 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Intrinsic Image Popularity Assessment
Jul 04, 2019
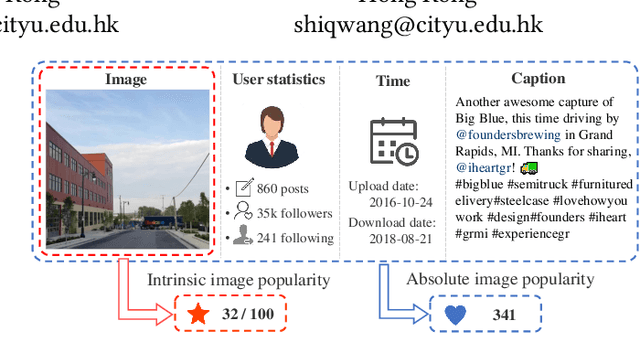
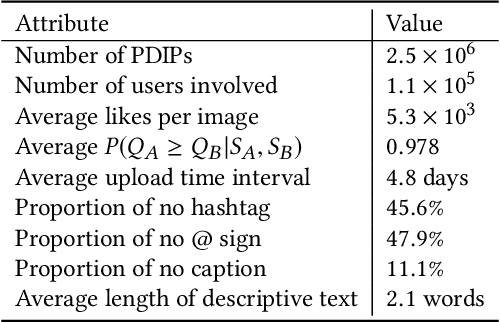


The goal of research in automatic image popularity assessment (IPA) is to develop computational models that can accurately predict the potential of a social image to go viral on the Internet. Here, we aim to single out the contribution of visual content to image popularity, i.e., intrinsic image popularity. Specifically, we first describe a probabilistic method to generate massive popularity-discriminable image pairs, based on which the first large-scale image database for intrinsic IPA (I$^2$PA) is established. We then develop computational models for I$^2$PA based on deep neural networks, optimizing for ranking consistency with millions of popularity-discriminable image pairs. Experiments on Instagram and other social platforms demonstrate that the optimized model performs favorably against existing methods, exhibits reasonable generalizability on different databases, and even surpasses human-level performance on Instagram. In addition, we conduct a psychophysical experiment to analyze various aspects of human behavior in I$^2$PA.
DMF-Net: Dual-Branch Multi-Scale Feature Fusion Network for copy forgery identification of anti-counterfeiting QR code
Jan 19, 2022
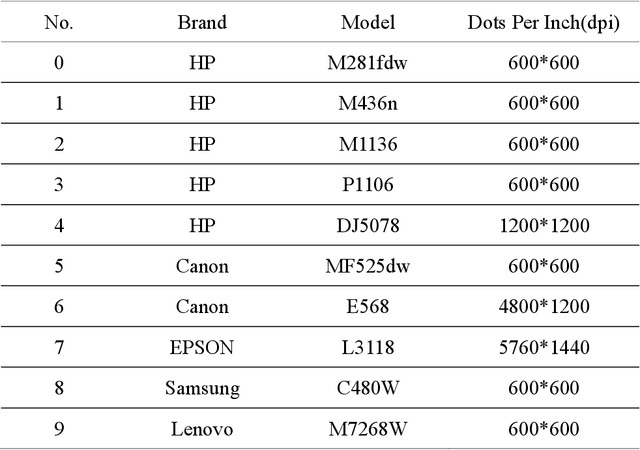

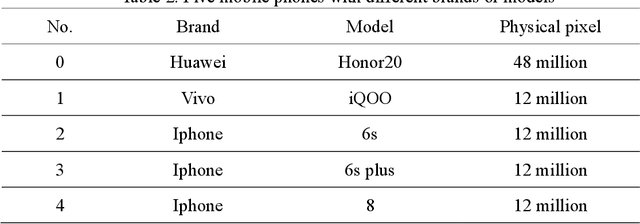
Anti-counterfeiting QR codes are widely used in people's work and life, especially in product packaging. However, the anti-counterfeiting QR code has the risk of being copied and forged in the circulation process. In reality, copying is usually based on genuine anti-counterfeiting QR codes, but the brands and models of copiers are diverse, and it is extremely difficult to determine which individual copier the forged anti-counterfeiting code come from. In response to the above problems, this paper proposes a method for copy forgery identification of anti-counterfeiting QR code based on deep learning. We first analyze the production principle of anti-counterfeiting QR code, and convert the identification of copy forgery to device category forensics, and then a Dual-Branch Multi-Scale Feature Fusion network is proposed. During the design of the network, we conducted a detailed analysis of the data preprocessing layer, single-branch design, etc., combined with experiments, the specific structure of the dual-branch multi-scale feature fusion network is determined. The experimental results show that the proposed method has achieved a high accuracy of copy forgery identification, which exceeds the current series of methods in the field of image forensics.
DuDoTrans: Dual-Domain Transformer Provides More Attention for Sinogram Restoration in Sparse-View CT Reconstruction
Nov 25, 2021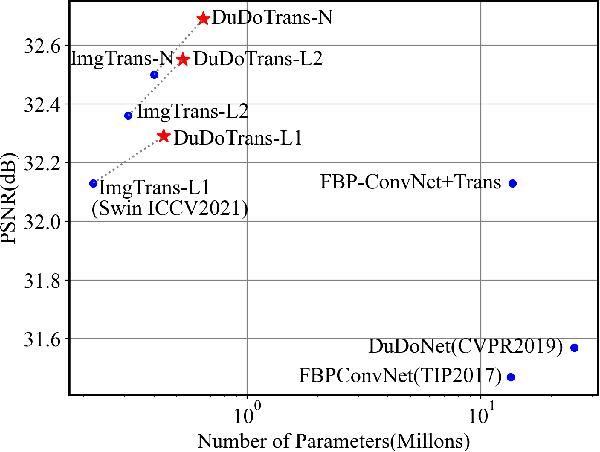
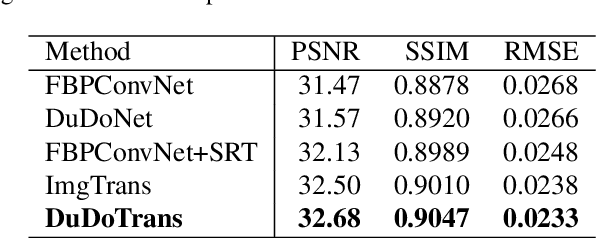
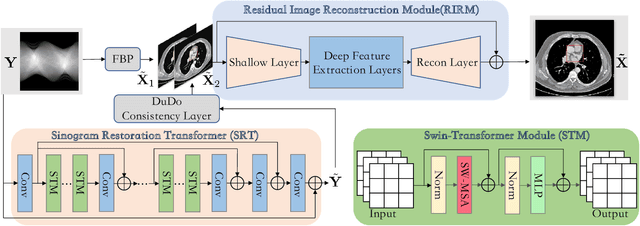
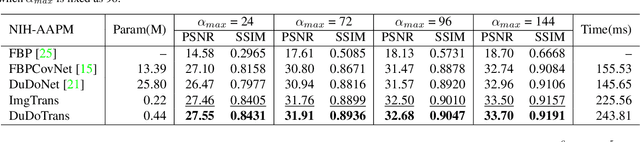
While Computed Tomography (CT) reconstruction from X-ray sinograms is necessary for clinical diagnosis, iodine radiation in the imaging process induces irreversible injury, thereby driving researchers to study sparse-view CT reconstruction, that is, recovering a high-quality CT image from a sparse set of sinogram views. Iterative models are proposed to alleviate the appeared artifacts in sparse-view CT images, but the computation cost is too expensive. Then deep-learning-based methods have gained prevalence due to the excellent performances and lower computation. However, these methods ignore the mismatch between the CNN's \textbf{local} feature extraction capability and the sinogram's \textbf{global} characteristics. To overcome the problem, we propose \textbf{Du}al-\textbf{Do}main \textbf{Trans}former (\textbf{DuDoTrans}) to simultaneously restore informative sinograms via the long-range dependency modeling capability of Transformer and reconstruct CT image with both the enhanced and raw sinograms. With such a novel design, reconstruction performance on the NIH-AAPM dataset and COVID-19 dataset experimentally confirms the effectiveness and generalizability of DuDoTrans with fewer involved parameters. Extensive experiments also demonstrate its robustness with different noise-level scenarios for sparse-view CT reconstruction. The code and models are publicly available at https://github.com/DuDoTrans/CODE
Superpixel Pre-Segmentation of HER2 Slides for Efficient Annotation
Jan 19, 2022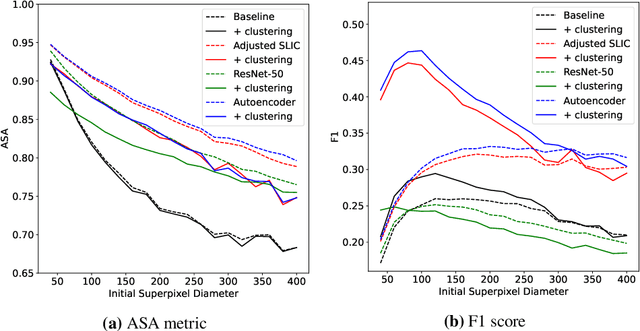
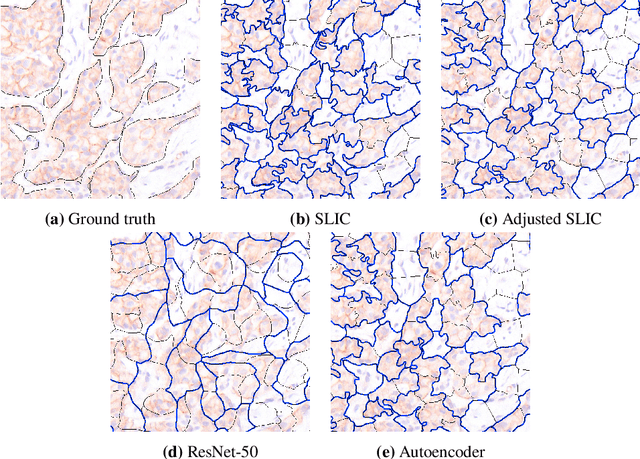
Supervised deep learning has shown state-of-the-art performance for medical image segmentation across different applications, including histopathology and cancer research; however, the manual annotation of such data is extremely laborious. In this work, we explore the use of superpixel approaches to compute a pre-segmentation of HER2 stained images for breast cancer diagnosis that facilitates faster manual annotation and correction in a second step. Four methods are compared: Standard Simple Linear Iterative Clustering (SLIC) as a baseline, a domain adapted SLIC, and superpixels based on feature embeddings of a pretrained ResNet-50 and a denoising autoencoder. To tackle oversegmentation, we propose to hierarchically merge superpixels, based on their content in the respective feature space. When evaluating the approaches on fully manually annotated images, we observe that the autoencoder-based superpixels achieve a 23% increase in boundary F1 score compared to the baseline SLIC superpixels. Furthermore, the boundary F1 score increases by 73% when hierarchical clustering is applied on the adapted SLIC and the autoencoder-based superpixels. These evaluations show encouraging first results for a pre-segmentation for efficient manual refinement without the need for an initial set of annotated training data.
Similarity-Based Clustering for Enhancing Image Classification Architectures
Nov 03, 2020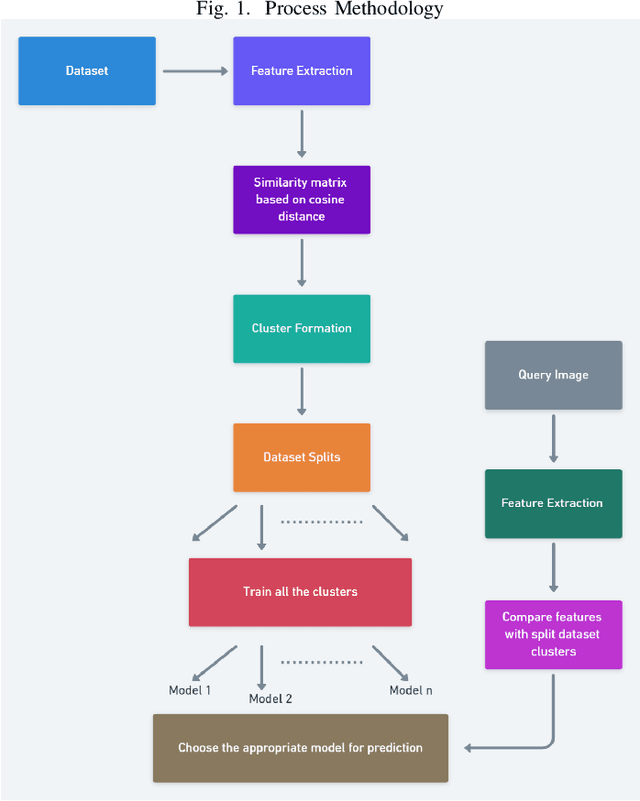
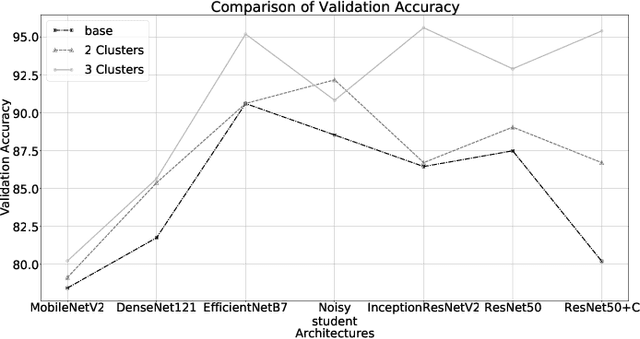
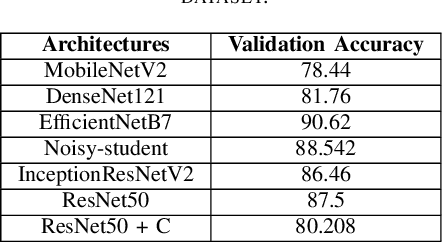

Convolutional networks are at the center of best in class computer vision applications for a wide assortment of undertakings. Since 2014, profound amount of work began to make better convolutional architectures, yielding generous additions in different benchmarks. Albeit expanded model size and computational cost will, in general, mean prompt quality increases for most undertakings but, the architectures now need to have some additional information to increase the performance. We show empirical evidence that with the amalgamation of content-based image similarity and deep learning models, we can provide the flow of information which can be used in making clustered learning possible. We show how parallel training of sub-dataset clusters not only reduces the cost of computation but also increases the benchmark accuracies by 5-11 percent.
When less is more: Simplifying inputs aids neural network understanding
Jan 19, 2022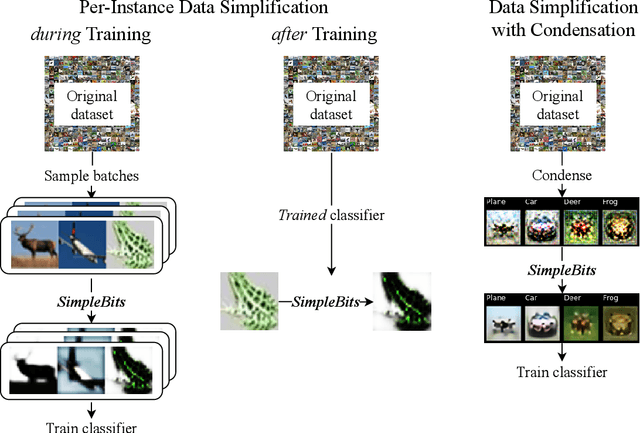

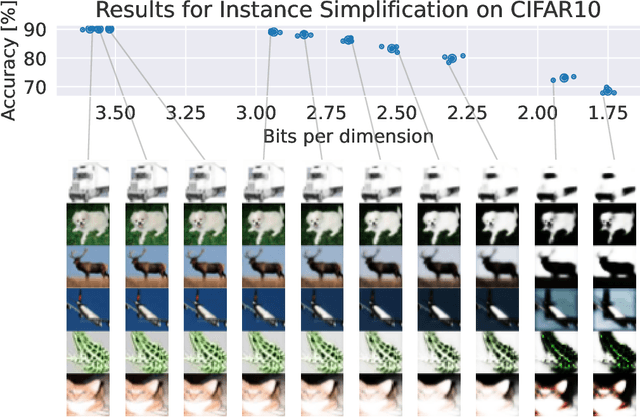
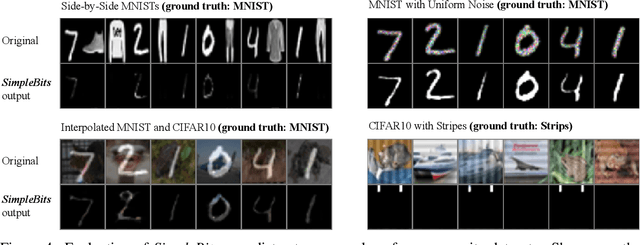
How do neural network image classifiers respond to simpler and simpler inputs? And what do such responses reveal about the learning process? To answer these questions, we need a clear measure of input simplicity (or inversely, complexity), an optimization objective that correlates with simplification, and a framework to incorporate such objective into training and inference. Lastly we need a variety of testbeds to experiment and evaluate the impact of such simplification on learning. In this work, we measure simplicity with the encoding bit size given by a pretrained generative model, and minimize the bit size to simplify inputs in training and inference. We investigate the effect of such simplification in several scenarios: conventional training, dataset condensation and post-hoc explanations. In all settings, inputs are simplified along with the original classification task, and we investigate the trade-off between input simplicity and task performance. For images with injected distractors, such simplification naturally removes superfluous information. For dataset condensation, we find that inputs can be simplified with almost no accuracy degradation. When used in post-hoc explanation, our learning-based simplification approach offers a valuable new tool to explore the basis of network decisions.
Reusing Discriminators for Encoding: Towards Unsupervised Image-to-Image Translation
Mar 06, 2020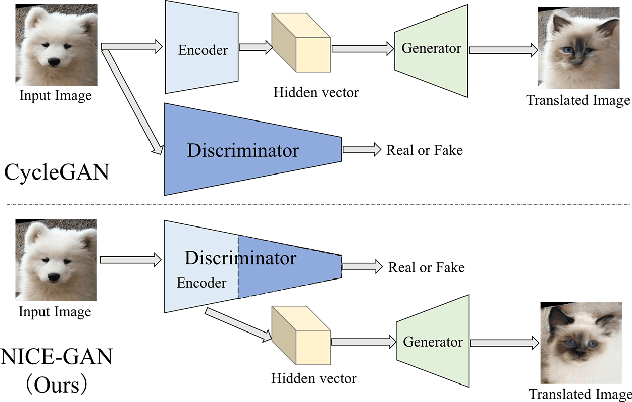
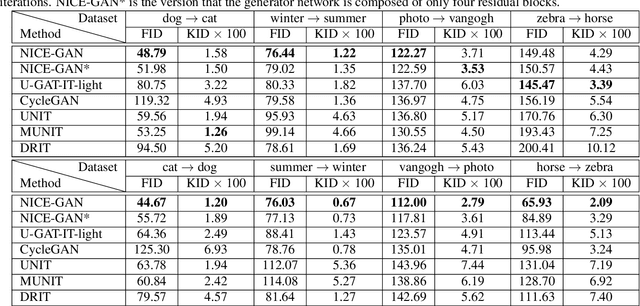
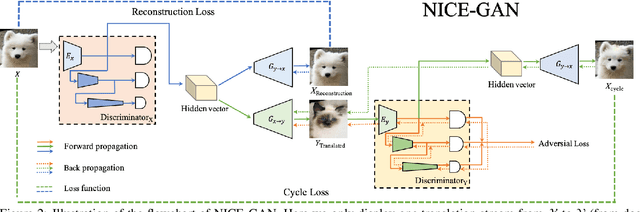
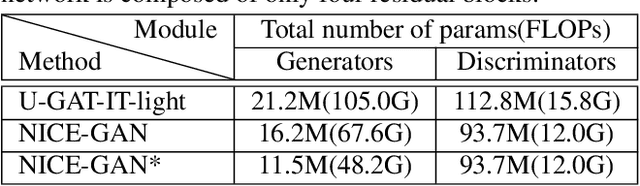
Unsupervised image-to-image translation is a central task in computer vision. Current translation frameworks will abandon the discriminator once the training process is completed. This paper contends a novel role of the discriminator by reusing it for encoding the images of the target domain. The proposed architecture, termed as NICE-GAN, exhibits two advantageous patterns over previous approaches: First, it is more compact since no independent encoding component is required; Second, this plug-in encoder is directly trained by the adversary loss, making it more informative and trained more effectively if a multi-scale discriminator is applied. The main issue in NICE-GAN is the coupling of translation with discrimination along the encoder, which could incur training inconsistency when we play the min-max game via GAN. To tackle this issue, we develop a decoupled training strategy by which the encoder is only trained when maximizing the adversary loss while keeping frozen otherwise. Extensive experiments on four popular benchmarks demonstrate the superior performance of NICE-GAN over state-of-the-art methods in terms of FID, KID, and also human preference. Comprehensive ablation studies are also carried out to isolate the validity of each proposed component. Our codes are available at https://github.com/alpc91/NICE-GAN-pytorch.
MDCN: Multi-scale Dense Cross Network for Image Super-Resolution
Aug 30, 2020
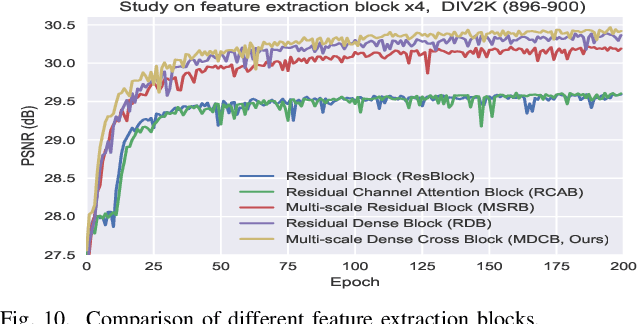
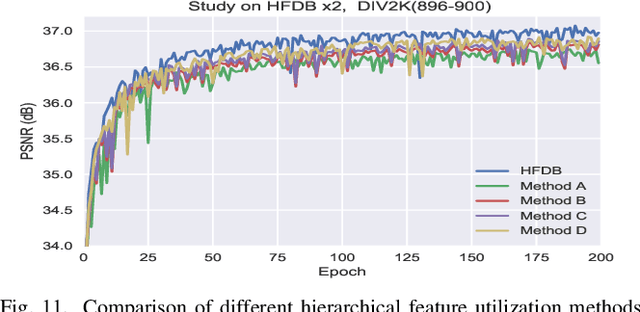

Convolutional neural networks have been proven to be of great benefit for single-image super-resolution (SISR). However, previous works do not make full use of multi-scale features and ignore the inter-scale correlation between different upsampling factors, resulting in sub-optimal performance. Instead of blindly increasing the depth of the network, we are committed to mining image features and learning the inter-scale correlation between different upsampling factors. To achieve this, we propose a Multi-scale Dense Cross Network (MDCN), which achieves great performance with fewer parameters and less execution time. MDCN consists of multi-scale dense cross blocks (MDCBs), hierarchical feature distillation block (HFDB), and dynamic reconstruction block (DRB). Among them, MDCB aims to detect multi-scale features and maximize the use of image features flow at different scales, HFDB focuses on adaptively recalibrate channel-wise feature responses to achieve feature distillation, and DRB attempts to reconstruct SR images with different upsampling factors in a single model. It is worth noting that all these modules can run independently. It means that these modules can be selectively plugged into any CNN model to improve model performance. Extensive experiments show that MDCN achieves competitive results in SISR, especially in the reconstruction task with multiple upsampling factors. The code will be provided at https://github.com/MIVRC/MDCN-PyTorch.
Finding the Task-Optimal Low-Bit Sub-Distribution in Deep Neural Networks
Jan 13, 2022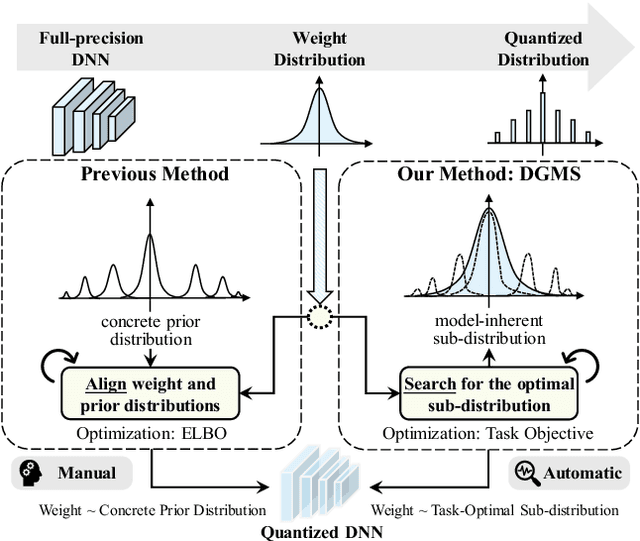
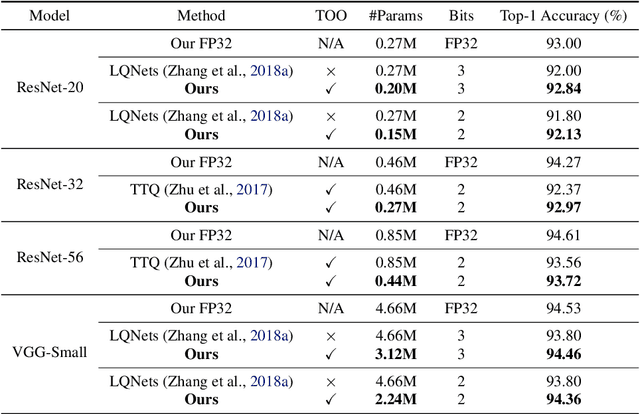
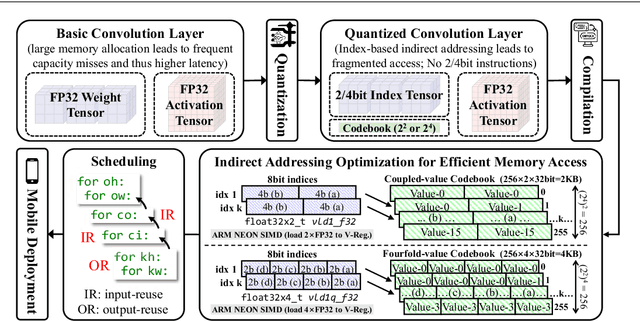
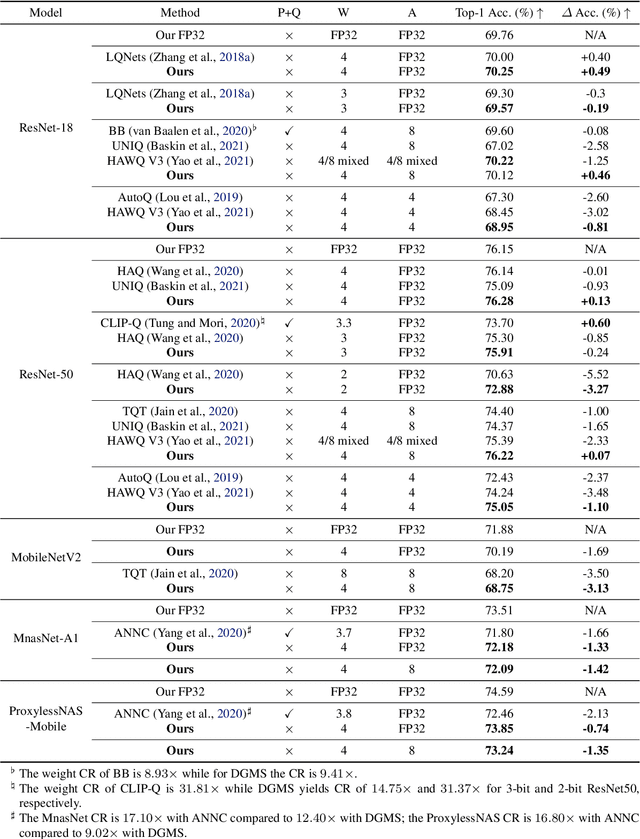
Quantized neural networks typically require smaller memory footprints and lower computation complexity, which is crucial for efficient deployment. However, quantization inevitably leads to a distribution divergence from the original network, which generally degrades the performance. To tackle this issue, massive efforts have been made, but most existing approaches lack statistical considerations and depend on several manual configurations. In this paper, we present an adaptive-mapping quantization method to learn an optimal latent sub-distribution that is inherent within models and smoothly approximated with a concrete Gaussian Mixture (GM). In particular, the network weights are projected in compliance with the GM-approximated sub-distribution. This sub-distribution evolves along with the weight update in a co-tuning schema guided by the direct task-objective optimization. Sufficient experiments on image classification and object detection over various modern architectures demonstrate the effectiveness, generalization property, and transferability of the proposed method. Besides, an efficient deployment flow for the mobile CPU is developed, achieving up to 7.46$\times$ inference acceleration on an octa-core ARM CPU. Codes have been publicly released on Github (https://github.com/RunpeiDong/DGMS).
Depth image denoising using nuclear norm and learning graph model
Aug 09, 2020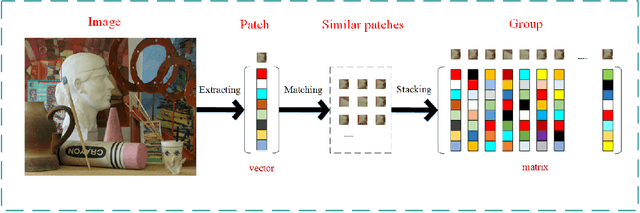
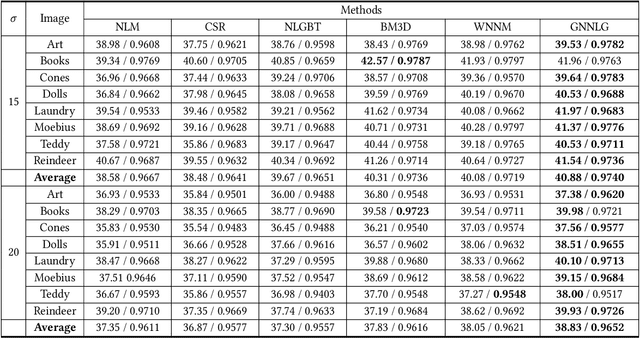
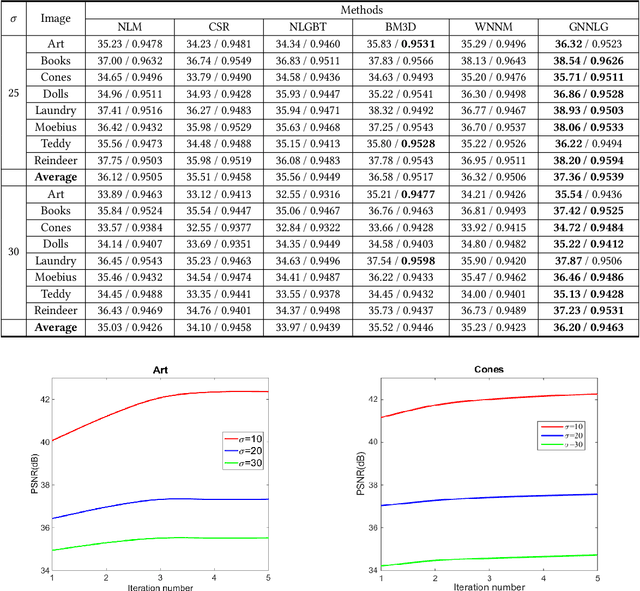
The depth images denoising are increasingly becoming the hot research topic nowadays because they reflect the three-dimensional (3D) scene and can be applied in various fields of computer vision. But the depth images obtained from depth camera usually contain stains such as noise, which greatly impairs the performance of depth related applications. In this paper, considering that group-based image restoration methods are more effective in gathering the similarity among patches, a group based nuclear norm and learning graph (GNNLG) model was proposed. For each patch, we find and group the most similar patches within a searching window. The intrinsic low-rank property of the grouped patches is exploited in our model. In addition, we studied the manifold learning method and devised an effective optimized learning strategy to obtain the graph Laplacian matrix, which reflects the topological structure of image, to further impose the smoothing priors to the denoised depth image. To achieve fast speed and high convergence, the alternating direction method of multipliers (ADMM) is proposed to solve our GNNLG. The experimental results show that the proposed method is superior to other current state-of-the-art denoising methods in both subjective and objective criterion.