 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Adorym: A multi-platform generic x-ray image reconstruction framework based on automatic differentiation
Dec 22, 2020
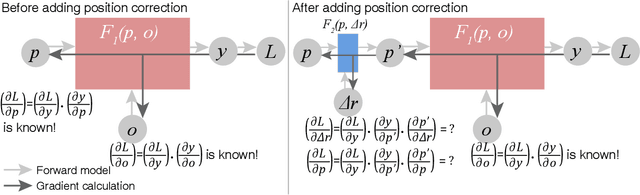
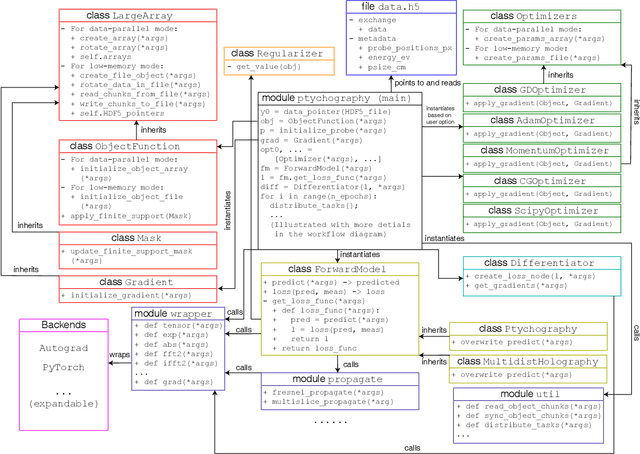

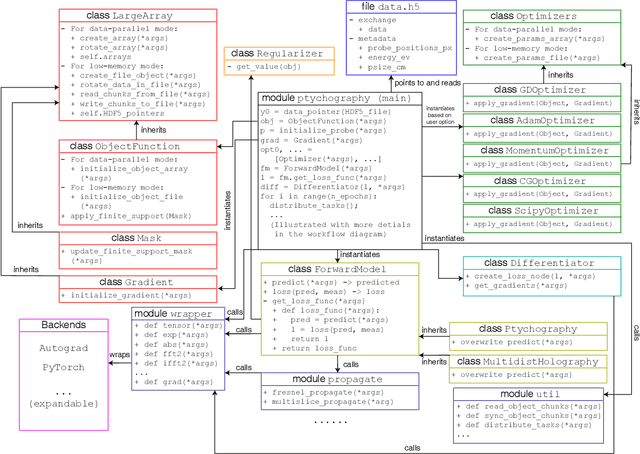
We describe and demonstrate an optimization-based x-ray image reconstruction framework called Adorym. Our framework provides a generic forward model, allowing one code framework to be used for a wide range of imaging methods ranging from near-field holography to and fly-scan ptychographic tomography. By using automatic differentiation for optimization, Adorym has the flexibility to refine experimental parameters including probe positions, multiple hologram alignment, and object tilts. It is written with strong support for parallel processing, allowing large datasets to be processed on high-performance computing systems. We demonstrate its use on several experimental datasets to show improved image quality through parameter refinement.
Discriminability-enforcing loss to improve representation learning
Feb 14, 2022
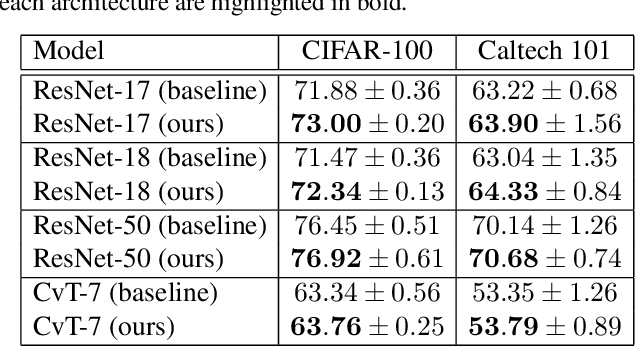
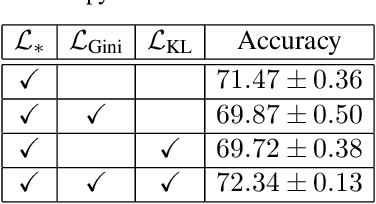
During the training process, deep neural networks implicitly learn to represent the input data samples through a hierarchy of features, where the size of the hierarchy is determined by the number of layers. In this paper, we focus on enforcing the discriminative power of the high-level representations, that are typically learned by the deeper layers (closer to the output). To this end, we introduce a new loss term inspired by the Gini impurity, which is aimed at minimizing the entropy (increasing the discriminative power) of individual high-level features with respect to the class labels. Although our Gini loss induces highly-discriminative features, it does not ensure that the distribution of the high-level features matches the distribution of the classes. As such, we introduce another loss term to minimize the Kullback-Leibler divergence between the two distributions. We conduct experiments on two image classification data sets (CIFAR-100 and Caltech 101), considering multiple neural architectures ranging from convolutional networks (ResNet-17, ResNet-18, ResNet-50) to transformers (CvT). Our empirical results show that integrating our novel loss terms into the training objective consistently outperforms the models trained with cross-entropy alone.
Voxelmorph++ Going beyond the cranial vault with keypoint supervision and multi-channel instance optimisation
Feb 28, 2022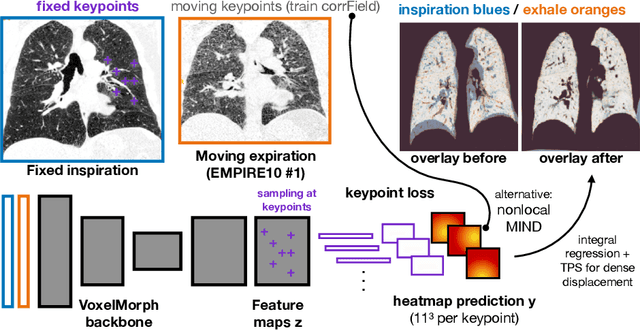
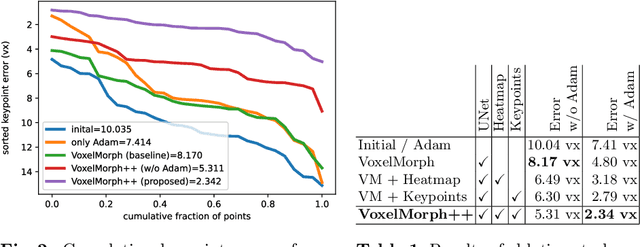
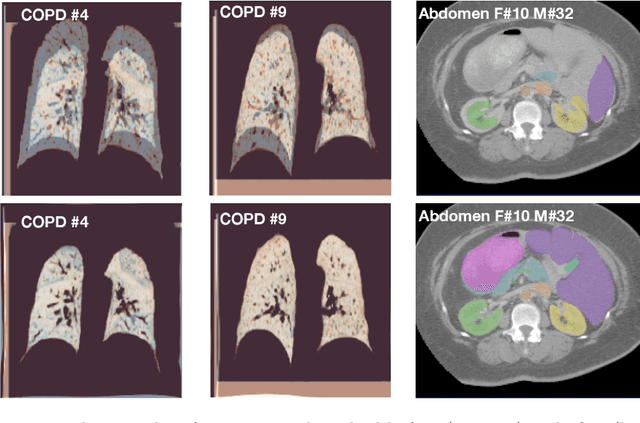
The majority of current research in deep learning based image registration addresses inter-patient brain registration with moderate deformation magnitudes. The recent Learn2Reg medical registration benchmark has demonstrated that single-scale U-Net architectures, such as VoxelMorph that directly employ a spatial transformer loss, often do not generalise well beyond the cranial vault and fall short of state-of-the-art performance for abdominal or intra-patient lung registration. Here, we propose two straightforward steps that greatly reduce this gap in accuracy. First, we employ keypoint self-supervision with a novel network head that predicts a discretised heatmap and robustly reduces large deformations for better robustness. Second, we replace multiple learned fine-tuning steps by a single instance optimisation with hand-crafted features and the Adam optimiser. Different to other related work, including FlowNet or PDD-Net, our approach does not require a fully discretised architecture with correlation layer. Our ablation study demonstrates the importance of keypoints in both self-supervised and unsupervised (using only a MIND metric) settings. On a multi-centric inspiration-exhale lung CT dataset, including very challenging COPD scans, our method outperforms VoxelMorph by improving nonlinear alignment by 77% compared to 19% - reaching target registration errors of 2 mm that outperform all but one learning methods published to date. Extending the method to semantic features sets new stat-of-the-art performance on inter-subject abdominal CT registration.
Learning Multi-Object Dynamics with Compositional Neural Radiance Fields
Mar 04, 2022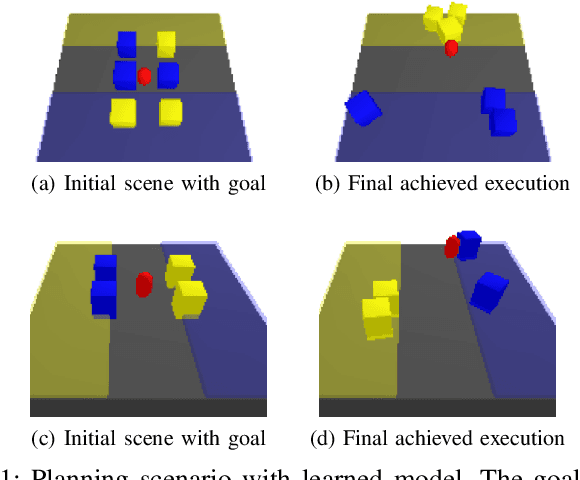
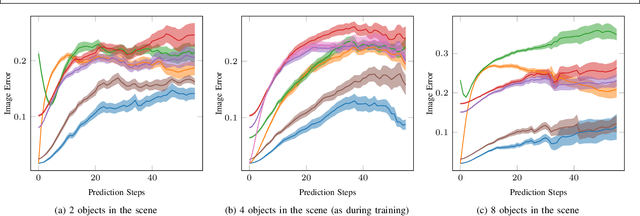
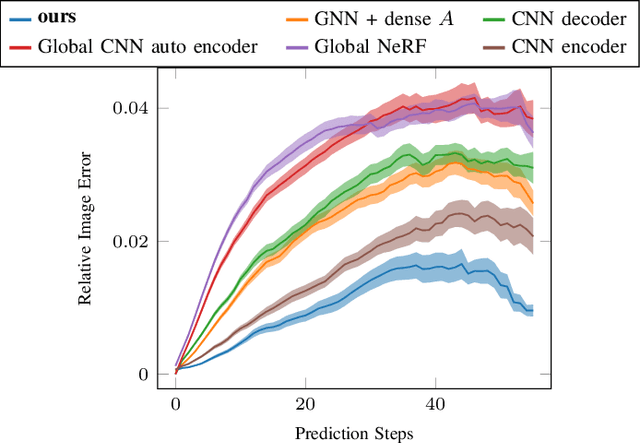
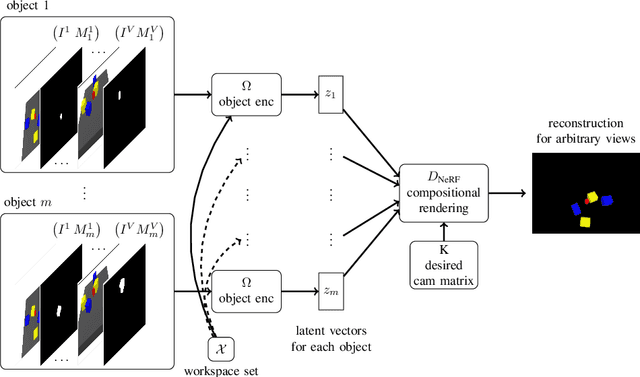
We present a method to learn compositional predictive models from image observations based on implicit object encoders, Neural Radiance Fields (NeRFs), and graph neural networks. A central question in learning dynamic models from sensor observations is on which representations predictions should be performed. NeRFs have become a popular choice for representing scenes due to their strong 3D prior. However, most NeRF approaches are trained on a single scene, representing the whole scene with a global model, making generalization to novel scenes, containing different numbers of objects, challenging. Instead, we present a compositional, object-centric auto-encoder framework that maps multiple views of the scene to a \emph{set} of latent vectors representing each object separately. The latent vectors parameterize individual NeRF models from which the scene can be reconstructed and rendered from novel viewpoints. We train a graph neural network dynamics model in the latent space to achieve compositionality for dynamics prediction. A key feature of our approach is that the learned 3D information of the scene through the NeRF model enables us to incorporate structural priors in learning the dynamics models, making long-term predictions more stable. The model can further be used to synthesize new scenes from individual object observations. For planning, we utilize RRTs in the learned latent space, where we can exploit our model and the implicit object encoder to make sampling the latent space informative and more efficient. In the experiments, we show that the model outperforms several baselines on a pushing task containing many objects. Video: https://dannydriess.github.io/compnerfdyn/
Modeling Lost Information in Lossy Image Compression
Jun 23, 2020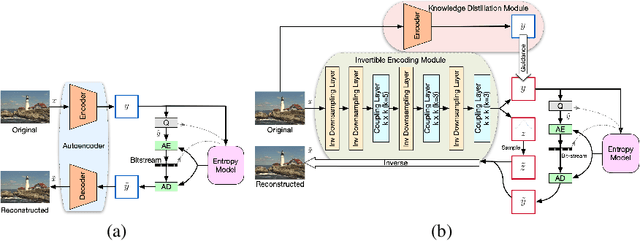
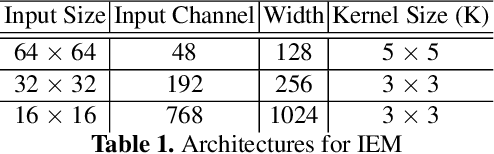

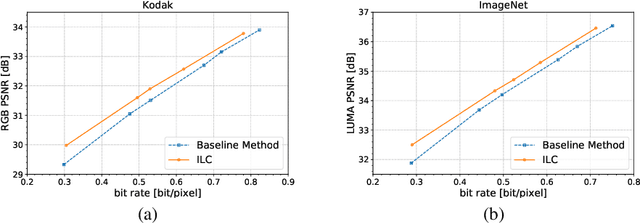
Lossy image compression is one of the most commonly used operators for digital images. Most recently proposed deep-learning-based image compression methods leverage the auto-encoder structure, and reach a series of promising results in this field. The images are encoded into low dimensional latent features first, and entropy coded subsequently by exploiting the statistical redundancy. However, the information lost during encoding is unfortunately inevitable, which poses a significant challenge to the decoder to reconstruct the original images. In this work, we propose a novel invertible framework called Invertible Lossy Compression (ILC) to largely mitigate the information loss problem. Specifically, ILC introduces an invertible encoding module to replace the encoder-decoder structure to produce the low dimensional informative latent representation, meanwhile, transform the lost information into an auxiliary latent variable that won't be further coded or stored. The latent representation is quantized and encoded into bit-stream, and the latent variable is forced to follow a specified distribution, i.e. isotropic Gaussian distribution. In this way, recovering the original image is made tractable by easily drawing a surrogate latent variable and applying the inverse pass of the module with the sampled variable and decoded latent features. Experimental results demonstrate that with a new component replacing the auto-encoder in image compression methods, ILC can significantly outperform the baseline method on extensive benchmark datasets by combining with the existing compression algorithms.
Mining Cross-Image Semantics for Weakly Supervised Semantic Segmentation
Jul 03, 2020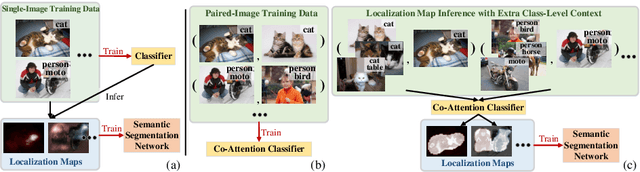
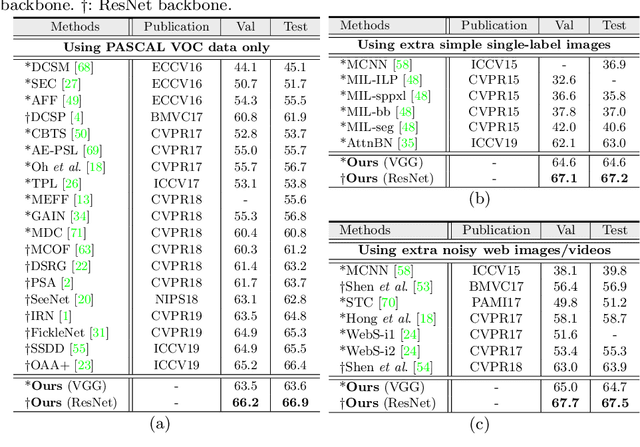
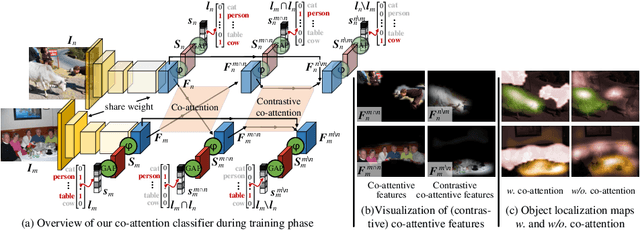
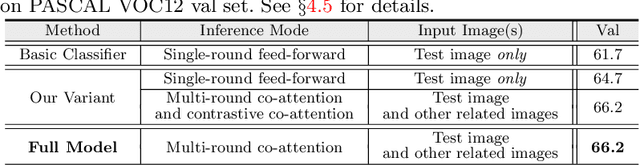
This paper studies the problem of learning semantic segmentation from image-level supervision only. Current popular solutions leverage object localization maps from classifiers as supervision signals, and struggle to make the localization maps capture more complete object content. Rather than previous efforts that primarily focus on intra-image information, we address the value of cross-image semantic relations for comprehensive object pattern mining. To achieve this, two neural co-attentions are incorporated into the classifier to complimentarily capture cross-image semantic similarities and differences. In particular, given a pair of training images, one co-attention enforces the classifier to recognize the common semantics from co-attentive objects, while the other one, called contrastive co-attention, drives the classifier to identify the unshared semantics from the rest, uncommon objects. This helps the classifier discover more object patterns and better ground semantics in image regions. In addition to boosting object pattern learning, the co-attention can leverage context from other related images to improve localization map inference, hence eventually benefiting semantic segmentation learning. More essentially, our algorithm provides a unified framework that handles well different WSSS settings, i.e., learning WSSS with (1) precise image-level supervision only, (2) extra simple single-label data, and (3) extra noisy web data. It sets new state-of-the-arts on all these settings, demonstrating well its efficacy and generalizability. Moreover, our approach ranked 1st place in the Weakly-Supervised Semantic Segmentation Track of CVPR2020 Learning from Imperfect Data Challenge.
DDR-ID: Dual Deep Reconstruction Networks Based Image Decomposition for Anomaly Detection
Jul 18, 2020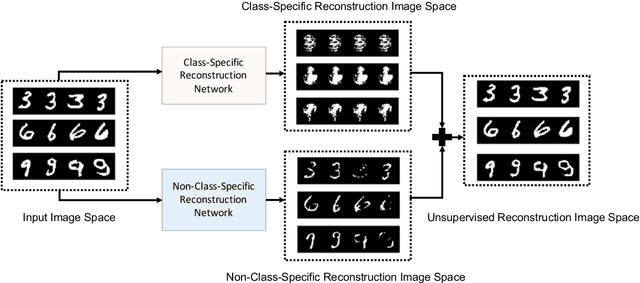
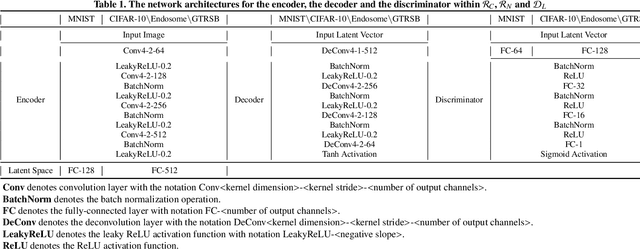
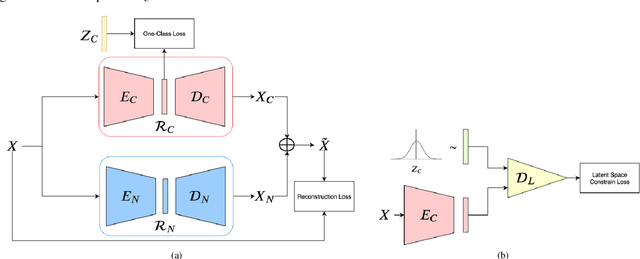
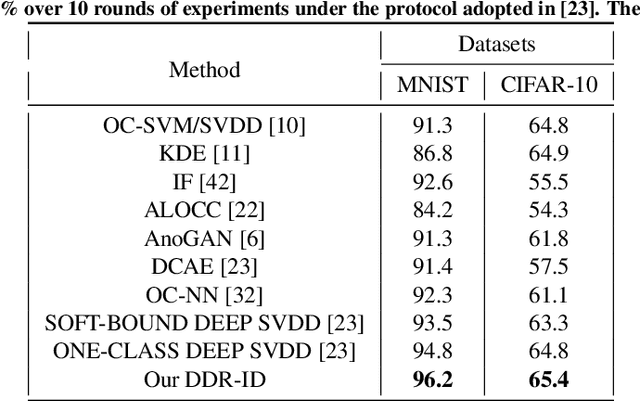
One pivot challenge for image anomaly (AD) detection is to learn discriminative information only from normal class training images. Most image reconstruction based AD methods rely on the discriminative capability of reconstruction error. This is heuristic as image reconstruction is unsupervised without incorporating normal-class-specific information. In this paper, we propose an AD method called dual deep reconstruction networks based image decomposition (DDR-ID). The networks are trained by jointly optimizing for three losses: the one-class loss, the latent space constrain loss and the reconstruction loss. After training, DDR-ID can decompose an unseen image into its normal class and the residual components, respectively. Two anomaly scores are calculated to quantify the anomalous degree of the image in either normal class latent space or reconstruction image space. Thereby, anomaly detection can be performed via thresholding the anomaly score. The experiments demonstrate that DDR-ID outperforms multiple related benchmarking methods in image anomaly detection using MNIST, CIFAR-10 and Endosome datasets and adversarial attack detection using GTSRB dataset.
Improving Deep Neural Network Classification Confidence using Heatmap-based eXplainable AI
Jan 08, 2022
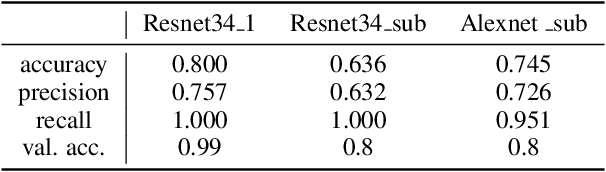
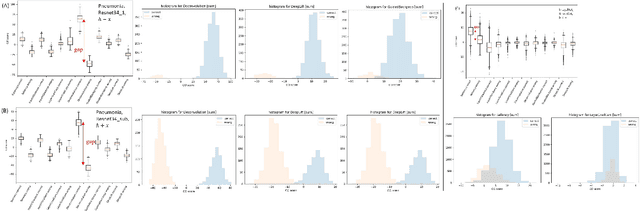
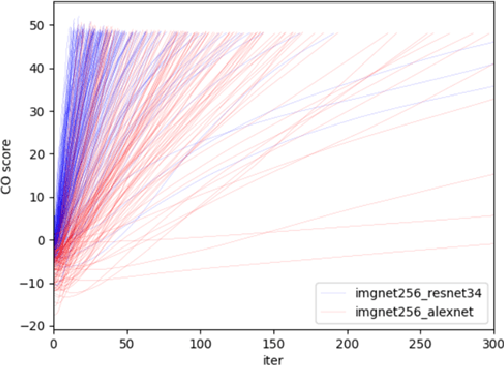
This paper quantifies the quality of heatmap-based eXplainable AI methods w.r.t image classification problem. Here, a heatmap is considered desirable if it improves the probability of predicting the correct classes. Different XAI heatmap-based methods are empirically shown to improve classification confidence to different extents depending on the datasets, e.g. Saliency works best on ImageNet and Deconvolution on ChestX-Ray Pneumonia dataset. The novelty includes a new gap distribution that shows a stark difference between correct and wrong predictions. Finally, the generative augmentative explanation is introduced, a method to generate heatmaps maps capable of improving predictive confidence to a high level.
VIDIT: Virtual Image Dataset for Illumination Transfer
May 13, 2020
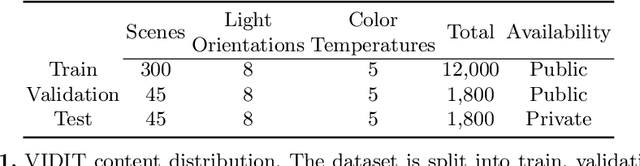
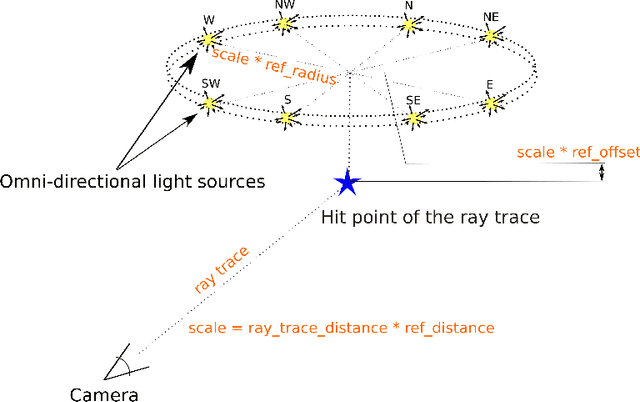

Deep image relighting is gaining more interest lately, as it allows photo enhancement through illumination-specific retouching without human effort. Aside from aesthetic enhancement and photo montage, image relighting is valuable for domain adaptation, whether to augment datasets for training or to normalize input test data. Accurate relighting is, however, very challenging for various reasons, such as the difficulty in removing and recasting shadows and the modeling of different surfaces. We present a novel dataset, the Virtual Image Dataset for Illumination Transfer (VIDIT), in an effort to create a reference evaluation benchmark and to push forward the development of illumination manipulation methods. Virtual datasets are not only an important step towards achieving real-image performance but have also proven capable of improving training even when real datasets are possible to acquire and available. VIDIT contains 300 virtual scenes used for training, where every scene is captured 40 times in total: from 8 equally-spaced azimuthal angles, each lit with 5 different illuminants.
FedDG: Federated Domain Generalization on Medical Image Segmentation via Episodic Learning in Continuous Frequency Space
Mar 10, 2021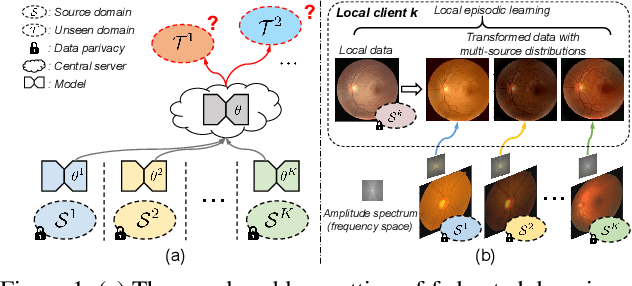
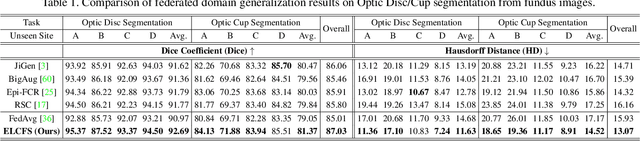
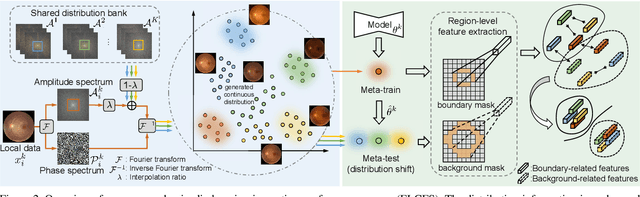
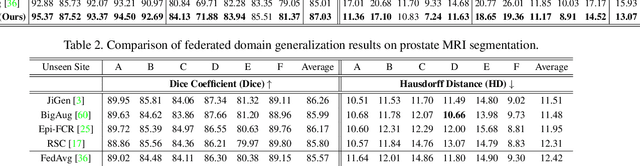
Federated learning allows distributed medical institutions to collaboratively learn a shared prediction model with privacy protection. While at clinical deployment, the models trained in federated learning can still suffer from performance drop when applied to completely unseen hospitals outside the federation. In this paper, we point out and solve a novel problem setting of federated domain generalization (FedDG), which aims to learn a federated model from multiple distributed source domains such that it can directly generalize to unseen target domains. We present a novel approach, named as Episodic Learning in Continuous Frequency Space (ELCFS), for this problem by enabling each client to exploit multi-source data distributions under the challenging constraint of data decentralization. Our approach transmits the distribution information across clients in a privacy-protecting way through an effective continuous frequency space interpolation mechanism. With the transferred multi-source distributions, we further carefully design a boundary-oriented episodic learning paradigm to expose the local learning to domain distribution shifts and particularly meet the challenges of model generalization in medical image segmentation scenario. The effectiveness of our method is demonstrated with superior performance over state-of-the-arts and in-depth ablation experiments on two medical image segmentation tasks. The code is available at "https://github.com/liuquande/FedDG-ELCFS".