 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Semantic Similarity Computing Model Based on Multi Model Fine-Grained Nonlinear Fusion
Feb 05, 2022
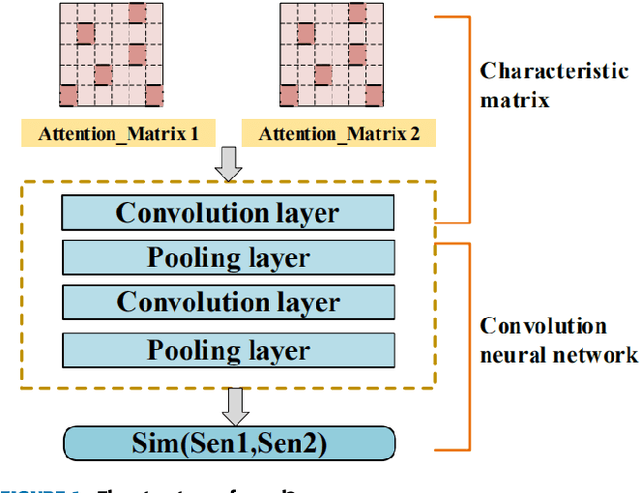

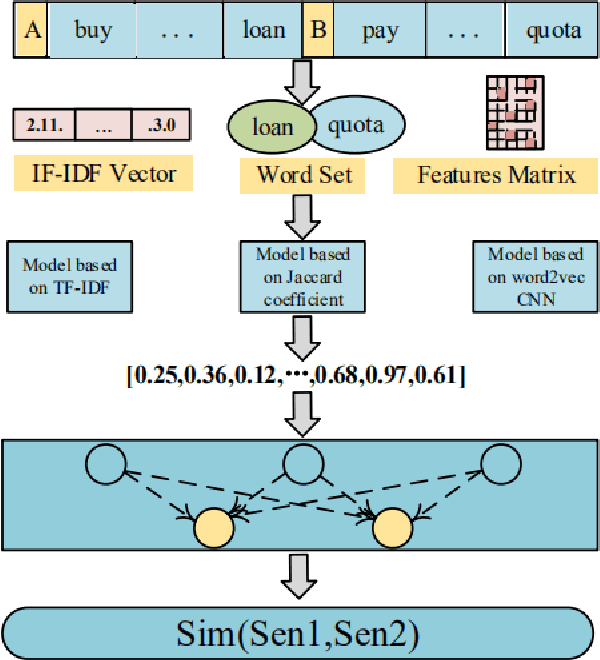
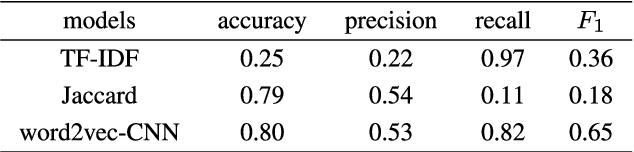
Natural language processing (NLP) task has achieved excellent performance in many fields, including semantic understanding, automatic summarization, image recognition and so on. However, most of the neural network models for NLP extract the text in a fine-grained way, which is not conducive to grasp the meaning of the text from a global perspective. To alleviate the problem, the combination of the traditional statistical method and deep learning model as well as a novel model based on multi model nonlinear fusion are proposed in this paper. The model uses the Jaccard coefficient based on part of speech, Term Frequency-Inverse Document Frequency (TF-IDF) and word2vec-CNN algorithm to measure the similarity of sentences respectively. According to the calculation accuracy of each model, the normalized weight coefficient is obtained and the calculation results are compared. The weighted vector is input into the fully connected neural network to give the final classification results. As a result, the statistical sentence similarity evaluation algorithm reduces the granularity of feature extraction, so it can grasp the sentence features globally. Experimental results show that the matching of sentence similarity calculation method based on multi model nonlinear fusion is 84%, and the F1 value of the model is 75%.
Total-Body Low-Dose CT Image Denoising using Prior Knowledge Transfer Technique with Contrastive Regularization Mechanism
Dec 01, 2021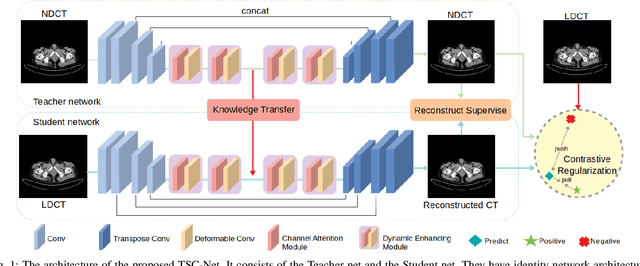
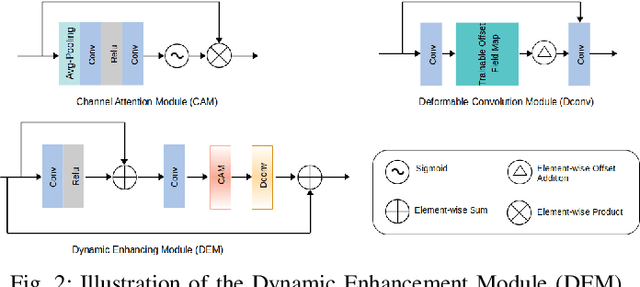

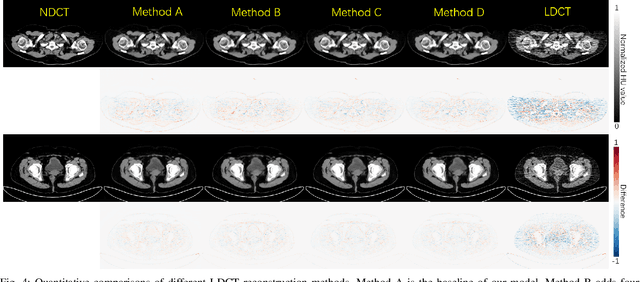
Reducing the radiation exposure for patients in Total-body CT scans has attracted extensive attention in the medical imaging community. Given the fact that low radiation dose may result in increased noise and artifacts, which greatly affected the clinical diagnosis. To obtain high-quality Total-body Low-dose CT (LDCT) images, previous deep-learning-based research work has introduced various network architectures. However, most of these methods only adopt Normal-dose CT (NDCT) images as ground truths to guide the training of the denoising network. Such simple restriction leads the model to less effectiveness and makes the reconstructed images suffer from over-smoothing effects. In this paper, we propose a novel intra-task knowledge transfer method that leverages the distilled knowledge from NDCT images to assist the training process on LDCT images. The derived architecture is referred to as the Teacher-Student Consistency Network (TSC-Net), which consists of the teacher network and the student network with identical architecture. Through the supervision between intermediate features, the student network is encouraged to imitate the teacher network and gain abundant texture details. Moreover, to further exploit the information contained in CT scans, a contrastive regularization mechanism (CRM) built upon contrastive learning is introduced.CRM performs to pull the restored CT images closer to the NDCT samples and push far away from the LDCT samples in the latent space. In addition, based on the attention and deformable convolution mechanism, we design a Dynamic Enhancement Module (DEM) to improve the network transformation capability.
Learning Transformation-Aware Embeddings for Image Forensics
Jan 13, 2020
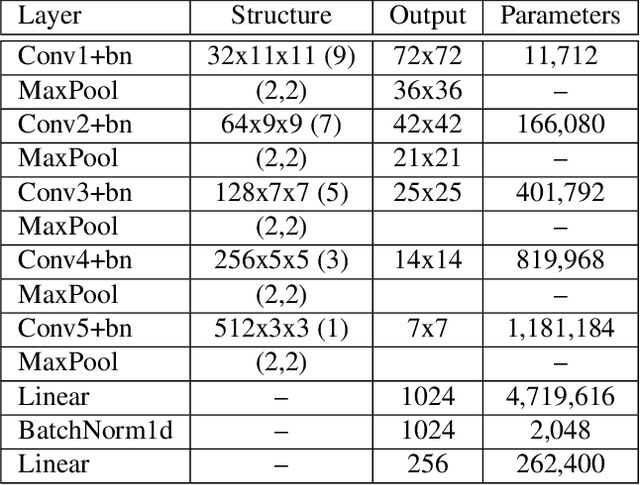

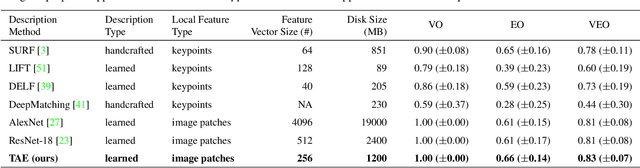
A dramatic rise in the flow of manipulated image content on the Internet has led to an aggressive response from the media forensics research community. New efforts have incorporated increased usage of techniques from computer vision and machine learning to detect and profile the space of image manipulations. This paper addresses Image Provenance Analysis, which aims at discovering relationships among different manipulated image versions that share content. One of the main sub-problems for provenance analysis that has not yet been addressed directly is the edit ordering of images that share full content or are near-duplicates. The existing large networks that generate image descriptors for tasks such as object recognition may not encode the subtle differences between these image covariates. This paper introduces a novel deep learning-based approach to provide a plausible ordering to images that have been generated from a single image through transformations. Our approach learns transformation-aware descriptors using weak supervision via composited transformations and a rank-based quadruplet loss. To establish the efficacy of the proposed approach, comparisons with state-of-the-art handcrafted and deep learning-based descriptors, and image matching approaches are made. Further experimentation validates the proposed approach in the context of image provenance analysis.
Improving Learning-to-Defer Algorithms Through Fine-Tuning
Dec 18, 2021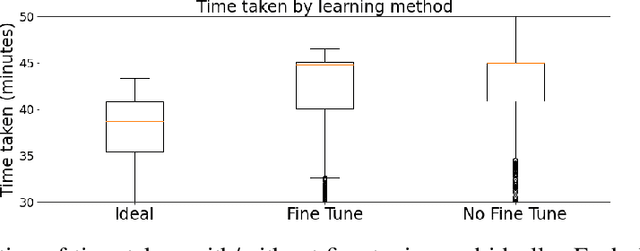
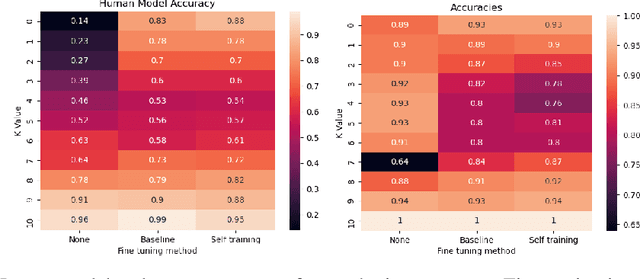
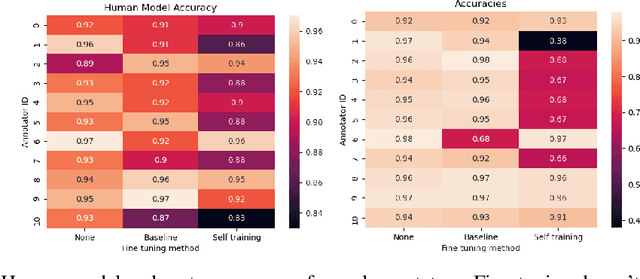
The ubiquity of AI leads to situations where humans and AI work together, creating the need for learning-to-defer algorithms that determine how to partition tasks between AI and humans. We work to improve learning-to-defer algorithms when paired with specific individuals by incorporating two fine-tuning algorithms and testing their efficacy using both synthetic and image datasets. We find that fine-tuning can pick up on simple human skill patterns, but struggles with nuance, and we suggest future work that uses robust semi-supervised to improve learning.
Multi-modal Aggregation Network for Fast MR Imaging
Oct 20, 2021
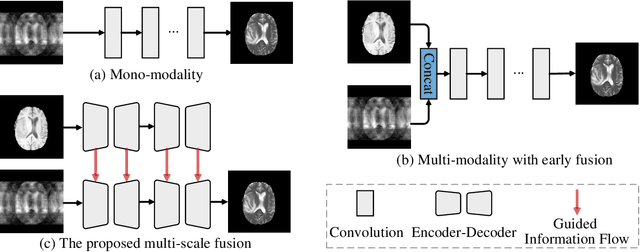
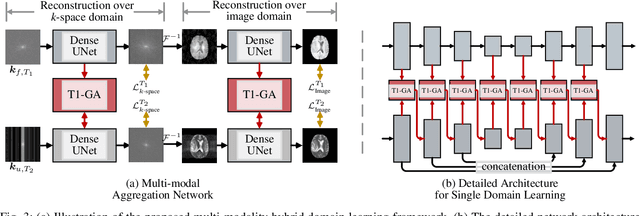
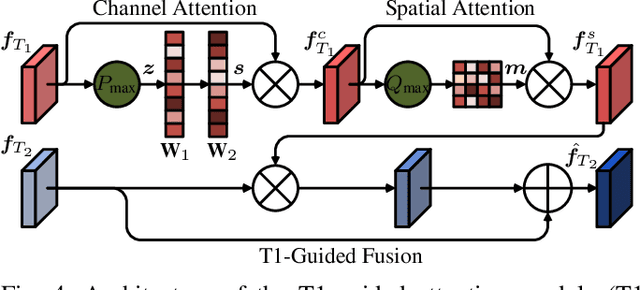
Magnetic resonance (MR) imaging is a commonly used scanning technique for disease detection, diagnosis and treatment monitoring. Although it is able to produce detailed images of organs and tissues with better contrast, it suffers from a long acquisition time, which makes the image quality vulnerable to say motion artifacts. Recently, many approaches have been developed to reconstruct full-sampled images from partially observed measurements in order to accelerate MR imaging. However, most of these efforts focus on reconstruction over a single modality or simple fusion of multiple modalities, neglecting the discovery of correlation knowledge at different feature level. In this work, we propose a novel Multi-modal Aggregation Network, named MANet, which is capable of discovering complementary representations from a fully sampled auxiliary modality, with which to hierarchically guide the reconstruction of a given target modality. In our MANet, the representations from the fully sampled auxiliary and undersampled target modalities are learned independently through a specific network. Then, a guided attention module is introduced in each convolutional stage to selectively aggregate multi-modal features for better reconstruction, yielding comprehensive, multi-scale, multi-modal feature fusion. Moreover, our MANet follows a hybrid domain learning framework, which allows it to simultaneously recover the frequency signal in the $k$-space domain as well as restore the image details from the image domain. Extensive experiments demonstrate the superiority of the proposed approach over state-of-the-art MR image reconstruction methods.
Predicting 4D Liver MRI for MR-guided Interventions
Feb 25, 2022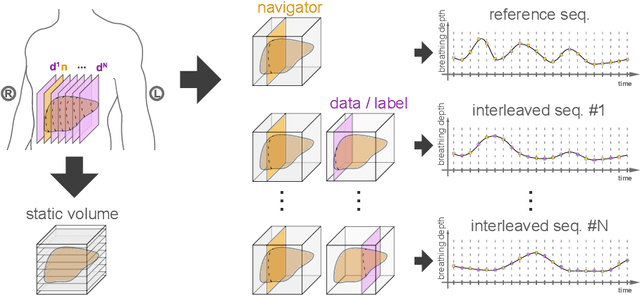


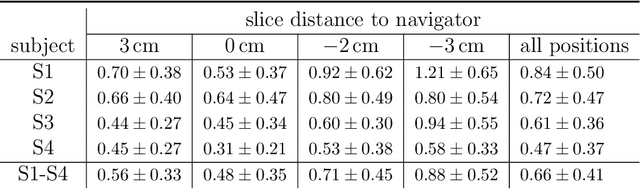
Organ motion poses an unresolved challenge in image-guided interventions. In the pursuit of solving this problem, the research field of time-resolved volumetric magnetic resonance imaging (4D MRI) has evolved. However, current techniques are unsuitable for most interventional settings because they lack sufficient temporal and/or spatial resolution or have long acquisition times. In this work, we propose a novel approach for real-time, high-resolution 4D MRI with large fields of view for MR-guided interventions. To this end, we trained a convolutional neural network (CNN) end-to-end to predict a 3D liver MRI that correctly predicts the liver's respiratory state from a live 2D navigator MRI of a subject. Our method can be used in two ways: First, it can reconstruct near real-time 4D MRI with high quality and high resolution (209x128x128 matrix size with isotropic 1.8mm voxel size and 0.6s/volume) given a dynamic interventional 2D navigator slice for guidance during an intervention. Second, it can be used for retrospective 4D reconstruction with a temporal resolution of below 0.2s/volume for motion analysis and use in radiation therapy. We report a mean target registration error (TRE) of 1.19 $\pm$0.74mm, which is below voxel size. We compare our results with a state-of-the-art retrospective 4D MRI reconstruction. Visual evaluation shows comparable quality. We show that small training sizes with short acquisition times down to 2min can already achieve promising results and 24min are sufficient for high quality results. Because our method can be readily combined with earlier methods, acquisition time can be further decreased while also limiting quality loss. We show that an end-to-end, deep learning formulation is highly promising for 4D MRI reconstruction.
Splatting-based Synthesis for Video Frame Interpolation
Jan 25, 2022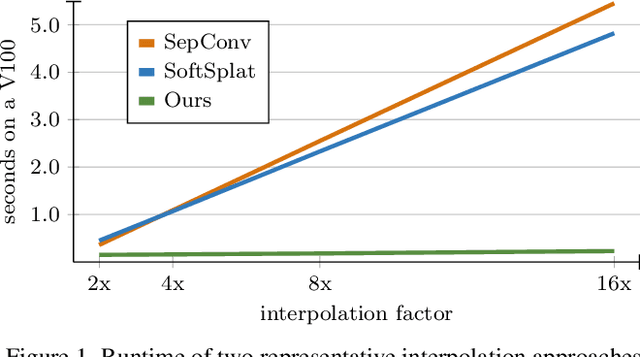


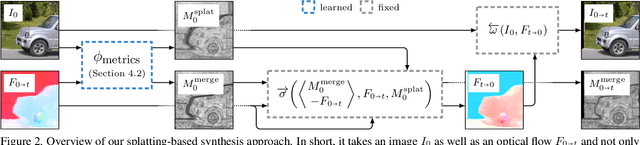
Frame interpolation is an essential video processing technique that adjusts the temporal resolution of an image sequence. An effective approach to perform frame interpolation is based on splatting, also known as forward warping. Specifically, splatting can be used to warp the input images to an arbitrary temporal location based on an optical flow estimate. A synthesis network, also sometimes referred to as refinement network, can then be used to generate the output frame from the warped images. In doing so, it is common to not only warp the images but also various feature representations which provide rich contextual cues to the synthesis network. However, while this approach has been shown to work well and enables arbitrary-time interpolation due to using splatting, the involved synthesis network is prohibitively slow. In contrast, we propose to solely rely on splatting to synthesize the output without any subsequent refinement. This splatting-based synthesis is much faster than similar approaches, especially for multi-frame interpolation, while enabling new state-of-the-art results at high resolutions.
Performance characterization of a novel deep learning-based MR image reconstruction pipeline
Aug 14, 2020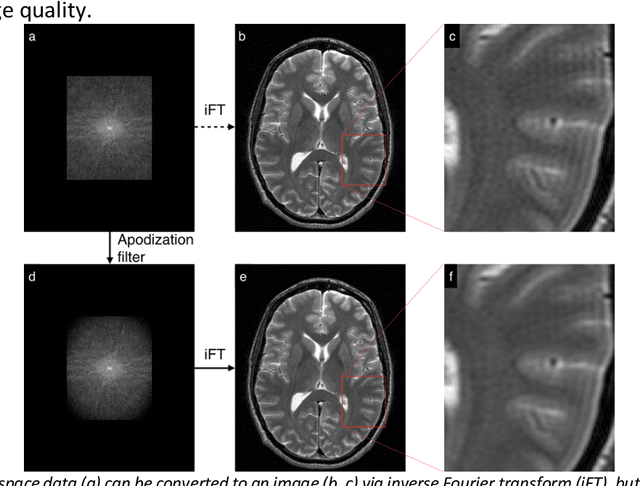
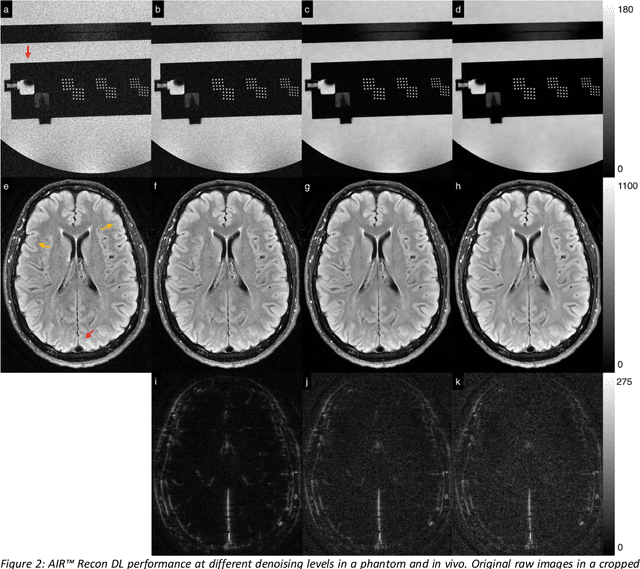
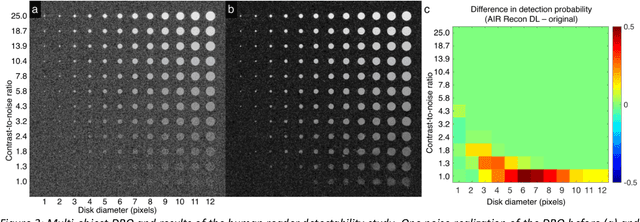
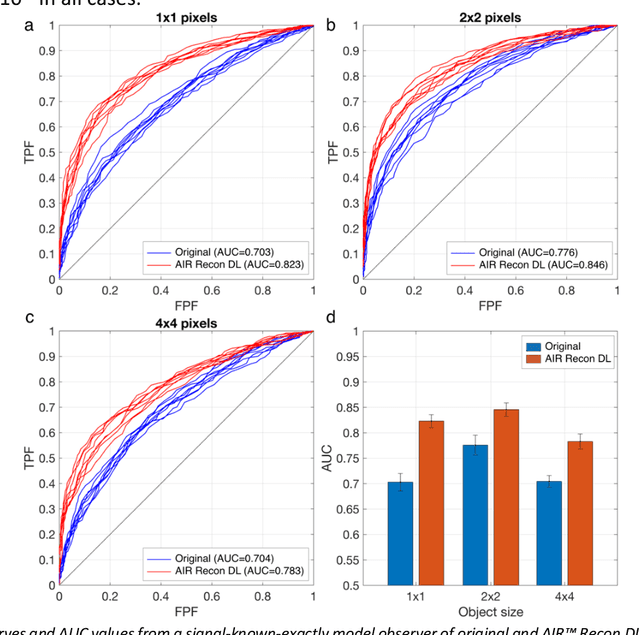
A novel deep learning-based magnetic resonance imaging reconstruction pipeline was designed to address fundamental image quality limitations of conventional reconstruction to provide high-resolution, low-noise MR images. This pipeline's unique aims were to convert truncation artifact into improved image sharpness while jointly denoising images to improve image quality. This new approach, now commercially available at AIR Recon DL (GE Healthcare, Waukesha, WI), includes a deep convolutional neural network (CNN) to aid in the reconstruction of raw data, ultimately producing clean, sharp images. Here we describe key features of this pipeline and its CNN, characterize its performance in digital reference objects, phantoms, and in-vivo, and present sample images and protocol optimization strategies that leverage image quality improvement for reduced scan time. This new deep learning-based reconstruction pipeline represents a powerful new tool to increase the diagnostic and operational performance of an MRI scanner.
Strategies for Robust Image Classification
Mar 26, 2020
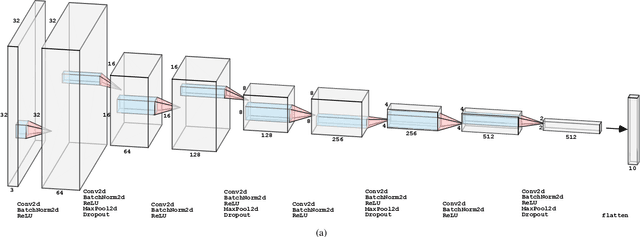

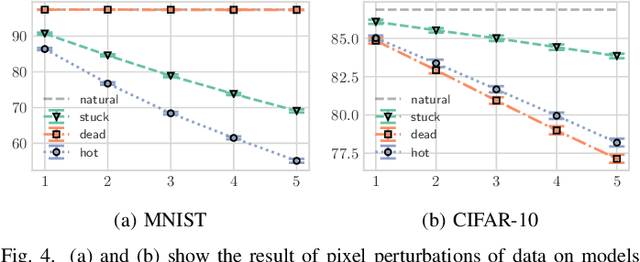
In this work we evaluate the impact of digitally altered images on the performance of artificial neural networks. We explore factors that negatively affect the ability of an image classification model to produce consistent and accurate results. A model's ability to classify is negatively influenced by alterations to images as a result of digital abnormalities or changes in the physical environment. The focus of this paper is to discover and replicate scenarios that modify the appearance of an image and evaluate them on state-of-the-art machine learning models. Our contributions present various training techniques that enhance a model's ability to generalize and improve robustness against these alterations.
AttentionGAN: Unpaired Image-to-Image Translation using Attention-Guided Generative Adversarial Networks
Dec 10, 2019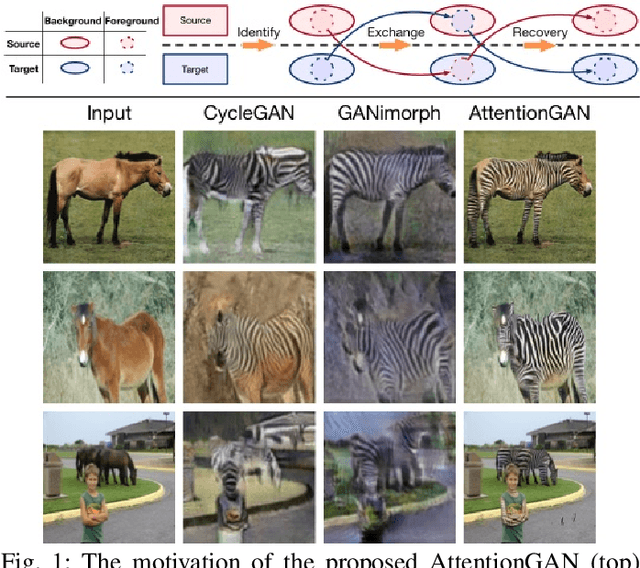



State-of-the-art methods in the unpaired image-to-image translation are capable of learning a mapping from a source domain to a target domain with unpaired image data. Though the existing methods have achieved promising results, they still produce unsatisfied artifacts, being able to convert low-level information while limited in transforming high-level semantics of input images. One possible reason is that generators do not have the ability to perceive the most discriminative semantic parts between the source and target domains, thus making the generated images low quality. In this paper, we propose a new Attention-Guided Generative Adversarial Networks (AttentionGAN) for the unpaired image-to-image translation task. AttentionGAN can identify the most discriminative semantic objects and minimize changes of unwanted parts for semantic manipulation problems without using extra data and models. The attention-guided generators in AttentionGAN are able to produce attention masks via a built-in attention mechanism, and then fuse the generation output with the attention masks to obtain high-quality target images. Accordingly, we also design a novel attention-guided discriminator which only considers attended regions. Extensive experiments are conducted on several generative tasks, demonstrating that the proposed model is effective to generate sharper and more realistic images compared with existing competitive models. The source code for the proposed AttentionGAN is available at https://github.com/Ha0Tang/AttentionGAN.