 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen less is more: Simplifying inputs aids neural network understanding
Paper and Code
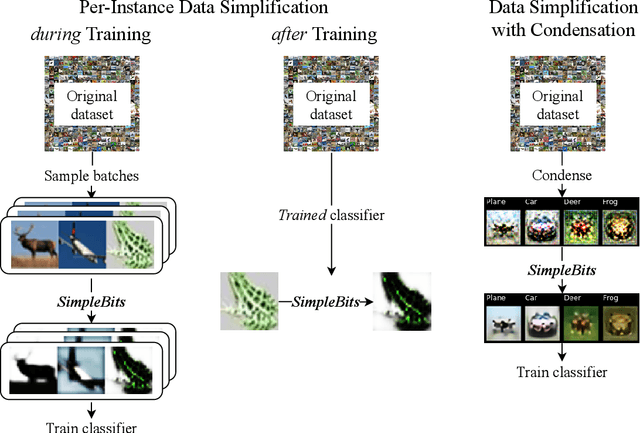

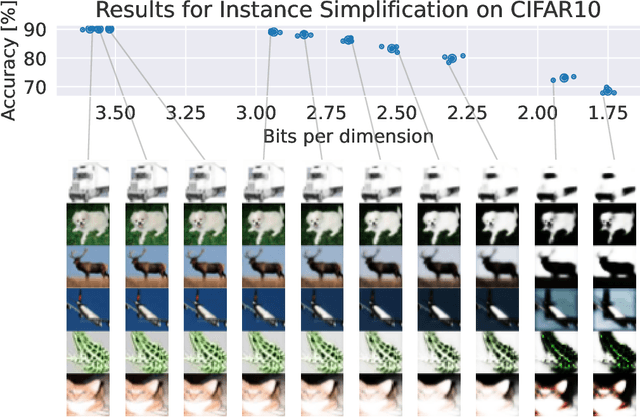
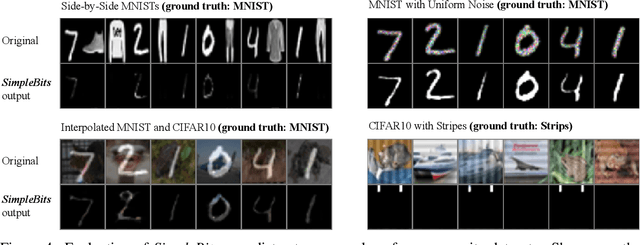
How do neural network image classifiers respond to simpler and simpler inputs? And what do such responses reveal about the learning process? To answer these questions, we need a clear measure of input simplicity (or inversely, complexity), an optimization objective that correlates with simplification, and a framework to incorporate such objective into training and inference. Lastly we need a variety of testbeds to experiment and evaluate the impact of such simplification on learning. In this work, we measure simplicity with the encoding bit size given by a pretrained generative model, and minimize the bit size to simplify inputs in training and inference. We investigate the effect of such simplification in several scenarios: conventional training, dataset condensation and post-hoc explanations. In all settings, inputs are simplified along with the original classification task, and we investigate the trade-off between input simplicity and task performance. For images with injected distractors, such simplification naturally removes superfluous information. For dataset condensation, we find that inputs can be simplified with almost no accuracy degradation. When used in post-hoc explanation, our learning-based simplification approach offers a valuable new tool to explore the basis of network decisions.