 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Deep Neural Network Classification Confidence using Heatmap-based eXplainable AI
Jan 08, 2022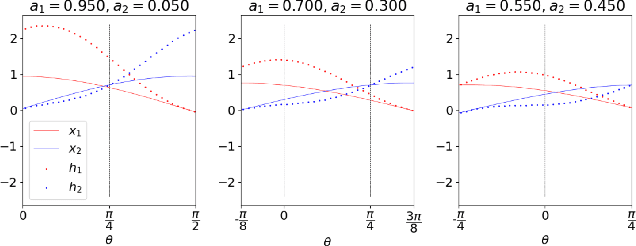
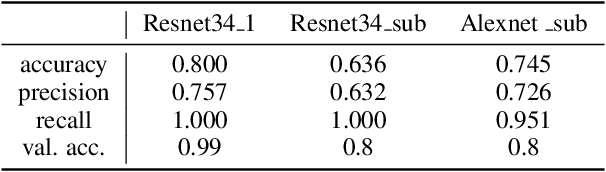
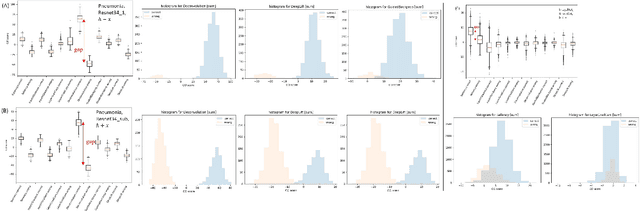
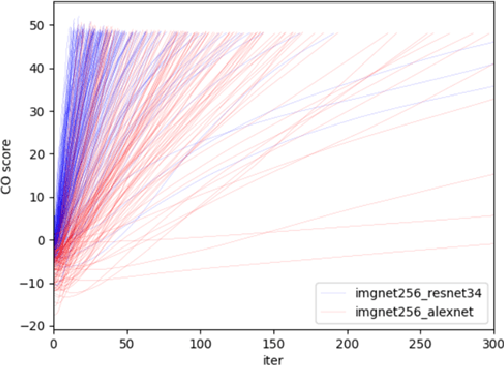
This paper quantifies the quality of heatmap-based eXplainable AI methods w.r.t image classification problem. Here, a heatmap is considered desirable if it improves the probability of predicting the correct classes. Different XAI heatmap-based methods are empirically shown to improve classification confidence to different extents depending on the datasets, e.g. Saliency works best on ImageNet and Deconvolution on ChestX-Ray Pneumonia dataset. The novelty includes a new gap distribution that shows a stark difference between correct and wrong predictions. Finally, the generative augmentative explanation is introduced, a method to generate heatmaps maps capable of improving predictive confidence to a high level.
Self Reward Design with Fine-grained Interpretability
Dec 30, 2021

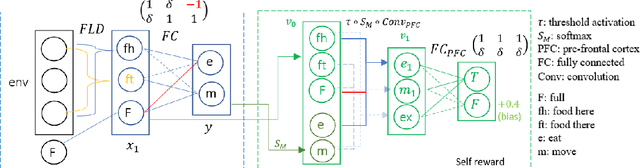
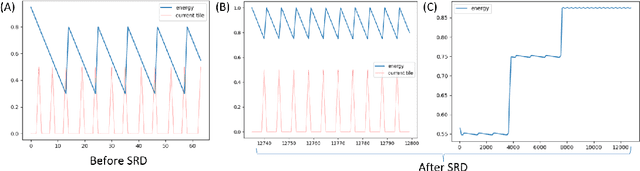
Transparency and fairness issues in Deep Reinforcement Learning may stem from the black-box nature of deep neural networks used to learn its policy, value functions etc. This paper proposes a way to circumvent the issues through the bottom-up design of neural networks (NN) with detailed interpretability, where each neuron or layer has its own meaning and utility that corresponds to humanly understandable concept. With deliberate design, we show that lavaland problems can be solved using NN model with few parameters. Furthermore, we introduce the Self Reward Design (SRD), inspired by the Inverse Reward Design, so that our interpretable design can (1) solve the problem by pure design (although imperfectly) (2) be optimized via SRD (3) perform avoidance of unknown states by recognizing the inactivations of neurons aggregated as the activation in \(w_{unknown}\).
Two Instances of Interpretable Neural Network for Universal Approximations
Dec 30, 2021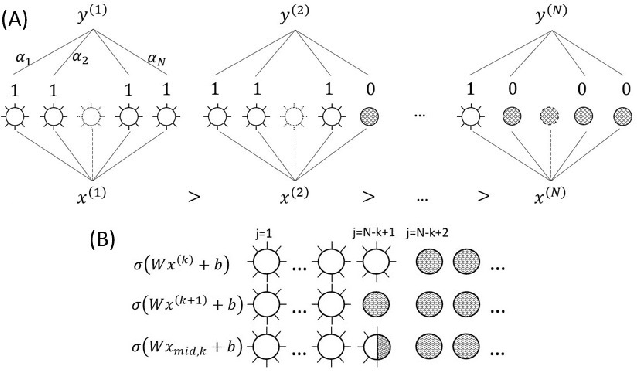

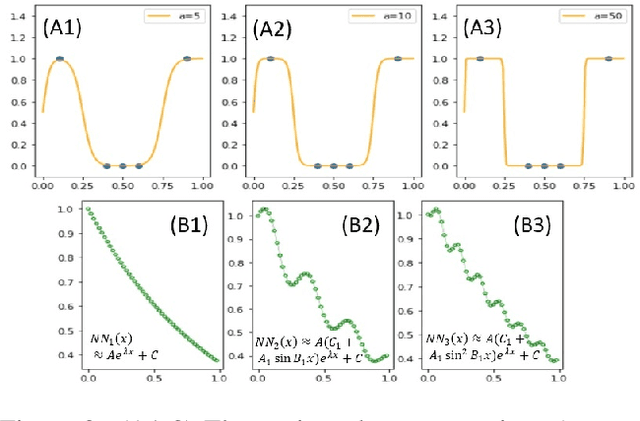
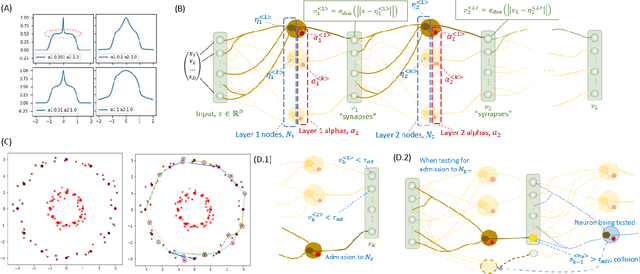
This paper proposes two bottom-up interpretable neural network (NN) constructions for universal approximation, namely Triangularly-constructed NN (TNN) and Semi-Quantized Activation NN (SQANN). The notable properties are (1) resistance to catastrophic forgetting (2) existence of proof for arbitrarily high accuracies on training dataset (3) for an input \(x\), users can identify specific samples of training data whose activation ``fingerprints" are similar to that of \(x\)'s activations. Users can also identify samples that are out of distribution.
A Modified Convolutional Network for Auto-encoding based on Pattern Theory Growth Function
Apr 04, 2021


This brief paper reports the shortcoming of a variant of convolutional neural network whose components are developed based on the pattern theory framework.
Convolutional Neural Network Interpretability with General Pattern Theory
Feb 05, 2021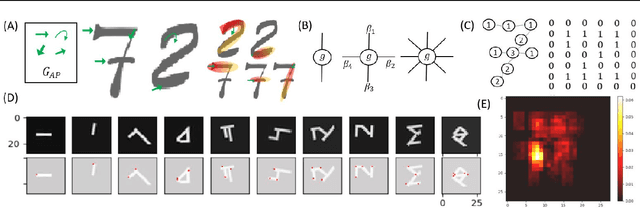
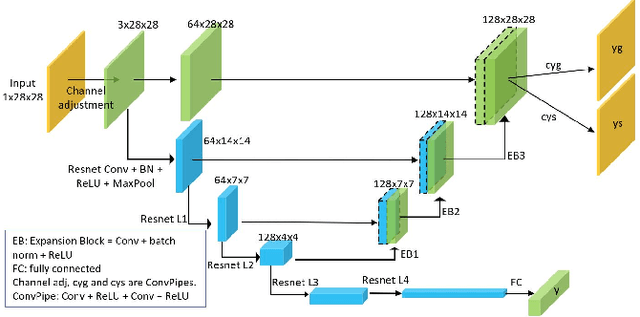
Ongoing efforts to understand deep neural networks (DNN) have provided many insights, but DNNs remain incompletely understood. Improving DNN's interpretability has practical benefits, such as more accountable usage, better algorithm maintenance and improvement. The complexity of dataset structure may contribute to the difficulty in solving interpretability problem arising from DNN's black-box mechanism. Thus, we propose to use pattern theory formulated by Ulf Grenander, in which data can be described as configurations of fundamental objects that allow us to investigate convolutional neural network's (CNN) interpretability in a component-wise manner. Specifically, U-Net-like structure is formed by attaching expansion blocks (EB) to ResNet, allowing it to perform semantic segmentation-like tasks at its EB output channels designed to be compatible with pattern theory's configurations. Through these modules, some heatmap-based explainable artificial intelligence (XAI) methods will be shown to extract explanations w.r.t individual generators that make up a single data sample, potentially reducing the impact of dataset's complexity to interpretability problem. The MNIST-equivalent dataset containing pattern theory's elements is designed to facilitate smoother entry into this framework, along which the theory's generative aspect is naturally presented.
Quantifying Explainability of Saliency Methods in Deep Neural Networks
Sep 07, 2020
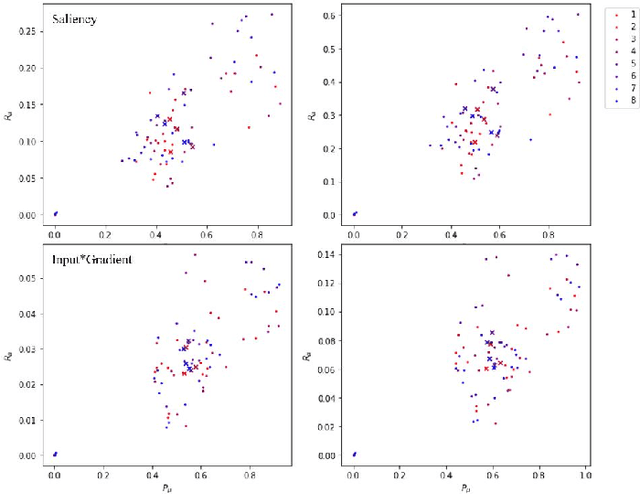

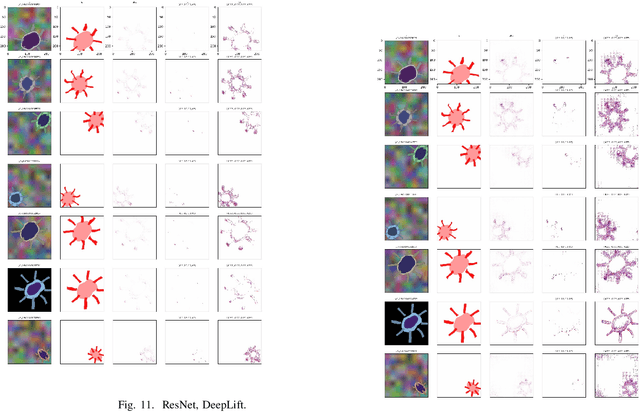
One way to achieve eXplainable artificial intelligence (XAI) is through the use of post-hoc analysis methods. In particular, methods that generate heatmaps have been used to explain black-box models, such as deep neural network. In some cases, heatmaps are appealing due to the intuitive and visual ways to understand them. However, quantitative analysis that demonstrates the actual potential of heatmaps have been lacking, and comparison between different methods are not standardized as well. In this paper, we introduce a synthetic data that can be generated adhoc along with the ground-truth heatmaps for better quantitative assessment. Each sample data is an image of a cell with easily distinguishable features, facilitating a more transparent assessment of different XAI methods. Comparison and recommendations are made, shortcomings are clarified along with suggestions for future research directions to handle the finer details of select post-hoc analysis methods.
Generalization on the Enhancement of Layerwise Relevance Interpretability of Deep Neural Network
Sep 05, 2020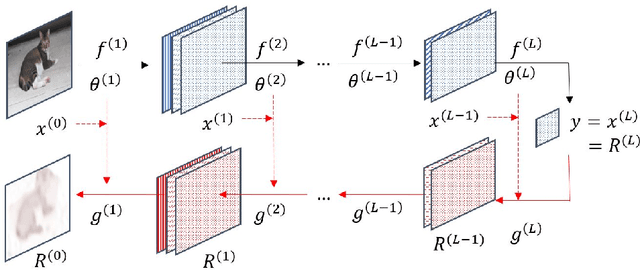
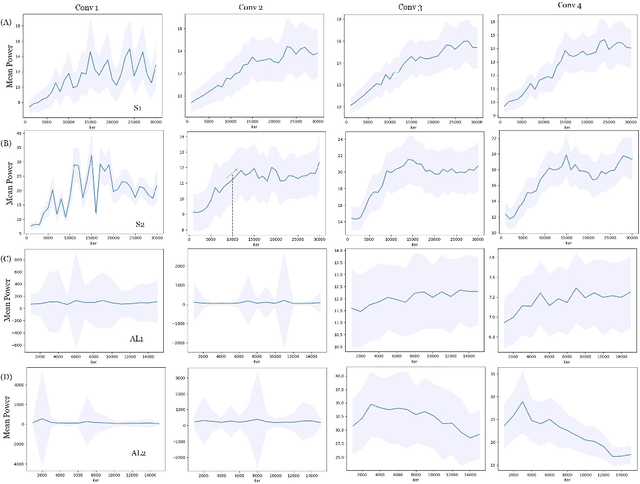


The practical application of deep neural networks are still limited by their lack of transparency. One of the efforts to provide explanation for decisions made by artificial intelligence (AI) is the use of saliency or heat maps highlighting relevant regions that contribute significantly to its prediction. A layer-wise amplitude filtering method was previously introduced to improve the quality of heatmaps, performing error corrections by noise-spike suppression. In this study, we generalize the layerwise error correction by considering any identifiable error and assuming there exists a groundtruth interpretable information. The forms of errors propagated through layerwise relevance methods are studied and we propose a filtering technique for interpretability signal rectification taylored to the trend of signal amplitude of the particular neural network used. Finally, we put forth arguments for the use of groundtruth interpretable information.
Enhancing the Extraction of Interpretable Information for Ischemic Stroke Imaging from Deep Neural Networks
Nov 19, 2019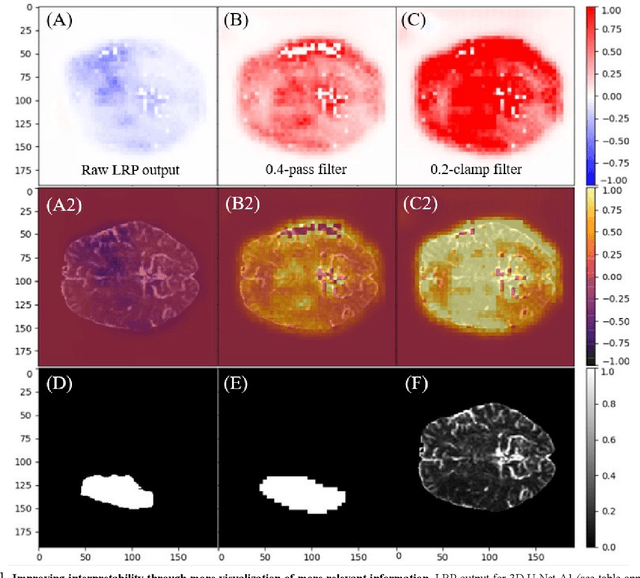
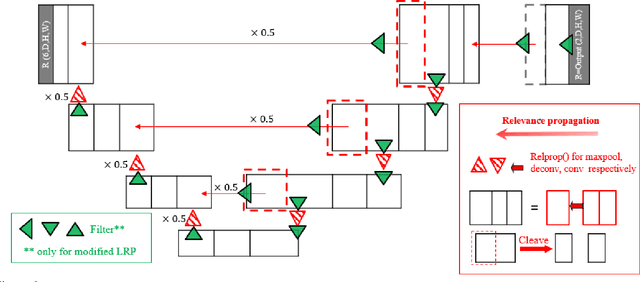
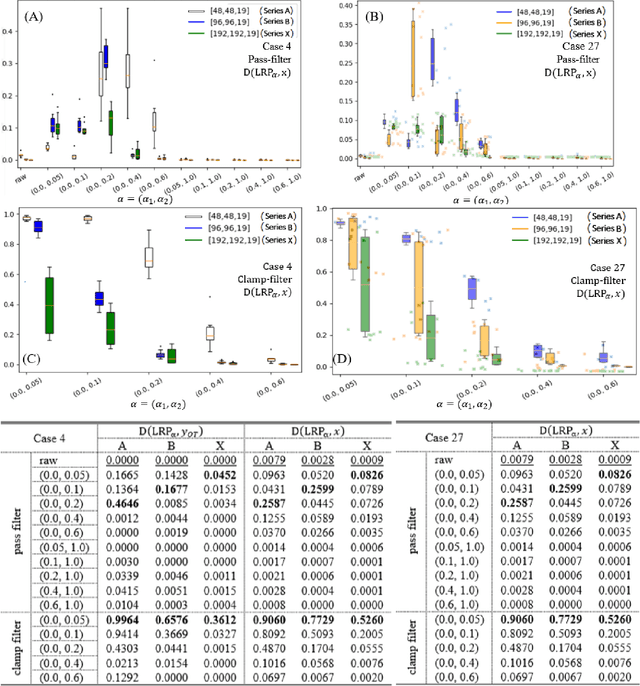
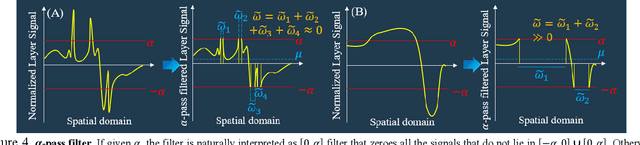
When artificial intelligence is used in the medical sector, interpretability is a crucial factor to consider. Diagnosis based on machine decision produced by a black-box neural network, sometimes lacking clear rationale, is unlikely to be clinically adopted for fear of potentially dire consequences arising from unexplained misdiagnosis. In this work, we implement Layer-wise Relevance Propagation (LRP), a visual interpretability method applied on 3D U-Net for lesion segmentation using the small dataset of multi-modal images provided by ISLES 2017 competition. We demonstrate that LRP modifications could provide more sensible visual explanations to an otherwise highly noise-skewed output and quantify them using inclusivity coefficients. We also link amplitude of modified signals to useful information content. High amplitude signals appear to constitute the noise that undermines the interpretability capacity of LRP. Furthermore, mathematical framework for possible analysis of function approximation is developed by analogy.
A Survey on Explainable Artificial Intelligence (XAI): Towards Medical XAI
Jul 31, 2019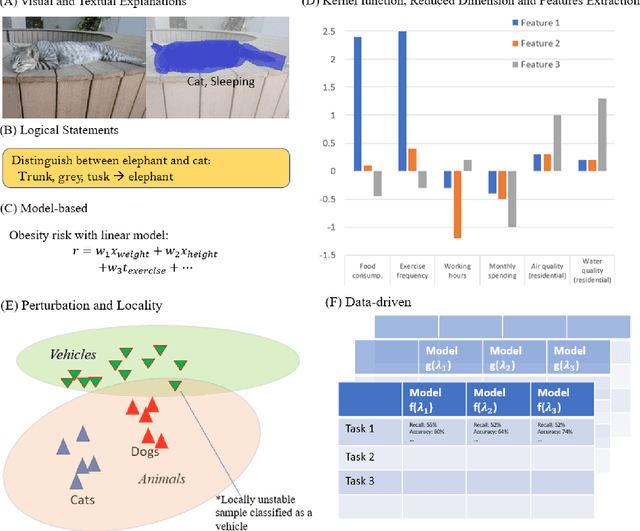
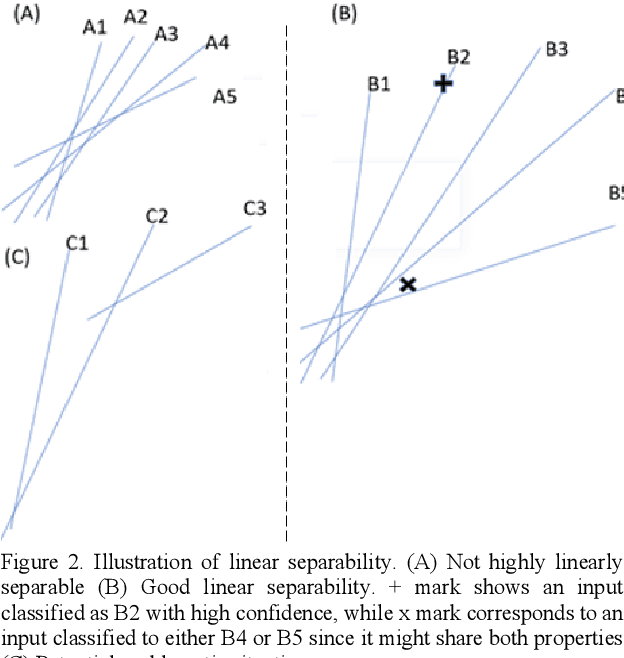
Recently, artificial intelligence, especially machine learning has demonstrated remarkable performances in many tasks, from image processing to natural language processing, especially with the advent of deep learning. Along with research progress, machine learning has encroached into many different fields and disciplines. Some of them, such as the medical field, require high level of accountability, and thus transparency, which means we need to be able to explain machine decisions, predictions and justify their reliability. This requires greater interpretability, which often means we need to understand the mechanism underlying the algorithms. Unfortunately, the black-box nature of the deep learning is still unresolved, and many machine decisions are still poorly understood. We provide a review on interpretabilities suggested by different research works and categorize them, with the intention of providing alternative perspective that is hopefully more tractable for future adoption of interpretability standard. We explore further into interpretability in the medical field, illustrating the complexity of interpretability issue.