 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttentionGAN: Unpaired Image-to-Image Translation using Attention-Guided Generative Adversarial Networks
Paper and Code
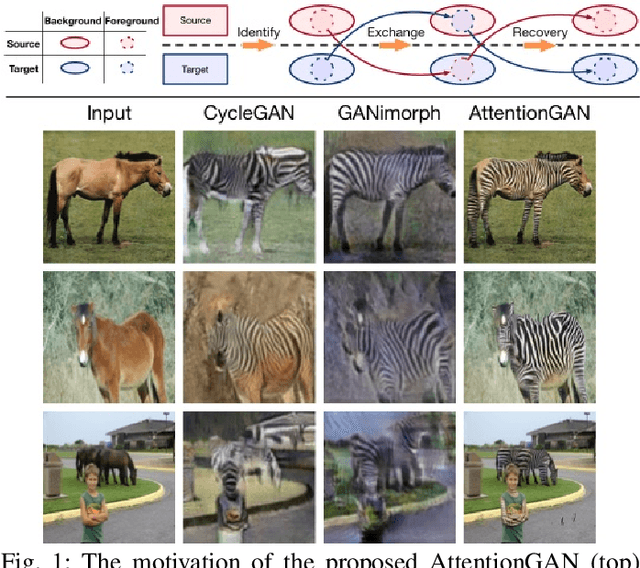



State-of-the-art methods in the unpaired image-to-image translation are capable of learning a mapping from a source domain to a target domain with unpaired image data. Though the existing methods have achieved promising results, they still produce unsatisfied artifacts, being able to convert low-level information while limited in transforming high-level semantics of input images. One possible reason is that generators do not have the ability to perceive the most discriminative semantic parts between the source and target domains, thus making the generated images low quality. In this paper, we propose a new Attention-Guided Generative Adversarial Networks (AttentionGAN) for the unpaired image-to-image translation task. AttentionGAN can identify the most discriminative semantic objects and minimize changes of unwanted parts for semantic manipulation problems without using extra data and models. The attention-guided generators in AttentionGAN are able to produce attention masks via a built-in attention mechanism, and then fuse the generation output with the attention masks to obtain high-quality target images. Accordingly, we also design a novel attention-guided discriminator which only considers attended regions. Extensive experiments are conducted on several generative tasks, demonstrating that the proposed model is effective to generate sharper and more realistic images compared with existing competitive models. The source code for the proposed AttentionGAN is available at https://github.com/Ha0Tang/AttentionGAN.