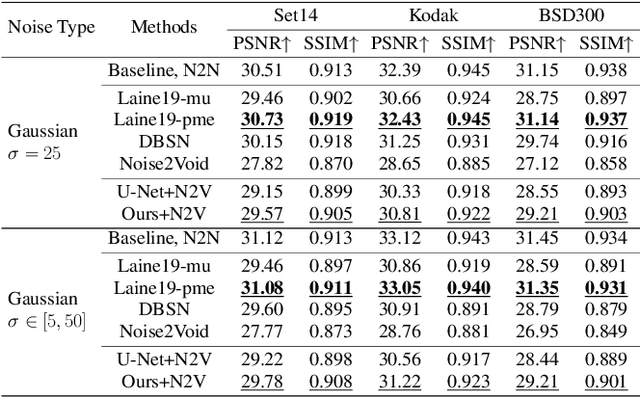
In recent years, self-supervised denoising methods have shown impressive performance, which circumvent painstaking collection procedure of noisy-clean image pairs in supervised denoising methods and boost denoising applicability in real world. One of well-known self-supervised denoising strategies is the blind-spot training scheme. However, a few works attempt to improve blind-spot based self-denoiser in the aspect of network architecture. In this paper, we take an intuitive view of blind-spot strategy and consider its process of using neighbor pixels to predict manipulated pixels as an inpainting process. Therefore, we propose a novel Mask Guided Residual Convolution (MGRConv) into common convolutional neural networks, e.g. U-Net, to promote blind-spot based denoising. Our MGRConv can be regarded as soft partial convolution and find a trade-off among partial convolution, learnable attention maps, and gated convolution. It enables dynamic mask learning with appropriate mask constrain. Different from partial convolution and gated convolution, it provides moderate freedom for network learning. It also avoids leveraging external learnable parameters for mask activation, unlike learnable attention maps. The experiments show that our proposed plug-and-play MGRConv can assist blind-spot based denoising network to reach promising results on both existing single-image based and dataset-based methods.
Convolutional Neural Network (CNN) vs Visual Transformer (ViT) for Digital Holography
Aug 20, 2021
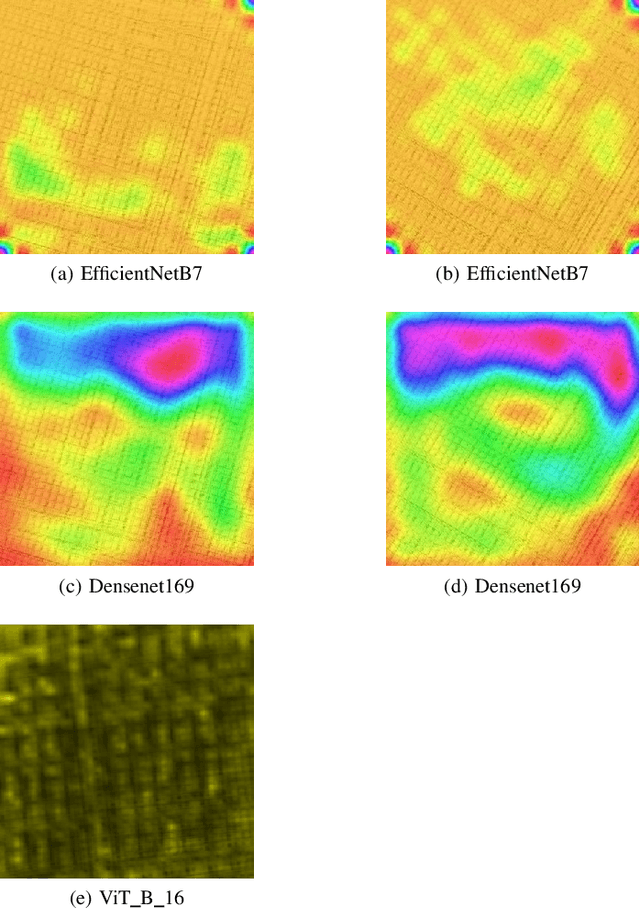

In Digital Holography (DH), it is crucial to extract the object distance from a hologram in order to reconstruct its amplitude and phase. This step is called auto-focusing and it is conventionally solved by first reconstructing a stack of images and then by sharpening each reconstructed image using a focus metric such as entropy or variance. The distance corresponding to the sharpest image is considered the focal position. This approach, while effective, is computationally demanding and time-consuming. In this paper, the determination of the distance is performed by Deep Learning (DL). Two deep learning (DL) architectures are compared: Convolutional Neural Network (CNN)and Visual transformer (ViT). ViT and CNN are used to cope with the problem of auto-focusing as a classification problem. Compared to a first attempt [11] in which the distance between two consecutive classes was 100{\mu}m, our proposal allows us to drastically reduce this distance to 1{\mu}m. Moreover, ViT reaches similar accuracy and is more robust than CNN.
Patchy Image Structure Classification Using Multi-Orientation Region Transform
Dec 02, 2019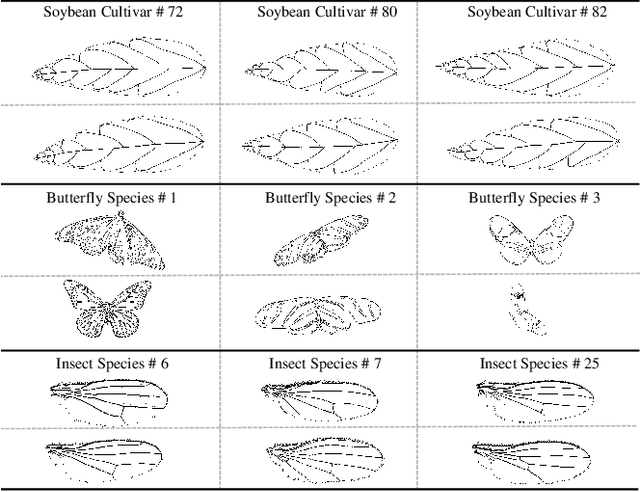
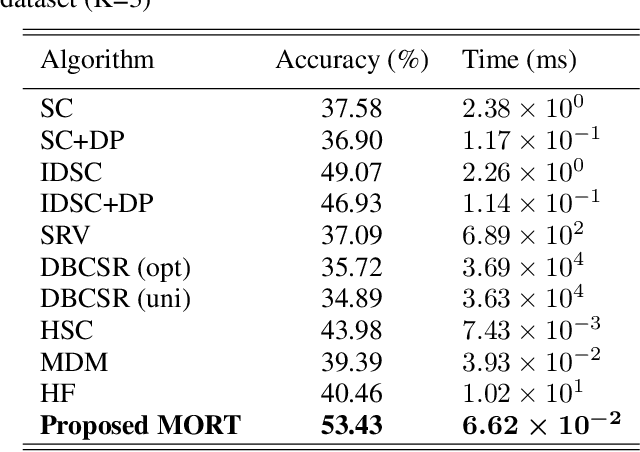


Exterior contour and interior structure are both vital features for classifying objects. However, most of the existing methods consider exterior contour feature and internal structure feature separately, and thus fail to function when classifying patchy image structures that have similar contours and flexible structures. To address above limitations, this paper proposes a novel Multi-Orientation Region Transform (MORT), which can effectively characterize both contour and structure features simultaneously, for patchy image structure classification. MORT is performed over multiple orientation regions at multiple scales to effectively integrate patchy features, and thus enables a better description of the shape in a coarse-to-fine manner. Moreover, the proposed MORT can be extended to combine with the deep convolutional neural network techniques, for further enhancement of classification accuracy. Very encouraging experimental results on the challenging ultra-fine-grained cultivar recognition task, insect wing recognition task, and large variation butterfly recognition task are obtained, which demonstrate the effectiveness and superiority of the proposed MORT over the state-of-the-art methods in classifying patchy image structures. Our code and three patchy image structure datasets are available at: https://github.com/XiaohanYu-GU/MReT2019.
TADA: Taxonomy Adaptive Domain Adaptation
Sep 10, 2021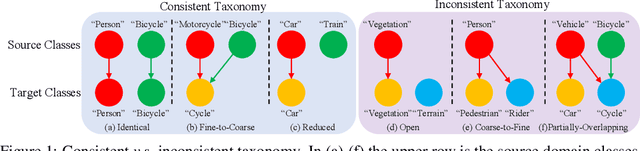
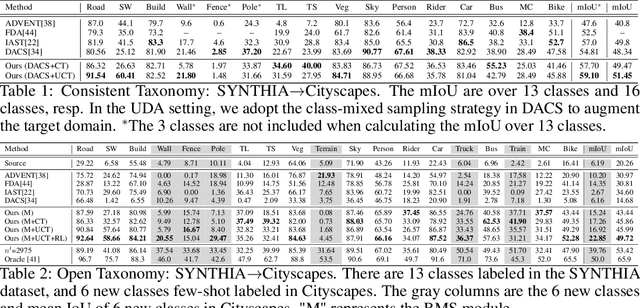
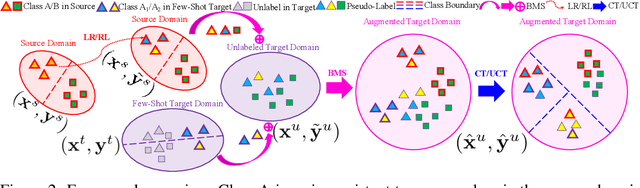
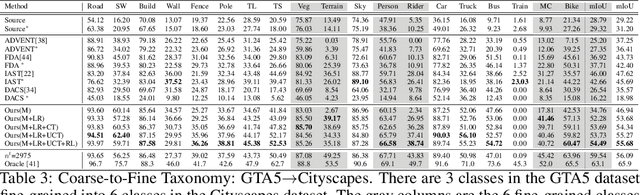
Traditional domain adaptation addresses the task of adapting a model to a novel target domain under limited or no additional supervision. While tackling the input domain gap, the standard domain adaptation settings assume no domain change in the output space. In semantic prediction tasks, different datasets are often labeled according to different semantic taxonomies. In many real-world settings, the target domain task requires a different taxonomy than the one imposed by the source domain. We therefore introduce the more general taxonomy adaptive domain adaptation (TADA) problem, allowing for inconsistent taxonomies between the two domains. We further propose an approach that jointly addresses the image-level and label-level domain adaptation. On the label-level, we employ a bilateral mixed sampling strategy to augment the target domain, and a relabelling method to unify and align the label spaces. We address the image-level domain gap by proposing an uncertainty-rectified contrastive learning method, leading to more domain-invariant and class discriminative features. We extensively evaluate the effectiveness of our framework under different TADA settings: open taxonomy, coarse-to-fine taxonomy, and partially-overlapping taxonomy. Our framework outperforms previous state-of-the-art by a large margin, while capable of adapting to new target domain taxonomies.
Process of image super-resolution
Apr 17, 2019In this paper we explain a process of super-resolution reconstruction allowing to increase the resolution of an image.The need for high-resolution digital images exists in diverse domains, for example the medical and spatial domains. The obtaining of high-resolution digital images can be made at the time of the shooting, but it is often synonymic of important costs because of the necessary material to avoid such costs, it is known how to use methods of super-resolution reconstruction, consisting from one or several low resolution images to obtain a high-resolution image. The american patent US 9 208 537 describes such an algorithm. A zone of one low-resolution image is isolated and categorized according to the information contained in pixels forming the borders of the zone. The category of it zone determines the type of interpolation used to add pixels in aforementioned zone, to increase the neatness of the images. It is also known how to reconstruct a low-resolution image there high-resolution image by using a model of super-resolution reconstruction whose learning is based on networks of neurons and on image or a picture library. The demand of chinese patent CN 107563965 and the scientist publication "Pixel Recursive Super Resolution", R. Dahl, M. Norouzi, J. Shlens propose such methods.
Superpixel-based Domain-Knowledge Infusion in Computer Vision
May 20, 2021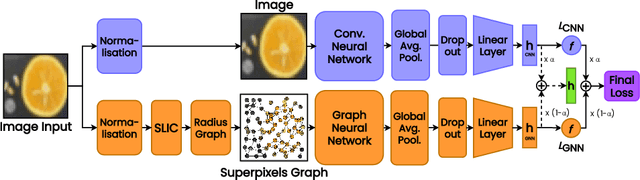

Superpixels are higher-order perceptual groups of pixels in an image, often carrying much more information than raw pixels. There is an inherent relational structure to the relationship among different superpixels of an image. This relational information can convey some form of domain information about the image, e.g. relationship between superpixels representing two eyes in a cat image. Our interest in this paper is to construct computer vision models, specifically those based on Deep Neural Networks (DNNs) to incorporate these superpixels information. We propose a methodology to construct a hybrid model that leverages (a) Convolutional Neural Network (CNN) to deal with spatial information in an image, and (b) Graph Neural Network (GNN) to deal with relational superpixel information in the image. The proposed deep model is learned using a generic hybrid loss function that we call a `hybrid' loss. We evaluate the predictive performance of our proposed hybrid vision model on four popular image classification datasets: MNIST, FMNIST, CIFAR-10 and CIFAR-100. Moreover, we evaluate our method on three real-world classification tasks: COVID-19 X-Ray Detection, LFW Face Recognition, and SOCOFing Fingerprint Identification. The results demonstrate that the relational superpixel information provided via a GNN could improve the performance of standard CNN-based vision systems.
Neural Network Kalman filtering for 3D object tracking from linear array ultrasound data
Nov 18, 2021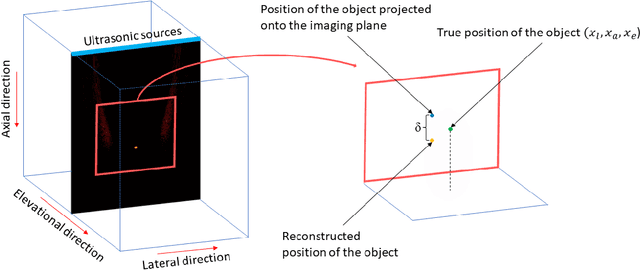
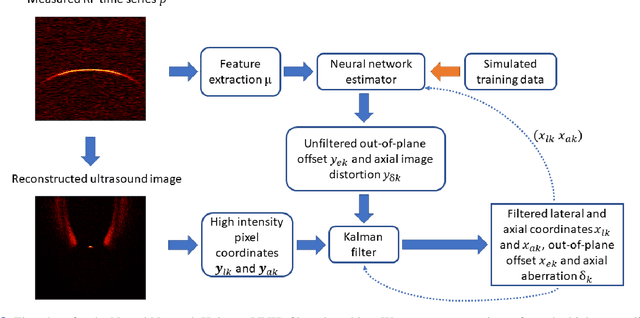
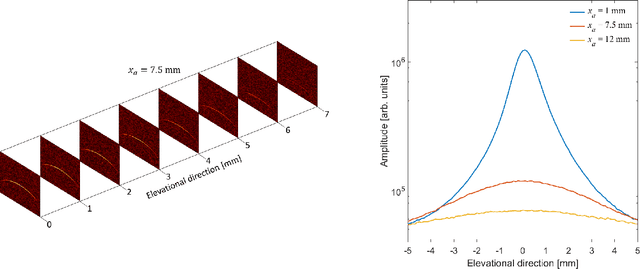
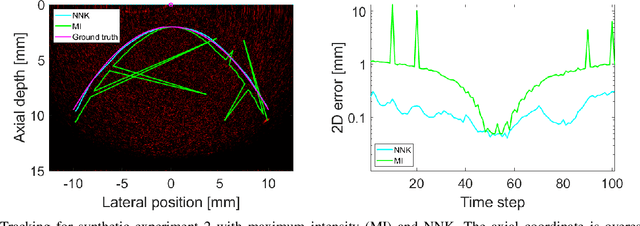
Many interventional surgical procedures rely on medical imaging to visualise and track instruments. Such imaging methods not only need to be real-time capable, but also provide accurate and robust positional information. In ultrasound applications, typically only two-dimensional data from a linear array are available, and as such obtaining accurate positional estimation in three dimensions is non-trivial. In this work, we first train a neural network, using realistic synthetic training data, to estimate the out-of-plane offset of an object with the associated axial aberration in the reconstructed ultrasound image. The obtained estimate is then combined with a Kalman filtering approach that utilises positioning estimates obtained in previous time-frames to improve localisation robustness and reduce the impact of measurement noise. The accuracy of the proposed method is evaluated using simulations, and its practical applicability is demonstrated on experimental data obtained using a novel optical ultrasound imaging setup. Accurate and robust positional information is provided in real-time. Axial and lateral coordinates for out-of-plane objects are estimated with a mean error of 0.1mm for simulated data and a mean error of 0.2mm for experimental data. Three-dimensional localisation is most accurate for elevational distances larger than 1mm, with a maximum distance of 5mm considered for a 25mm aperture.